
- 1文心一言降重效果 快码论文_文心一言降重诀窍
- 2java计算机毕业设计(附源码)学生信息管理系统(ssm+mysql+maven+LW文档)
- 3Kafka怎么保证消息发送不丢失_kafka 生产者和消费者怎么保证不丢消息
- 4国密算法SM3
- 5常见开源许可证_弱著佐权类许可证
- 6pyglet python播放视频有声音_播放器播放rtsp混合流正常,python代码播放有杂音
- 7Prim算法:最小生成树的构建_prim算法怎么构建最小生成树
- 8paddleocr - 数据集制作_paddleocr数据集格式
- 9阿里、腾讯、字节、京东、美团、百度......薪资职级大比拼
- 10【xml解析】的学习_xml语言 sph
搜索引擎技术 —— 检索模型
赞
踩
内容相似性计算框架
判断网页内容是否和用户查询相关,这依赖于搜索引擎所采用的检索模型。目前业界主要有以下几种检索模型:布尔模型、向量空间模型、概率模型、语言模型以及机器学习排序算法。
尽管目前检索模型多种多样,但是基本原理皆不变,下图是一个搜索引擎计算内容相似性的框架。当用户输入关键词之后,搜索引擎会在内部对用户的查询构造相应的查询表示方法。之后会判断哪些文档是和用户需求相匹配的,并且按照相关程序排序输出。

检索模型的评价
我们把检索结果文档划分为4部分,而越好的检索模型返回的结果就是要更多的提升第一象限和第二象限文档的排名,抑制第三象限和第四象限文档的排名。

检索模型
布尔模型
布尔检索模型是检索模型中最简单的一种。在布尔模型中,文档与用户查询由其包含的单词集合来表示,两者的相似性通过布尔代数运算来进行判定。
用户查询一般使用逻辑表达式,使用常见的 “与或非”这些逻辑运算将用户的查询词串联,以此作为用户的信息需求表达。例子如下,下面就会检索出同时包含百度和搜索引擎两个关键词的文档:
百度 && 搜索引擎
- 1
布尔模型简单直观,但是其过于简单所以缺点也很明显。其输出结果是二元的,要不结果是相关,要不是不相关的。所以其只能判断是否相关,不能确定相关程度。
向量空间模型
向量空间模式最初由信息检索领域奠基人Salton教授提出。目前在搜索领域、自然语言处理等多领域广泛应用。
文档表示
向量空间模型把每个文档看做是由 n 维特征组成的一个向量,特征可以是单词、词组、N-gram片段等多种形式。其表示形式如下,其中w12表示第一个文档的第二维特征的权重。
| 特征1 | 特征2 | 特征3 | |
|---|---|---|---|
| 文档1 | w11 | w12 | w13 |
| 文档2 | w21 | w22 | w23 |
| 文档3 | w31 | w32 | w33 |
相似性计算
将文档转换为特征向量后,我们就可以计算文档之间或者是查询和文档之间的相似性了。对于计算查询和网页内容相关性这个问题,向量空间模型做了转换以查询和文档之间的内容相似性来作为相关性的替代,按照文档和查询的相似性得分由高到低作为搜索结果。
内容相似性计算基于Cosine公式,这个公式计算用户查询Q和Di文档的相似性。公式中分子部分将文档的每个特征权值和查询的每个特征权值相乘求和;公式的分布部分是两个特征向量在欧式空间中长度的乘积,作为分子点积结果的规范化。规范化的目的就是对长文档的惩罚措施,抑制文档越长带来的得分越高的这种现象。
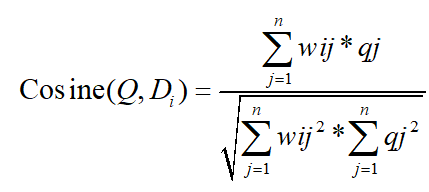
Q:查询关键词
Di:文档i
wij:文档特征权值
qj:查询的特征权值
- 1
- 2
- 3
- 4
但是,Cosine公式中的规范化方法有一个明显的缺陷:其会对长文档过分抑制,如果同时有相关短文档和长文档,它会使短文档的相关度数值大大高于长文档的相关度数值。
Cosine算法会将文档和查询看做使n维特征空间中的一个数值点,每个特征形成n维空间中的一个维度,连接特征空间原点和这个数值点形成的一个向量,而Cosine相似性就是计算特征空间中两个向量之间的夹角,夹角越小说明两个特征向量内容越相似;夹角越大,说明两个向量空间内容越不同。

特征权重计算
在向量空间模型中,特征权值计算框架一般称作TF*IDF框架。这一计算框架主要考虑的计算因子有两个:词频TF和逆文档频率IDF。
TF词频信息计算
TF代表了词频,即一个单词在文档中出现的次数。根据常识来说,在文档中反复出现从词汇其实更能反映文档的主旨。具体计算词频因子的时候,基于不同的出发点,可以采纳不同的计算公式。
最简单的方式方式就是,单词出现了多少次,那么权值便为多少。
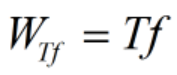
其变种的计算公式如下,其将词频数值Tf取Log值来作为词频权值。公式中数字1作为平滑计算用。而为什么要用Log则是抑制长文档带来的高分表现。
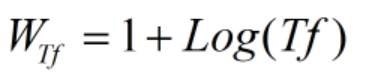
另外一种方法被称为增强型规范化Tf,其中a是调节因子,过去的经验取值0.4。公式中Max(Tf)代表了文档中所有单词中出现次数最多的那个单词的词频数目,其也是对长文档的抑制。
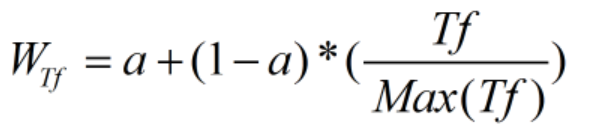
IDF逆文档频率计算
逆文档频率因子IDF代表的是文档集合范围的一种全局银子。给定一个文档集合,每个单词的IDF值是唯一确定的,跟具体文档无关。所以IDF考虑的不是文档本身的特征,而是特征单词之间的相对重要性。除此之外,IDF还代表了单词带有的信息量的多少,其值越高,说明其信息含量越多,就越有价值。
其计算公式如下,其中N代表文档集合中总共有多少个文档,而nk代表特征单词k在其中多少个文档出现过,即文档频率。
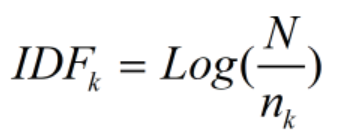
TF*IDF框架
TF*IDF框架是结合了上述的词频因子和逆文档频率因子的计算框架,一般上是将其直接相乘作为特征权值。
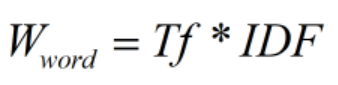
向量空间模型是一个经验型模型,靠直觉和经验不断摸索完善的,缺乏明确理论来指导前进方向。
概率检索模型
概率检索模型是从概率排序原理推导出来的。概率排序原理的基本思想:给定一个用户查询,如果搜索系统能够在搜索结果排序时按照文档和用户需求的相关性由高到低排序,那么这个搜索引擎系统的准确性是最优的。而在文档集合的基础上尽可能准确的对这种相关性进行估计则是其核心。
当用户发出一个查询请求,我们把文档集合划分为两个类别 :相关文档子集和不相关子集。对于某个文档D来说,如果其属于相关文档子集的概率大于属于不相关文档子集的概率,我们就可以认为这个文档是与用户查询是相关的。下图中P(R|D)代表相关性概率,而P(NR|D)则代表不相关概率:

相关性计算的目的就是要判断P(R|D)>P(NR|D),转换一下就是如下公式:
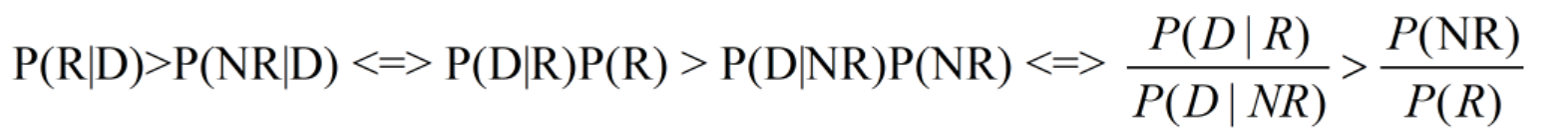
搜索引擎就只需要对P(D|R)/P(D|NR)的大小降序排列就可以了。问题就会转换成估算因子P(D|R)和P(D|NR),这些就由二元独立模型提供计算。
二元独立模型
计算上述两个因子,二元独立模型(BIM)做了如下两个假设:二元假设和词汇独立性假设。
二元假设
二元假设被死于布尔模型中的文档表示方法,一篇文档在由特征进行表述的时候,以特征出现和不出现两种情况来表示,不考虑其他因素。
词汇独立性假设
词汇独立性假设指文档中出现的单词之间是没有任何关联的。这是一个假设,也就是说我们认为出现搜索跟是否会出现索引是没有一点关系的。这样,我们可以对一个文档的概率估计转换为对文档包含单词的概率的乘积。
因子估算
假设对于五个单词在文档D中的表示{1,0,1,0,1}意义是第1,3,5个单词在文档D中出现过。现在我们用pi表示第i个单词在相关文档集合内出现的概率,这样文档D的概率可以表示为:

对于因子P(D|NR)则可以假设si表示第i个单词在不相关文档集合内出现的概率:
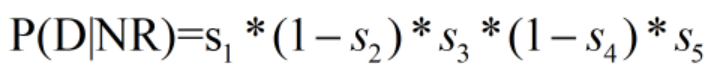
这样我们可以用如下公式进行概率检索模型的计算:
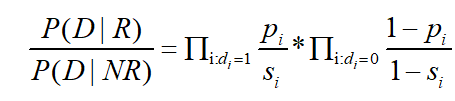
R //相关文档
NR //不相关文档
di = 1 //此时为词汇出现的情况
di = 0 //此时词汇为不出现的情况
- 1
- 2
- 3
- 4
进一步对这个数学公式等价变换为:
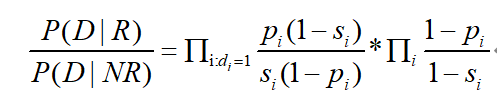
这个分为两个部分,第一个部分表示在文档中出现过的单词所计算得到从单词概率乘积,后面的那一部分 ∏i 代表对所有特征词计算所得到的单词概率乘积,这个是个定值。所以最终的相关性估算公式如:
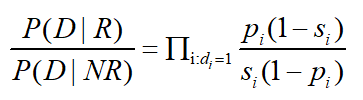
出于计算方便,对上述公式取log,便可得到如下相关性估值公式:
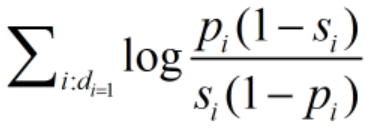
现在我们就差最后计算概率pi以及si了,这个可以根据下表:
| 相关文档 | 不相关文档 | 文档数量 | |
|---|---|---|---|
| di = 1 | ri | ni-ri | ni |
| di = 0 | R-ri | (N-R)-(ni-ri) | N-ni |
| 文档数量 | R | N-R | N |
相关性估值公式采取了log形式,如果ri=0,那么会出现log(0)的情形,为了避免这种情况,我们进行平滑计算,得到如下公式:

最后带入我们刚刚得到的log公式,便得到了如下的相关性估算公式,其含义是:对于同时出现在用户查询Q和文档D中的单词。累加每个单词的估值,其和就是文档D和查询的相关性度量。
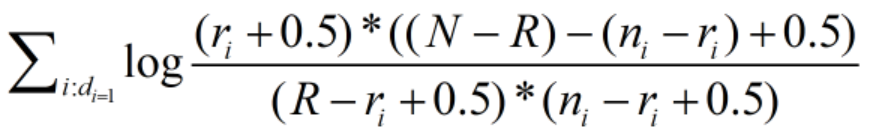
BM25模型
BIM(二元独立模型)基于二元假设推导而出,对于单词特征,只考虑是否在文档中出现过,不考虑单词权值。而BM35模型在BIM基础上,考虑了单词在查询中的权值以及单词在文档中的权值。
以下是BM25模型的计算公式,对于查询Q中出现的每个查询词,依次计算单词在文档D中的分值,累加后就是文档D和查询Q的相关性得分。这个公式的左边就是刚刚推导出来的BIM模型,右边那一部分则是查询词在文档D中的权值,其中 fi 表示单词在文档D中的词频,k1和K是经验参数;右边那一部分则是查询词自身的权值,其中qfi代表查询词在用户查询中的词频,k2则是经验参数。
在第二部分中,K代表了对文档长度的考虑,dl代表文档D的长度,而avdl则是文档集合中所有文档的平均长度,k1和b是经验参数,其中b为调节因子。如果b=0,那么文档长度因素将不起作用,经验则表明b=0.75时会获得比较好的搜索效果。
BM25中包含3个自由调节参数,除了调节因子b外,还有针对词频的调节因子k1和k2。k1。k1的作用时对查询词在文档中的词频进行调节,如果k1设定为0,则第二部分计算因子成了整数1,就表示不考虑词频的因素。根据经验来说,k=1.2会有比较好的效果。
调节因子k2则是针对查询中的词频进行调节,一般将这个值设定为0~1000较大的范围,这个k2的作用放大词频之间的差异。

BM25F模型
BM25F是很典型的BM25的改进算法。BM25模型在计算文档和查询相关性的时候,把文档当作一个整体来看待。但是在有些场景下,需要将文档内容切割成不同的组成部分,然后对不同成分分别对待。
一个网页由页面标题、Meta描述信息、页面内容等不用的域组成。在计算相关性得分的时候,关键词出现在不同的域会被赋予不同的得分。所以BM25F就是针对这种情况给出了如下计算公式,其中Wbim表示BIM推导出来的部分,也就是BM25公式的第一个组成部分。

BM25F与BM25的区别体现在第二个计算因子的fi上,这个因在综合了第 i 个单词出现在不同域的得分。假设一个文档D包含了u个域,而每个域的权值设定为Wk,fi将第一个单词在各个不同域的分值fui/Bu加权求和,其中fui代表单词在第u个域出现的词频数,Bu则是域的长度信息。

对于Bu来说,ulu是这个网页这个域从实际文本长度,avulu是文档集合中这个域的平均长度,而bu是调节因子。对于BM25F来说,除了调节因子k1之外,如果文档包含u个不同的域,则需要凭经验设定u个域权值Wk和u个长度调节因子bu。
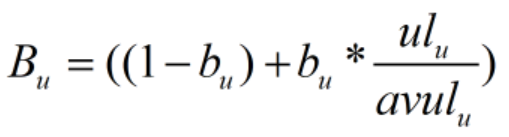
语言模型方法
语言模型方法为每个文档建立不同的语言模型,判断由文档生成用户查询的的可能性有多大,然后按照这种生成概率由高到低排序,作为搜索结果。
给定一篇文档和对应的用户查询,首先会为每个文档建立一个语言模型,语言模型代表了单词或者单词序列在文档中的分布情况。对于查询中的每个单词来说,每个单词都对应一个抽取概率,将这些单词的抽取概率相乘就是文档生成查询的总体概率。
假设一个网页包含 {百度、搜索引擎、索引、倒排索引、检索模型}这五个单词,每个单词都只出现一次。索引抽取每个单词的概率是1/5。那么文档生成{百度、中文、搜索引擎}的概率便如下:
P(Q|D) = P(百度|D)*P(中文|D)*P(搜索引擎|D) = 0.2*0.2*0 = 0
- 1
在上述例子中由于中文这个关键词没有出现过,所以导致语言模型方法失效,这个问题被称为数据稀疏问题。我们一般会采用数据平滑的方式解决这个问题,这个方式会从文档中出现过的单词的分布概率值中取出一部分,将这些值分配给文档中没有出现过的单词,这样所有单词都会有一个非零的概率值。
语言模型检索方法则会为所有单词引入一个背景概率来做数据平滑。对于文档集合的一元语言模型,某个单词的背景概率就是这个单词出现的次数除以文档集合的单词总数。
下面是加入数据平滑后的文档生成查询概率计算公式。分为两个部分,一个部分是之前提到的文档语言模型,另一部分是用作平滑的文档集合语言模型。
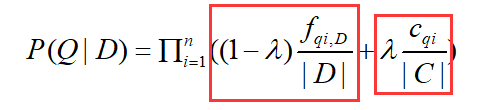
检索质量评价
对搜索系统的评价除了时间空间等运行效率方面,更重要的是对搜索结果质量进行评测。而搜索结果质量主要分为两个指标,即精确率和召回率。
- 精确率:本次搜索结果中相关文档所占的比例
- 召回率:本次搜索结果中包含的相关文档占整个集合中所有相关文档的比例。
除此之外还有P@10指标和MAP指标。
- P@10指标:其更关注搜索结果排名最靠前文档的结果质量,它用于评估在搜索结果排名最靠前的前十个文档有多大比例是相关的。
- MAP指标:其针对多次查询的平均准确率衡量标准。AP是针对单词查询的衡量标准,计算这一次查询出来的每个文档中理想排名/结果排名之和/相关文档个数。对这些查询的AP值求平均值,就得到了MAP指标。

参考文献
[1] 这就是搜索引擎

