
LeNet
原始论文中的版本
数据集为MNIST,输入:Name kernel stride pad Input Output Parameter Number Conv1 6 5×5 1 0 32×32×1 28×28×6 (5×5×1+1)×6 subsampling+sigmoid 2×2 2 0 28×28×6 14×14×6 (1+1)×6 Conv2 16 5×5 1 0 14×14×6 10×10×16 (5×5×3+1)×6+(5×5×4+1)×6+(5×5×4+1)×3+ (5×5×6+1)×1 subsampling+sigmoid 2×2 2 0 10×10×16 5×5×16 (1+1)×16 Conv3 120 5×5 1 0 5×5×16 1×1×120 (5×5×16+1)×120 FC4+tanh - - - 1x1x120 84 1x1x120x84 RBF - - - 84 10 0 下采样的方式为
这里, 和 是可学习参数。conv2使用了包括3层、4层、6层三种通道数不同的filters,然后将它们的输出拼接在一起作为这一层的输出。
这里使用多组不同形式的卷积的原因: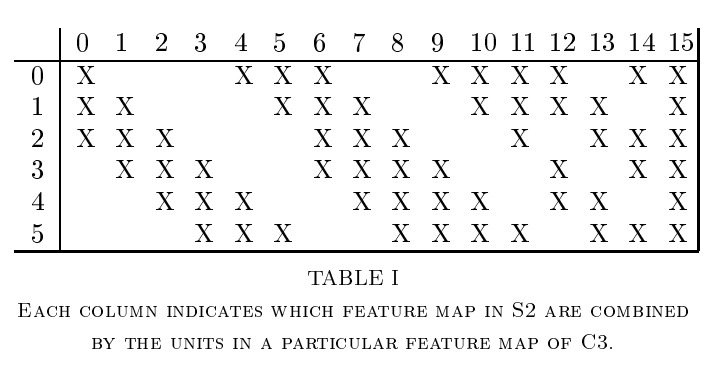
- 不完全机制限制了连接的数量,减少计算量
- 破坏了网络的对称性
最后一层是RBF,虽是全连接,但参数W是给定值。输入的维向量相当于的比特图。输出的每一个值,代表了输入与输出对应的参数权重的均方误差MSE。
要求损失函数可以使正确的label对应的输出值越小越好。
Caffe中的实现,输入的 batch size ,归一化scale
Name kernel stride pad Input Output Parameter Number Conv1+ReLU 20 5×5 1 0 28×28×1 24×24×6 (5×5×1+1)×20 Max Pooling 2×2 2 0 24×24×20 12×12×20 0 Conv2+ReLU 50 5×5 1 0 12×12×20 8x8x50 (5×5×20+1)×50 Max Pooling 2×2 2 0 8x8x50 4x4x50 0 FC3+ReLU - - - 4x4x50 500 4x4x50×500 FC4+Softmax - - - 500 10 500x10 损失函数为 SoftmaxWithLoss
细节:- 权重的初始化方式为xavier,偏移值的初始化方式为constant,默认设为0
- 权重的学习率为 base_learning_rate,偏移值的学习率为 base_learning_rate 的两倍
- 权重的初始化方式为xavier,偏移值的初始化方式为constant,默认设为0
AlexNet - ImageNet Classification with Deep Convolutional Neural Networks
结构
Name kernel stride pad Input Output Parameter Number Conv1+ReLU 96 11×11 4 0 227×227×3 55×55×96 (11×11×3+1)×96 Max Pooling 3x3 2 0 55x55x96 27x27x96 0 Conv2+ReLU 256 5x5 1 2 27x27x96 27x27x256 (5x5x96+1)x256 Max Pooling 3x3 2 0 27x27x256 13x13x256 0 Conv3+ReLU 384 3x3 1 1 13x13x256 13x13x384 (3x3x256+1)x384 Conv4+ReLU 384 3x3 1 1 13x13x384 13x13x384 (3x3x384+1)x384 Conv5+ReLU 256 3x3 1 1 13x13x384 13x13x256 (3x3x384+1)x256 Max Pooling 3x3 2 0 13x13x256 6x6x256 0 FC6+ReLU+Dropout - - - 6x6x256 4096 6x6x256x4096 FC7+ReLU+Dropout - - - 4096 4096 4096x4096 FC8+Softmax - - - 4096 1000 4096x1000 浮点乘法运算量:
参数60 Million,MACs 1.1 Billion
(实际计算量比这个值小,因为Conv层中使用了group)第一次引入ReLU,并使用了 overlapping Max Pooling
在前两个全连接层使用了系数为0.5的 Dropout,因此测试时需要将结果乘以0.5在论文中,还引入了局部响应归一化层LRN。但后来证明没有效果提升。同时,overlapping Max Pooling也没有被广泛应用。
训练细节:
batch size 128,momentum 0.9,weight decay 5e-4
学习率初始为0,每当error停止下降,就除以10- 数据增强
- 对于训练集,随机剪裁。对于测试集,将原始图片和对应的水平镜像从中间和四边剪切,然后将这十个预测结果取平均
- PCA jittering。基于整个训练集特征值 λ 和特征向量 P,对于每个epoch的每一张图像,从均值0、方差0.1的高斯分布随机抽取 α。对原始图片三维通道做 λ * α * P 映射
ZFNet - Visualizing and Understanding Convolutional Networks
引入 DeconvNet 来可视化某一 feature map
将该层其余 feature maps 设置为0,然后经过一系列的 (i) unpool (ii) rectify (iii) filters 映射回像素级别。
其中,(i) unpool:max-pooling同时记录位置信息。(ii) ReLU。(iii) 原卷积对应矩阵的转置。论文中使用可视化方法:
对于某一层的某个 feature map,我们在验证集中寻找使该 feature map 的 response 最大的九张图片,画出这九张图片中的该 feature map 反卷积映射的结果,并和原图相对应的 patch 对比特征可视化:层数越高,提取的特征越复杂,不变性越明显,越 discrimination。
训练过程中特征收敛过程:层数越低,收敛越早
特征不变性:(1) 图像缩放、平移对模型第一层影响较大,对后面基本没有影响;(2) 图像旋转后,特征不具有不变性。通过第一层和第二层可视化对AlexNet进行改造得到ZFNet:减小感受野,降低步长。
模型对局部特征敏感
模型具有特征泛化性,因此可以用于迁移学习。
Network in Network
引入1x1卷积
Original:Conv 3x3 -> ReLU -> Pooling
MLPConv: Conv 3x3 -> ReLU -> Conv 1x1 -> ReLU -> ... -> Pooling使用 average pooling 取代 FC
结构:MLPConv 堆叠 + global average pooling
VGG - Very Deep Convolutional Networks for Large-Scale Image Recognition
使用了统一的卷积结构,证明了深度对模型效果的影响。LRN层没有提升效果。
堆叠多个3x3的感受野,可以获得类似于更大感受野的效果。同时,多层3x3卷积堆叠对应的参数更少(减少参数相当于正则化效果)
运用了 Network in Network 中提出的1x1卷积。
训练方式: 256 batch size,0.9 momentum,5e-4 weight decay,0.5 dropout ratio。learning rate:初始1e-2,每当停止提升后下降为之前的十分之一
- 数据增强
- 颜色增强 color jittering,PCA jittering
- 尺度变换:训练集随机缩放到[256, 512],然后随机剪切到224x224
尺度变换对应的测试方法:(1) 随机裁剪,取平均,类似AlexNet (2) 将FC转为Conv,原始图片直接输入模型,这时输出不再是1x1x1000,而是NxNx1000,然后取平均。
- 颜色增强 color jittering,PCA jittering
GoogLeNet - Going deeper with convolutions
论文发表之前相关的工作:当时研究者关注增加层数和filter数目(可能会导致小样本过拟合,并需要大量的计算资源),并通过Dropout防止过拟合。尽管有人认为 Max Pooling 造成了空间信息的损失,但这种结构在 localization、detection、human pose estimation 中均取得很好的成绩。
Network-In-Network 中引入1x1卷积,增加了神经网络的表示能力【representational power】。GoogLeNet中的 Inception 结构也运用了1x1卷积来进行降维处理。为解决过拟合和计算代价高的问题,使用稀疏网络来代替全连接网络。在实际中,即使用卷积层。
Inception结构:对于输入的 feature maps,分别通过1x1卷积、3x3卷积、5x5卷积和 Max-Pooling 层,并将输出的 feature maps 连接起来作为 Inception 的输出【同时获得不同感受野的信息】。在3x3卷积、5x5卷积前面和池化层后面接1x1卷积,起降维的作用。
Inception v2 v3 - Rethinking the Inception Architecture for Computer Vision
- CNN的通用设计思想
- 通常,随着网络层数增加,空间特征数逐渐降低,通道数逐渐增加。
- 不要过度压缩损失精度信息,避免表征瓶颈。
- 增加非线性特征可以解耦合特征。
- 卷积的实现形式为空间聚合【spatial aggregation】
- 1x1卷积降维不会产生严重的影响。猜测:相邻通道之间具有强相关性,卷积前降维基本不会损失信息。
- 通常,随着网络层数增加,空间特征数逐渐降低,通道数逐渐增加。
5x5卷积的感受野与两个3x3卷积堆叠所对应的感受野相同。使用后者可以大大减少网络参数。7x7同理。此外,两个3x3卷积后各连接一个非线性层的效果优于仅在最后连接一个非线性层
NxN的卷积可以用1xN与Nx1的卷积堆叠实现。
使用 Label Smoothing 增加网络的正则能力。使用 Batch Normalization 和 RMSProp
ResNet - Deep Residual Learning for Image Recognition
网络过深会导致退化问题,通过短路连接解决该问题。
通常,一个 residual unit 的残差部分使用二至三层的函数映射(或称卷积层),shortcut 部分与残差部分进行 eltwise add 后再连接非线性层。
补充:论文
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
- 相比v3,Inception v4的主要变化是网络的加深,卷积和的个数也大大增加
- Inception-ResNet即将ResNet的残差结构替换成了简单的Inception结构
- 文中认为ResNet对提高精度的帮助较小【ResNet论文中提到ResNet解决了退化问题】,加快过深网络的训练速度是其主要优势。对于特别深的残差网络,可以通过在残层结构后接一个scaling【如残层结构输出的一个元素乘以0.2】来提高模型稳定性。
Wide Residual Networks
- 很多论文在ResNet的网络结构基础上进行了细微的改动。主要的观点是ResNet存在diminishing feature reuse的问题。网络过深,很多残差块对最终结果只做出了很少的贡献。甚至,有些残差块没有学到有用的信息,反而在之前学到的feature representation中加入了轻微噪声
- ResNet提高一点精度可能需要将深度增加一倍,而且会产生diminishing feature reuse问题,因此提出增加残差块的宽度,减少网络深度的WRNs
- 文中提到论文 Deep Networks with Stochastic Depth 中通过使残差块随机失活来降低每次训练使网络的深度。
- 作者做了大量的实验,表明两个3x3卷积堆叠的残差块的效果优于其他残差块结构。
- 同时增加深度和宽度可以提高精度,但需要正则。增加宽度比增加深度更容易训练。
- 在瘦长和矮胖的网络中,在残差块中的两个卷积间增加 Dropout 层均有效果。在不做大量的数据增强的前提下,Dropout 的效果比 Batch Normalization 更好
Aggregated Residual Transformations for Deep Neural Networks
- 指出 Inception 过于复杂,不易迁移到其他问题上;ResNet 存在 diminishing feature reuse 的问题。
- 提出了基数的概念,残差块采用 split-transform-merge 的策略,基数类似 group,表示 split 的数目。这种架构可以接近 large and dense layers 的表示能力,但只需要很少的计算资源。
- ResNeXt 有一种基本形式和两种变体,一种类似 Inception-ResNet,一种使用 group 实现。
Densely Connected Convolutional Networks
- DenseNet 极大地增加了特征重用的能力,其有以下优点。1. 参数少,通过向后连接的方式保留学到的信息;2. 改进了前向、反向传播,更易训练;3. 增加了监督学习的能力;4. 在小数据上不易过拟合,即增加了正则化的能力。
- Dense Block 中,对于任意一层的 feature maps,一方面会通过 BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3)得到下一层的 feature maps,另一方面会与其后的每一层 feature maps 连接在一起。并提出了 growth rate 的概念,增长率 k 是3x3卷积层输出的 feature maps 数, 而1x1卷积层输出的 feature maps 数为 4k
- 在 ImageNet 比赛中运用的模型,每两个 Dense Block 中间以 Batch Normalization - ReLU - Conv(1x1) - Aver Pooling(2x2) 相连。
Squeeze-and-Excitation Networks
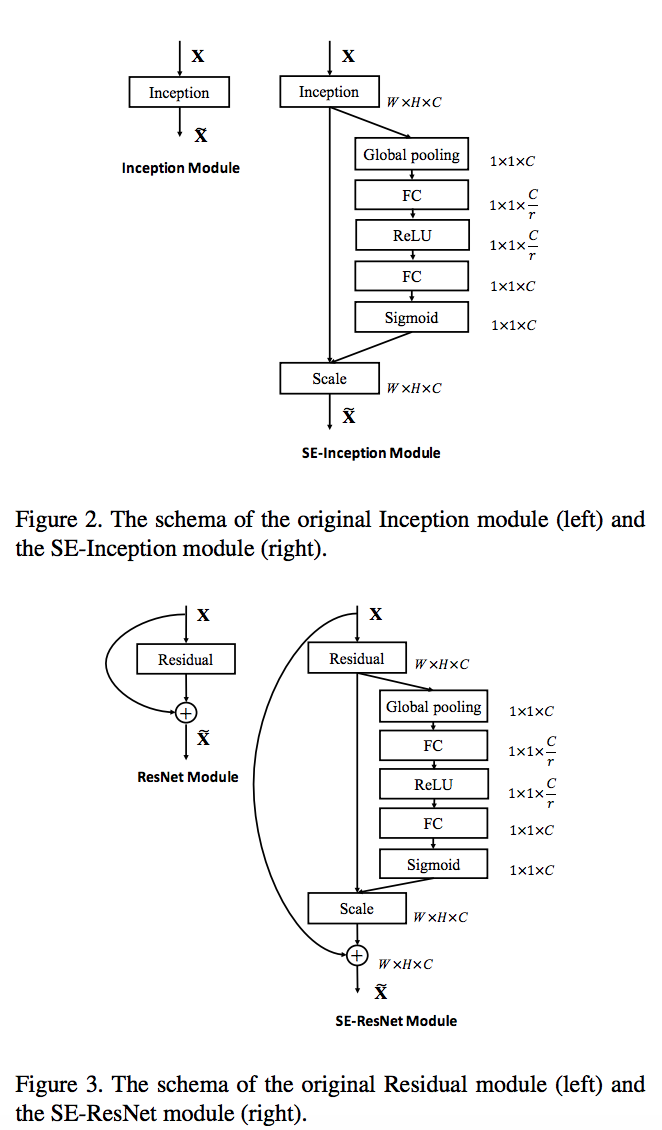
SqueezeNet, ShuffleNet, MobileNet, Xception
- SqueezeNet 的基本结构是 File Module,输入的 feature maps 先经过1x1卷积降维,然后分别通过1x1卷积和3x3卷积,并将两个输出连接起来,作为这个模块整体的输出。SqueezeNet 的结构就是多个 File Module 堆叠而成,中间夹杂着 max pooling。最后用 deep compression 压缩
- MobileNet 的基本结构是 3x3 depth-wise Conv 加 1x1 Conv。1x1卷积使得输出的每一个 feature map 要包含输入层所有 feature maps 的信息。这种结构减少了网络参数的同时还降低了计算量。整个 MobileNet 就是这种基本结构堆叠而成。其中没有池化层,而是将部分的 depth-wise Conv 的 stride 设置为2来减小 feature map 的大小。
- ShuffleNet 认为 depth-wise 会带来信息流通不畅的问题,利用 group convolution 和 channel shuffle 这两个操作来设计卷积神经网络模型, 以减少模型使用的参数数量,同时使用了 ResNet 中的短路连接。ShuffleNet 通过多个 Shuffle Residual Blocks 堆叠而成。
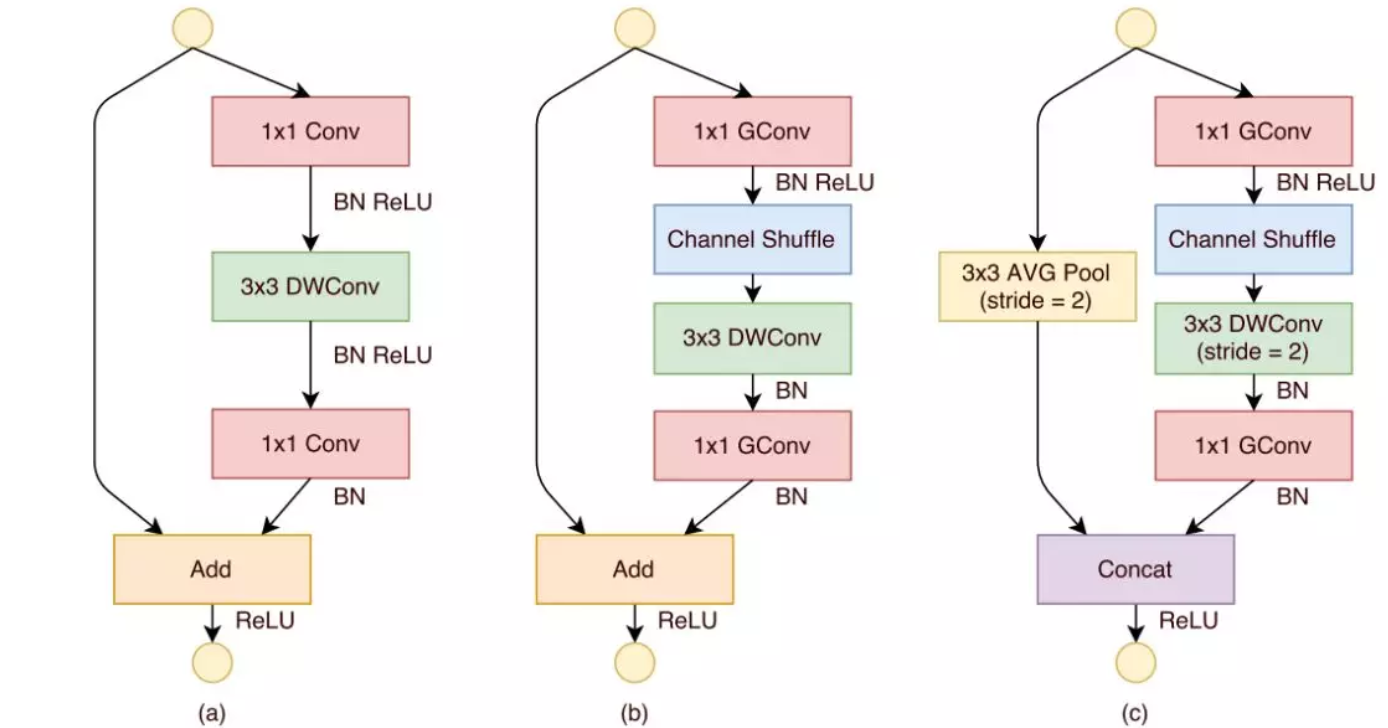
- Xception 相对于借鉴了 depth-wise 的思想,简化了 Inception-v3。Xception的结构是,输入的 feature maps 先经过一个1x1卷积,然后将输出的每一个 feature map 后面连接一个3x3的卷积(再逐通道卷积),然后将这些3x3卷积的输出连接起来。
补充:权重初始化方式
Xavier - Understanding the difficulty of training deep feedforward neural networks
MSRA - Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification


