
- 1软件开发人员的 5 项能力:如何识别优秀的程序员_软件技术能力体现
- 2128种chatGPT可以为人类做的事情_统计chatgpt 能做的任务类型
- 3shell中 -eq,-ne,-gt,-lt,-ge,-le数字比较符(整数值操作符)_shell gt
- 4SpringBoot系列——Jedis使用配置详解_springboot jedis连接池配置
- 5用23种设计模式打造一个cocos creator的游戏框架----(四)装饰器模式_cocos creator框架结构
- 6关于Spark报错不能连接到Server的解决办法(Failed to connect to master master_hostname:7077)_failed to connect to master h100:7077 org.apache.s
- 7win 11 添加VSCode至右键菜单_open with code win11
- 8全网素材解析接口_静听音乐,全网音乐VIP神器,各个音乐平台都能解析到无损音乐,酷狗音乐和咪咕音乐还可以下载至臻音质...
- 9基于Java的校园快递管理系统_一、运用meclipse软件,编写一个快递包裹的java程序,实现以下功能:(50分)(1)提
- 10利用PYQT5结合YOLOX搭建检测系统_yolov8病虫害识别和pyqt5
热词抽取与话题发现系列(1):郝晓玲研究_词共现 准确率
赞
踩
1. 背景
社区内容的数据挖掘方面主要可分为两大类:内容关联挖掘和用户关系挖掘, 热词/热点话题发现属于社区内容挖掘范畴,是指从大量的UGC文本中检测出用户广泛讨论的话题。涉及两个关键性技术:中文分词技术,中文话题发现技术。
中文分词算法主要分为两种:一是基于语言规则的方法,即计算机可以通过自然语言的语法、词性等内部规则分析出文本正确含义并分词,判断文本串是否成词主要依赖词库。 主要方法包括:基于统计过滤和规则;基于支持向量机与约束条件选取新词。 该类方法准确率更高,但对已知词库的依赖性强。 二是基于统计学习的方法,利用计算词元在文本中的各种统计特征值直接判断出成词的文本串。 该类方法比较灵活、适应能力强,具体可供参照的统计特征很多,如字与字之间的信息熵,字符串的最大组合概率,利用互信息和 t 测试差相结合,字符串出现的频率和置信度,利用词的前后缀信息提取高频词等等。 对于UGC社区而言,核心还在于热词发现与话题形成。
传统方法是,先对文本进行分词,然后猜测未能成功匹配的剩余片段就是新词。
顾森[1]提出运用内部凝固程度和自由运用程度来进行新词识别。 贺敏[2]判断上下文邻接种类, 首尾单字位置成词概率以及双字耦合度等语言特征, 分别过滤得到新词。 钟将[3]使用互信息和信息熵这两个信息度量反映词语之间的联合度,再创建新的评价函数将两个度量结合起来。
话题发现就是指从大量的UGC文本中检测出用户广泛讨论的话题。 一是基于文本聚类的方法。 例如,利用向量空间模型和主题模型等将相同话题的UGC聚类后,只将相关性强的文本聚集到一起,再设计算法提取出可以展现话题的主题词。 黄波等人用主题模型弥补了传统文本向量化方法的不足,利用 LDA模型提取出文档间的语义信息,分别对文档集进行LDA 建模和 VSM 建模,实现文本间相似度的计算,采用 Single-pass 算法和层次聚类的混合聚类方法对文本做话题聚类。 也有研究直接基于主题词进行话题发
现,计算量较小,效率更高。
2. 话题发现模型

利用[1-3]进行改进,采用不依赖于知识库的分析方法,对一定规模的语料进行计算,根据词频和信息熵的高低提取出语料中的常见词语。 并从以下三方面判断一个文本片段是否能够独立成词: 文本片段出现的频数、文本内部聚合度、粘联度。
- 文本片段的出现频数:
如果一个文本片段在语料中多次出现,那么它有可能是一个词,反之,只是偶然出现的字词组合很难认定为独立的词。 本文目的是检测热点话题,出现频率很少的词不太可能为实时热点,可以忽略,同时也可以快速排除大量候选词,加快算法速度。 因此本文规定一个文本片段的出现频数应超过某个阈值,否则不作为候选词。
- 文本片段的内部聚合度
原理:构成词的字之间必然存在一定相关性,而不仅仅是几个字的随机组合。
假设长度为 n 的文本片段 X 由字 x1x2x3… xn 组成,Count(X) 表示 X 在训练语料中出现的次数。 我们将文本片段 X 看作字符串 X1 与 X2 的组合,则 P(X) =P(X1)P(X2 | X1)。 对于长度为 n 的文本片段 X 有 n -1 种可能的分割方式。 根据最大似然估计的估算公式,P(X2 | X1) 即 Count(X1X2) / Count(X1)。 根据已有研究结论,用互信息度量字串内部紧密性的效果最
佳。 已知文本片段 X 看作文本片段 X1 与 X2 的组合,这个事件的互信息为后验概率与先验概率比值的对数:
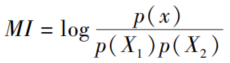
为减少计算量,仅取上式中的真数部分作为字串内部聚合度的度量。 按 X1、X2 所有组合分别计算出这个比值,取其中的最小结果作为文本片段 X 的内部聚合度。 之后对其设定阈值,达不到阈值的文本片段不作为候选词。 在实际计算时,由于客观条件限制,无法使用大规模训练语料来估计参数,因此使用 X 在样本语料中出现的次数代替 X 在训练语料中出现的次数。实验发现取此近似值不会对抽词效果产生重大影响,但可以极大地简化算法。 如果 X 为二字词,简化后的公式为:

其中,P(X) 表 示 文 本 片 段 X 的 内 部 聚 合 度,Length 表示整个样本语料的长度。 Count(X) 表示 X在训练语料中出现的次数。在实际应用中,阈值的设定是一个非常难的方向。
郝晓玲使用 2012 年 9 月的部分微博文本作为实验语料,首先对文本片段的出现频数规定了阈值,出现次数小于 20 的文本片段已经排除。 然后计算文本片段的内部聚合度,如表 1 所示。 左边是最终抽词结果中内部聚合度较高的 5 个词,可以观察到这些字的搭配相对固定,成词方法有限,因此聚合程度很高。 右边列出频数超过 20 次,但内部聚合度较小的文本片段。 这些文
本片段大都是很常见的字词搭配,它们只是偶然组合的可能性更大,不认为可以独立成词。

- 文本片段的粘联度
本文使用信息熵来量化文本片段的粘联度。 在信息论中,熵被用来衡量一个随机变量出现的期望值。 信息熵的计算公式为:
![]()
其中 p(xi) 表示事件 xi 发生的概率, {x1,x2,x3,… ,xi} 为 x 的集合。 b 是对数所使用的底数,通常取2、10 或自然常数 e。 这里选择 e 作为底数。 信息熵直观反应一个离散事件有多随机,随机性越大信息熵就越大。
假定 x 是文本片段左邻字的集合,在语料中该文本片段共出现 n 个不同的左邻字,分别计算这 n 种情况出现的概率并代入公式,就能得到 x 的信息熵,熵越大表示左邻字出现越随机,也说明该文本片段灵活度更高,更可能是一个词。 为信息熵设定阈值,将超过阈值的文本片段加入候选词集合。 郝晓玲利用微博语料进行分析, 可见信息熵最高的文本串是诸如“已经“ “还是“ “没有”等词,这些词频繁出现,使用灵活,符合人们的直观感受,如表 2 所示。

3. 主题词抽取
3.1 抽取规则
基于section2的算法,可以计算上述三个变量,并为其设置合适的阈值,挑选出语料中可以成词的文本片段,再将其运用于UGC关键词检测。实际应用中可以把UGC内容按时间维度区分,探测相邻时间段内出现频率激增的词语,判断出该时间段内可以作为主题词的即时热词.
- 词的相对出现频率。
通过算法抽取出语料中的高频词语,但高频词中往往包含许多无效词语(停词),如 “这种“ ”一个“ “我们”这类词语虽然使用频繁,但并不能代表样本语料的特征。 新的话题的形成应该有一定时效性,也就是说主题词在某个时间窗口内集中大量出现,而在之前的时间窗口内不常出现。
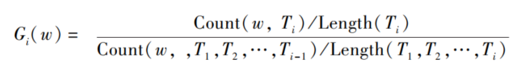
其中,Ti 表示时间窗口 i,Count(w, Ti) 表示词 w在时间窗口i中出现的频数,Length(Ti) 表示时间窗口i 中语料的长度。 在实际计算时,由于只需要将同一时间窗 口 内 的 词 做 横 向 比 较, 而 同 一 时 间 窗 口 的Length(Ti) 都相等,因此将公式简化为:
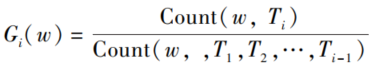
类似"这种" "一个" "我们" 的常用词在每个时间窗口内出现的频率几乎相同,一般不会得到很高的分数;而更能代表当日热点的词应该仅在当日频繁出现。
- 运用贝叶斯平均作平滑处理
运用贝叶斯平均作平滑处理。 假设词 W1在本月仅在当日出现 100 次,词 W2 在本月仅在当日出现 1 次,那么 W1、W2 的得分都等于1,但是显然只有 W1可能是热词,W2 只是偶然出现一次。 因此还需对得分进行平滑,在这里贝叶斯平均的作用就是弱化样本量过小对最终得分的影响。
- 基于词共现的主题词聚类
词共现分析是自然语言处理技术中挖掘词与词关联的重要方法,核心思想是词与词之间的共现频率在一定程度上反映词与
词之间的语义关联。
在大规模的文本语料中,如果两个词频繁地同时出现于同一时间窗口(可能是一篇文档、段落或一句话) 内,则这两个词是语义关联的,且两个词共同出现的频率越高,这两个词的关联度越高。在UGC文本中,某个话题往往包含多个主题词,词的共现率即指两个词在一条微博内容中同时出现的概率。通过词共现分析,可将代表相同主题的不同关键词关联起来。 共现率的计算公式为:
![]()
其中 Count(w1,w2) 表示在整个语料 S 中同时包括词 w1 和词 w2 的UGC数量,n(S) 表示语料 S 中总共包含的UGC数量。 共现词对的抽取类似于形如 X -> Y的蕴涵式,借鉴韩家炜 等观点,本文中的关联规则定义为:给定一个数据集 S,关联规则在 S 中的支持度(Support) 是 D 中事务同时包含 w1、w2 的百分比,即w1、w2 在 所 有 事 务 中 同 时 出 现 的 概 率; 置 信 度(Confidence) 是包含 w1 的事务中同时又包含 w2 的百分比、包括w2 的事务中同时又包括w1 的百分比的平均值。 如果同时满足最小支持度阈值和最小置信度阈值,则认为 w1、w2 是共现词。 结合已有的词共现率公式,得到关于两个词之间共现率的支持度与置信度的计算公式:
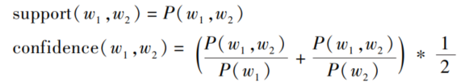
郝晓玲对2014年9 月 11 日微博语料中部分共现词对的计算结果如下:

多次试验之后,认为置信度的阈值设为 0. 005 是较为合理的,支持度的阈值设定为 0. 5,且支持度的阈值需要依据 n(S)(即语料 S 中总共包含的微博数量)相应调整。 相比支持度(即共现率),置信度可以更好地表示两个词之间的关联程度。 对每个词 w,找到所
有能与其关联、符合阈值的共现词,为每个词建立形如Conf (w) = {w1, w2, … , wm} 的共现词集合,集合中的词可能属于同一个话题。 如果一个词与越多的词相关联、且关联程度越大,则认为该词所含的信息量更大,对话题的表达更有意义。 用下式来计算每个词对所属话题的贡献程度:
![]()
假设用 k 个主题词表示一个话题,则提取对该话题贡献程度最大的词(不妨称为关键主题词) 及该词与其关联程度最大的 k - 1 个词作为话题的表示。 具体过程为:
a. 计算所有主题词对所属话题的贡献程度G(w);b. 选出贡献程度最高的主题词,与该词关联度最高的k 个主题词构成一个话题;c. 被使用过的 k 个主题词不再作为其他话题的关键主题词,从主题词列表中删除;d. 重复第 b 步,直到所有主题词都被归类。
4. 实验
4.1 数据来源
郝晓玲使用的微博语料来自数据堂网站( http: / / www. datatang. com / ),实验语料为新浪微博“名人堂风云影响力榜单———媒体影响力榜冶 在2012 年 9 月发布的微博信息集(每位用户采集平均条数为 98. 7)。 榜单上的大都为媒体用户,因此新闻类微博占多数,最终用于实验的共有 9445 条微博文本信息。
4.2 实验步骤
首先进行文本预处理,将每条微博文本按非汉字符号分隔,得到若干文本片段。 枚举文本片段中的所有词组合方式,取最大词长为 4, 对一个长度为 n 的文本片段,至多可以提取出 n + (n - 1) +(n - 2) + (n - 3) = 4n - 6 个不重复的文本串。
- 抽取高频词
阈值设定为词频大于 20,内部聚合度大于 20,信息熵大于 1,共抽取出 2588 个词。 由于所用语料为媒体发布的微博信息,可以看到这类文本在用词上类似于新闻用语。 然后分别从9 月9 日、10 日、11日的微博语料中抽取高频词,抽取结果如表所示。

实验语料中每一天收录的微博条数不同,因此只能纵向观察当日词频。 在 9 月 10 日和 11 日出现频率最高的三个词都是“中国冶 “日本冶 和“钓鱼岛冶,可见这是该时间段内较受关注的话题。 也有许多高频词,如“一个冶 “我们冶 “没有冶 等词并没有实际意义,需要在接下来的步骤中将其剔除。
- 主题词筛选
分别从 9 月 9 日、10 日、11日的语料中抽取高频词,计算词的相对出现频率,并用贝叶斯平均进行平滑处理后的热词。
-
基于词共现的主题词聚类
先对主题词做了一些筛选,因为意义重复的主题词会干扰最后的话题结果,如“光明“ 与 “光明乳业” 在语料中代表相同
的意义,故取含义更详细的“光明乳业“,删除“光明”一词。 然后对前 50 个主题词计算词共现率,最终从三天的微博语料中发现的话题如表所示。

结合当日的新闻资料看热点话题的检测结果基本正确。 如 9 月 9 日国家统计局公布 8 月 CPI,各项价格同比上涨;光明乳业被曝质量问题;南京丁先生被ATM 机吞一万元,谎称多吐钱客服五分钟赶来。 9 月10 日是教师节,同时这天汽柴油价上调,中国及日本
政府就钓鱼岛问题发表声明。 9 月 11 日中央气象台开始把钓鱼岛及周边海域的天气预报纳入到国内城市预报,国足挑战巴西队惨败等。 在 9 月 10 日与 11 日都提取出两条与钓鱼岛相关的话题,实际上它们是属于同一个主题之下,但是从新闻角度看出发点并不同,如“国有化,日本政府,钓鱼岛,购岛,确定冶 是指日本单方面确定购买钓鱼岛,“主权,领土,中国政府,钓鱼岛,非法,购岛冶 是指中国政府对钓鱼岛宣告领土主权,从这个角度认为这样划分话题也是可行的。
5. 参考文献
[1] 顾摇 森. 基于大规模语料的新词发现算法[J]. 程序员,2012(7):54-57
[2] 贺摇 敏,龚才春,张华平,等. 一种基于大规模语料的新词识别方法[J]. 计算机工程与应用,2007,43(21)157-159.
[3] 钟摇 将,耿升华,董高峰. 一种新词检测方法研究[J]. 数字通信,2013,40(2):1-5.

