
- 1Python基础:print() 与格式化输出_print格式化
- 2最详细的编译paddleOcrGPU C++版本指南(包含遇到坑的解决办法)_paddleocr c++
- 3RIS辅助毫米波系统中基于压缩感知的信道估计_ris信道估计
- 4本地部署 Llama3 – 8B/70B 大模型!_llama3 70b本地部署显存要求
- 5github_gut hub
- 6浅谈linux关机_linux安全关机
- 7大规模端云协同智能计算(大小模型端云协同联合学习)_大小模型协同
- 8python爬虫之MongoDB——MongoDB与python的交互_mongodb交互抓包
- 9【传奇服务器爱好者】-IGE引擎M2-用户游戏相关命令_传奇m2命令都有什么
- 10安利 10 个 Intellij IDEA 实用插件
没想到我还要求着AI动起来(Stable Diffusion进阶篇:ComfyUI SVD图片转视频)_image only checkpoint loader
赞
踩
前言
在上一篇文章中讲到了如何下载安装ComfyUI,目的就是为了今天的图片转视频,毕竟上次的Gen2让我的钱包不是很满意。
当然如果完全没接触过ComfyUI或者WebUI看这期视频跟着操作也是可以的,前提是得先下载安装好
本文涉及的工作流和插件,需要的朋友请扫描免费获取哦

如果是已经接触过WebUI的小伙伴们来说这篇文章还是很好上手的。
在上篇文章的结尾我简单地操作了一遍ComfyUI并且用动图演示了一下:
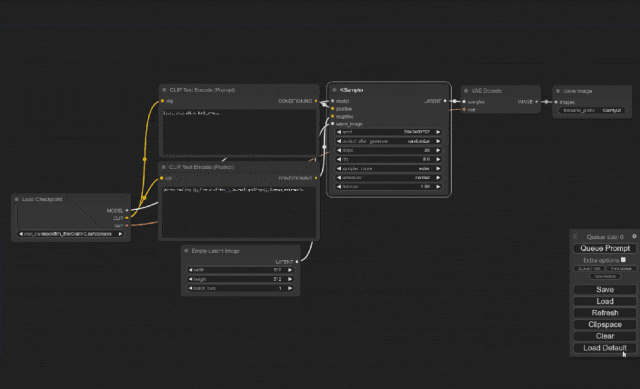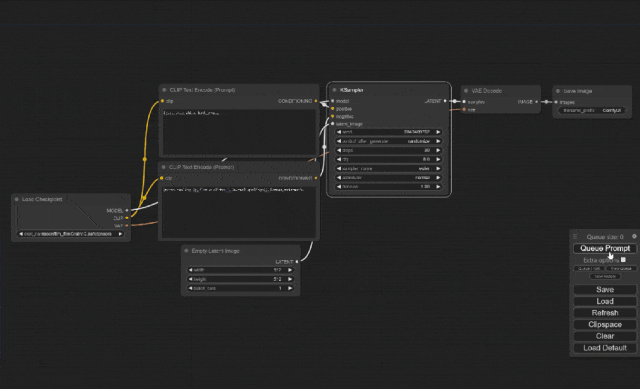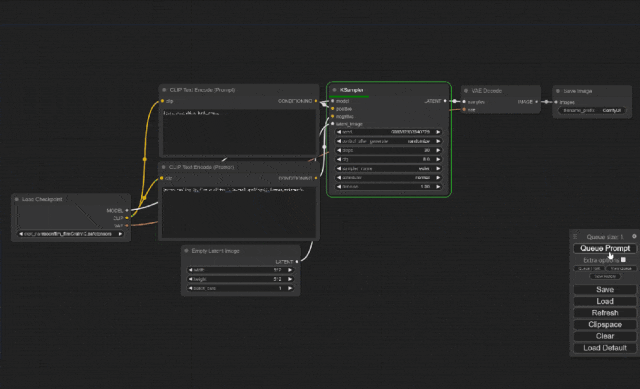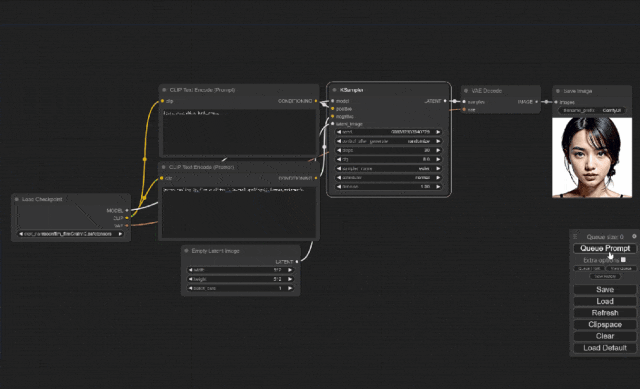
这个就是ComfyUI的一个完整的工作流程,像我这样的比较懒的可能会觉得要是想增加其他功能要连线什么的好麻烦,这个时候有一个简单的方法。
打开ComfyUI的官方Github链接:
https://github.com/comfyanonymous/ComfyUI
选择这个ComfyUI Examples,打开之后会有很多工作流程:
然后点击进入,例如我点开这个3D,就会进入到这样的页面
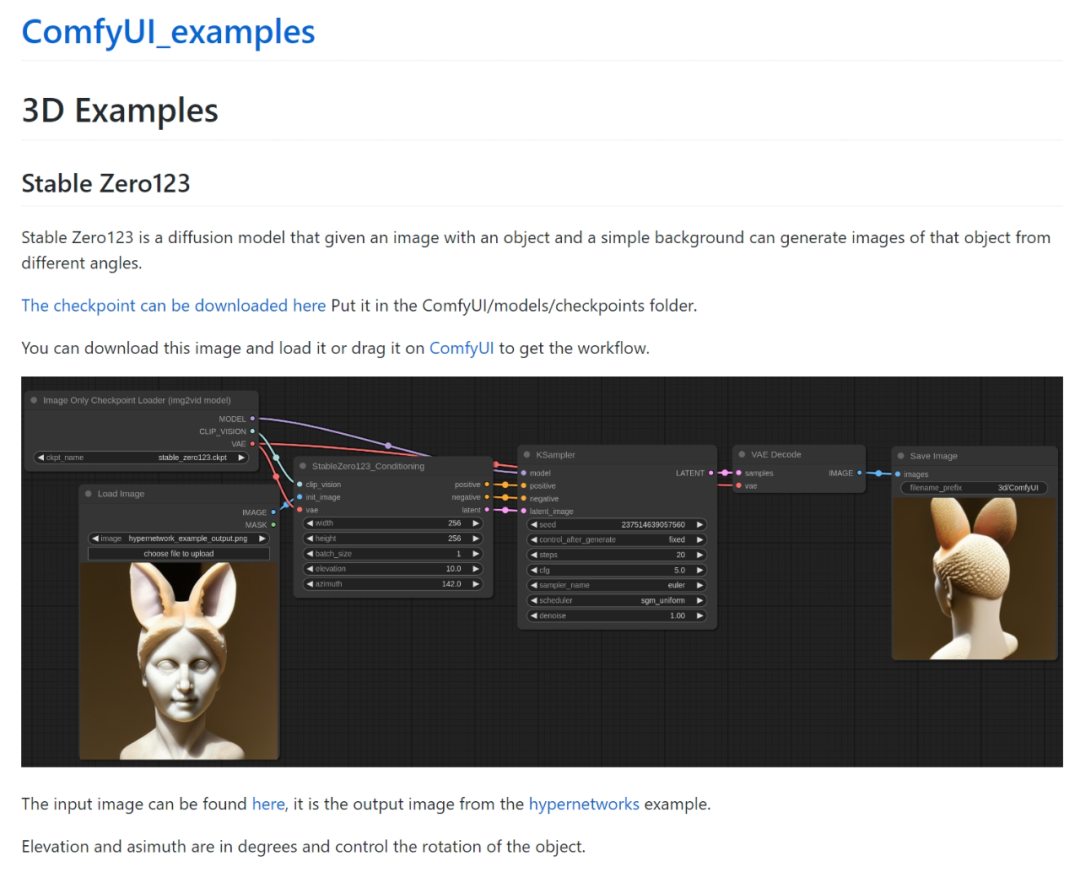
然后将这张图片保存到本地,之后只需要将图片拖到ComfyUI界面中,系统就会自动识别到这个工作流程并更新。
怎么样,是不是超级无敌方便,同时也可以根据自己的喜好对工作流进行微调,之后记得点击右侧的Save保存即可,这样也方便后续的导入使用。
好了,简单的介绍学习就到这里,让我们来进入今天的正题吧!

SVD的准备工作
虽然之前可能讲过但是这里再复习一次,SVD全称是Stable Video Diffusion稳定视频扩散模型,是由Stabilityai公司开源发布的图像转视频的潜在扩散模型。
从结果上看Svd的生成效果略优于pika和runway(Gen2),同时SVD是免费开源的模型。
免费的东西谁不喜欢呢?只需要在Hugging face上下载svd模型就可以。
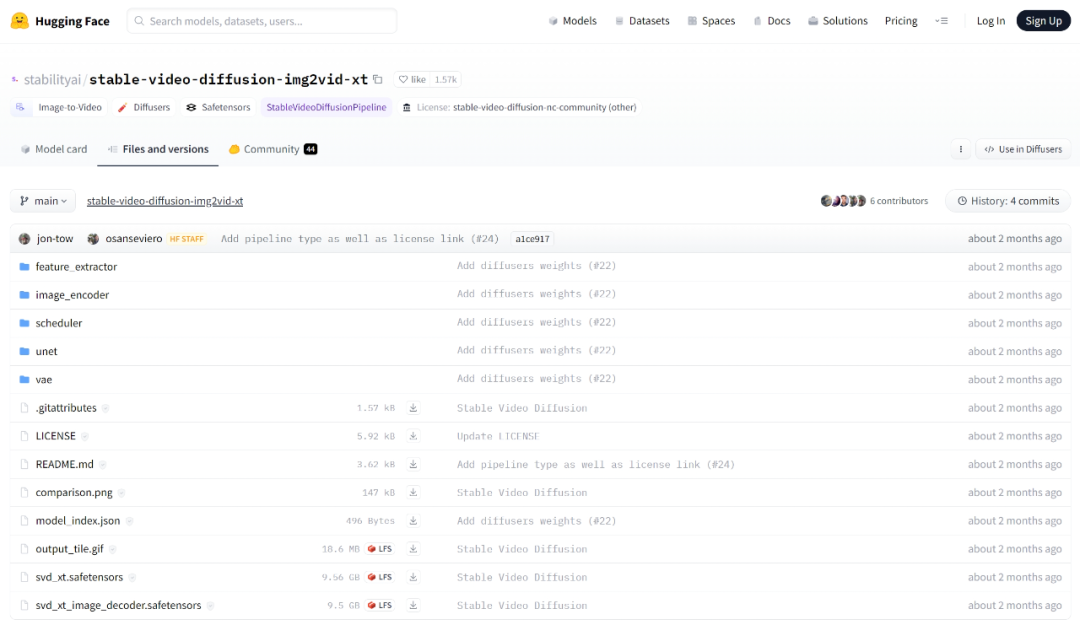
这里有两个模型,分别是svd模型和svd xt模型,之前下载过的小伙伴可以不需要再下载。
这两个模型的区别在于svd模型可以生成14帧的动画而svd xt可以生成25帧的动画,如果设备比较不错例如3060以上性能的可以下载svd xt试试。
除此之外还需要安装一个节点软件:ComfyUI-VideoHelperSuite

如果之前学过animatediff就应该下载过,这个插件在工作流中需要用到video combine模块,这模块可以方便保存和导出不同格式的视频。
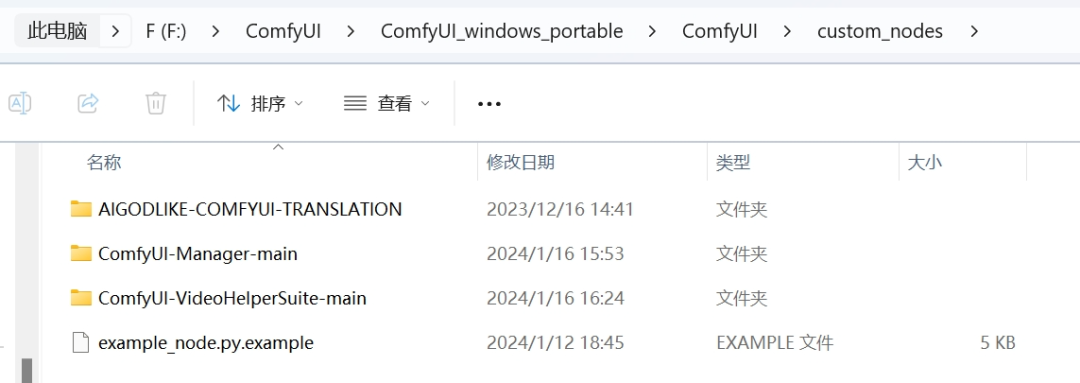
这些节点软件下载好后都要解压放在这个custom_nodes文件夹中:
**根目录:\ComfyUI\ComfyUI_windows_portable\ComfyUI\custom_nodes
**
准备完毕之后就正式开始今天的学习啦!
**SVD的使用(逐步操作)
**
第一步:
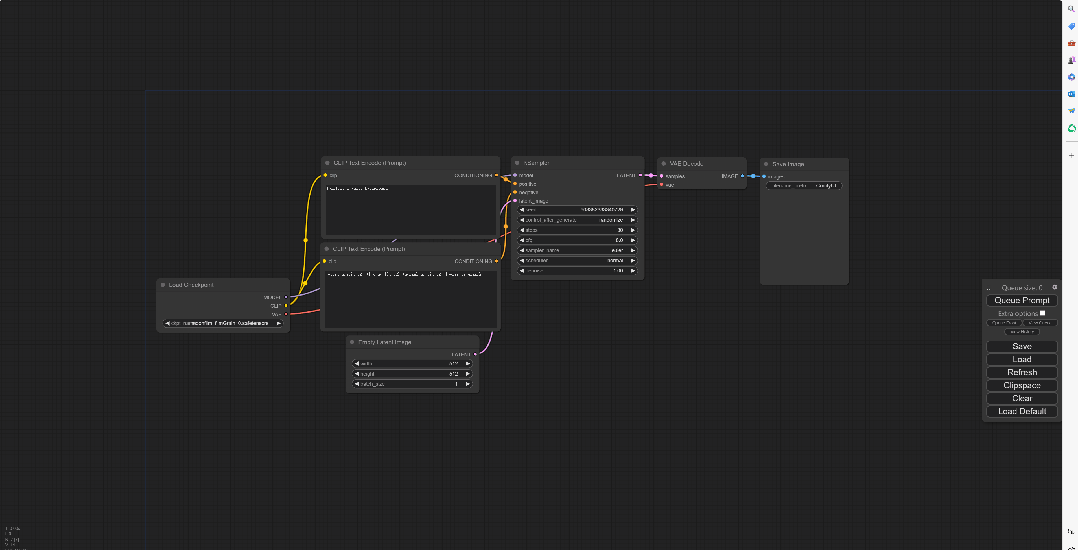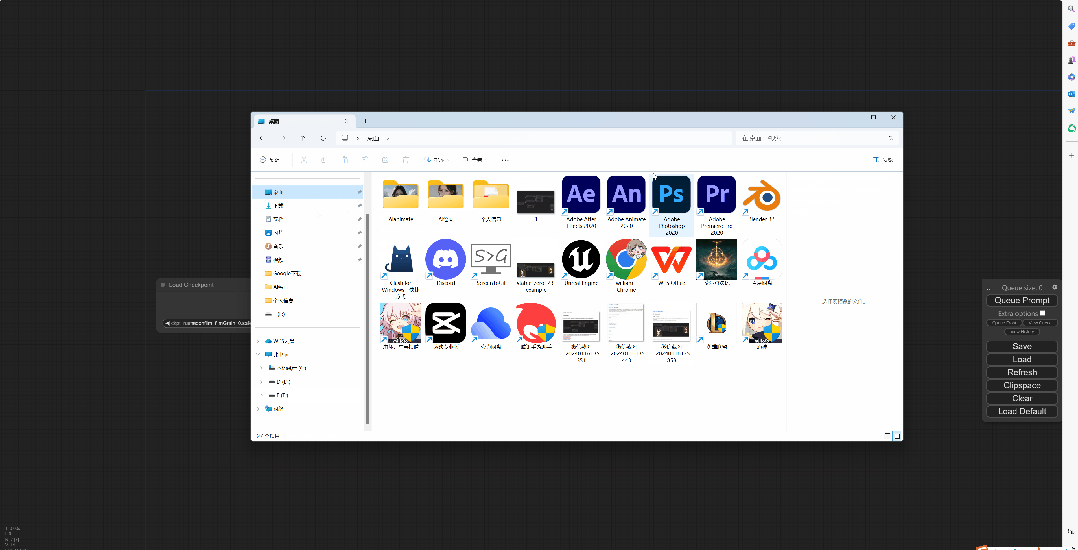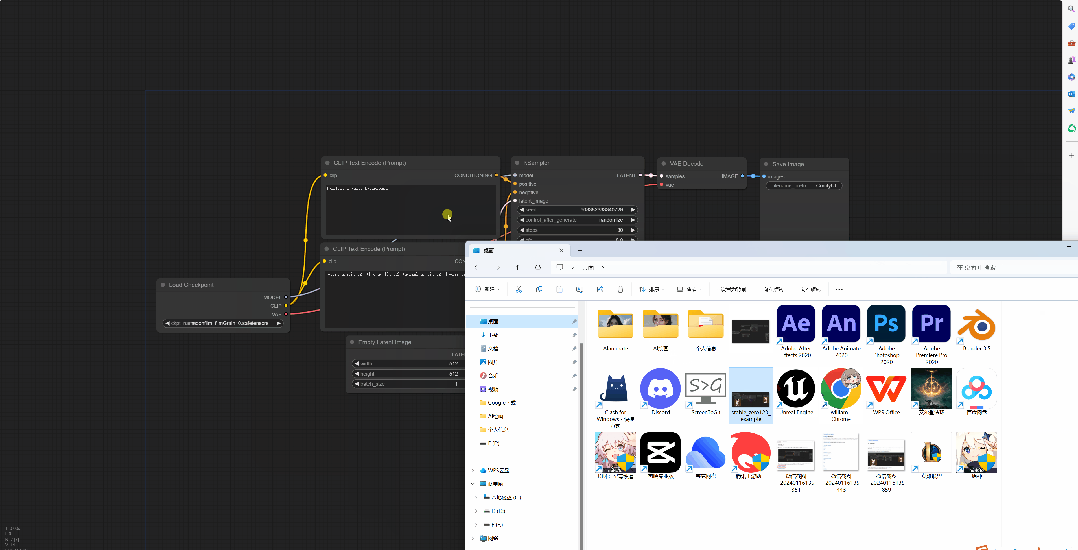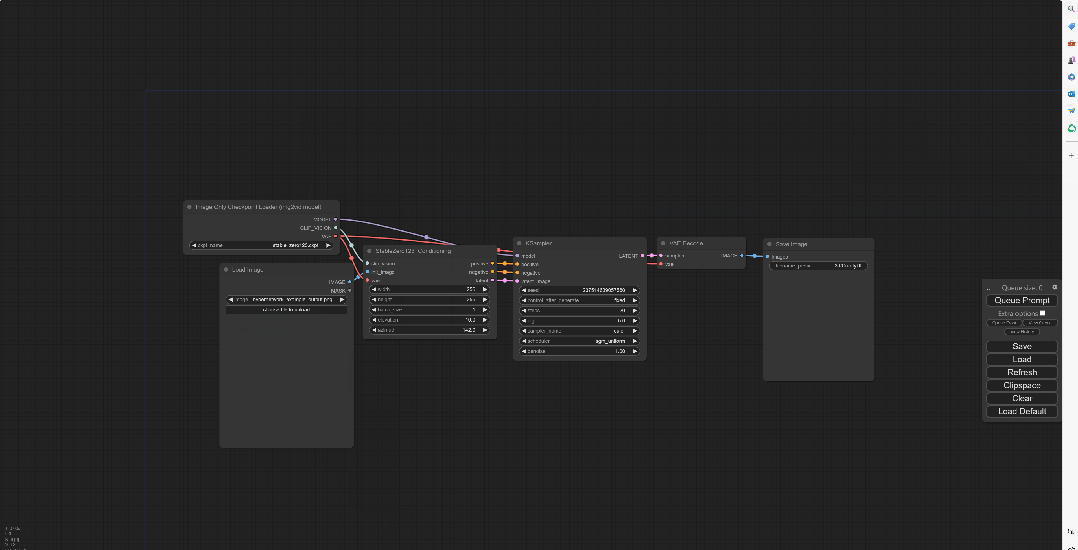
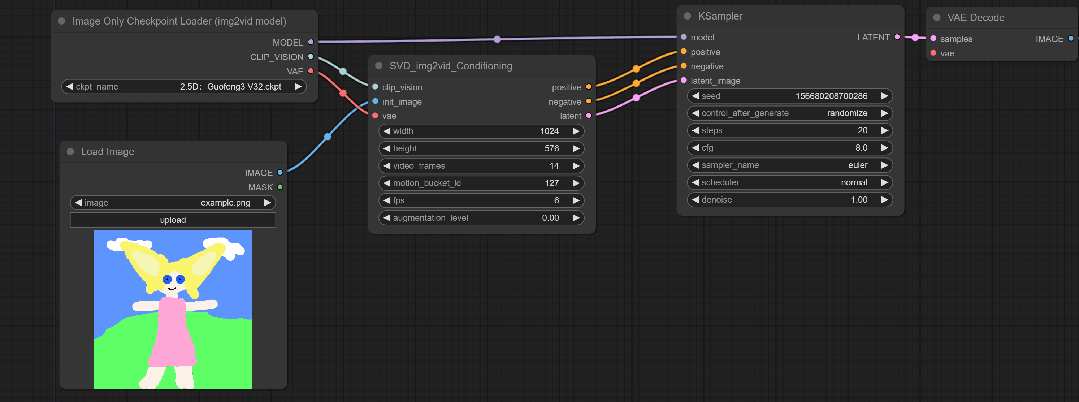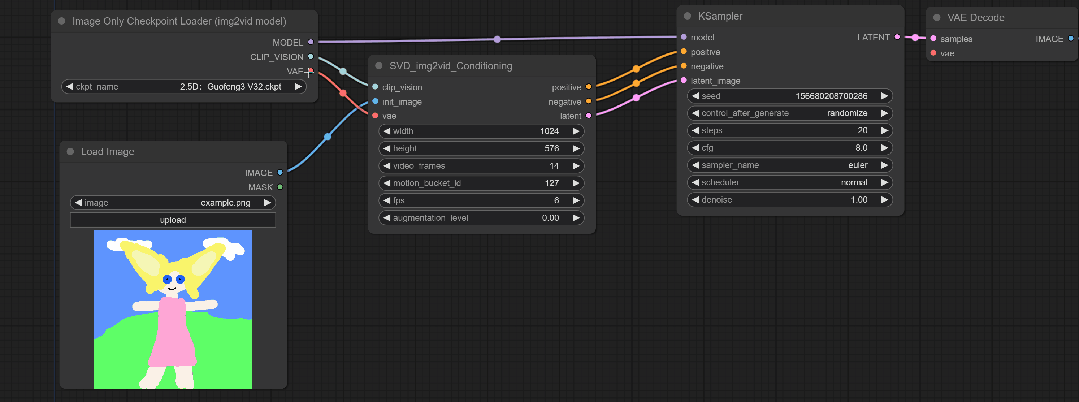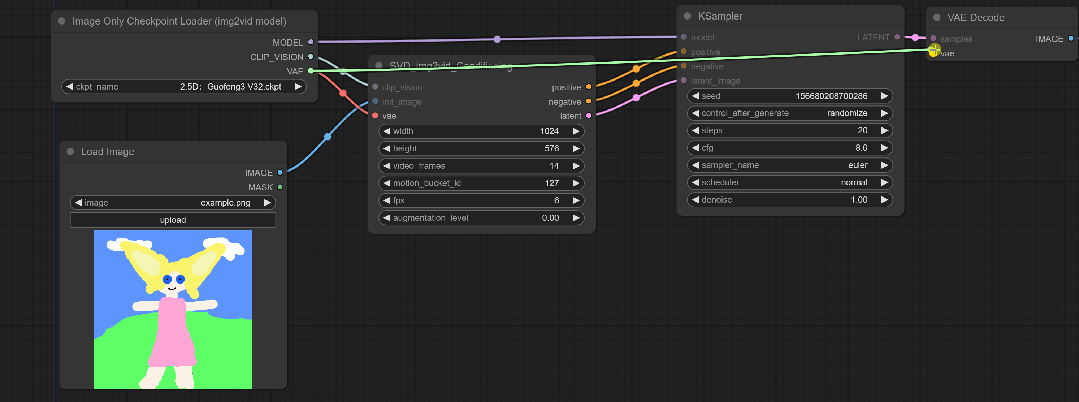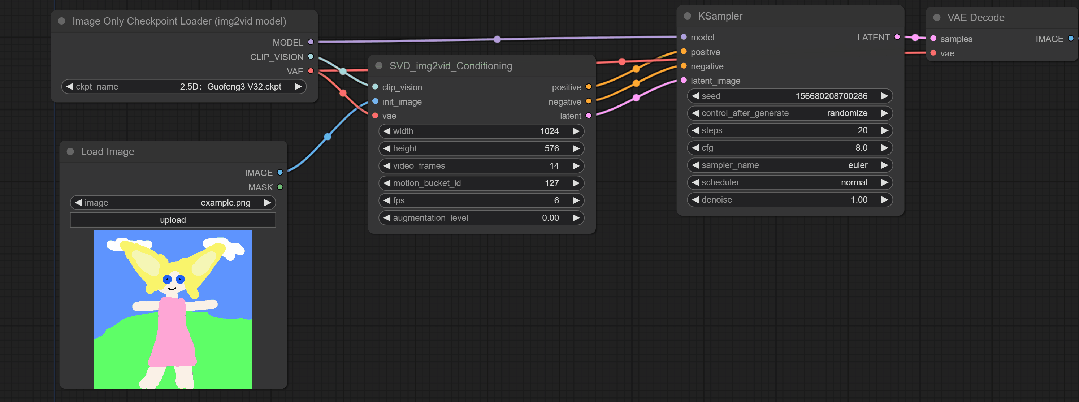
打开ComfyUI保持默认的工作流,然后在空白处鼠标左键双击输入SVD,然后就会弹出SVD_imag2vid_Conditioning

这个模块的功能是以SVD图片转视频为条件
第二步:
由于SVD_imag2vid_Conditioning上并没有可以连接Checkpoint的地方,所以要点击Clip_vision往左拖拽,选择Image Only Checkpoint Loader(imag2vid model)
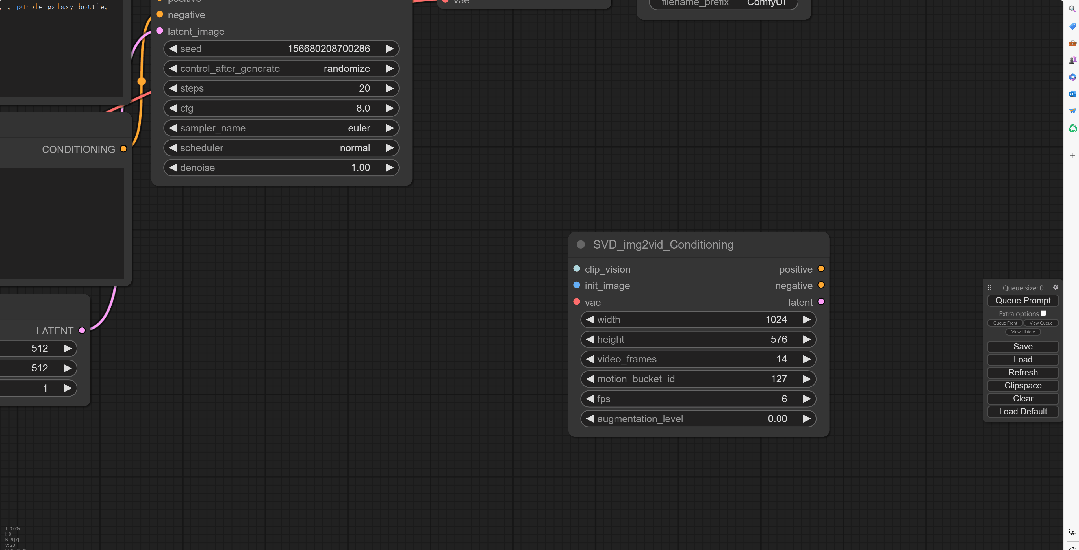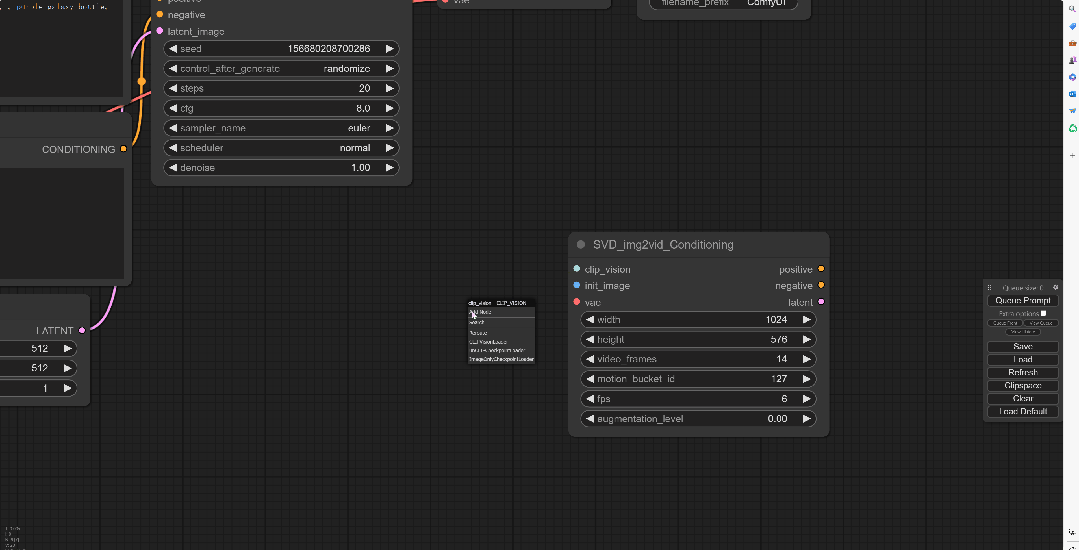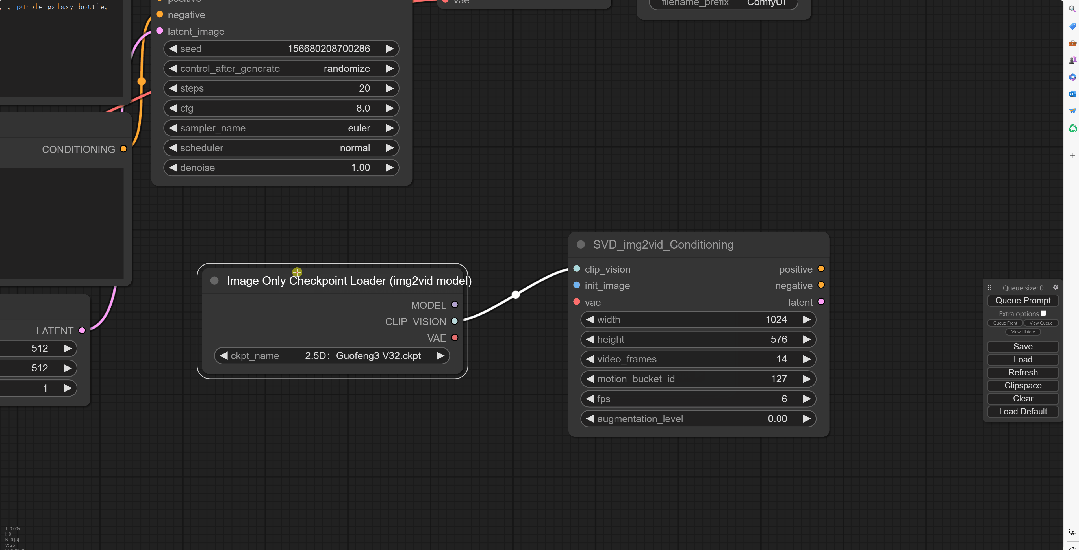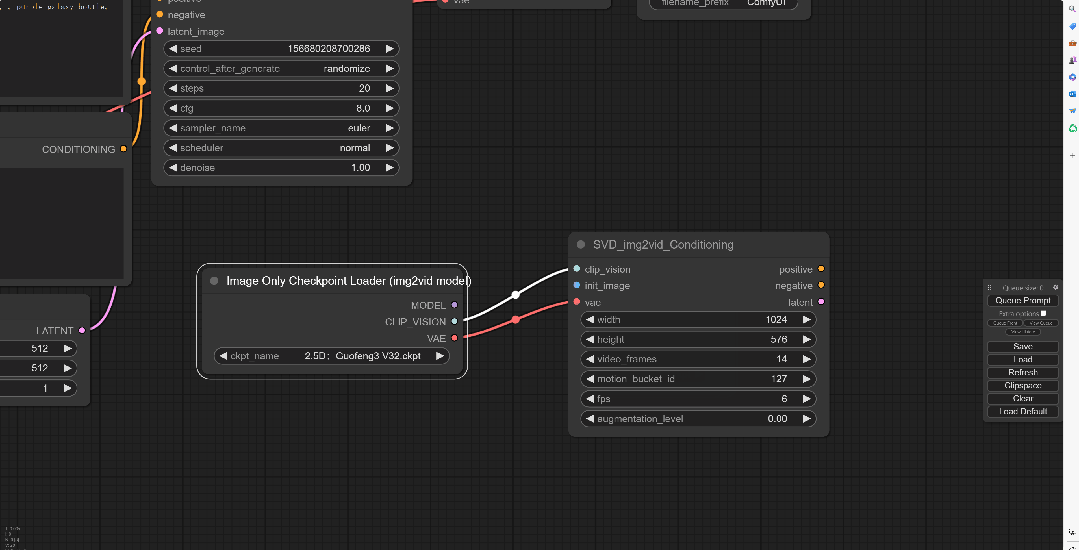
并且将模型上的VAE节点连接回SVD的vae上,这样Clip bision节点就连接好了。

接下来就把红色框内的模块都删除掉,用不着了
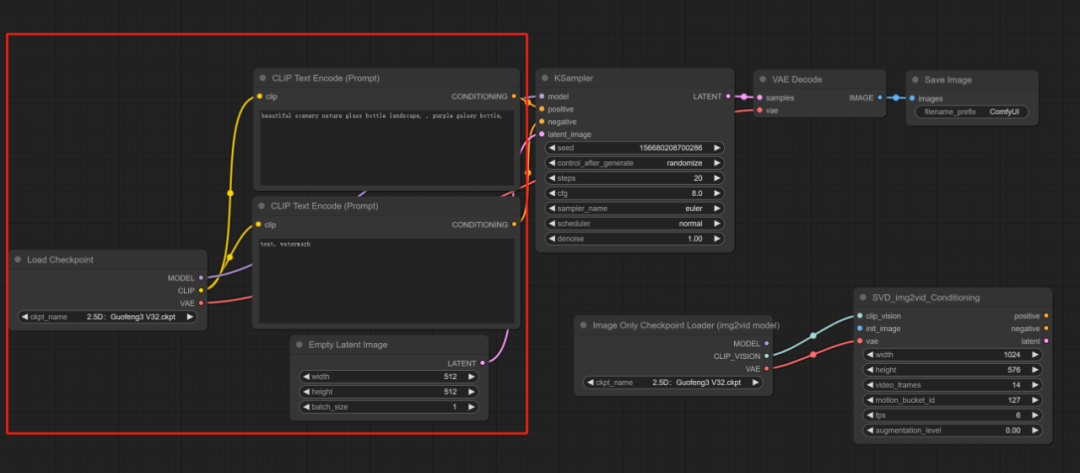
第三步:
在空白处鼠标左键双击,搜LoadIMAGE,这样得到的模块可以将用来转为视频的图片加载进来。简单来说就是用来放想要动起来的图片的。
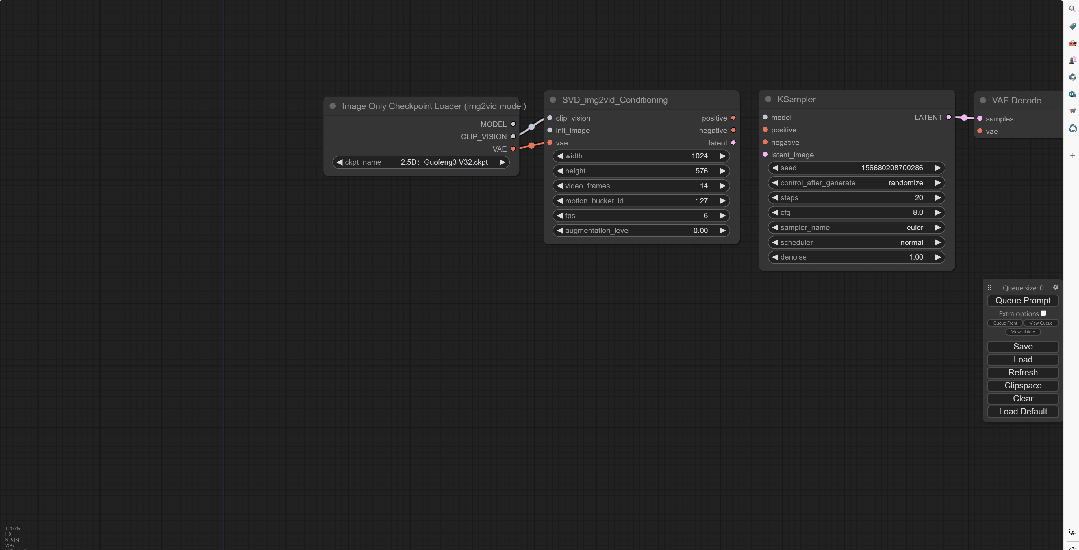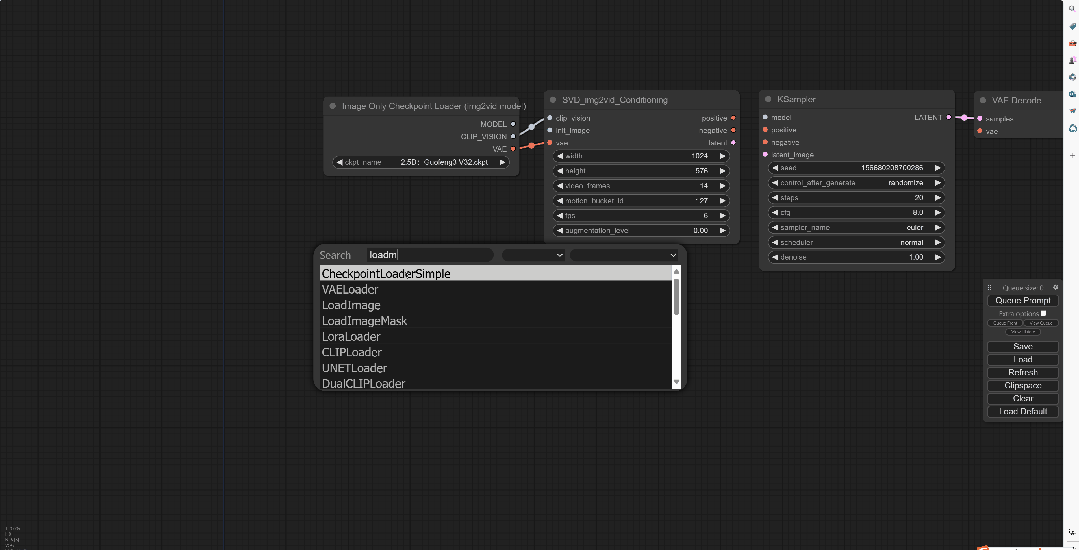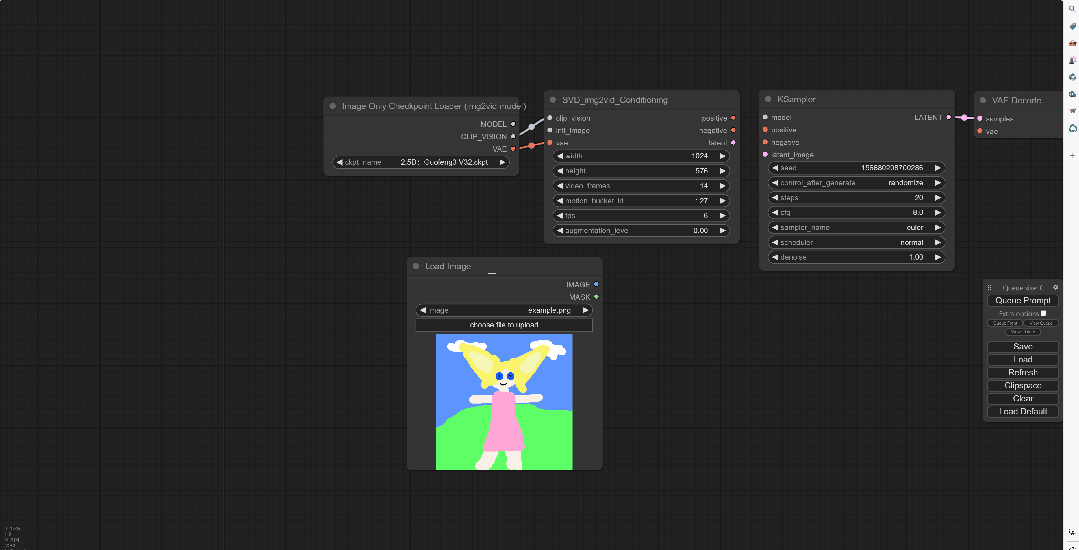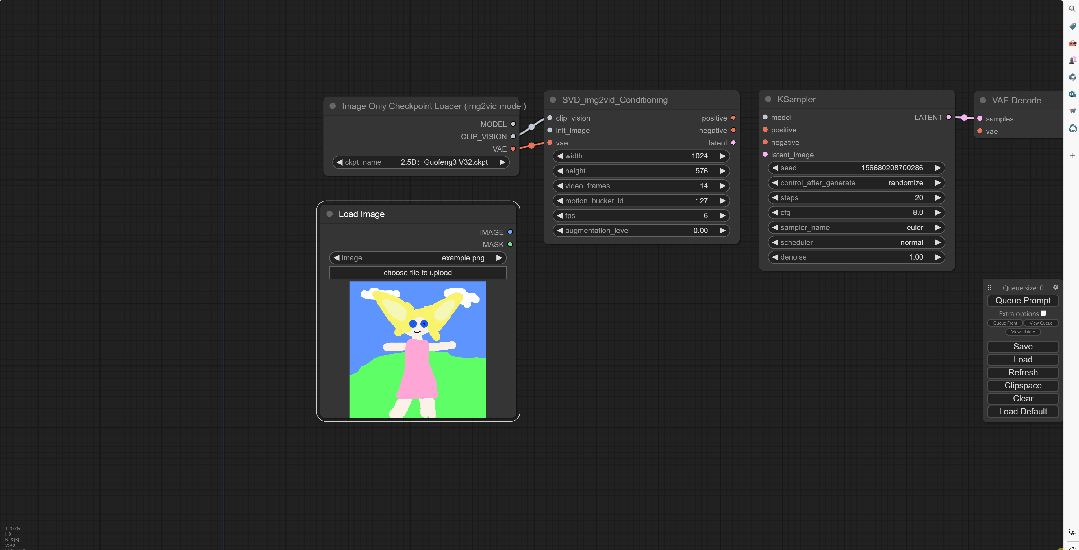
并且将图片节点连接到int_image上
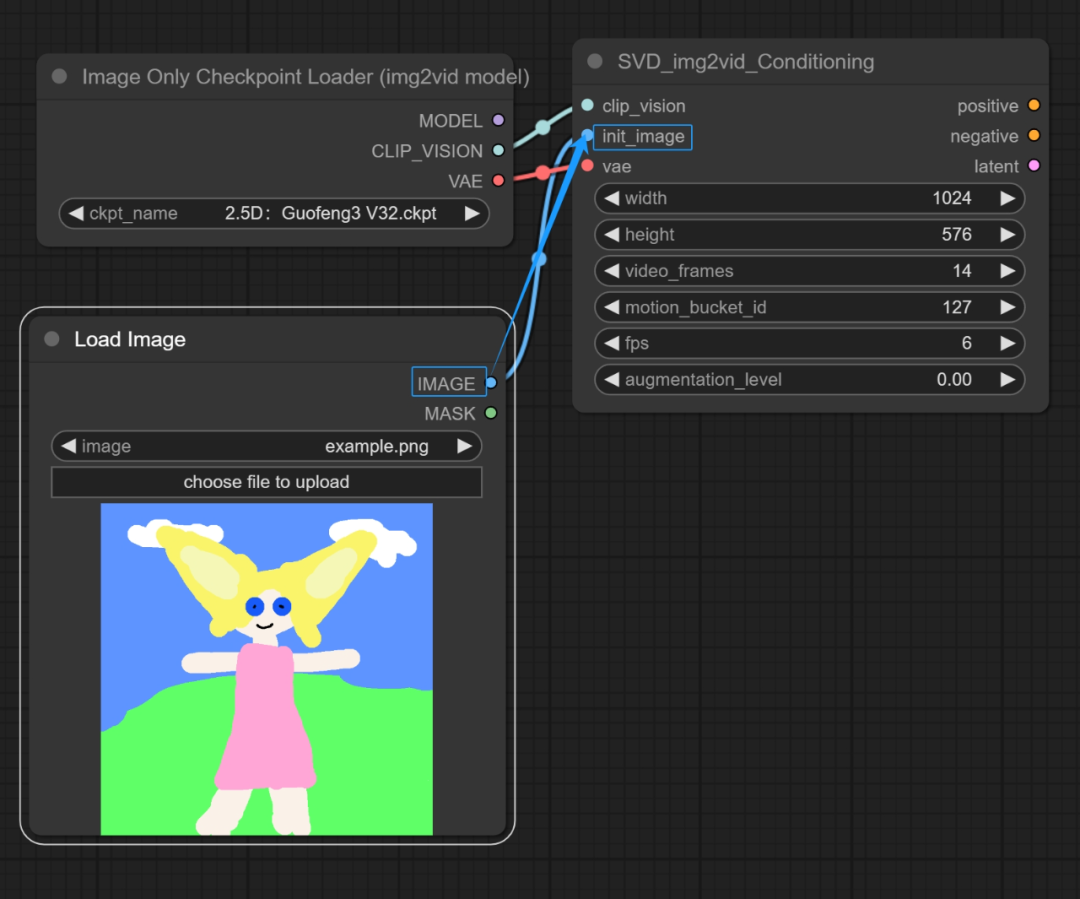
第四步:
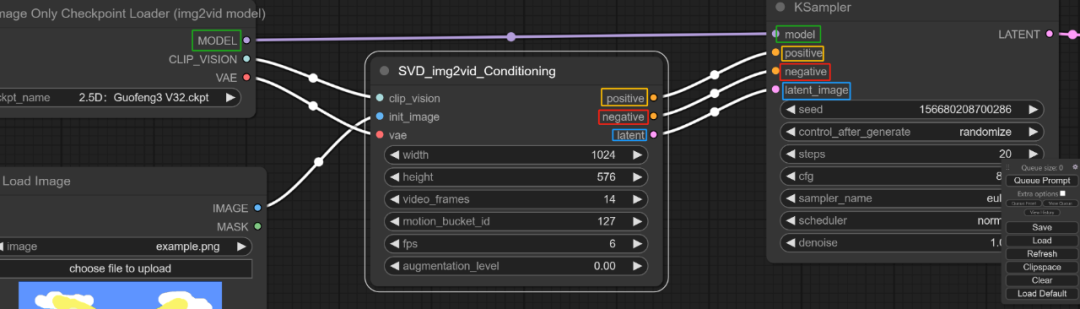
将前两个模块分别连接到KSampler上,分别对应正提示词、负提示词、潜空间和模型。

**第五步(接下来我的电脑出现了点问题,部分演示暂时用教程视频截图替代):
**
鼠标左键双击空白处,输入VideoCombine得到该节点。
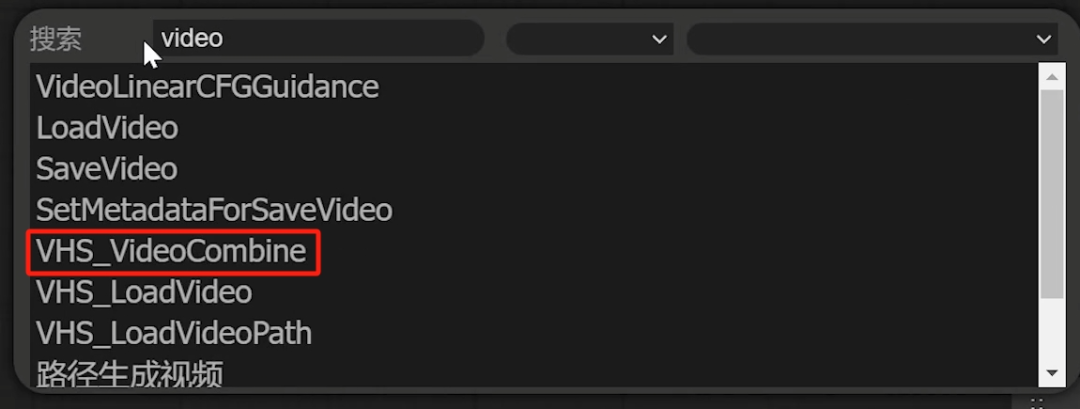
这个节点是需要下载了先前的VideoHelperSuite才有,然后将VAE与该节点进行连接,目的是为了能够更好地把输出的图片序列转换为视频。

与此同时将filename_prefix也就是前缀改为svd,format视频格式改为video/h264-mp4

第六步:
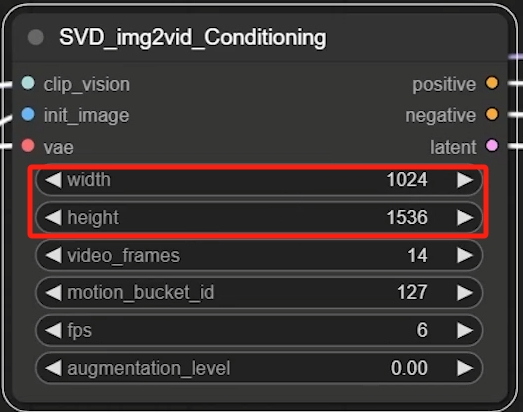
在鼠标右键查看图像属性后,将对应的原图像宽高输入进SVD_img2vid_Conditioning中
然后再将一条VAE的线从Image Only Checkpoint Loader连接到VAE Decode

第七步:
这个时候其实已经可以生成动图了,但是在这个情况下生成的结果颜色差异会过大画面崩坏。
究其原因是因为KSample上的CFG数值为8,在文生图的情况下CFG的数值为5-8,而使用SVD的时候建议数值为1-3区间。
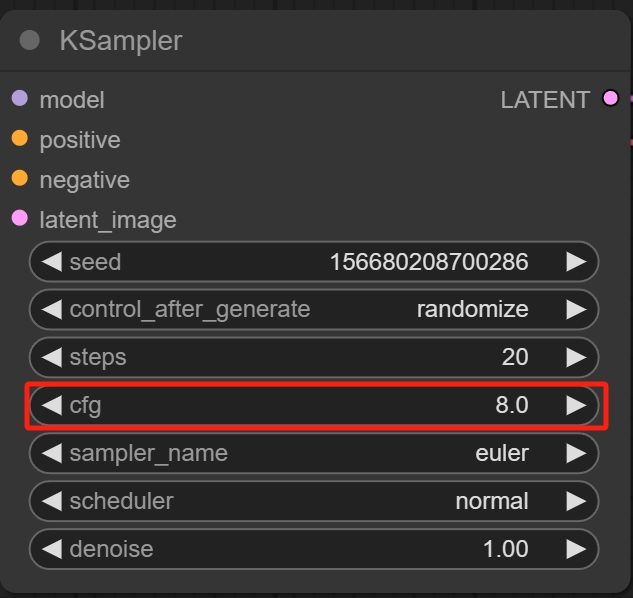
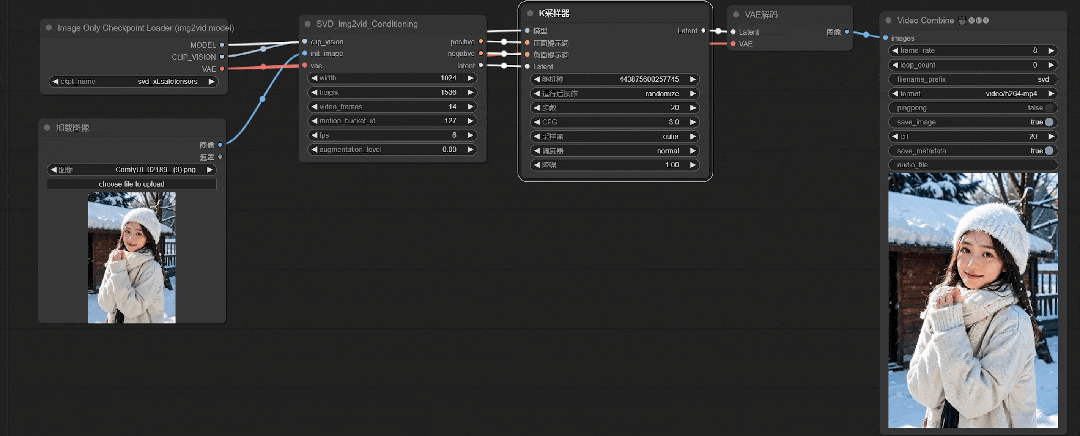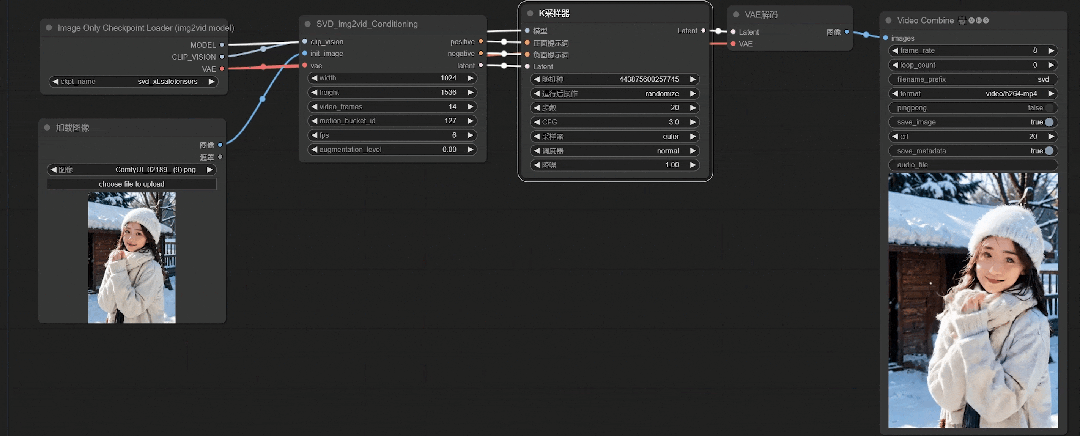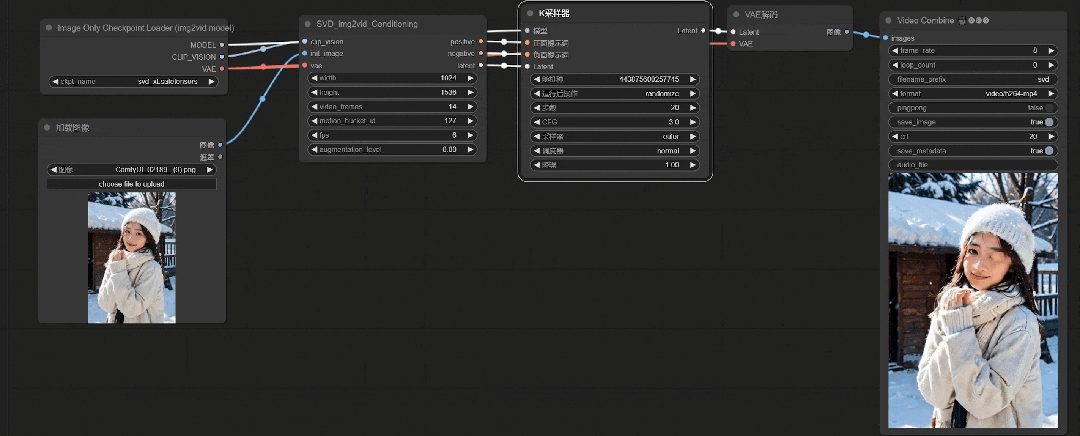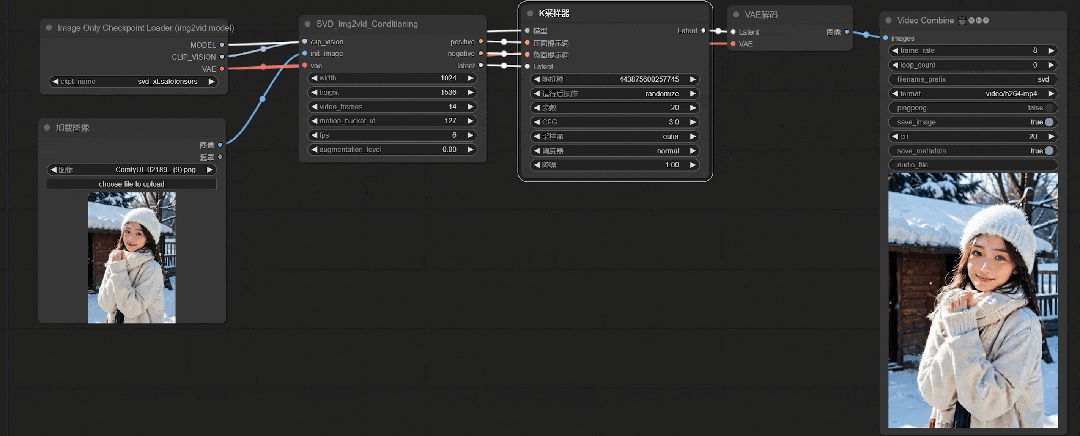
当CFG越接近1,其初始图像对画面的控制力就越小。但是因为这里用的初始图像是人物,所以将CFG值改为3最好。
这样图像效果看着还可以(取自原视频教程演示)
**第八步:**
虽然看着已经差不多了,但是需要一些操作。这里空白处双击鼠标右键,输入VideoLinearCFGGuidance。
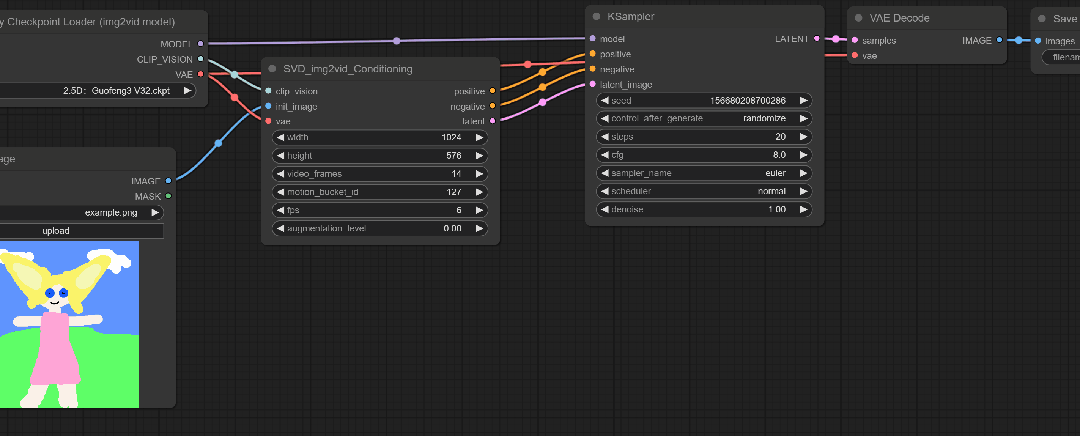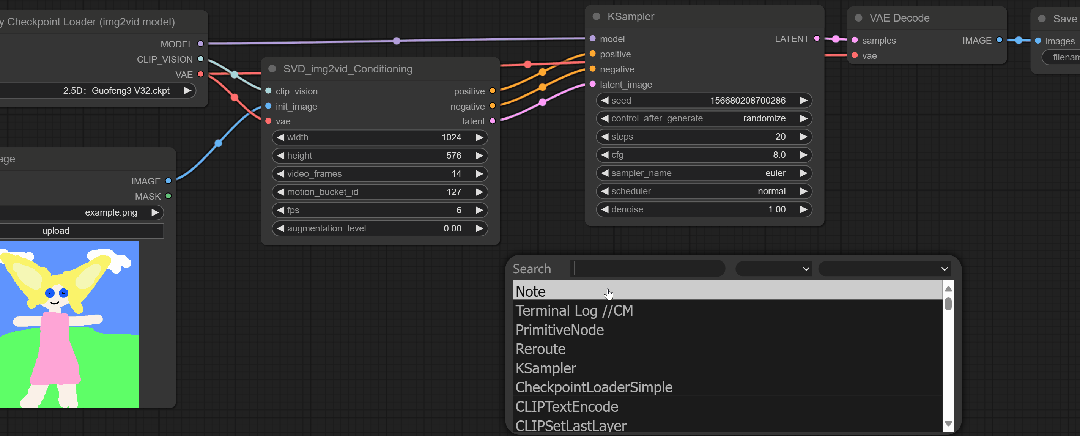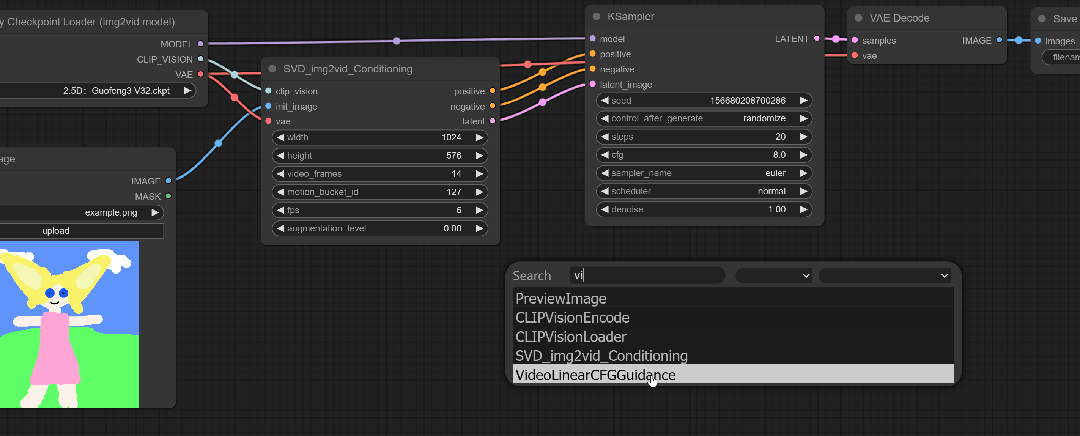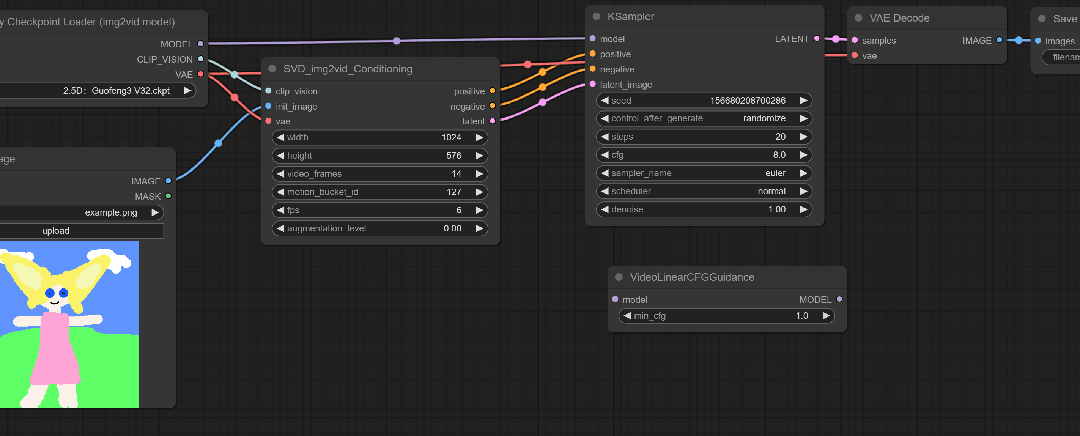
这个模块通过跨帧缩放CFG来进行视频采样,听着有点像之前的Ebsynth。
根据原教程来说:距离初始图像距离较远的帧会逐渐接受较高的CFG值。
将这个模块与SVD和KSample连接起来
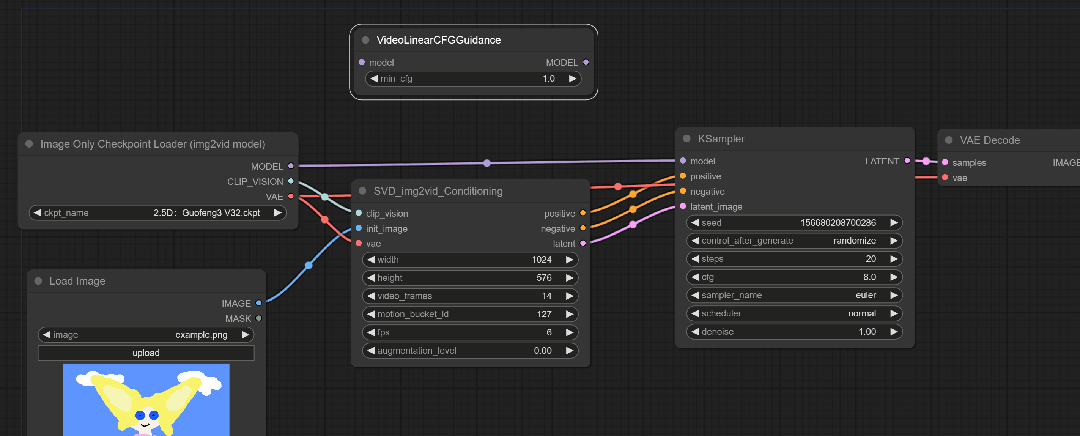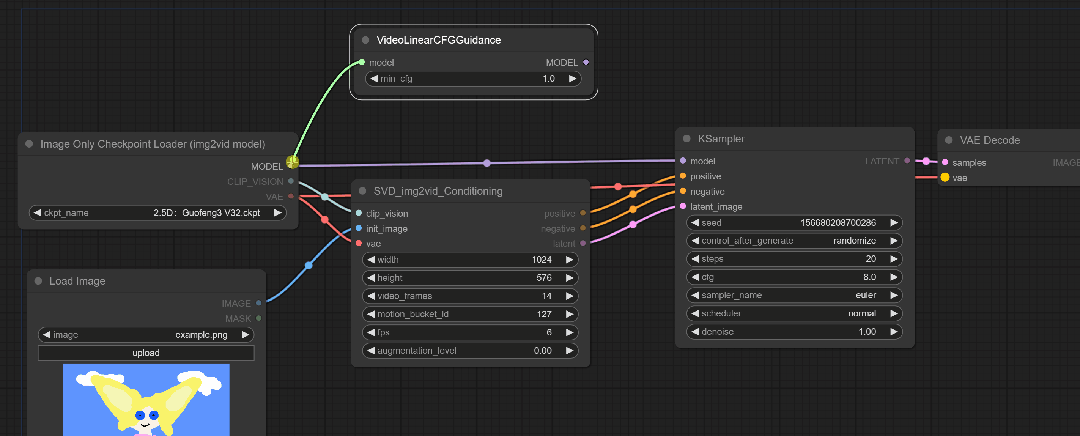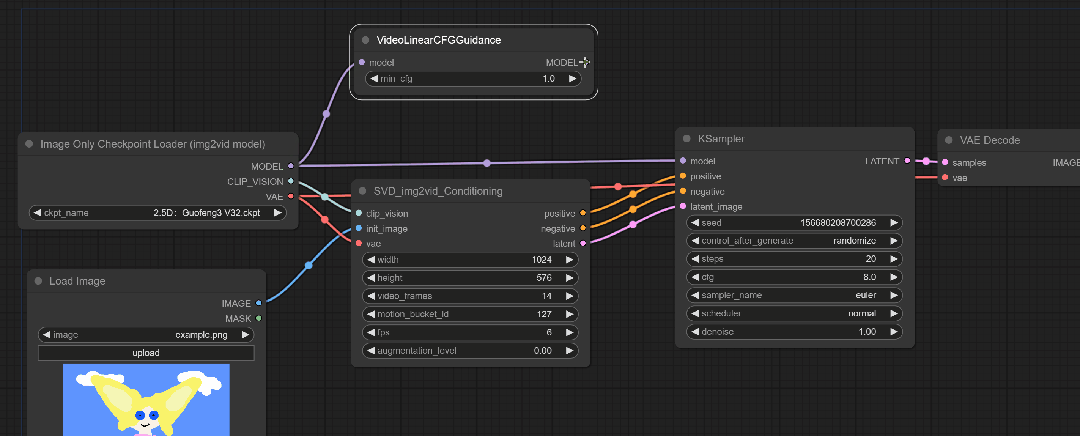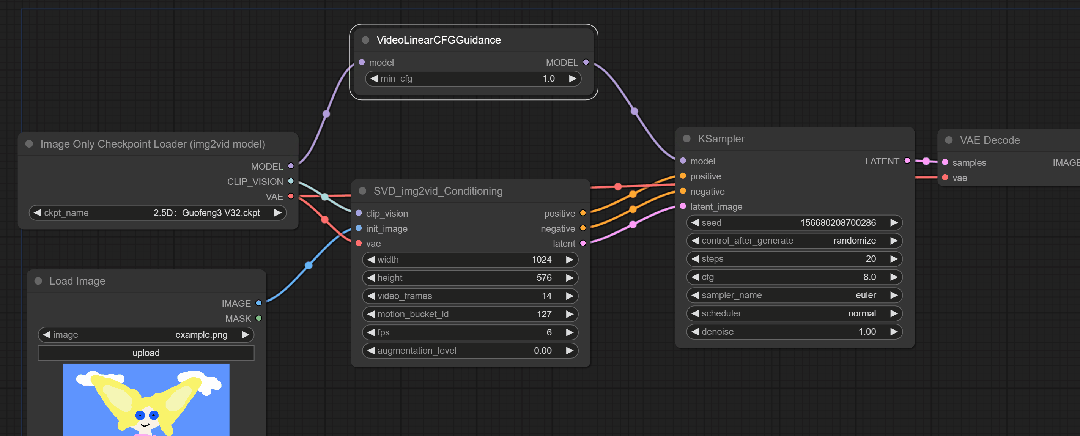
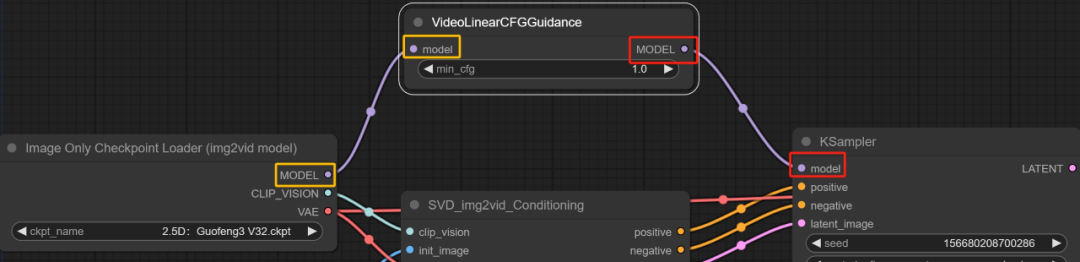
再次生成试试看:
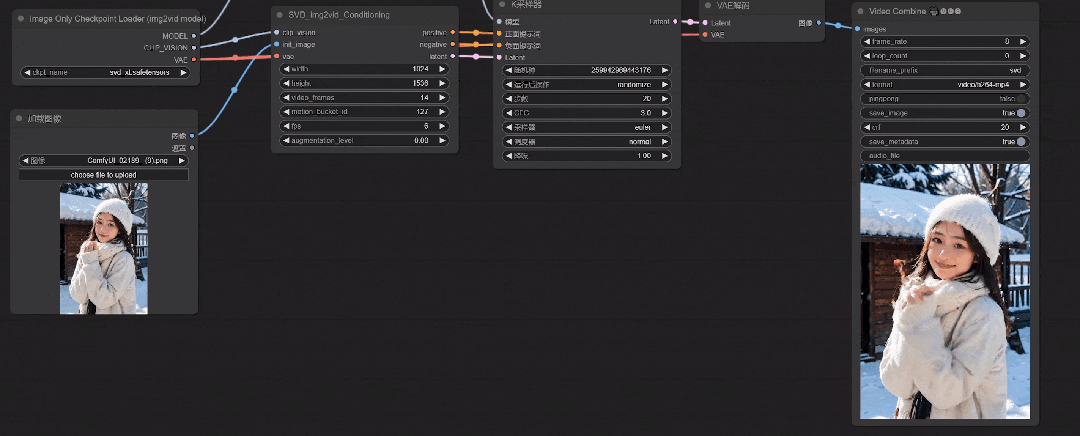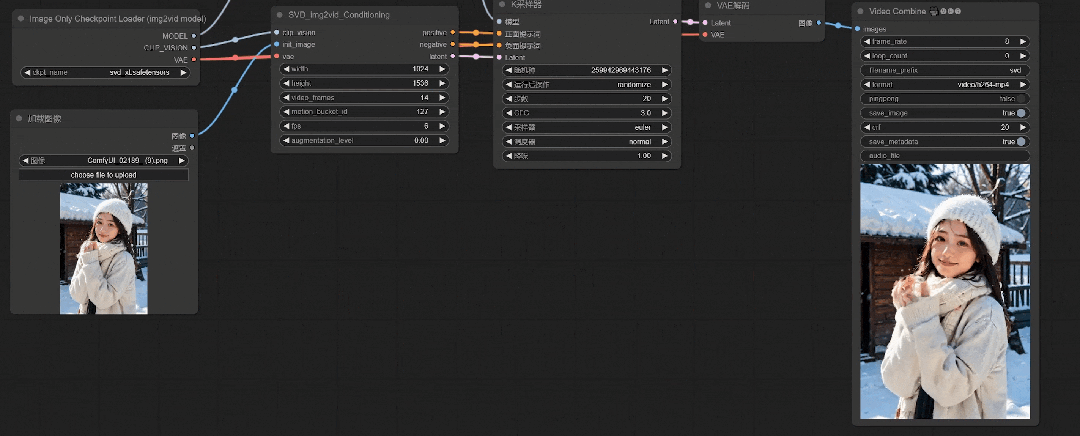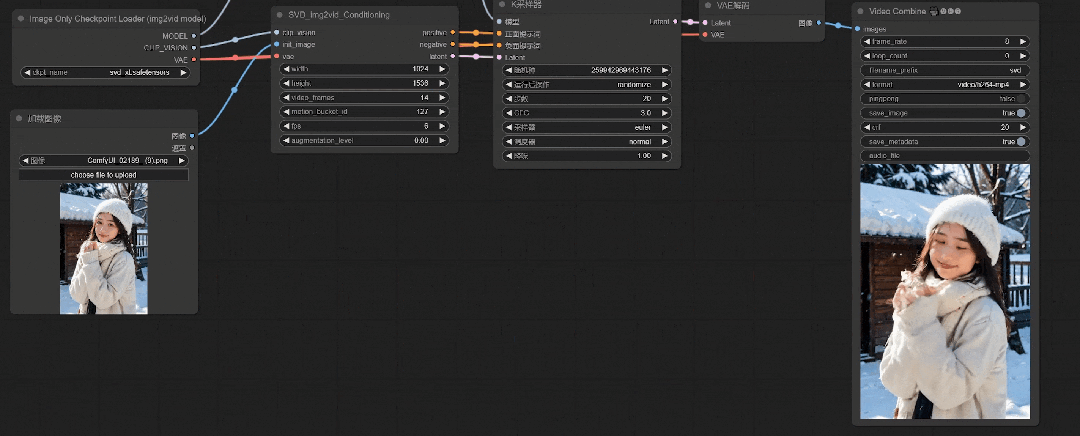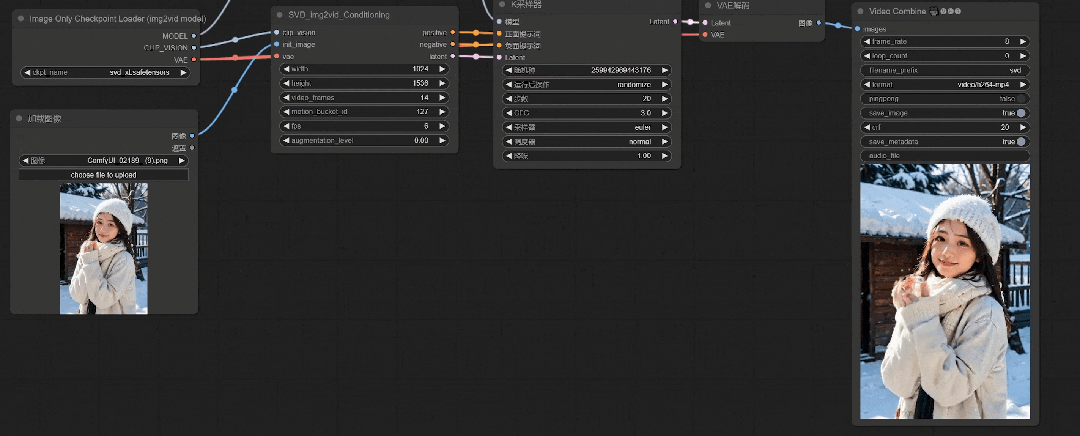
可以看到人物的动作更丰富了些,但是由于初始CFG值较低,肢体和面部会有比较明显的崩坏感。
第八步:
接下来就需要到SVD中进行参数调整
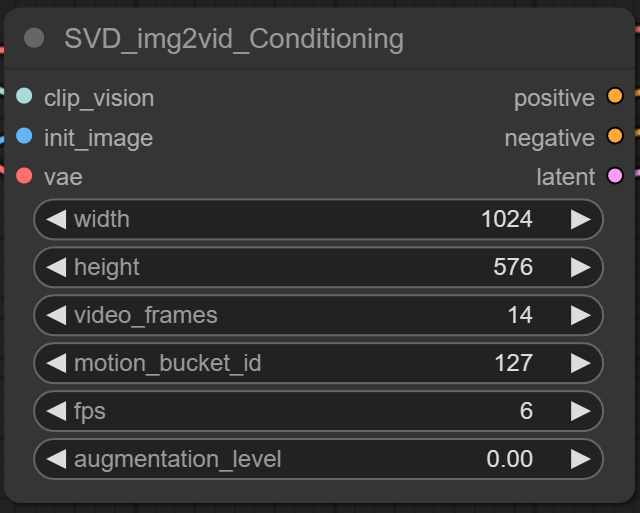
这个width和height很好理解,就是生成视频的宽高,建议尺寸在1500以内。
video_frames就是生成的运动帧数,根据硬件设备条件设置,一般推荐在25帧以内。
motion_bucket_id数值越高,输出画面中的运动幅度就越大。一般数值在100以内,最多不超过200。
FPS(frames per second)就很好理解了,就是每秒的帧数,在这里一般为6或者8。
agumentation_level是指添加到输入图像的噪声量,较高的噪声会降低与输入图像的相似度,一般在0.1以内最多不超过0.5
将参数调整后再试一次:
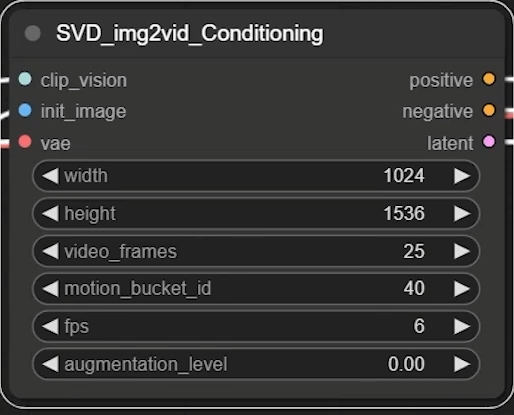

适当地增加Augmentation_level并不会使得画面崩坏,反而使得人物动作更加自然。
在视频制作中CFG、Motion_bucket_id和augmentation_level都是需要进行动态调整的,不同的画面主体需要不同的参数,实在不知道要怎么做的可以使用下面的官方推荐参数:
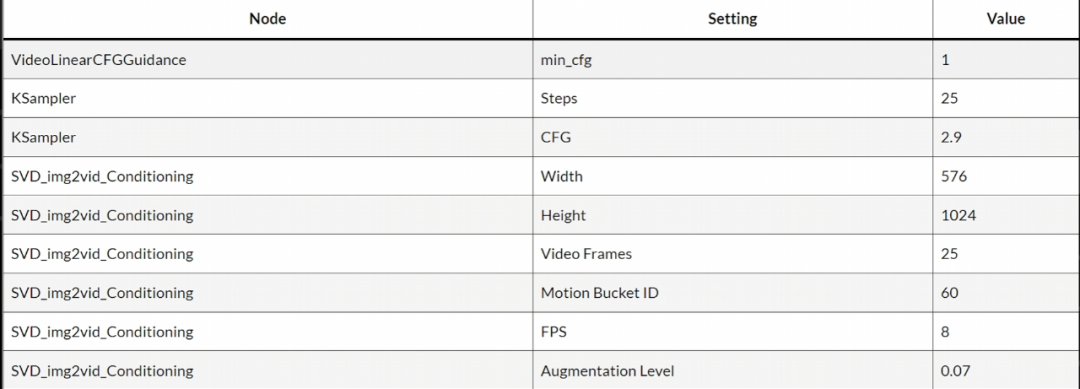
**问题总结:**
目前的操作过程中有个问题可能会出现
有些同学可能找不到Video Combine跟我一样,那就有几个可能,第一是VideoHelperSuite没有放在custom_nodes文件夹中。

如果确认在文件夹中但是仍然没有搜索到的话可以有两个选择,下载一个管理包(连接在文末),用管理文件来下载插件:

如果出现了下载失败的情况,那我暂时也没办法,可以私信我我找到办法了就回复。
第二种选择是去B站搜索秋葉启动器,之前一直用的是WebUI版本其实也有ComfyUI版本可以下载。
如果还有什么其他问题可以看原视频教程的评论区,我会把链接都放在文末。
那今天的内容就到这里结束啦!大伙下篇笔记见,拜了个拜!

1girl, upper body, psychedelic, latex bodysuit,wavy hair, splashing, abstract background
Negative prompt: (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, watermark
-
Steps: 20
-
Sampler: DPM++ 2M Karras
-
CFG scale: 7
-
Seed: 3403042071
-
Size: 512x512
-
Model hash: e4a30e4607
-
Model: majicmixRealistic_v6
-
Denoising strength: 0.7
-
Clip skip: 2
-
Hires upscale: 2
-
Hires upscaler: R-ESRGAN 4x+
-
Version: v1.6.0-2-g4afaaf8a0
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!


