
热门标签
热门文章
- 1鸿蒙OS南向开发(二)LOT上云 ·智慧家居方案_谈谈你对鸿蒙南向开发技术的理解
- 2linux环境离线安装jdk8_linux离线安装arm jdk1.8
- 3长轮询实现方式(fetch,sse)_fetch sse
- 4科技团队治理能力成长路线图
- 5xinference
- 6Suno AI:现在任何人都可以创作所有类型的音乐
- 7大白话带你认识JVM_大白话jvm性能测试
- 8ThinkPHP8多应用配置及不同域名访问不同应用的配置【详解】_thinkphp8 多应用
- 9命名实体识别NER & 如何使用BERT实现_bert ner
- 10BERT+textCNN+aclImdb文本情感分析(改)_bert+textcnn情感分析模型设计图
当前位置: article > 正文
Python实例--遍历文件夹下所有的文件或文件夹_python遍历文件夹中的文件夹
作者:笔触狂放9 | 2024-03-26 20:12:47
赞
踩
python遍历文件夹中的文件夹
一、前言
最近在跑深度学习的网络模型,跑通代码的前提是要读取数据集,众所周知,深度学习的数据集是非常庞大的,动辄就几个G,想要一个一个的输入无疑是天方夜谭,因此,利用Python遍历数据集就显得非常重要了。同时我对遍历数据集的操作还不太熟悉,于是在此记录一下!一般有2种情况,第一种是文件夹中只有文件时,这种情况比较简单;第2种是文件夹中既有文件又有文件夹时。首先,我们需要导入os这个必要的模块。
import os
- 1
二、文件夹内只有文件时
当目标文件夹中只有文件时,使用os模块的listdir(path)方法即可;该方法可以返回目标路径下的文件和文件夹的名字列表,参数path就是目标文件夹的路径。
'''
path:要遍历的文件夹路径
return:返回目标文件夹下的文件和文件夹的名字列表
'''
filelist = os.listdir(path)
- 1
- 2
- 3
- 4
- 5
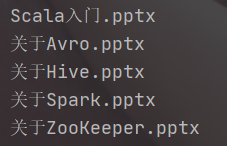
- Hadoop资料
- Scala入门.pptx
- 关于Avro.pptx
- 关于Hive.pptx
- 关于Spark.pptx
- 关于ZooKeeper.pptx
- 1
- 2
- 3
- 4
- 5
- 6
filelist = os.listdir('E:\Hadoop资料')
for filename in filelist:
print(filename)
- 1
- 2
- 3
三、文件中既有文件又有文件夹
当目标文件夹中既有文件又有文件夹时,我们使用listdir()方法就只能获得第一层子文件或文件夹了,而子文件夹中的内容便获取不到了。这时候我们需要用到os.walk()方法:传入目标路径即可。该方法可以递归的找出目表路径下的所有文件。
'''
path:目标文件夹
return
filepath:filepath就是目标路径下所有文件的路径
dirnames:dirnames是目标路径下的所有目录名称
filenames:filenames则是各个路径下的文件名称列表
'''
filepath,dirnames,filenames = os.walk(path)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
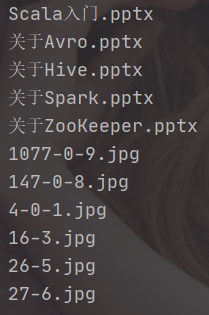
- Hadoop资料
- Scala入门.pptx
- 关于Avro.pptx
- 关于Hive.pptx
- 关于Spark.pptx
- 关于ZooKeeper.pptx
- demo1
- 4-0-1.jpg
- 147-0-8.jpg
- 1077-0-9.jpg
- demo2
- 16-3.jpg
- 26-5.jpg
- 27-6.jpg
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
fileOrdirlist = os.walk('')
for filepath,dirnames,filenames in fileOrdirlist:
for filename in filenames:
print(filename)
- 1
- 2
- 3
- 4
希望对大家有所帮助!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/319445
推荐阅读

相关标签

