
- 1一张图片组合一组动作就可以生成毫无违和感的视频!_github magic animate
- 2python中importlib库用法详解_importlib.util.find_spec
- 3来看一看滑动时间窗格_移动时间窗
- 4android 自定义图片合集(自定义控件)_android自定义控件获取图片集合
- 5ERR! Error: CERT_UNTRUSTED_982 error error: cert_untrusted
- 6江西单招学计算机的学校有哪些,2020年江西单招都有哪些学校
- 7Gradle kotlin Springboot多模块导致无法引用kotlin的类文件(BootJar)_springboot spi机制 无法读取kotlin
- 8pytorch:图像识别模型与自适应策略_set_parameter_requires_grad
- 9聊聊鸿蒙系统与开发者生态前景_鸿蒙开发发展前景
- 10解读 Amazon Q | 用 AI 聊天机器人连接你与未来的无限可能
自然语言处理NLP概论_nlp概述
赞
踩
1 什么是NLP
在人工智能出现之前,机器可以理解结构化的数据,比如excel,数据库里面的数据,但是对于文本,视频,语音等非结构化的数据,虽然蕴含了极大的信息,但是机器却不能够直接理解,所以自然语言处理学科就应运而生。NLP就是人和计算机之间沟通的桥梁。
1.1 NLP的两大任务
NLP有两个核心任务,分别是
- NLU:自然语言理解(Natural Language Understanding)
- NLG:自然语言生成(Natural Language Generating)

通过一张图来说明二者的应用
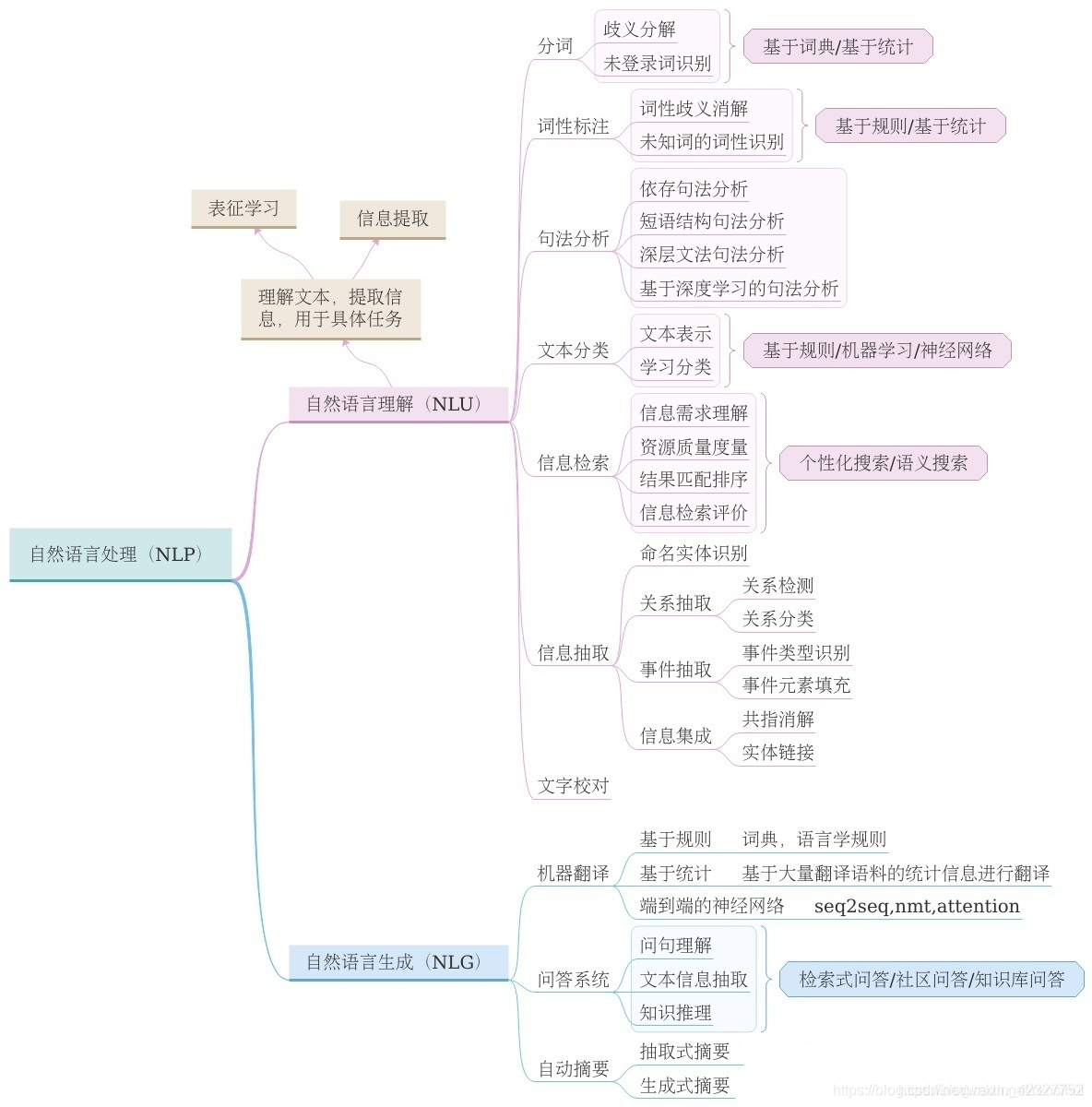
1 NLU 自然语言理解
1.在NLU领域的难点:
- 语言的多样性
- 语言的歧义性
- 语言的鲁棒性
- 语言的知识依赖
- 语言的上下文
2.知识图谱:
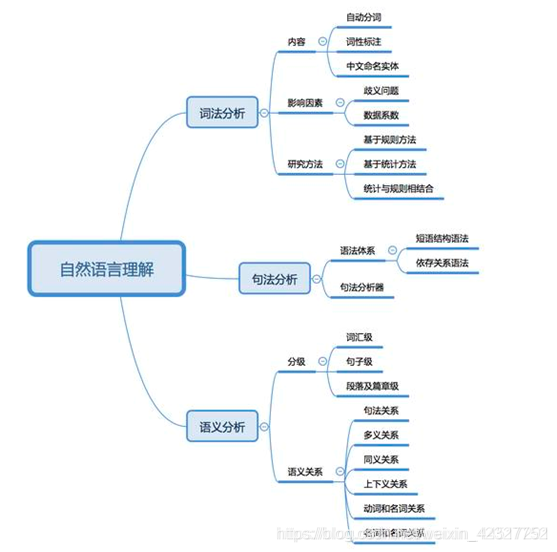 3.发展历程
3.发展历程
2 NLG 自然语言生成
定义:将非语言格式的数据转换成⼈类可以理解的语言格式。
- 1)text-to-text:文本到语言的生成
- 2)data-to-text:数据到语言的生成
- 3)image-to-text:图像到语言的生成
步骤:
第一步:内容确定 - Content Determination
首先,NLG 系统需要决定哪些信息应该包含在正在构建的文本中,哪些不应该包含。通常数据中包含的信息比最终传达的信息要多。
第二步:文本结构 - Text Structuring
确定需要传达哪些信息后,NLG 系统需要合理的组织文本的顺序。例如在报道一场篮球比赛时,会优先表达「什么时间」「什么地点」「哪2支球队」,然后再表达「比赛的概况」,最后表达「比赛的结局」。
第三步:句子聚合 - Sentence Aggregation
不是每一条信息都需要一个独立的句子来表达,将多个信息合并到一个句子里表达可能会更加流畅,也更易于阅读。
第四步:语法化 - Lexicalisation
当每一句的内容确定下来后,就可以将这些信息组织成自然语言了。这个步骤会在各种信息之间加一些连接词,看起来更像是一个完整的句子。
第五步:参考表达式生成 - Referring Expression Generation|REG
这个步骤跟语法化很相似,都是选择一些单词和短语来构成一个完整的句子。不过他跟语法化的本质区别在于“REG需要识别出内容的领域,然后使用该领域(而不是其他领域)的词汇”。
第六步:语言实现 - Linguistic Realisation
最后,当所有相关的单词和短语都已经确定时,需要将它们组合起来形成一个结构良好的完整句子。
典型应用:
-
1)应用目标:能够大规模的产生个性化内容;帮助人类洞察数据,让数据更容易理解;加速内容生产。
-
2)自动写新闻(自动定稿),聊天机器人(机器客服),BI(商业智能)的解读和报告生成
-
3)论文写作,摘要生成,自动作诗,新闻写作、报告生成,
1.2 NLP的发展和技术路线
NLP的两种途径
1 基于传统机器学习的NLP流程

其中,中文语料预处理的四个核心:

2 基于深度学习的NLP流程

3 方法路线
知识图谱:
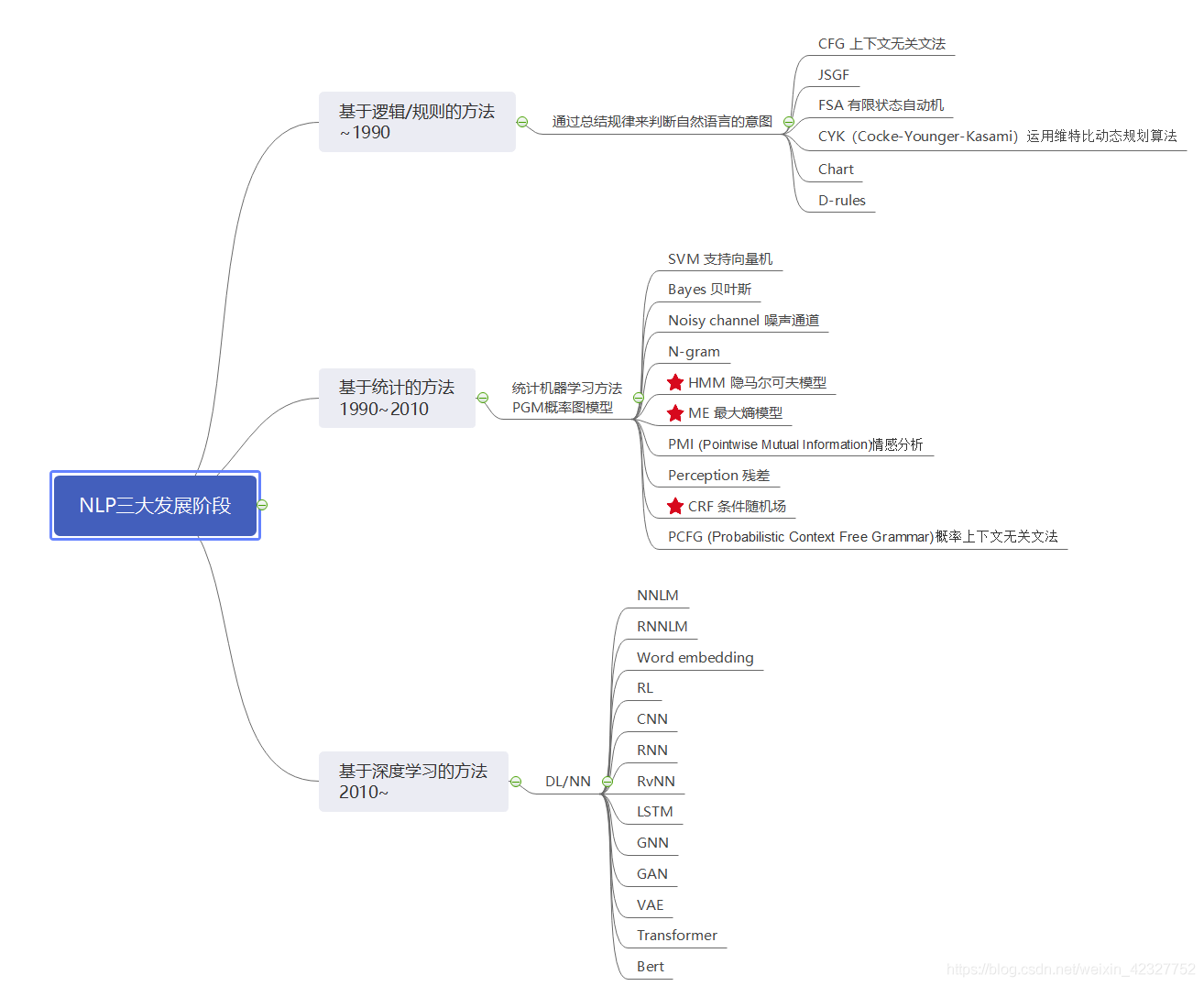
曾经NLP上课时候老师讲的ppt:

再附上一张宗成庆老师的统计自然语言书籍思维导图
1.3 目前研究方向
 2019
年
A
C
L
投
稿
热
门
2019年ACL投稿热门
2019年ACL投稿热门
2019
年
A
C
L
投
稿
热
门
2019年ACL投稿热门
2019年ACL投稿热门
 2020
A
C
L
投
稿
热
门
2020ACL投稿热门
2020ACL投稿热门
2020
A
C
L
投
稿
热
门
2020ACL投稿热门
2020ACL投稿热门
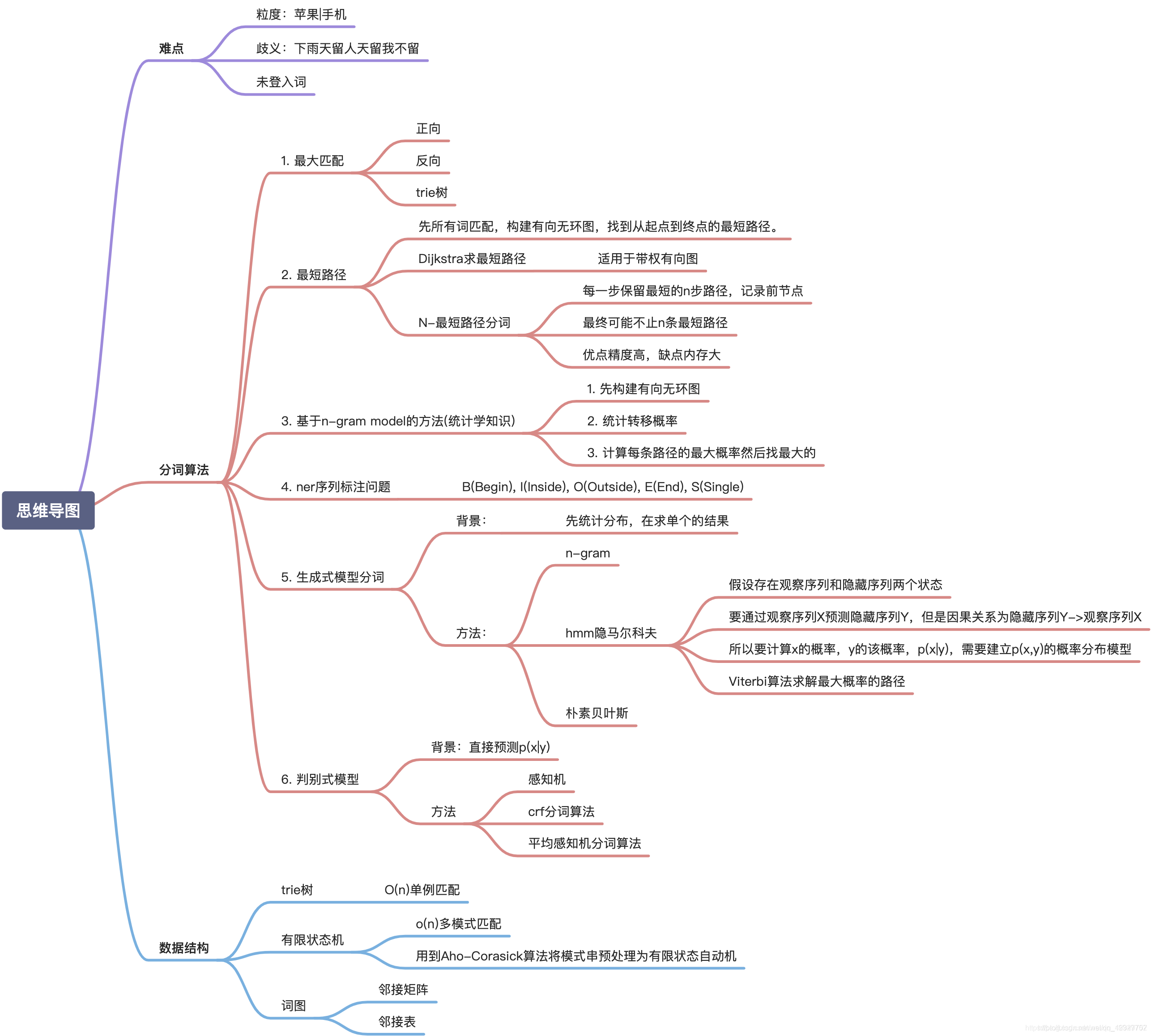
2 词法分析(Lexical Analyse)
词是最小的能够独立运用的语言单位,因此,词法分析是其他一切自然语言处理问题(例如:句法分析、语义分析、文本分类、信息检索、机器翻译、机器问答等)的基础,会对后续问题产生深刻的影响。

在词法分析中,主要有分词,词性标注,(命名)实体识别等任务。最终任务就是:将输入的句子字串转换成词序列并标记出各词的词性。
2.1 分词
分词就是将句子,段落,篇章等等长文本分解为已字词为单位的数据结构,得到结构化数据,方便后续处理。
1. 为什么需要分词?
- 将复杂问题转换为数学问题。通过将文本等等【非结构化数据】转换为【结构化数据】,可以进行后续数学建模。

- 词具有合适的粒度。此时表达含义的最小单位,字的粒度太小,无法表达完整的含义;而句子的粒度太大,承载的信息量过多。

2. 中英文分词的区别
-
英文由于空格将单词自然的分开,而中文没有空格之类的符号,所以中文分词的难度相对较大
-
英文单词有多种形态,比如过去式,现在时,将来时等等,所以需要词形还原(Lemmatization:does,doing,did还原成do)和词干提取(Stemming:cities转换为city),而中文不需要。
-
中文分词需要考虑粒度的问题。比如【中国科技技术大学】可以有几种分词方式:
- 中国 / 科技技术 / 大学
- 中国 / 科学 / 技术 / 大学
- 中国科学技术大学
3. 中文分词的难点
- 没有统一的标准。没有统一的规范/标准来制定分词规则,每个公司都有自己的分词标准。
- 歧义词难以切分。
- 新词如何识别?
4. 分词方法

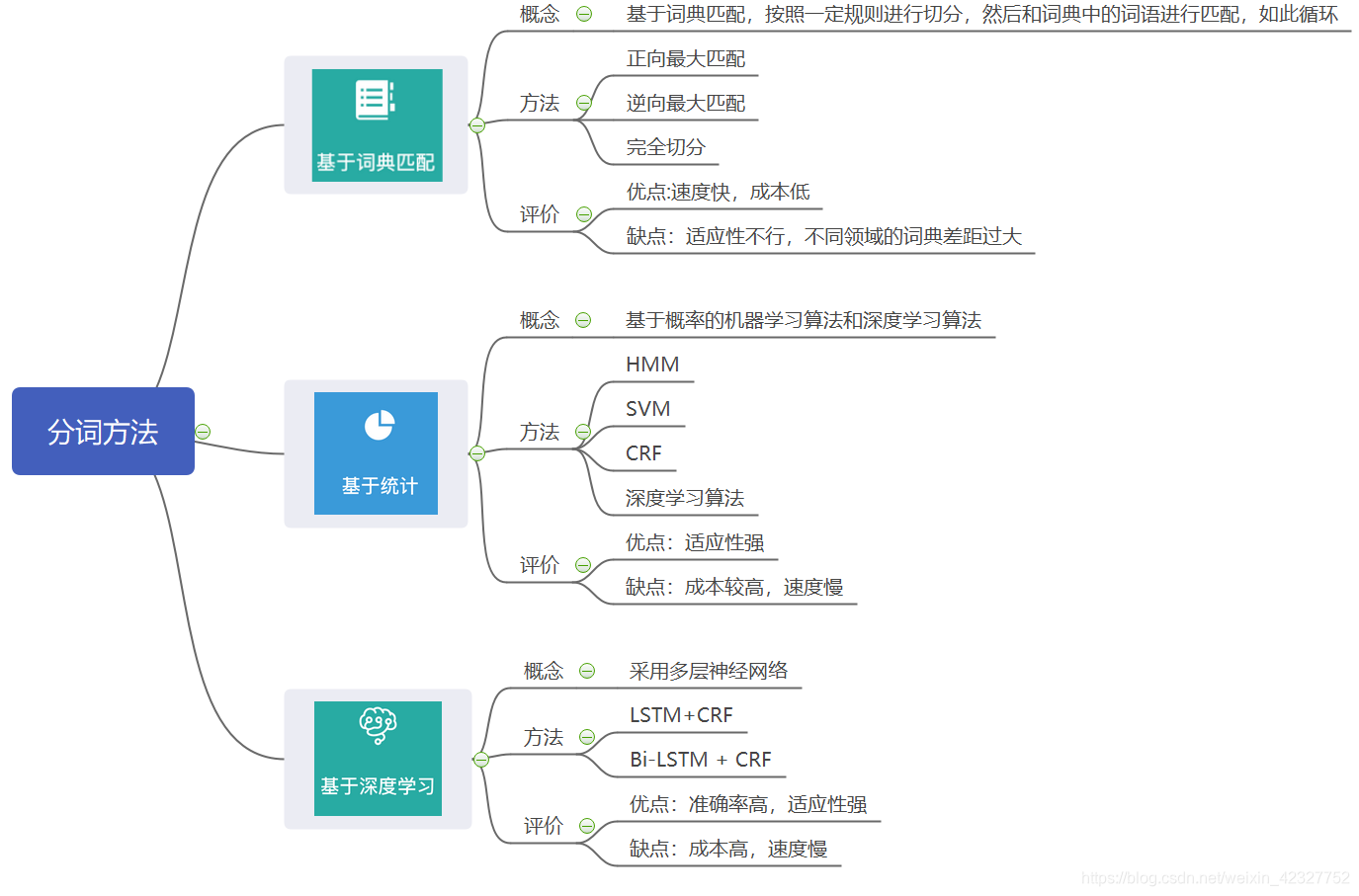
5 分词知识图谱
2.2 词性标注
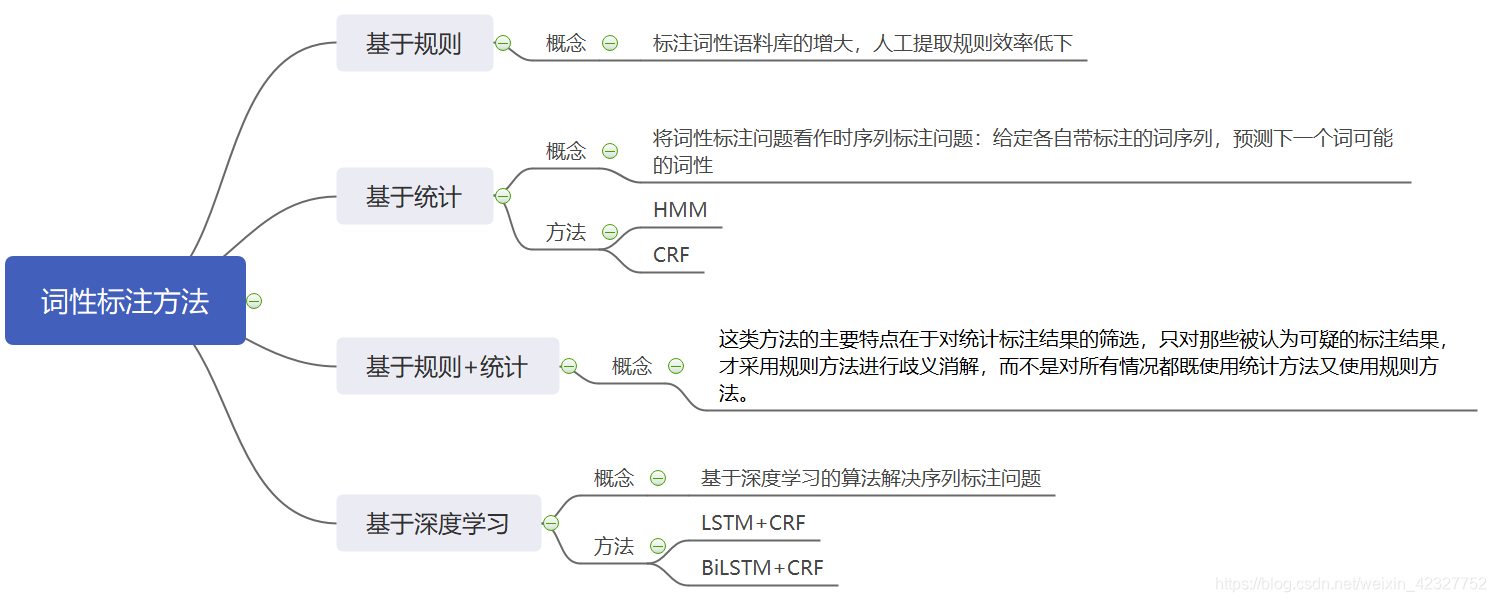
1 什么是词性标注
词性:单词的语法分类,比如名次动词形容词副词等等。
词性标注:为句子中的每一个单词预测一个词性标签的任务,如下图:

2 词性标注难点
- ①汉语缺乏词的形态变化,不能像外语那样,直接从词的形态变化上来判别词的类别;
- ②常用词的兼类现象严重。兼类词使用频度高,兼类现象复杂多样,覆盖面广,又涉及汉语中大部分词类,使得词类消岐的任务困难重重;
- ③研究者本身的主观因素也会造成兼类词处理的困难。据统计,常见的汉语兼类现象具有以下的分布特征:
- 1.在汉语词汇中,兼类词数量不多,约占总词条数的 5- 11% 。
- 2.兼类词的使用频率很高,越常用的词,其词性兼类现象越严重。
- 3.兼类现象分布不均。如何高效地进行兼类词排歧是目前词性标注面临的主要困难之一。
3 词性标注常用方法

4 语料库和标注集
同分词一样,词性标注也没有一个统一的标准,无论是词性划分的颗粒度还是词性标签都不一致。一方面各派系林立,互不兼容;另一方面,部分语料库称为内部资料,不公开给社会。
常用的公开语料库有:
- 《人民日报》语料库和PKU标注集
- 国家语委语料库和863标注集
5 语料标注工具推荐
- Jieba :结巴github地址
- HandLP: HandLP的github地址
- StanfordCoreNLP: github地址
2.3 命名实体识别(NER)
1 什么是命名实体识别
命名实体识别(Named Entity Recognition,简称NER),是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。
2 命名实体识别方法

3 实现方式

-
有监督的学习方法:
这一类方法需要利用大规模的已标注语料对模型进行参数训练。目前常用的模型或方法包括隐马尔可夫模型、语言模型、最大熵模型、支持向量机、决策树和条件随机场等。值得一提的是,基于条件随机场的方法是命名实体识别中最成功的方法。 -
半监督的学习方法:
这一类方法利用标注的小数据集(种子数据)自举学习。 -
无监督的学习方法:
这一类方法利用词汇资源(如WordNet)等进行上下文聚类。 -
混合方法:
几种模型相结合或利用统计方法和人工总结的知识库。
值得一提的是,由于深度学习在自然语言的广泛应用,基于深度学习的命名实体识别方法也展现出不错的效果,此类方法基本还是把命名实体识别当做序列标注任务来做,比较经典的方法是LSTM+CRF、BiLSTM+CRF。
4 推荐工具

3 句法分析(Syntactic Analyse)
句法分析就是找到一个句子的组成成分,打上标签。如下所示:

3.1 成分句法分析
成分句法分析要做的是,给定一个句子,句子中每个词汇都是成分。它们的标签,就是它们的词性。接着,相邻的成分,可以组合成一个更大的单位。比如 deep 和 learning 可以组合起来成为一个名词短语。very 和 powerful 也可以组合起来,变成一个形容词短语。is 和 very powerful 又可以组合起来,变成一个动词短语。最后这个动词短语和名词短语组合起来,变成整个句子。

1 成分标签

2 方法
- 基于规则:CFG(上下文无关法)
- 基于统计:PCFG(概率上下文无关)
- 基于深度学习
3 成分结构与依存结构关系
成分结构树可以转换为依存结构树,反之不能。可以通过以下方法转换:
- 定义中心词表,为句法树每个节点选择中心子节点
- 同一层内将非中心子结点的中心词依存到中心子结点的中心词上,下一层的中心词依存到上一层的中心词上,从而得到相应的依存结构。
3.2依存句法分析
依存句法是由法国语言学家L.Tesniere最先提出。它将句子分析成一颗依存句法树,描述出各个词语之间的依存关系。也即指出了词语之间在句法上的搭配关系,这种搭配关系是和语义相关联的。
在自然语言处理中,用词与词之间的依存关系来描述语言结构的框架称为依存语法(dependence grammar),又称从属关系语法。利用依存句法进行句法分析是自然语言理解的重要技术之一。
依存句法通过分析语言单位内成分之间的依存关系解释其句法结构,主张句子中核心动词是支配其他成分的中心成分。而它本身却不受其他任何成分的支配,所有受支配成分都以某种关系从属于支配者。

1 依存关系标签表

2 常用方法
-
基于规则:早期基于规则的方法包括类似CYK的动态规划算法,基于约束满足的方法和确定性分析策略等。
-
基于统计:
- 生成式依存分析方法
- 判别式依存分析方法
- 确定式依存分析方法
-
基于深度学习:近年来,深度学习在句法分析课题上逐渐成为研究热点,主要研究工作集中在特征表示方面。传统方法的特征表示主要采用人工定义原子特征和特征组合,而深度学习则把原子特征(词、词性、类别标签)进行向量化,在利用多层神经元网络提取特征。

