
- 1mysql多表查询_mysql查2个表
- 2我的世界java版动作优化_我的世界动作优化模组
- 3初始Java JavaSE 异常 认识异常
- 4【git】git push异常问题出现@符号解决方法_git中包含@
- 5数据分析师面试必备,数据分析面试题集锦(四)
- 6产品经理面试相关经验和总结_互联网产品经理项目经验
- 7LeetCode 面试题 02.02. 返回倒数第 k 个节点 【Kth Node From End of List LCCI】_python解决leetcod02.02返回链表倒数第k个节点本机测试
- 8FPGA设计Verilog基础之Verilog的顺序块、并行块和块名的详细介绍_顺序块中须有时序控制信号‘
- 9SpringBoot趣探究--1.logo是如何打印出来的_springboot 打印指定图标
- 10经典面试问题回答思路【网上收集整理的】_面试官问你和朋友一起去旅行1罗列清单,2买飞机票,3去步行你会选哪个3
day02-Spark集群及参数_spark代码 参数
赞
踩
一、Spark运行环境变量问题(了解)
1-pycharm远程开发运行时,执行的是服务器的代码
2-通过本地传递指令到远程服务器运行代码时,会加载对应环境变量数据,加载环境变量文件是
用户目录下的.bashrc文件在/etc/bashrc
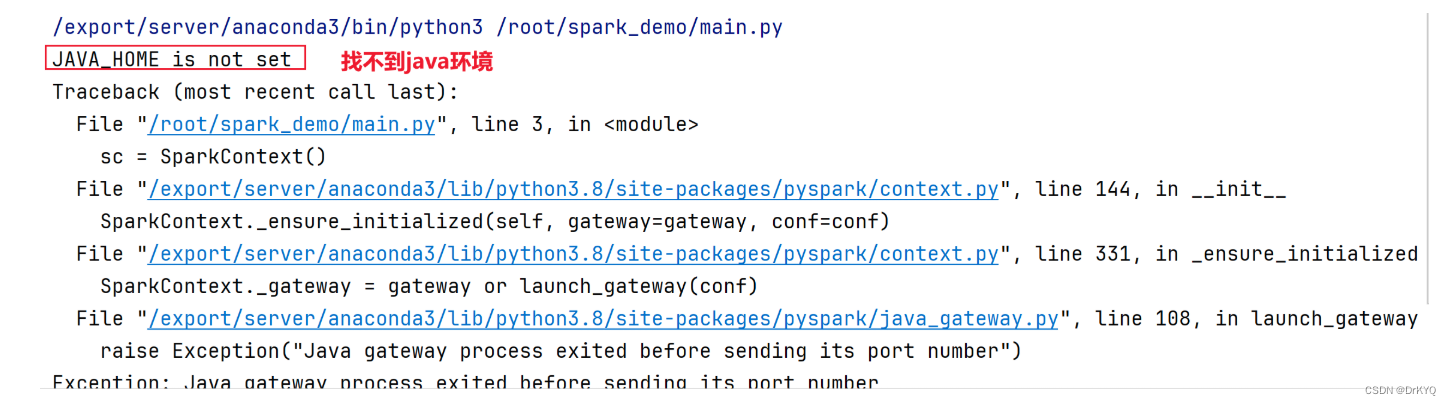
1-1 在代码中添加
使用os模块在代码中添加环境变量
from pyspark import SparkContext import os # 这里可以选择本地PySpark环境执行Spark代码,也可以使用虚拟机中PySpark环境,通过os可以配置 os.environ['JAVA_HOME'] = '/export/server/jdk' sc = SparkContext() data = [1,2,3,4] rdd = sc.parallelize(data) res = rdd.reduce(lambda x,y:x+y) print(res)
1-2 在用户环境文件中添加
在用户的环境变量文件中添加
当运行远程代码文件时,会读取/root/.bashrc文件中配置的信息
export JAVA_HOME=/export/server/jdk
使用os模块指定,每次代码文件中都要指定
使用bashrc只需要指定一次
二、集群下Spark的使用(掌握)
2-1 Standalone模式
使用spark自带的standalone资源调度服务
-
node1启动服务
/export/server/spark/sbin/start-all.sh
-
standalone服务角色介绍
-
master 类似yarn中的ResourceManger 负责管理整资源服务
-
worker 类似yarn 中Nodemanager 负责将每台机器上的资源给到计算任务
-
-
standalone的资源调度页面
-
交互开发 :指定使用standalone进行资源调度
pyspark --master spark://node1:7077
-
脚本式开发
from pyspark import SparkContext # master参数可以指定调用的资源服务 # 使用standalone资源调度 sc = SparkContext(master='spark://node1:7077')
2-2 yarn模式
-
启动服务
/export/server/hadoop/sbin/start-yarn.sh
-
yanr的服务角色
-
ResourceManger
-
Nodemanager
-
-
yarn的资源调度页面
-
交互开发 :指定使用yarn进行资源调度
-
需要启动hdfs
-
start-dfs.sh
-
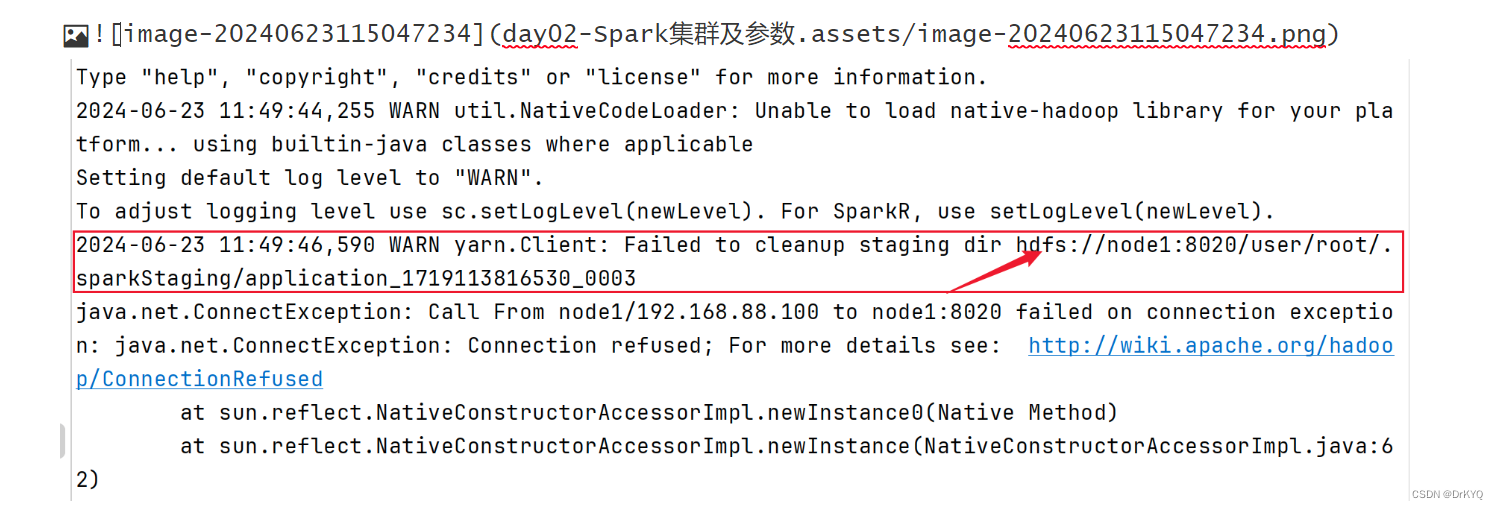

pyspark --master yarn
-
脚本开发
from pyspark import SparkContext # 没有指定任何参数,使用本地local模式 sc = SparkContext() # master参数可以指定调用的资源服务 # 使用yarn资源调度 sc = SparkContext(master='yarn')
2-3 不同运行模式总结
-
交互式
# 没有任何指定,采用是local模式,调用的是本机资源无法使用集群资源,相当于是单机计算 pyspark # 使用standalone资源调度 需要启动standalone服务 pyspark --master spark://node1:7077 # 使用yarn资源调度,高可用的使用方式一样 需要启动yarn服务 pyspark --master yarn
-
脚本式
-
在代码中指定
-
from pyspark import SparkContext # 没有指定任何参数,使用本地local模式 sc = SparkContext() # master参数可以指定调用的资源服务 # 使用standalone资源调度 sc = SparkContext(master='spark://node1:7077') # 使用yarn资源调度 sc = SparkContext(master='yarn')
实际开发只需要选择一种方式即可,公司中主要使用yarn
2-4 集群模式下运行流程
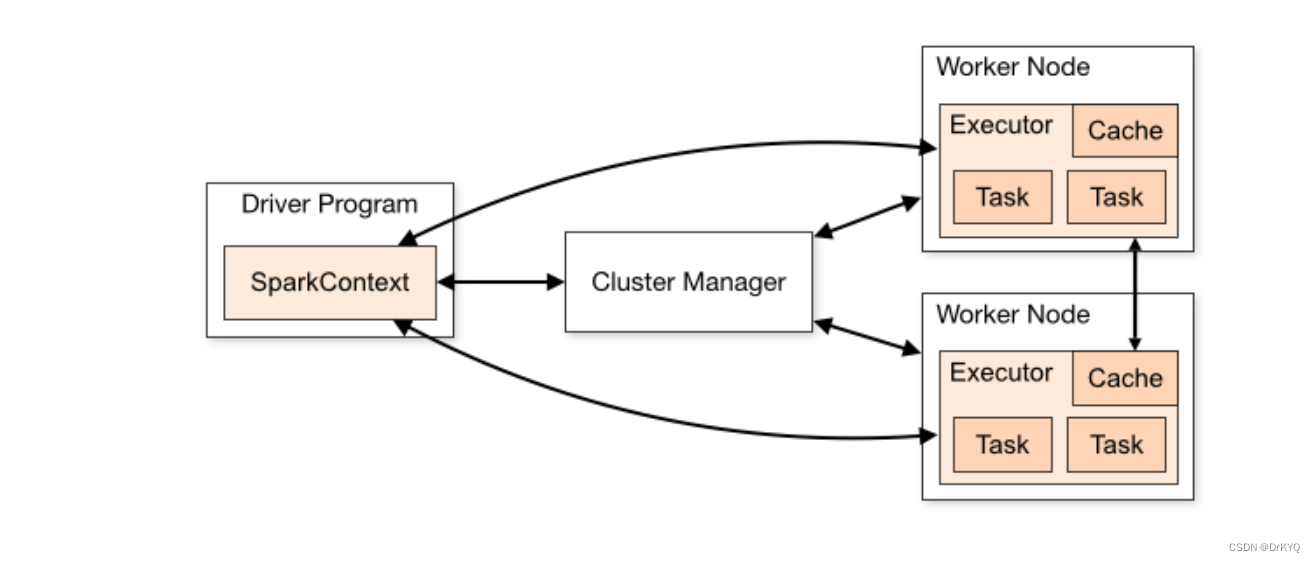
-
运行计算任务生成dirver程序
-
在dirver中生成sparkcontext对象
-
通过sparkcontext中方法向资源调度服务器申请资源
-
找对应的资源节点创建executor进程
-
executor创建后会通知sparkcontext
-
sparkcontext分配计算任务task到对应的executor执行,每个task就是一个线程
三、Spark的历史日志服务(掌握)
历史日志用来产看spark计算任务运行情况
-
启动hadoo
-
start-all.sh
-
-
启动
/export/server/spark/sbin/start-history-server.sh
-
执行计算任务
-
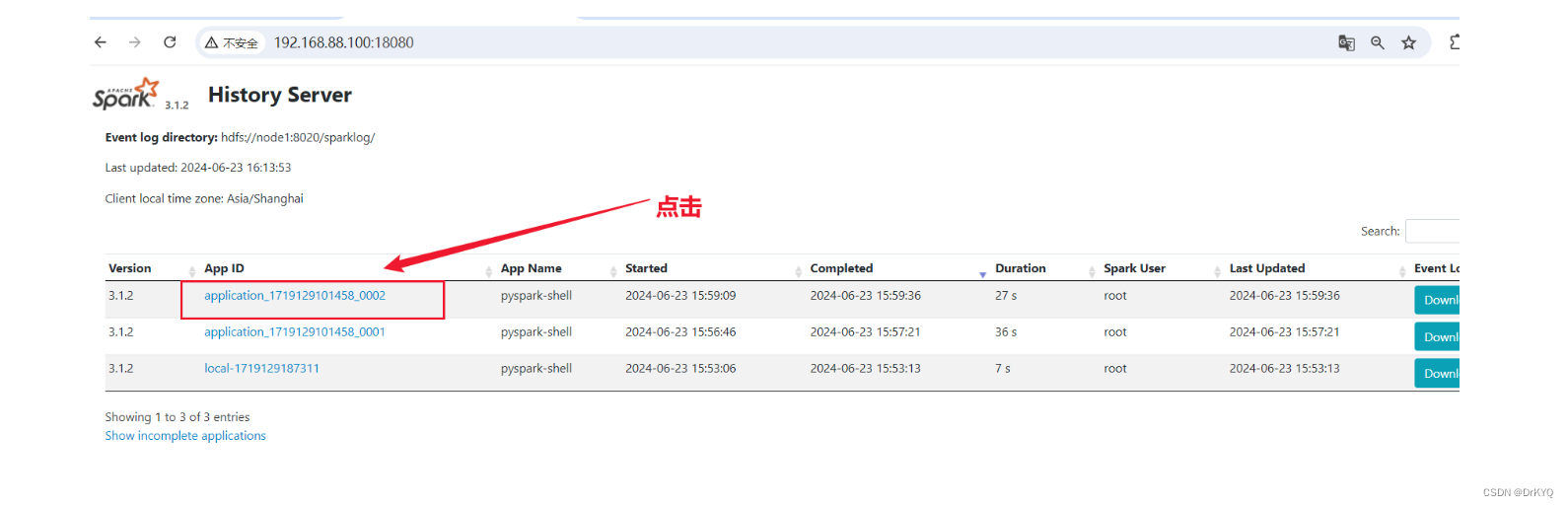
访问历史日志页面
-
计算任务运行期间
-
计算任务结束后
-


四、spark的指令参数(熟悉)
使用spark指令时可以通过参数方式配置相关spark的信息
4-1 书写格式
pyspark --参数 参数值
4-2 参数说明
pyspark --help
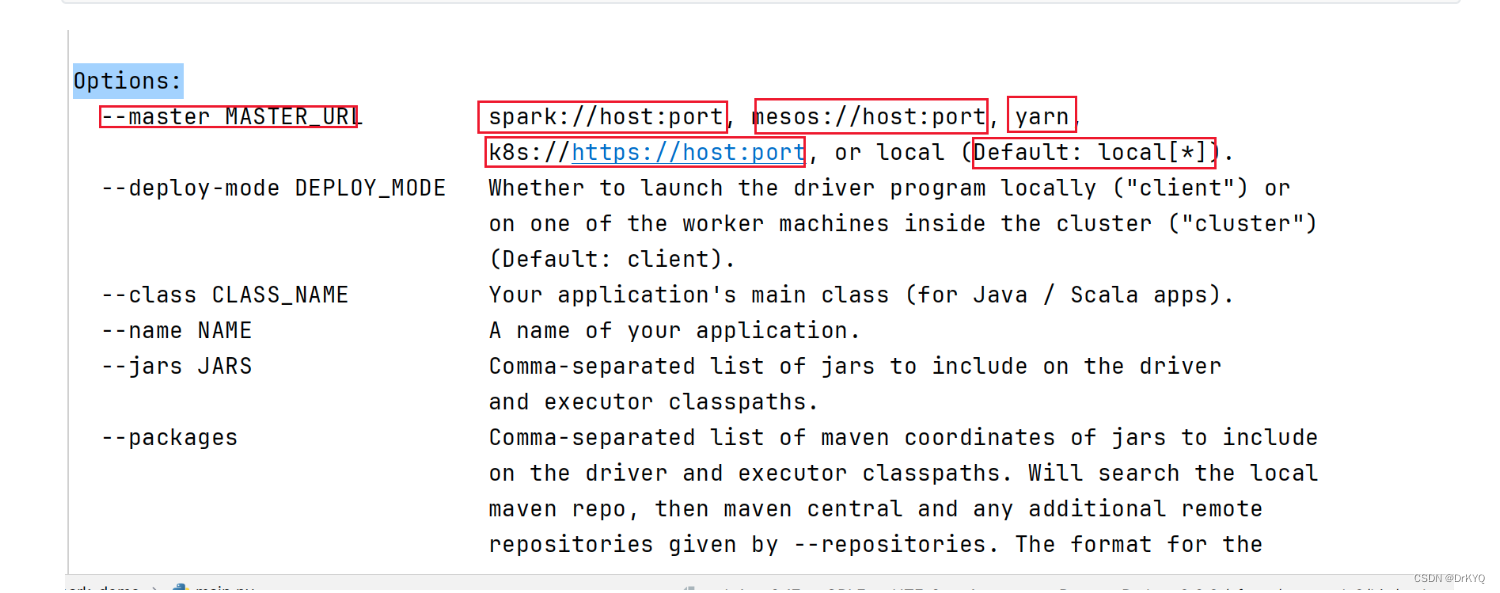
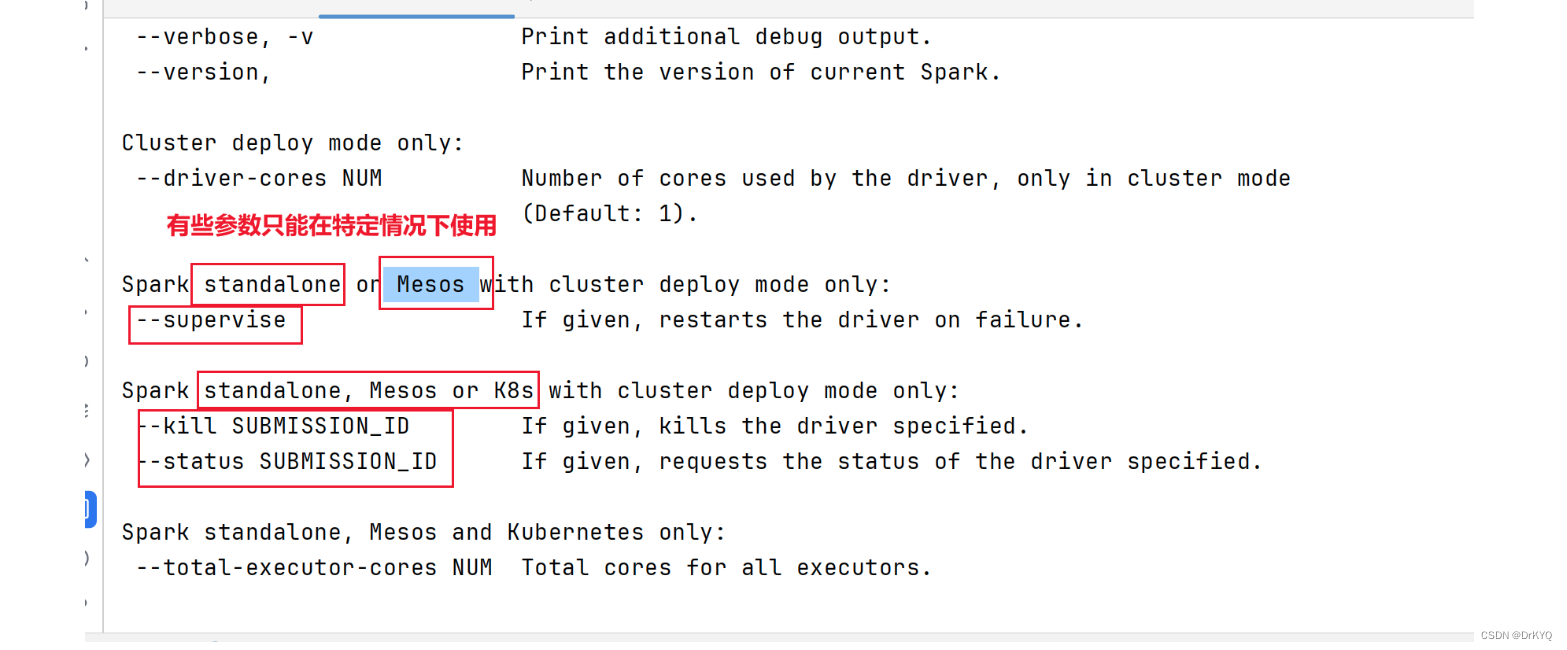
# 表示应用运行的模式,要么是本地local要么是集群(Standalone、YARN、Mesos)了 --master MASTER_URL # 本地模式∶local[2] 数字表示可以使用到本地的cpu核心数据量, loacl[*] *表示自动判断 # Standalone集群∶spark∶//xxx∶7077,yyy∶7077 # YARN 集群∶ yarn # 表示的是应用运行的名称,通常在应用开发的时候指定 --name NAME # 表示应用运行时指定的某些参数配置,http∶//spark.apache.org/docs/2.2.0/configuration.html # 当value中值有空格组成的时候,使用双引号将key=value引起来 # 可以不用在bashrc写配置可以通过conf配置,每次运行都要指定很麻烦 --conf "PROP=VALUE" # 第一种方式∶属性的值中没有空格 --conf spark.eventLog.enabled=false # 第二种方式∶属性的值中有空格,将属性和值统一使用双引号引起来 --conf"spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimestamps" # Driver相关配置 对driver一般不用配置 # 指定Driver Program JVM进程内存大小,默认值为1g --driver-memory MEM # 表示Driver 运行CLASS PATH路径,使用不多 --driver-class-path # Spark standalone with cluster deploy mode∶运行在standalone 中cluster Deploy Mode 默认值为1 cpu核心数据 # 运行在YARN in cluster mode,默认值是1 --driver-cores NUM # Executor运行所需内存大小 --executor-memory MEM # Execturo 运行的CPU Cores,默认的情况下,在Standalone集群上为worker节点所有可有的CpuCores,在YARN集群下为2 --executor-cores NUM # 表示运行在Standalone集群下,所有Executor的CPU Cores,结合--executor-cores计算出Executor个数 --total-executor-cores # 表示在YARN集群下,Executor的个数,默认值为2 --num-executors # 表示Drive Program运行的地方,也叫做应用部署模式,默认值为client,通常在生产环境中使用cluster --deploy-mode DEPLOY_MODE
4-3 参数演示
-
指定名称
pyspark --name itcast
-
指定配置信息
pyspark --master yarn --name itcast_conf --conf 'spark.sql.shuffle.partitions=100'

-
指定运行资源
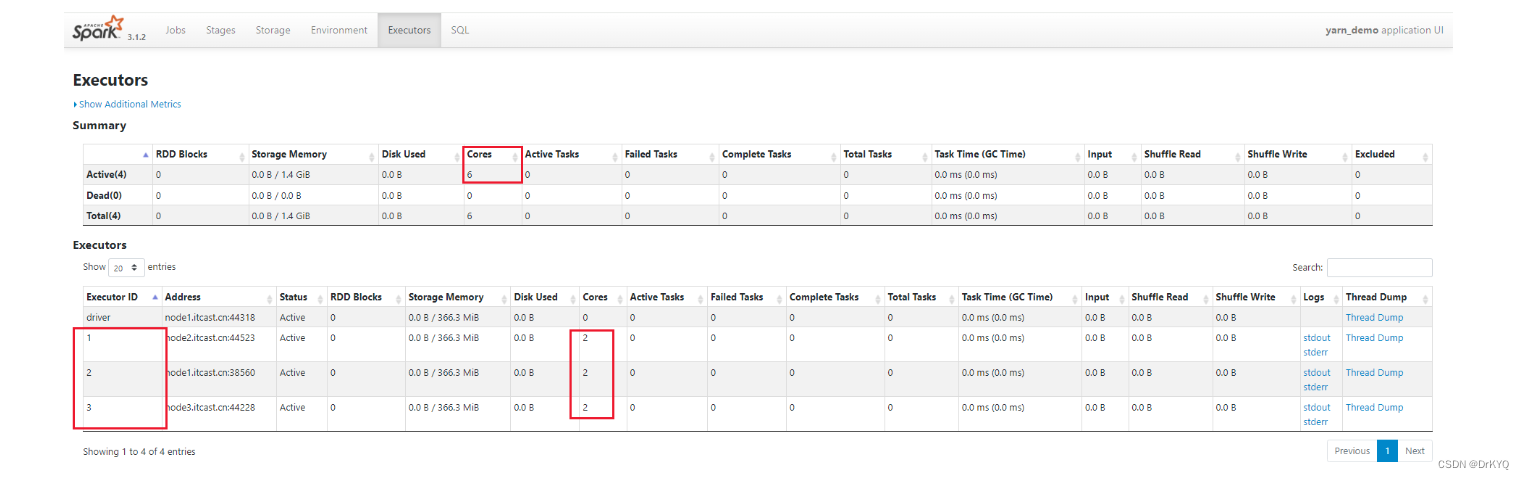
pyspark --master yarn --name yarn_demo --num-executors 3 --executor-cores 2
五、spark-submit提交方式(熟悉)
一般是在代码上线部署使用spark-submit提交运行代码
Submitting Applications - Spark 3.5.1 Documentation
采用该方式运行提交代码,dirver的运行位置有资源调度服务决定
spark-submit [指令参数] Python文件或java文件
5-1 部署模式参数
# 表示Drive Program运行的地方,也叫做应用部署模式, # 默认值为client,通常在生产环境中使用cluster --deploy-mode DEPLOY_MODE
-
两种模式区别
-
dirver在哪里运行
-
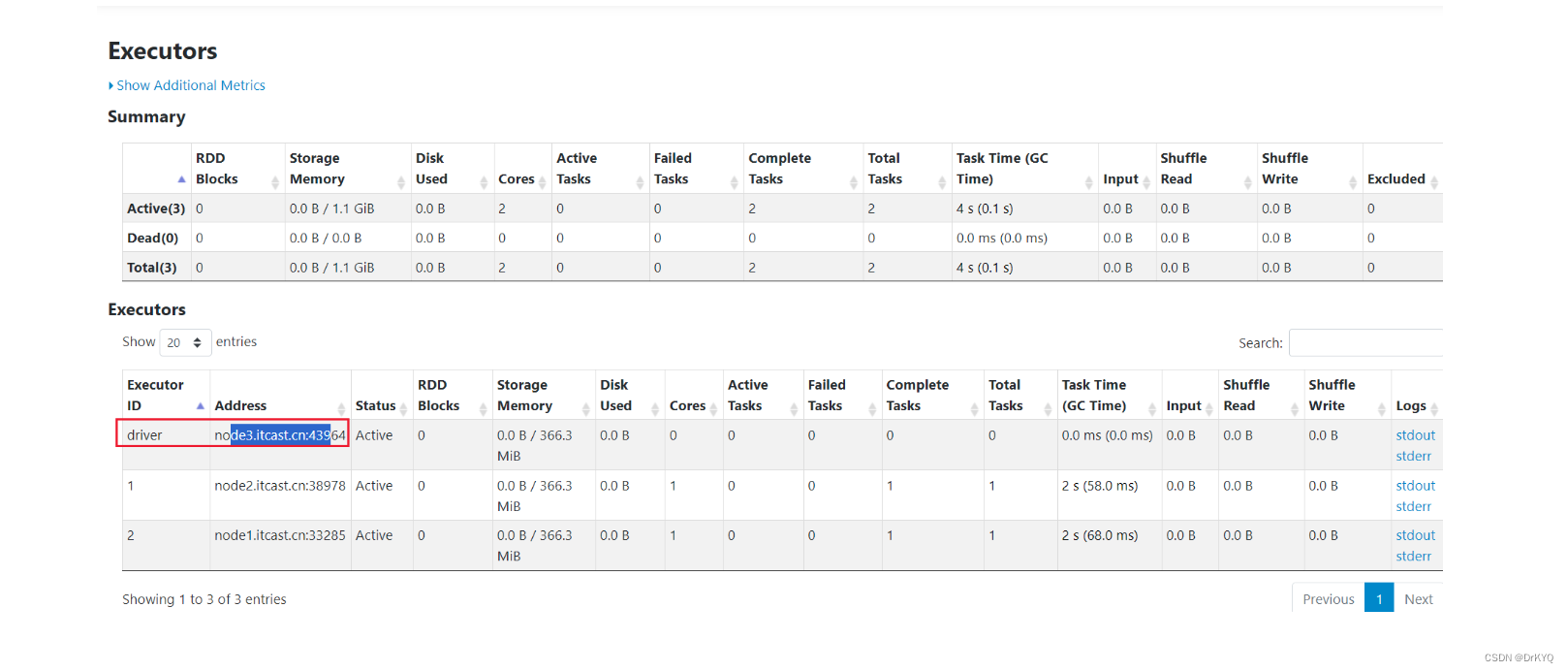
clinet模式:dirver是在提交代码的服务器上运行,该方式是默认方式,不指定是就采用client模式
-
cluster模式:dirver由
资源的调度服务找到对应服务器上运,在该模式下必须指定master,选择资源调度服务
-
-
5-2 clinet模式指定
spark-submit --master yarn /root/spark_demo/main.py

5-3 cluster 模式
spark-submit --master yarn --deploy-mode cluster /root/spark_demo/main.py
六 端口
Hadoop
-
web页面访问
-
hdfs 9870
-
yarn 8088
-
history 19888
-
-
程序服务访问
-
hdfs 8020
-
CDH访问端口
-
7180
Spark
-
采用standalone
-
web端口 8080
-
-
历史日志
-
运行期间 4040
-
运行结束 18080
-

