
- 1[Linux C] linux C实现trim功能_c trim_string
- 2Spring MVC AbstractHandlerMapping原理解析
- 3解决git clone时报SSL错误_git clone ssl
- 4西安华为OD面试体验_西安华为od怎么样
- 5Linux怎么对文件内容trim,Linux平台下SSD的TRIM指令的最佳使用方式(不区别对待NVMe)...
- 6【鸿蒙手机】获取UDID,并添加签名认证_华为手机udid
- 7python 全栈开发,Day75(Django与Ajax,文件上传,ajax发送json数据,基于Ajax的文件上传,SweetAlert插件)...
- 8亚马逊云计算技术应用有哪些?_亚马逊云技术侧重点
- 9小心被偷脸!天天用的人脸识别风险原来这么多?_人脸验证是否会泄露信息
- 10STM32CubeMX学习笔记(10)——SPI接口使用(读写SPI Flash W25Q64)_stm32cubemx配置spi
CUDA编程 - Nsight system & Nsight compute 的安装和使用 - 学习记录_cuda nsight
赞
踩
在 cuda 编程中,经常会用到 Nsight system 和 Nsight compute 进行性能分析等,下面做个学习总结。
本篇包括安装和常用分析思路总结,具体实践操作总结会放在下一篇博客。
安装和下载地址
一、Nsight Systems
1.1、主要应用
主要倾向于观察全局的 Profiling,比如 核函数读写情况,核函数之间的调度情况,SM占有率,CPU和GPU之间的异步执行的情况等。

1.2、比较常用的分析
1.2.1、情况一
可以对 kernel 执行 和 memory 进行 timeline 分析,尝试寻找是否可以优化
常用的优化角度:
- 隐藏 memory access
- 多流调度
- 删除冗长的 memory access
- 融合kernel减少 kernel launch的overhead
- CPU与GPU的 overlapping
一、比如核函数与核函数之间的执行情况,是根据 timeline 进行分析的
比如下面的 timeline 可以发现核函数与核函数之间有延迟,或者是核函数的启动延迟等,都是可以展示出来的
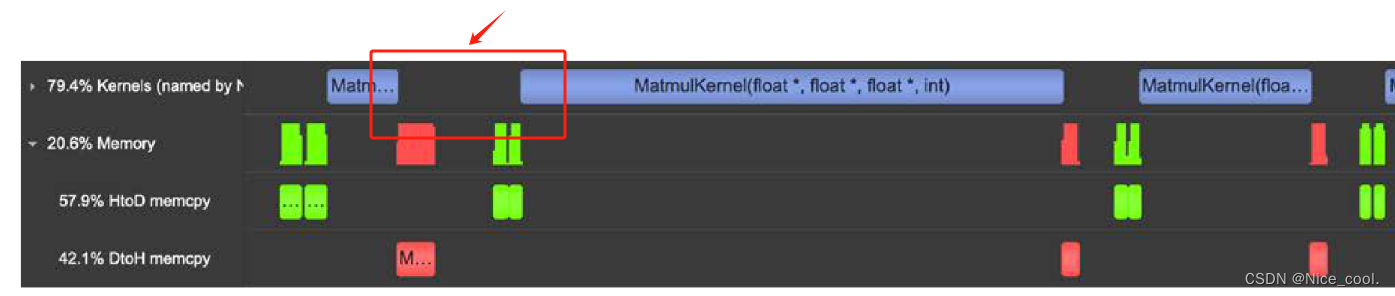
二、 在多个 stream 的时候,可以查看调度情况和 Overlap 等,从而分析出如何进行更高效的调度

1.2.2、情况二
分析 DRAM 以及 PCIe 带宽的使用率 ,分析 SM 中 warp 的占有率
一、可以从中分析到哪些带宽没有被充分利用,从而进行优化

二、可以从中知道一个 SM 中资源是否被用满

二、Nsight Compute
2.1、主要应用
主要分析核函数的内部的操作,比如显示不同block size核函数的执行时间,执行的吞吐量,带宽分析等。
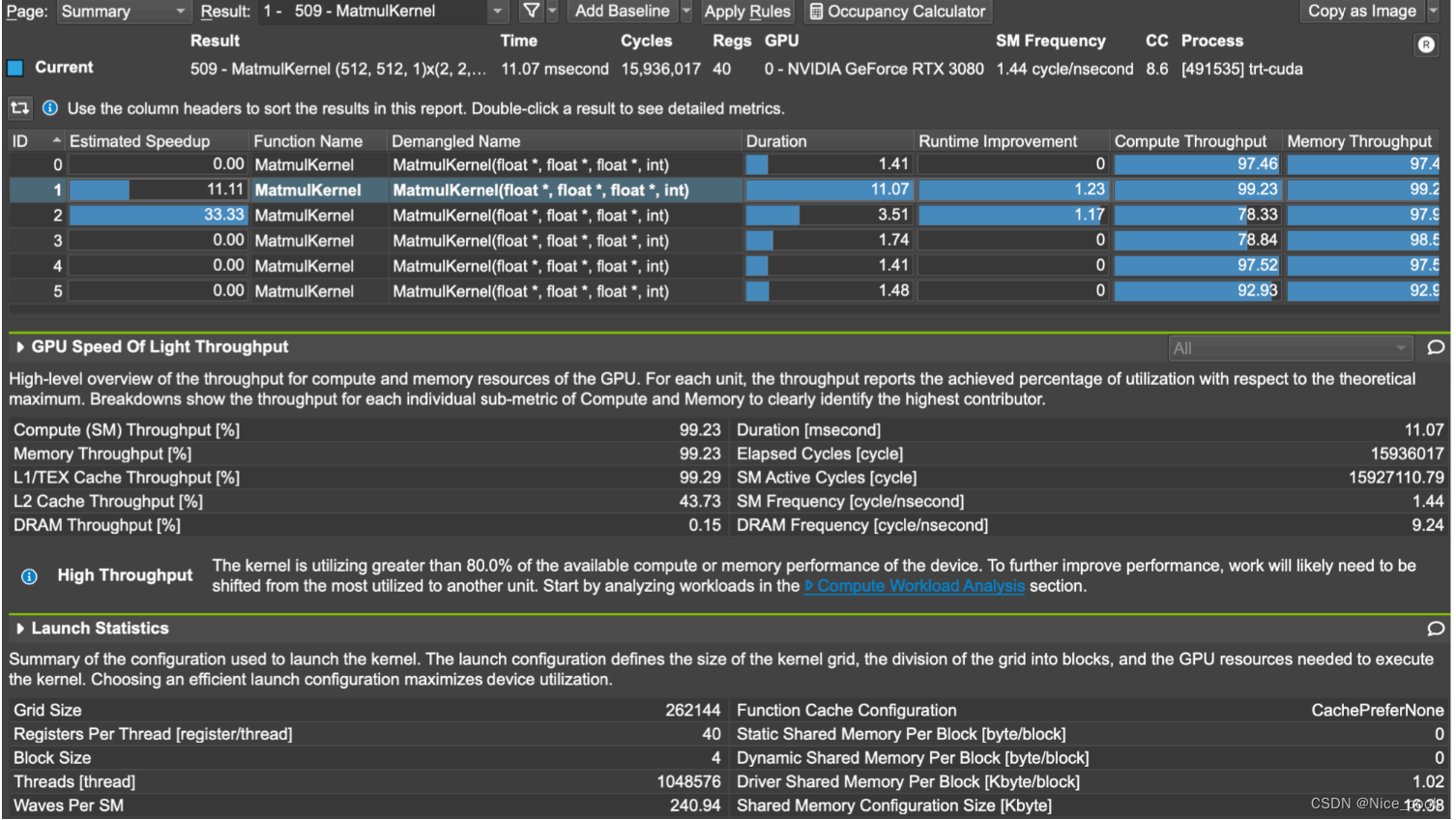
2.2、比较常用的分析
2.2.1、情况一
一、roofline analysis
- 1
对核函数进行 roofline analysis,可以知道现在的核函数是计算密集型还是仿真密集型。即可以判断下一步优化是提高计算度,计算密度,还是优化访存等。
并且根据 base line 进行优化比较,比如设置两个核函数,对比核函数对性能的影响

比如在下图 蓝色在绿色的上方

2.2.2、情况二
二、occupancy analysis (占有率)
- 1
对核函数的各个指标进行估算一个warp的占有率的变化

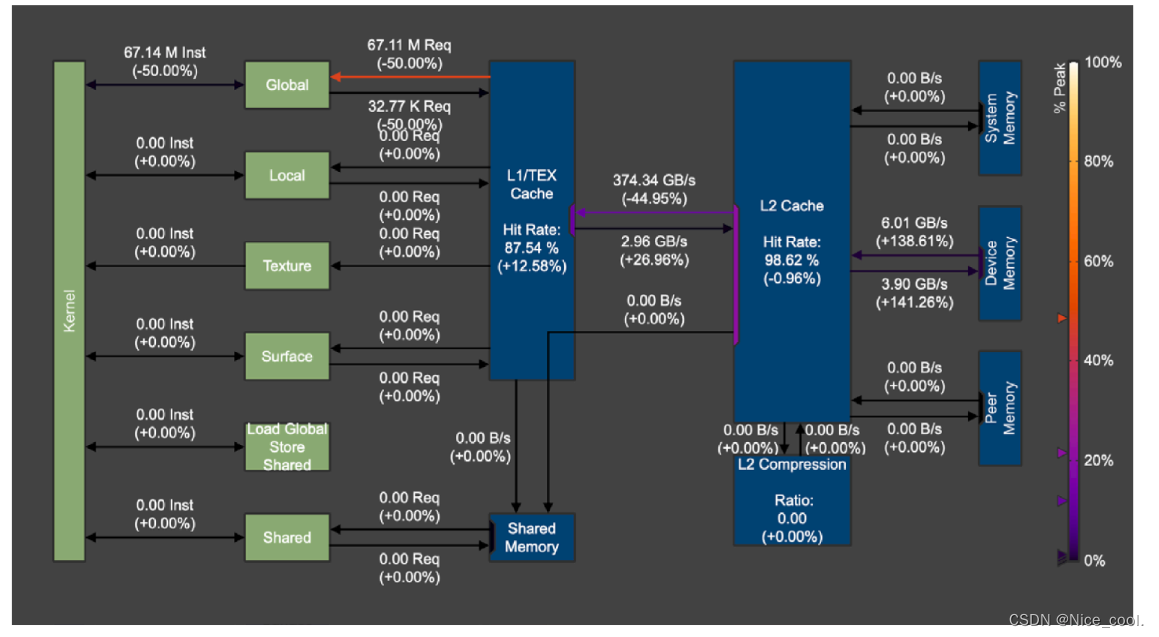
三、memory bindwidth analysis
- 1
针对核函数中对各个memory的数据传输的带宽进行分析。可以比较好的理解memory架构
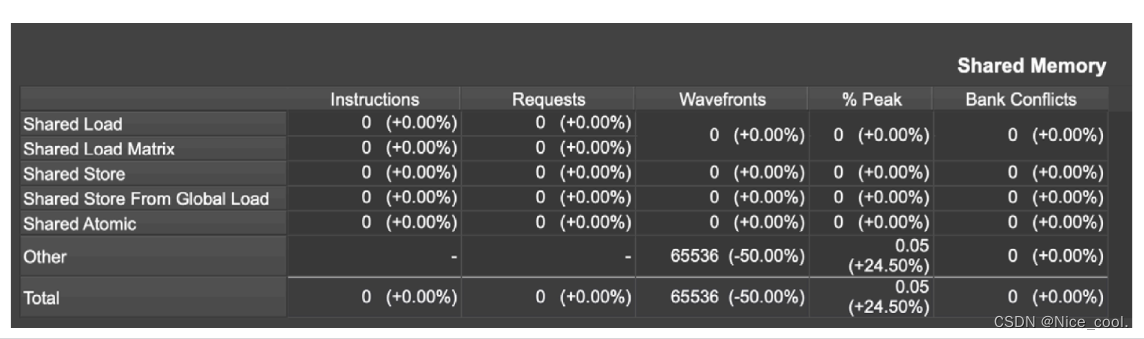
四、shared memory analysis
- 1
针对核函数中对 shared memory 访问以及使用效率的分析
三、两者的比较
3.1、Nsight systems
偏重于可视化application的整体的profiling以及各个细节指标
- PCIe bindwidth
- DRAM bindwidth
- SM Warp occupancy
- 所有核函数的调度信息
- 所有核函数的执行时间,以及占用整体时间的比例
- 多个Stream之间的调度信息
- 同一个stream中的多个队列的调度信息
- CPU和GPU之间的数据传输耗时
- Application整体上的各个核函数以及操作的消耗时间排序
- 捕捉同一个stream中的多个event
整体上会提供一些比较全面的信息,我们一般会从这里得到很多信息进而进行优化
3.2、Nsight compute
偏重于可视化每一个CUDA kernel的profiling以及各个细节指标
-SM中计算吞吐量
-L1 cache数据传输吞吐量
-L2 cache数据传输吞吐量
-DRAM数据传输吞吐量
-当前核函数属于计算密集型还是访存密集型
•Roofline model分析
-核函数中的L1 cache的cache hit几率, cache miss几率的多少
-核函数中各个代码部分的延迟
•精确到代码部分进行highlight
-核函数的load bandwidth, store bandwith, load次数, store次数
-L1 cache/shared memory, L2 cache, global memory中的memory access scheduling
-设置baseline,来进行核函数的优化前后的效率对比
整体上能够得到一个针对某一个kernel的非常精确的profiling,源码级别的性能捕捉,以及优化推荐
四、参考使用途径
方法一
在 host 端使用 Nsight 进行 ssh 远程 profiling
方法二
在 remote 端使用 Nsight 进行直接 profiling
方法三
在 remote 端通过CUI获取statistics之后传输到host端进行查看
***在当host端的nsight不能够直接ssh到 target device 情况下使用。比如说Jetson的profiling
方法四
在 remote 端直接使用CUI进行分析
***在当host端的nsight不能够直接ssh到 target device 情况下使用。比如说 Jetson 的profiling

