
- 1Unity3D开发之WebGL平台上 unity和js前端通信交互_unity 跟js 交互
- 2释放pytorch占用的gpu显存_pytorch程序异常后删除占用的显存操作
- 3【Microsoft Azure 的1024种玩法】七十五.云端数据库迁移之快速将阿里云RDS SQL Server无缝迁移到Azure SQL Database中_azure 迁移sql 到阿里云
- 4【K8S系列】深入解析k8s网络
- 5qt day3
- 6详解MySQL事务日志——undo log_undo log存的是什么
- 7SqlSugar小结_sqlsugar ignorecolumns
- 8小鹤输入法及练习工具推荐_小鹤双拼在线练习
- 9游戏开发者的操作系统课设的正确打开方式(Unity3D)_unity完成操作系统
- 10Typora收费了?推荐两款Markdown编辑器
redis数据结构底层原理及相关运用_redis 底层数据接口
赞
踩
Redis的数据结构
Redis的数据结构,可以在两个不同的层面来讨论它。
第一个层面,是从使用者的角度。比如:string、list、hash、set、zset(sorted set)五种数据类型
这一层面也是Redis暴露给外部的调用接口,也就是我们平时使用redis数据库所使用的数据结构。
第二个层面,就是这五种数据类型的内部实现结构,属于更底层的实现。
比如:dict(字典)、sds(simple dynamic string简单动态字符串)、intset(整数集合)、ziplist(压缩列表)、quicklist(快速列表)、skiplist(跳跃表)数据结构。
第一个层面
分别介绍一下应用场景和底层实现
String:最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存。常用命令get、set、自增incr、自减decr、mget等。String底层数据结构实现为简单动态字符串(SDS)。对于sds这个数据结构后面在介绍内部实现结构的时候会详细介绍。
对于redis的string比较常见的使用场景有下面这些:
-
缓存数据:将一些常用的数据存储在Redis的string类型中,通过缓存的方式提高系统的性能,减少对数据库或其他外部系统的访问。
-
分布式锁:利用Redis的string类型的setnx命令可以实现分布式锁,保证多个客户端对同一个资源的互斥访问。这里简单介绍一下是怎么实现的。
-
客户端A尝试获取锁,调用Redis的setnx命令,将一个特定的字符串作为key,将当前时间戳作为value,如果返回值为1,则表示A成功获取到了锁;否则,表示锁已经被其他客户端持有。
-
客户端B也尝试获取锁,同样调用Redis的setnx命令,如果返回值为0,则表示锁已经被其他客户端持有,B需要等待一段时间后再次尝试获取锁。
-
客户端A完成对资源的操作后,调用Redis的del命令,将key删除,释放锁。
-
客户端B等待一段时间后再次尝试获取锁,如果获取到了锁,则可以执行对资源的操作。
需要注意的由于网络延迟等原因,可能会出现客户端A已经获取到锁,但是还没有来得及释放锁时,客户端B也已经获取到锁的情况这样就会导致死锁。
为了解决这个问题,可以在setnx命令中给key设置一个过期时间,表示锁的有效期,这样即使客户端A没有来得及释放锁,锁也会在一定时间后自动失效。
hash:可以用来存储一个对象结构的比较理想的数据类型。一个对象的各个属性,正好对应一个hash结构的各个field。在field比较少,各个value值也比较小的时候,hash采用ziplist来实现;而随着field增多和value值增大,hash可能会变成dict来实现。当hash底层变成dict来实现的时候,它的存储效率就没法跟那些序列化方式相比了。
list:可以通过(lpush和rpop)简单的消息队列的功能。另外还有一个就是,可以利用lrange范围操作命令,做基于redis的分页功能,性能极佳,用户体验好。Redis对外暴露的list数据类型,它底层实现所依赖的内部数据结构就是quicklist。
对于这个简单信息队列的实现步骤是
-
客户端向Redis中的一个list类型的key中插入消息,可以使用lpush或rpush命令,其中lpush命令表示从左边插入消息,rpush命令表示从右边插入消息,消息可以是任意类型的字符串。
-
客户端从Redis中的list类型的key中取出消息,可以使用lpop或rpop命令,其中lpop命令表示从左边取出消息,rpop命令表示从右边取出消息,如果list中没有消息,则命令会一直等待,直到有消息为止。
-
Redis中的list类型可以设置最大长度,超出最大长度后插入的消息会自动删除最早插入的消息,从而实现消息队列功能。
需要注意的是,Redis的list类型是线性的,不支持多个消费者并发消费消息,如果需要支持多个消费者并发消费消息,可以使用Redis的pub/sub功能或者其他消息队列系统,如RabbitMQ、Kafka等。
set:set存放的是一堆不重复值的集合,所以可以做全局去重的功能。intset作为set的底层实现,但当数据量较大或者集合元素为字符串时,redis会使用dict实现set。
sorted set:sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。sorted set底层实现的数据结构有skiplist、ziplist。
第二个层面
1.dict(字典)
dict是一个用于维护key和value映射关系的数据结构,与很多语言中的Map或dictionary类似。Redis的一个database中所有key到value的映射,就是使用一个dict来维护的。dict本质上是为了解决算法中的查找问题(Searching)。
1.一般查找问题的解法分为两个大类
一个是基于各种平衡树,一个是基于哈希表,平常使用的各种Map或dictionary,大都是基于哈希表实现的。
2.dict的算法实现
dict也是一个基于哈希表的算法,跟java中的hashMap类似,dict采用某个哈希函数从key计算得到在哈希表中的位置,采用拉链法解决冲突,
并在装载因子(load factor)超过预定值时自动扩展内存,引发重哈希(rehashing)。
dict的数据结构定义
- typedef struct dict{
- dictType *type; //直线dictType结构,dictType结构中包含自定义的函数,这些函数使得key和value能够存储任何类型的数据
- void *privdata; //私有数据,保存着dictType结构中函数的 参数
- dictht ht[2]; //两张哈希表
- long rehashidx; //rehash的标记,rehashidx == -1,表示没有进行 rehash
- int itreators; //正在迭代的迭代器数量
- }dict;
dict结构图
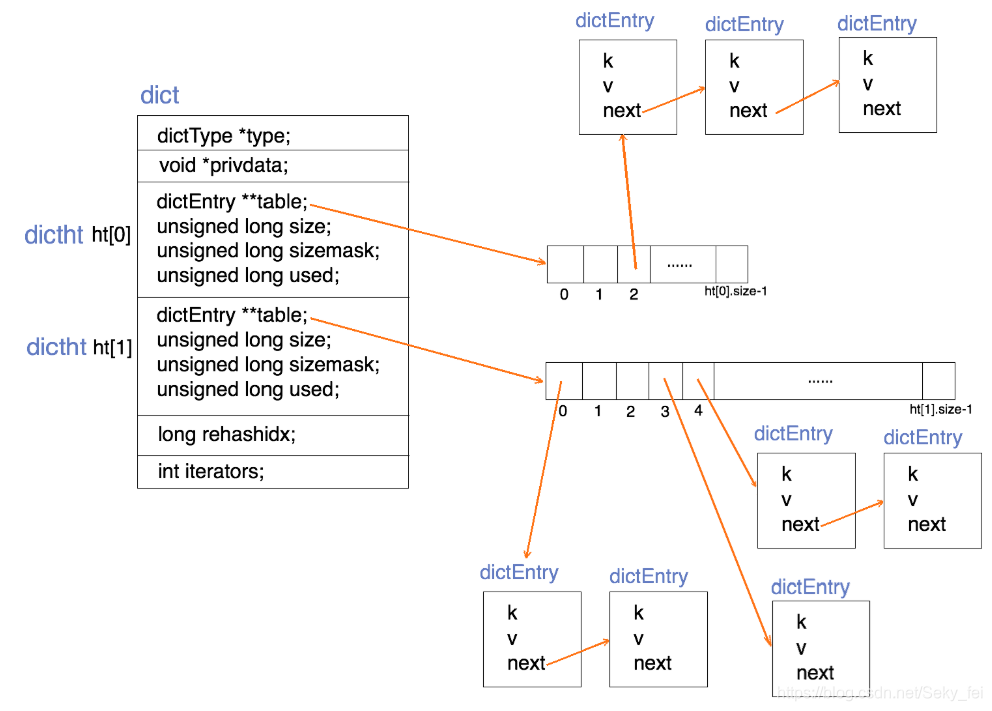
dict采用哈希函数对key取哈希值,得到在哈希表中的位置(桶的位置),再采用拉链法解决hash冲突。
两个哈希表(ht[2]):只有在重哈希的过程中,ht[0]和ht[1]才都有效。而在平常情况下,只有ht[0]有效,ht[1]里面没有任何数据。上图表示的就是重哈希进行到中间某一步时的情况。
重哈希过程:跟HashMap一样,当装载因子(load factor)超过预定值时就会进行rehash。dict进行重hash扩容是将ht[0]上某一个bucket(即一个dictEntry链表)上的每一个dictEntry移动到扩容后的ht[1]上,触发rehash的操作有查询、插入和删除元素。每次移动一个链表(即渐进式rehash)原因是为了防止redis长时间的堵塞导致不可用。
dict添加操作:如果正在重哈希中,会把数据插入到ht[1]和ht[0];否则插入到ht[0]。
dict查询操作:先在第一个哈希表ht[0]上进行查找,再判断当前是否在重哈希,如果没有,那么在ht[0]上的查找结果就是最终结果。否则,再在ht[1]上进行查找。查询时会先根据key计算出桶的位置,在到桶里的链表上寻找key。
dict删除操作:判断当前是不是在重哈希过程中,如果是ht[0]和ht[1]它都要查找删除;否则只在ht[0]中查找要删除的key。
rehash操作步骤
1.负载因子计算:负载因子 = 哈希表已保存节点数量 / 哈希表大小
load_factor = ht[0].used / ht[0].siz
2.rehash的条件:触发dict的rehash主要有两种:一种是触发扩容操作,另一种是触发收缩操作。两种rehash触发的条件是不一样的,需要各自满足一下条件才能导致rehash操作。
触发扩容操作条件:当以下条件中的任意一个被满足时, 程序会自动开始对哈希表执行扩展操作。
1.服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 1。
2.服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 5。
BGSAVE命令:用于在后台异步保存当前 Redis 实例快照(snapshot)到磁盘。
BGREWRITEAOF 命令:用于在后台异步重写当前 Redis 实例的 AOF 文件
AOF文件: AOF 文件是 Redis 用于持久化数据的一种方式,它记录了 Redis 服务器所有的写操作。随着时间的推移,AOF 文件会越来越大,如果不进行重写,AOF 文件可能会占用过多的磁盘空间。因此,定期执行 BGREWRITEAOF 命令可以帮助缩减 AOF 文件大小,同时也能提高 Redis 实例的性能。
根据 BGSAVE 命令或 BGREWRITEAOF 命令是否正在执行,服务器执行扩展操作所需的负载因子并不相同,这是因为在执行 BGSAVE 命令或 BGREWRITEAOF命令的过程中, Redis会fork一个子进程,而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率,所以在子进程存在期间,服务器会提高执行扩展操作所需的负载因子,从而尽可能地避免在子进程存在期间进行哈希表扩展操作,这可以避免不必要的内存写入操作, 最大限度地节约内存。
写时复制技术来如何优化子进程的使用效率:
当子进程需要修改某个内存区域时,它会先将该区域复制一份,然后在副本上进行修改。这样就可以避免对原始内存区域的修改,保证了主进程和子进程之间的内存数据一致性。同时,由于子进程只需要修改少量的内存区域,因此也能减少内存的使用量。
在子进程完成快照或 AOF 重写操作后,Redis 会将子进程中修改的数据写回到主进程中,从而保证了 Redis 实例的数据一致性。
触发收缩操作条件:当哈希表的负载因子小于0.1时,程序自动开始对哈希表执行收缩操作。
(ht[0].used / ht[0].siz) < 0.1,也就是填充率必须<10%。
渐进式 rehash
扩展或收缩哈希表需要将 ht[0]里面的所有键值对 rehash 到 ht[1]里面, 但是, 这个 rehash 动作并不是一次性、集中式地完成的, 而是分多次、渐进式地完成的。
这样做的原因在于,如果哈希表里保存的键值对数量很大时, 如:四百万、四千万甚至四亿个键值对, 那么一次性将这些键值对全部 rehash 到 ht[1] 的话,庞大的计算量(需要重新计算链表在桶中的位置)可能会导致服务器在一段时间内停止服务(redis是单线程的,如果全部移动会引起客户端长时间阻塞不可用)。
因此, 为了避免 rehash 对服务器性能造成影响, 服务器不是一次性将 ht[0]里面的所有键值对全部 rehash 到 ht[1], 而是分多次、渐进式地将 ht[0]里面的键值对慢慢地 rehash 到 ht[1]。
以下是哈希表渐进式rehash的详细步骤:
(1)为ht[1]分配空间,让dict字典同时持有 ht[0] 和 ht[1] 两个哈希表。
(2)在字典中维持一个索引计数器变量rehashidx,并将它的值设置为0,表示rehash工作正式开始。
(3)在rehash进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将ht[0]哈希表在 rehashidx索引(table[rehashidx]桶上的链表)上的所有键值对rehash到ht[1]上,当rehash工作完成之后,将rehashidx属性的值增一,表示下一次要迁移链表所在桶的位置。
(4)随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有桶对应的键值对都会被rehash至ht[1],这时程序将rehashidx属性的值设为-1,表示rehash操作已完成。
渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均滩到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
sds(简单动态字符串)
SDS的数据结构定义
- /*
- * redis中保存字符串对象的结构
- */
- struct sdshdr {
- //用于记录buf数组中使用的字节的数目,和SDS存储的字符串的长度相等
- int len;
- //用于记录buf数组中没有使用的字节的数目
- int free;
- //字节数组,用于储存字符串
- char buf[]; //buf的大小等于len+free+1,其中多余的1个字节是用来存储’\0’的
- };
SDS和C字符串的区别
1.获取字符串长度
由于C字符串没有记录自身的长度信息,所以获取C字符串长度的时候,必须遍历整个字符串,其时间复杂度是O(n),而SDS中有len属性,所以在获取其长度时,时间复杂度为O(1)。
2.内存分配释放策略
- 对于C字符串而言,不管是字符串拼接,还是字符串缩短,都要扩展底层的char数组的空间大小,再将旧char数据拷贝过来。
- SDS的内存分配策略就不一样,可以概括为预分配 + 惰性释放。
SDS内存分配策略:预分配
(1)如果对SDS字符串修改后,len的值小于1MB,那么程序会分配和len同样大小的空间给free,此时len和free的值是相同。
例如:如果SDS的字符串长度修改为15字节,那么会分配15字节空间给free,SDS的buf属性长度为15(len)+15(free)+1(空字符) = 31字节。
(2)如果SDS字符串修改后,len大于等于1MB,那么程序会分配1MB的空间给free。
例如:SDS字符串长度修改为50MB那么程序会分配1MB的未使用空间给free,SDS的buf属性长度为 50MB(len)+1MB(free)+1byte(空字符)。
总结:free的空间大小由len决定,在没超过1Mb时候 free=len,超过时,free空间固定为1Mb.
SDS内存释放策略:惰性释放
当需要缩短SDS字符串时,程序并不立刻将内存释放,而是使用free属性将这些空间记录下来,实际的buf大小不会变,以备将来使用。
3.缓冲区溢出问题
SDS的字符串的内存预分配策略能有效避免缓冲区溢出问题;C字符串每次操作增加长度时,都要分配足够长度的内存空间,否则就会产生缓冲区溢出
4.二进制安全
(1)C字符串的编码是ASCII编码,在字符串的末尾是以”\0“结束,也就是空字符,所以在字符串中不能包含空字符,要不然会让程序误以为结束,这也限制了C字符串只能保存文本数据,不能保存图片,音频,视频等二进制数据。
(2)SDS以二进制存储数据的,可以存储任意数据。因此不管buf保存什么格式的数据,都是存入什么数据,读取就什么数据,二进制安全。
5.SDS兼容部分C字符串函数
SDS总会在buf[]数组分配空间时,多分配一个字节来存储空字符(’\0’),便于重用C中的函数。
intset(整数集合)
intset是Redis集合的底层实现之一,当存储整数集合并且数据量较小的情况下Redis会使用intset作为set的底层实现,当数据量较大或者集合元素为字符串时则会使用dict实现set。
(1)intset的数据结构定义
- typedef struct intset {
- uint32_t encoding; //intset的类型编码
- uint32_t length; //集合包含的元素数量
- int8_t contents[]; //保存元素的数组
- }
(2)inset数据集合具有以下特点:
(1)所有的元素都保存在contents 数组中,且按照从小到大的顺序排列,并且不包含任何重复项。
(2)intset将整数元素按顺序存储在数组里,并通过二分法降低查找元素的时间复杂度。
(3)虽然contents 数组申明成了int8_t类型,但contents数组中具体存储什么类型完全取决于encoding变量的值,类似于继承。它可以保存具体类型为int16_t、int32_t 或者int64_t 的整数值。
(3)元素升级
当新增的元素类型比原集合元素类型的长度要大时(比如:原来是int16_t,现在新增一个int64_t的元素),需要对整数集合进行升级,才能将新元素放入整数集合中。具体步骤:
-
1、根据新元素类型,扩展整数集合底层数组的大小,并为新元素分配空间。
-
2、将底层数组现有的所有元素都转成与新元素相同类型的元素,并将转换后的元素放到正确的位置,放置过程中,维持整个元素顺序都是有序的。
-
3、将新元素添加到整数集合中(保证有序)
注意:升级能极大地节省内存;整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态。
4.skiplist(跳表)
skiplist查找效率很高,堪比优化过的二叉平衡树(红黑树),且比平衡树的实现简单,查找单个key,skiplist和平衡树的时间复杂度都为O(log n)。平衡树的插入和删除操作可能引发树的旋转调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
skiplist首先它是一个list。实际上,它是在有序链表的基础上发展起来的。先来看一个有序链表,如下图(最左侧的灰色节点表示一个空的头结点):

这样种链表中,如果要查找某个数据,需要从头开始逐个进行比较,直到找到等于 或 大于(没找到)给定数据为止,时间复杂度为O(n)。同样,当插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
有了上面出现的问题后进一步优化,假如我们这样来设计,在每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是7, 19, 26)。现在当查找数据的时候,可以先沿着这个新链表(第一层链表)进行查找。当碰到比待查数据大的节点时,再回到第二层链表进行查找。
比如,要查找23,查找的路径是沿着下图中标红的指针所指向的方向进行的:整个查询路线如红色箭头。

先在第一层链表上查询,23首先和7比较,再和19比较,比它们都大,继续向后比较。但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。
再在第二层链表上查询,23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它的插入位置应该在22和26之间。
在这个查找过程中,由于新增加的指针,不再需要向原链表一样,每个节点都逐个进行比较。需要比较的节点数大概只有原来的一半。 利用同样的方式,可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:

在这个新的三层链表结构上,如果还是查找23,那么沿着最上层链表首先要比较的是19,发现23比19大,接下来我们就知道只需要到19的后面去继续查找,从而一下子跳过了19前面的所有节点。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度。
skiplist正是受这种多层链表的想法的启发而设计出来的,实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。但是,这种方法在插入数据的时候有很大的问题。新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n)。删除数据也有同样的问题。
skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)(就是节点右侧的指针数量)。每个节点生成的层数都会遵循一定的概率分布。生成的层数越多,这个节点在Skiplist中的访问效率就越高,因为它可以被更多层级的链表所包含,从而更快地被访问到。比如层数量为3,1,2,3层都可以访问到他。
skiplist中一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。而节点的层数(level)也不全是没有规则随机的,而是遵循指数分布或正态分布等。如下图各个节点层数(level)是随机出来的一个skiplist,我们依然查找23,查找路径如图:
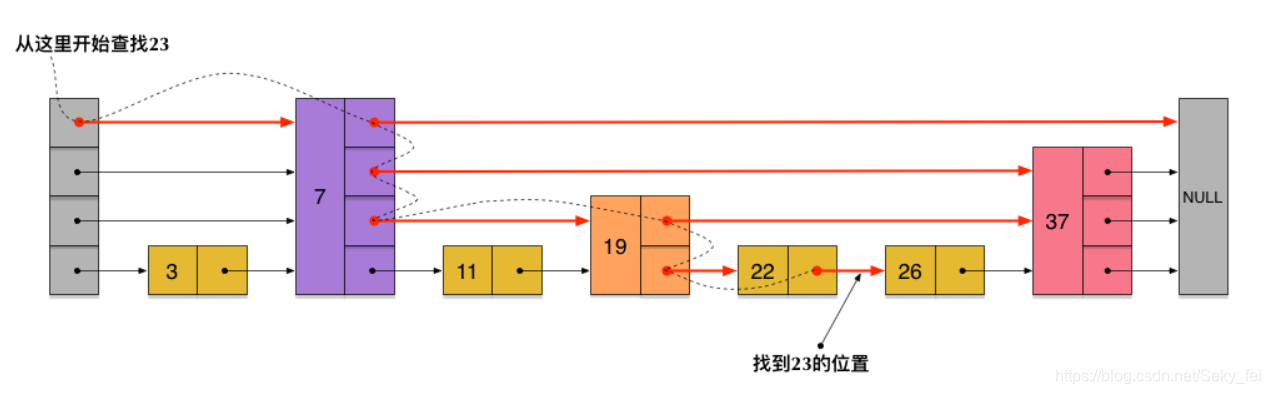
skiplist与平衡树、哈希表的比较
skiplist 和 各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。
平衡树的插入 和 删除操作可能引发树的旋转调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。
从内存占用上来说,skiplist比平衡树更灵活一些。平衡树一般每个节点包含2个指针,而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于一个概率参数p。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
5.ziplist(压缩表)
ziplist是一个经过特殊编码的双向链表,它的设计目标就是为了提高存储效率。ziplist可以用于存储字符串或整数,其中整数是按真正的二进制表示进行编码的,而不是编码成字符串序列。
Redis对外暴露的hash数据类型,在field比较少,各个value值也比较小的时候,hash采用ziplist来实现;而随着field增多和value值增大,hash可能会变成dict来实现。当hash底层变成dict来实现的时候,它的存储效率就没法跟那些序列化方式相比了。
ziplist的数据结构
ziplist在内存中的结构大致如下:
<zlbytes><zltail><zllen><entry>...<entry><zlend>
1.结构说明:
(1)zlbytes: 表示整个ziplist占用的字节总数。
(2)zltail:表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。
(3)zllen:16bit,表示ziplist中数据项(entry)的个数。当ziplist里数据大于2^16-1后,再获取元素个数时,ziplist从头到尾遍历。
(4)entry:表示真正存放数据的数据项,长度不定,采用变长编码.也就是进行了数据压缩
变长编码是一种无损压缩数据的方法,它通过使用不同长度的编码来表示不同的符号,以实现压缩数据的目的。具体实现方法如下:
-
建立符号表:首先需要建立一个符号表,将需要编码的符号按照出现概率从高到低排序,将出现概率较高的符号用较短的编码表示,出现概率较低的符号用较长的编码表示。
-
编码符号:按照符号表中的编码规则对每个符号进行编码,将编码后的结果存储在压缩后的数据中。
-
解码数据:解压时,根据符号表中的编码规则对压缩后的数据进行解码,还原出原始数据。
变长编码常用的方法有霍夫曼编码、算术编码等,其中霍夫曼编码是最常用的一种。
(5)zlend: ziplist最后1个字节,是一个结束标记,值固定等于255。
entry的内部结构:<prevrawlen><len><data>
(1)prevrawlen: 表示前一个数据项占用的总字节数。作用是为了让ziplist能够从后向前遍历(从后一项的位置,只需向前偏移prevrawlen个字节,就找到了前一项),这个字段采用变长编码。
(2)len: 表示当前数据项的数据长度(即<data>部分的长度)。也采用变长编码。
(3)data:存储的数据。
注意:ziplist虽然是个特殊编码的双向链表,但为了提高存储效率,内存地址空间是连续的,更像是一个list,只是比list多了一个链表的首尾操作而已。
ziplist(压缩表)的特点
1)内存空间连续:ziplist为了提高存储效率,从存储结构上看ziplist更像是一个表(list),但不是一个链表(linkedlist)。ziplist将每一项数据存放在前后连续的地址空间内,一个ziplist整体占用一大块内存。而普通的双向链表每一项都占用独立的一块内存,各项之间用指针连接,这样会带来大量内存碎片,而且指针也会占用额外内存。
(2)查询元素:查找指定的数据项就会性能变得很低,需要进行遍历整个zipList。
(3)插入和修改:每次插入或修改引发的重新分配内存(realloc)操作会有更大的概率造成内存拷贝,从而降低性能。跟list一样,一旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更大的一块数据。
ziplist提高了存储效率,是内存紧缩的列表,多个数据在一起的连续空间,不擅长修改,在两端pop或者push快。
这里简单介绍一下ziplist相对于链表和数组方面的相同和区别。
首先根据上面的ziplist的特点你可以看出,ziplist同时有链表和数组的缺点。首先,ziplist相对于数组来说查询效率不高,需要遍历查询,然后ziplist相对于链表来说插入效率也不高,需要移动元素进行插入。但是,对于redis来说,它是在内存中存储数据,而内存又是十分重要的资源,所以他肯定需要ziplist这种紧凑的内存布局,而且,相对于数组来说,虽然插入也需要移动元素,但是可以动态的调整内存大小,而数组的大小是固定的。所以对于redis来说,ziplist的优点大于在查询和插入上的缺点。
hash为什么要转为dict
(1)ziplist的数据发生改动(插入或修改),会引发内存realloc(内存重新分配),可能导致内存拷贝。
(2)ziplist里查找数据时需要进行遍历(跟双向链表一样),数据项过多会变慢。
6.quicklist(快速列表)
Redis对外暴露的list数据类型,它底层实现所依赖的内部数据结构就是quicklist。先来看看Redis对外暴露的list数据类型操作特点 :
1.Redis对外暴露的上层list数据类型,它支持的一些修改操作如下:
(1)lpush: 在左侧(即列表头部)插入数据。
(2)rpop: 在右侧(即列表尾部)删除数据。
(3)rpush: 在右侧(即列表尾部)插入数据。
(4)lpop: 在左侧(即列表头部)删除数据。
2.list也支持在任意中间位置的存取操作,比如lindex和linsert,但它们都需要对list进行遍历,所以时间复杂度较高,为O(N)。
3.list具有的特点:list的内部实现quicklist正是一个双向链表。
它是一个能维持数据项先后顺序的列表(各个数据项的先后顺序由插入位置决定),便于在表的两端追加和删除数据,而对于中间位置的存取具有O(N)的时间复杂度。这正是一个双向链表所具有的特点。
quicklist(快速表)的结构
quicklist确实是一个双向链表,而且是一个ziplist的双向链表。即quicklist双向链表是由多个节点(Node)组成,而quicklist的每个节点又是一个ziplist。结构如下图:
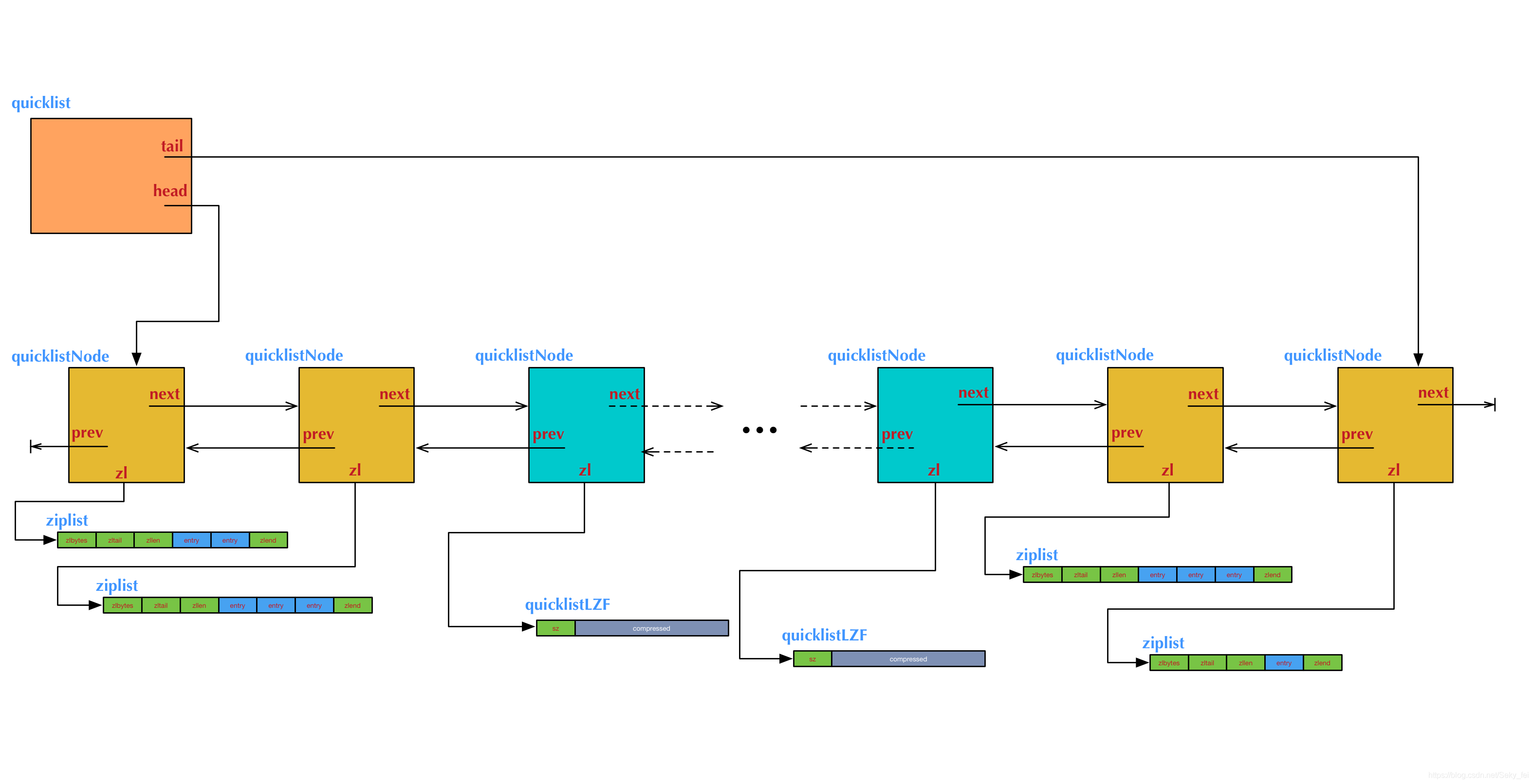
quicklist的结构为什么这样设计呢?总结起来,大概又是一个空间和时间的折中:
双向链表便于在表的进行插入和删除节点操作,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
ziplist由于是一整块连续内存,所以存储效率很高。但是,它不利于修改操作,每次数据变动都会引发一次内存的内存重新分配(realloc)。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝,进一步降低性能。
可见,一个quicklist节点上的ziplist要保持一个合理的长度。那到底多长合理呢?这可能取决于具体应用场景。实际上,Redis提供了一个配置参数list-max-ziplist-size,就是为了让使用者可以来根据自己的情况进行调整。
可见,一个quicklist节点上的ziplist要保持一个合理的长度。那到底多长合理呢?这可能取决于具体应用场景。实际上,Redis提供了一个配置参数list-max-ziplist-size,就是为了让使用者可以来根据自己的情况进行调整。
list-max-ziplist-size -2 //可以取正数,也可以取负数。
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如,当这个参数配置成5的时候,表示每个quicklist节点的ziplist最多包含5个数据项。
当取负值的时候,表示按照占用字节数来限定每个quicklist节点上的ziplist长度。这时,它只能取-1到-5这五个值。每个值得含义如下
#每个值含义如下:
-5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
-4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
-3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
-2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)
-1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
另外,list的设计目标是能够用来存储很长的数据列表的。当列表很长的时候,最容易被访问的很可能是两端的数据,中间的数据被访问的频率比较低(访问起来性能也很低)。如果应用场景符合这个特点,那么list还提供了一个选项,能够把中间的数据节点进行压缩,从而进一步节省内存空间。Redis的配置参数list-compress-depth就是用来完成这个设置的。 这个参数表示一个quicklist两端不被压缩的节点个数。
#参数表示一个quicklist两端不被压缩的节点个数
list-compress-depth 0
参数list-compress-depth的取值含义如下:
0: 是个特殊值,表示都不压缩。这是Redis的默认值。
1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩。
2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩。
3: 表示quicklist两端各有3个节点不压缩,中间的节点压缩。
依此类推…
注:这里的节点个数是指quicklist双向链表的节点个数,而不是指ziplist里面的数据项个数。实际上,如果一个quicklist节点如果被压缩,那么ziplist就是整体被压缩了。
总结:quicklist将 双向链表插入和修改元素不需要移动节点的优点 和 ziplist的存储效率很高优点(一整块连续内存)结合在一起,同时将各自的缺点进行一个折中的处理。

