
- 1威纶通 西门子1200/1500绝对地址方式连接_威纶通触摸屏与西门子1200地址定义
- 2Stable Diffusion - 光影魔法,SD中的光影控制(附模型)_stable diffusion光影搭配
- 3Android笔试题大全(持续更新中)
- 47·19微软蓝屏事件:对全球 IT 基础设施的冲击与反思_微软蓝屏事件的影响和启示
- 5Maven的安装与配置 for mac_maven for mac
- 6夏日智启:我的Datawhale AI夏令营探索之旅_datawhale ai夏令营怎么样
- 7企业运维实战(docker compose)_docker实战企业运维
- 8232接口针脚定义_工业RS232接口总线原理与应用方案
- 9数据结构与算法————图的遍历DFS深度优先搜索和BFS广度优先搜索_题目 1702: 数据结构-图的遍历-dfs深度优先搜索(深搜)
- 10可图开源专属 ControlNet 模型以及 Inpainting 模型,更多玩法,更强生态!_可图 controlnet
ComfyUI 实战教程:一键扩图
赞
踩
大家好,我是每天分享AI应用的萤火君!
本文给大家分享一个很有用的技术:AI扩图。所谓扩图就是扩展图像的边界,在图像的边界外新增更多画面元素,这不仅仅是扩大图像的尺寸,还要让新添加的部分与原有图像的内容自然融合。
AI扩图有很多的应用场景,比如:
- 摄影后期处理:想要裁剪照片来获得更好的构图,但裁剪后可能会导致画面不平衡,扩图可以让裁剪后的照片看起来更加完整;
- 游戏开发:在游戏环境中添加更多的细节或者扩展场景,使得游戏世界更加真实丰富;
- 社交媒体和广告设计:有时候需要将图像调整到特定的尺寸,如果原始图片不够大,AI扩图技术可以帮助填充额外的空间,使设计更加美观。
- 虚拟现实(VR)和增强现实(AR):在创建VR/AR体验时,为了增强沉浸感,可能需要扩展场景的边界,AI扩图技术可以自动合成出合适的环境延伸。
想想还是挺让人激动的,大家可能也有点等不及了,本文将使用 ComfyUI 工作流来实现AI扩图。
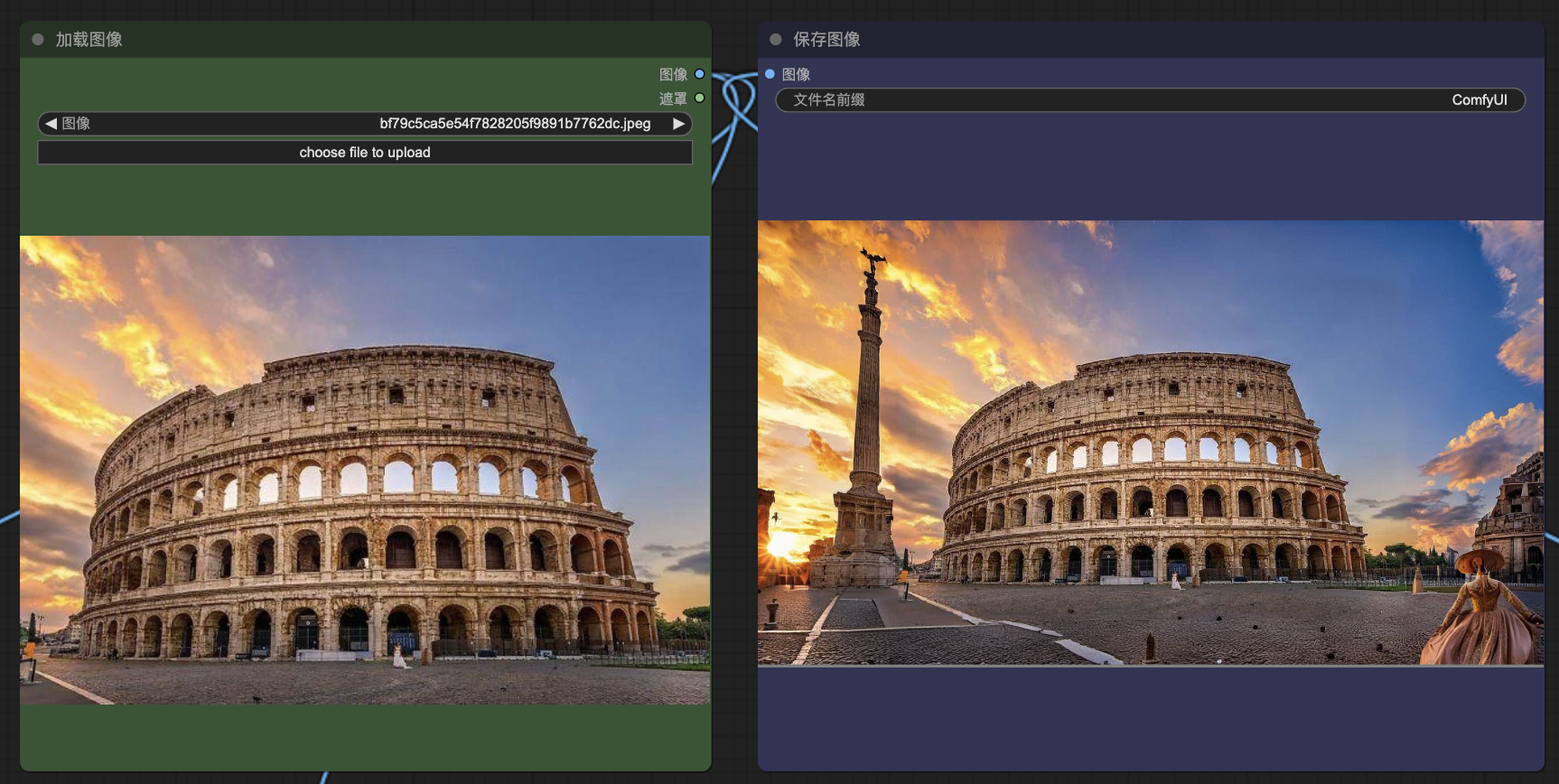
效果展示
老规矩,先看效果:


ComfyUI 环境准备
目前 ComfyUI 比较依赖显卡,要想流畅的运行各种工作流,24G显存的Nvidia显卡是标配,不过这个价格不菲,动辄过万。即使你不差钱,部署ComfyUI、安装插件、下载模型也都是坎。
手动安装
如果上边的问题都不是问题,可以看看我这篇安装教程:
https://mp.weixin.qq.com/s?__biz=MzkxNTUxNjU2OQ==&mid=2247484951&idx=1&sn=640080a52a6edaceb48fe3b888dfe82f&chksm=c15cbbe1f62b32f729b60aa6b1245002c9ac26959d8c57247674e41e05d2fe2c09639798427b#rd
使用云环境
如果你刚接触ComfyUI,或者平时只是偶尔用用,建议先在云环境体验。我最近在好易社区上传了一个ComfyUI 镜像,内置了常用的插件和模型,市面上大部分工作流都能直接跑起来,欢迎大家来试试,如有问题可以给我留言。
好易社区注册:https://www.haoee.com/?inviteCode=XLZLpI7Q,目前注册就送5元,没收到的话可联系客服解决。
1、注册后访问这个地址:https://bbs.haoee.com/postDetail/618,点击页面右下角的 “创建实例”。
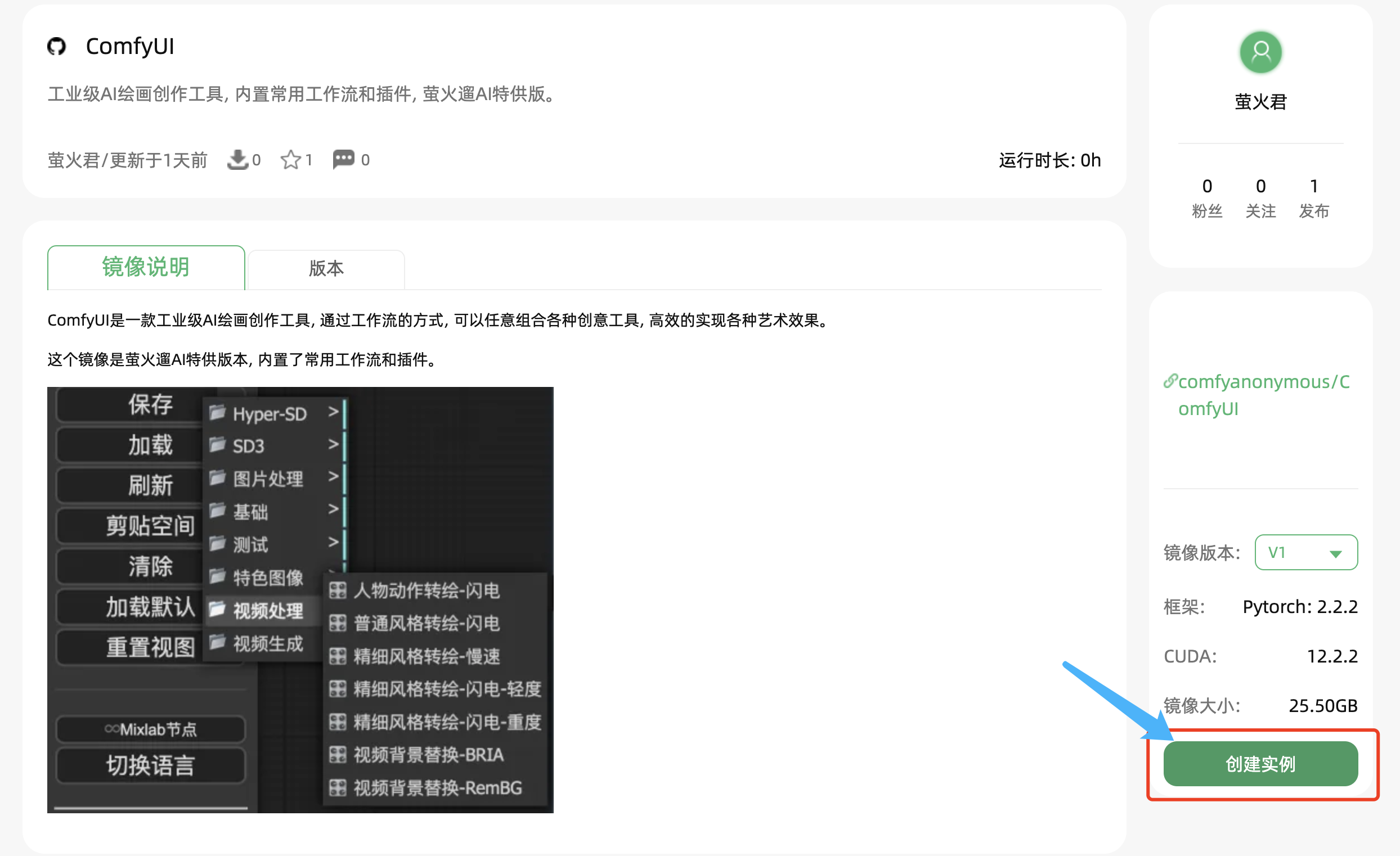
2、在容器实例页面,可以跟踪实例的状态,进行各种管理操作。

3、点击“JupyterLab”,进入程序启动器页面。

在“启动器”页面,点击双箭头按钮启动程序,待显示 http://127.0.0.1:7860 就代表启动成功了。
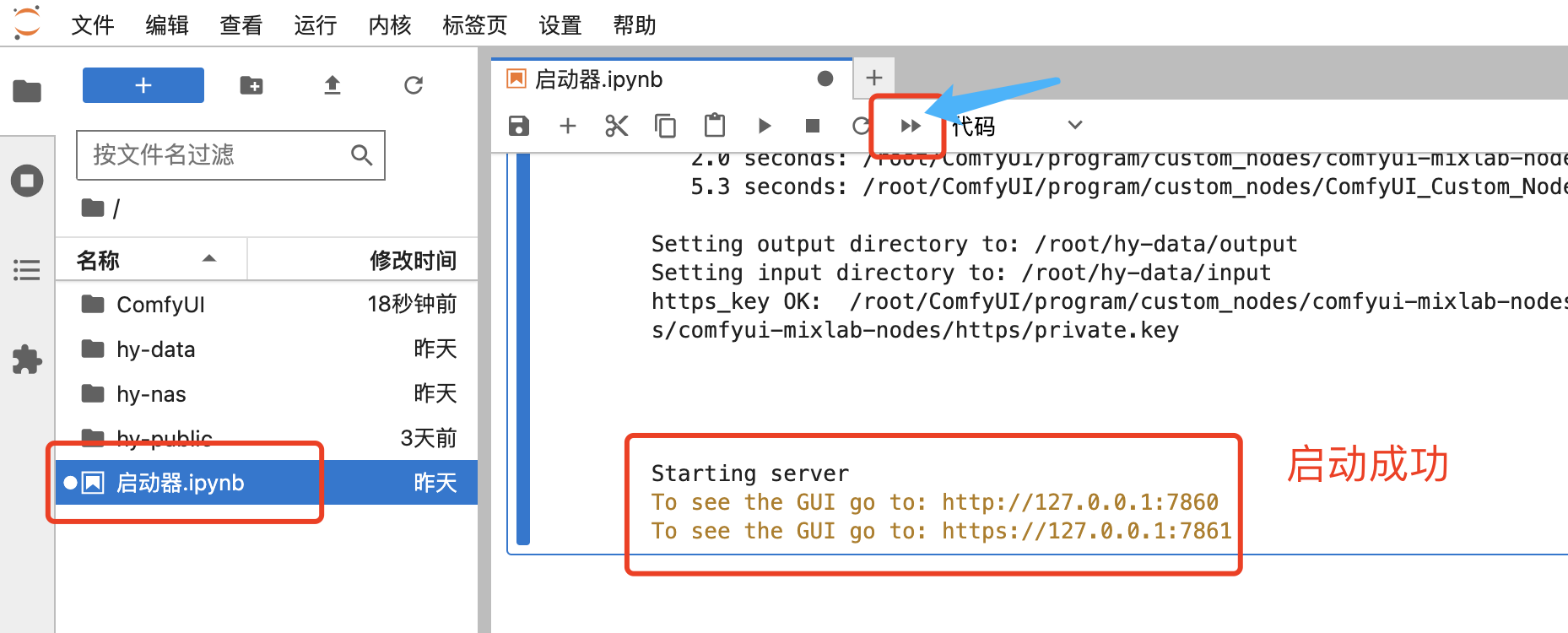
4、回到实例列表页面,点击“公网访问”,复制后在浏览器中打开。

不使用的时候,记得关机,以免继续扣费。
一键扩图工作流
这个工作流由多个部分组成,包括:提示词部分、扩图遮罩部分、IPAdapter部分和外扩重绘部分,下边将一一介绍。工作流下载见文末。
提示词部分
用来控制新图片中扩展画面的生成内容。
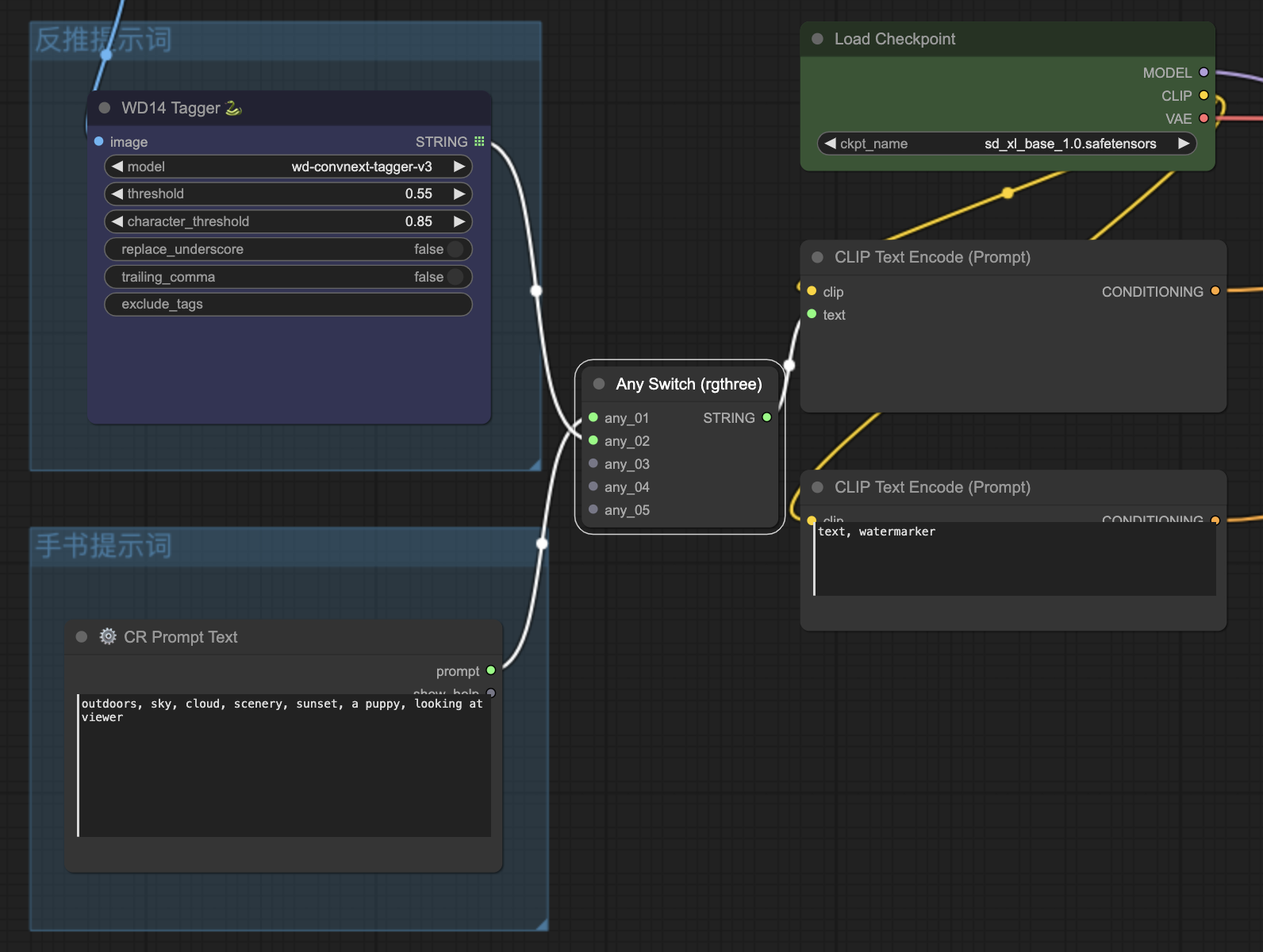
WD 14 Tagger:因为要扩图,我们需要参考原图中的内容,所以这里引入了一个反推提示词的节点:WD14 Tagger,可以生成一段描述图片元素的文本,作为扩图时的正向提示词。
CR Prompt Text:但是有时候扩图也不是完全引用原图中的元素,比如人物肖像图,就不需要在扩展的部分再画一个人出来,而是需要引入一些新的元素,所以这里也有一个手写提示词的节点。
Any Switch:不可同时使用“反推提示词”和“手写提示词”,Any Switch 保证最多只有一个提示词被使用。比如:当我们需要使用“反推示词”时,可以把“手写提示词”的分组忽略(在分组上右键选择忽略),Any Switch就会把“反推示词”生成的文本传递给后边的提示词节点,反之亦然。
CLIP Text Encode(Prompt):CLIP文本编码器,这里有两个,分别用来编码正向提示词和反向提示词。
扩图遮罩部分
用来初始化新图片中的扩展画面。

外补画板:扩图就是在原图的基础上扩展画面,外补画板用来扩展原图在各个方向上要增加的尺寸大小,根据自己的需要设置就好了。它会输出一张新图像和扩展部分的遮罩,其中的羽化用来控制遮罩边缘的模糊程度,使得扩展画面和原画面的拼接过渡更自然。
遮罩填充:这里有三种遮罩填充的方式,默认的是以灰色纯色填充,其它两种是以边界周围的颜色来填充,不过填充的算法有所不同,具体就不讲了。
遮罩模糊:这里用的是局部重绘的遮罩模糊,其在遮罩边缘的模糊效果较弱,主要控制遮罩内的的模糊程度,对于保持整体颜色不变很有帮助。
预览图像:画面扩展和遮罩填充、模糊后的效果预览。
IPAdapter部分
用来控制新图片中扩展画面的生成风格,使之更接近原图。如何模型和图片的匹配度比较高,这组节点也可以忽略。

任意切换:这里用了任意切换,使得 IPAdapter 默认参考原图片,我们也可以在这里指定一个新的参考图,代替原图片供 IPAdapter使用。
CLIP视觉加载器:加载视觉模型,用来从参考图片提取视觉特征。
IPAdapter模型加载器:加载IPAdapter模型。
应用IPAdapter:IPAdapter的主节点,IPAdapter会对模型产生影响,这里需要输入SD基础模型,经过IPAdapter处理后,再应用于SD采样。
外扩重绘部分
用来控制外扩部分的重新绘制,用到的主要插件是:https://github.com/Acly/comfyui-inpaint-nodes

VAE编码局部重绘条件:这是 Inpaint 插件提供的,输出两个Latent,分别用于采样和Fooocus, 可以减少VAE编码次数。
应用Fooocus局部重绘:使用Fooocus的局部重绘能力,可以将普通的SDXL模型转化为Inpaint模型。Fooocus是ControlNet大佬搞出来的一个简便图片生成工具。
加载Fooocus局部重绘:加载Fooocus相关修补模型。
K采样器:完成 Stable Diffusion的采样去噪工作,生成新图片。
生成图片
最后点击生成图片就可以了。
工作流下载
为了方便大家入门,我整理了一批工作流,包括基本的文生图、图生图、ControlNet的使用、图片的处理、视频的处理等等,发消息“工作流”到公/众\号“萤火遛AI”,即可领取。
另外我创建了一个AI绘画专栏,更多的工作流、模型等资源会发布在这个专栏中。加入专栏,还可以零门槛,全面系统的学习 Stable Diffusion 创作,让灵感轻松落地!如有需要请点击链接进入:https://xiaobot.net/post/03340243-9df6-4ea0-bad6-9911a5034bd6
以上就是本文的主要内容,如有问题,欢迎留言。
用好 ComfyUI:
- 首先需要对 Stable Diffusion 的基本概念有清晰的理解,熟悉 ComfyUI 的基本使用方式;
- 然后需要在实践过程中不断尝试、不断加深理解,逐步掌握各类节点的能力和使用方法,提升综合运用各类节点进行创作的能力。
我将在后续文章中持续输出 ComfyUI 的相关知识和热门作品的工作流,帮助大家更快的掌握 Stable Diffusion,创作出满足自己需求的高质量作品,感兴趣的同学请及时关注。

