
- 1Paddle OCR 常用cmd命令_cmd脚本启动ocr
- 2CSS入门详细笔记【2023.07】_css 浏览器判断table样式
- 3文本分类学习 (七)支持向量机SVM 的前奏 结构风险最小化和VC维度理论_svm中xi∈rn
- 4多模态文本分类技术_多模态分类
- 5vue-router传递参数的几种方式_this.$router.resolve传params
- 6【ChatGPT】使用 GPT-4 探索大模型在“智能数据应用”领域的应用思路:NLP ---> DSL ---> SQL(ChatGPT DSL 能力挖掘) 2_nlp转dsl
- 7【NLP】NLP从业人员必须知道的十大必备知识库(附资料下载)
- 8深度学习笔记(5)_池化层输出的是什么
- 9通过Jenkins实现Unity多平台自动打包以及相关问题解决_unity通过jenkins实现自动化打包
- 10抓包工具:Sunny网络中间件
MySQL数据库基本使用_mysql环境下数据库分为什么和什么其作用分别是
赞
踩
一、数据库的概念及作用
1.数据库的概念
数据库就是以一定格式进行组织的数据的集合。通俗来看数据库就是用户计算机上的一些具有特殊格式的数据文件的集合。
问题:
既然数据库本身就是一种文件,那用户可以不使用数据库而使用普通文件来进行数据的存储吗? 从理论上是可以的。
但是相比于普通文件,数据库有以下特点:
- 持久化存储
- 读写速度极高
- 保证数据的有效性
- 对程序支持性非常好,容易扩展
2.数据库的作用

二、数据库分类及特点
1.数据库分类
- 关系型数据库
- 非关系型数据库

2.关系型数据库
关系数据库,是指采用了关系模型来组织数据的数据库,简单来说,关系模型指的就是二维表格模型.
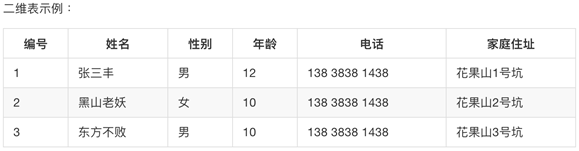
MySQL采用了双授权政策,它分为社区版和商业版,由于其体积小、速度快、总体使用成本低,尤其是开源,一般中小型网站的开发都选择MySQL作为网站数据库。

3.非关系型数据库
非关系型数据库,又被称为NoSQL(Not Only SQL ),意为不仅仅是SQL,对NoSQL 最普遍的定义是“非关联型的”,强调Key-Value的方式存储。

注:本部分主要讨论关系型数据库
三、数据库管理系统
1.数据库管理系统介绍
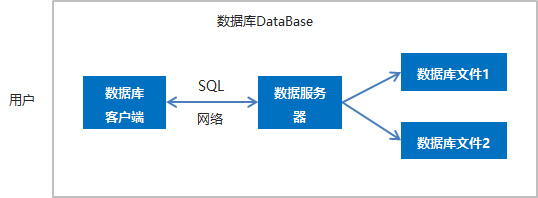
数据库管理系统( Database Management System,简称DBMS)是为管理数据库而设计的软件系统。
包括三大部分构成
- 数据库文件集合:主要是一系列的数据文件,作用是存储数据。
- 数据库服务器:主要负责对数据文件以及文件中的数据进行管理。
- 数据库客户端:主要负责和服务端通信,向服务端传输数据或者从服务端获取数据。
2.SQL语句
数据库客户端和数据库服务端怎么通讯呢?
数据库客户端通过“特殊的语言”告诉服务端,客户端想要做什么. 这个专门的语言就是SQL语句。

所以,我们学习数据库的重点在于如何编写SQL 语句。
SQL(Structured Query Language)是结构化查询语言,是一种用来操作RDBMS的数据库语言。当前几乎所有关系型数据库都支持使用SQL语言进行操作,也就是说可以通过 SQL 操作 oracle,sql server,mysql,sqlite 等等所有的关系型的数据库。
那么什么是RDBMS呢?
Relational Database Management System 就是所谓的关系型数据库管理系统RDBMS,是专门用来管理关系型数据库的系统
常见的关系型数据库:
- oracle:银行,电信等项目
- ms sql server:在微软的项目中使用
- sqlite:轻量级数据库,主要应用在移动平台
- mysql:web时代使用最广泛的关系型数据库。
3.关系型数据库中核心元素

4.知识回顾
RDBMS的组成:
- 数据库客户端
- 数据库服务端
- 数据库文件集合
SQL语句:
- 关系型数据库中客户端和服务端之间通讯的语言
关系型数据库中的核心元素:
- 字段:一列数据类型相同的数据
- 记录:一行记录某个事物的完整信息的数据
- 数据表:有若干字段和记录组成
- 数据库:由若干数据表组成
四、MySQL环境搭建
1.服务端安装
安装服务器端: 在终端中输入如下命令,回车后,然后按照提示输入
sudo apt-get install mysql-server
- 1
2.服务端启动
启动服务:
sudo service mysql start
- 1
查看进程中是否存在MySQL服务:
ps ajx|grep mysql
- 1
ps:查看当前系统进程 -a 显示所有用户进程 -j 任务格式显示进程 -x显示无控制终端进程
3.服务端停止和重启
停止服务:
sudo service mysql stop
- 1
重启服务:
sudo service mysql restart
- 1
4.客户端安装
在终端运行如下命令,按提示填写信息:
sudo apt-get install mysql-client
- 1
最基本的连接命令如下,输入后回车:
mysql -uroot -pmysql
- 1
退出链接: exit或者quit
5.MySQL配置文件(了解)
配置文件目录为/etc/mysql/mysql.cnf:

进入mysql.conf.d目录,打开mysql.cnf,可以看到配置项:
配置文件路径:/etc/mysql/mysql.conf.d/mysqld.cnf

6.主要配置选项

五、客户端Navicat的使用
1.Navicat
MySQL数据库本身自带有命令行工具. 但自带的工具在功能上和易用性上总比不上第三方开发的工具, 比如Navicat, 使用它你几乎能完成任何针对 MySQL 的管理任务。
Navicat是一套快速、可靠并价格适宜的数据库管理工具, 适用于三种平台, Microsoft Windows、Mac OS X 及 Linux。可以用来对本机或远程的 MySQL、SQL Server、SQLite、Oracle 及 PostgreSQL 数据库进行管理及开发. 专 为简化数据库的管理及降低系统管理成本而设. 它的设计符合数据库管理员、开发人员及中小企业的需求。Navicat 是以 直觉化的图形用户界面而建的, 让你可以以安全并且简单的方式对数据库进行操作。
2.创建数据库
①.连接数据库之后在左侧栏当前连接处右击,选择新建数据库
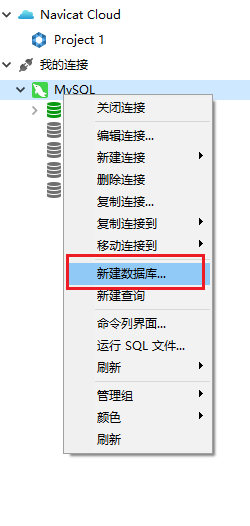
②.点击后弹出新窗口,填写数据库名称并选择语言

③.填写完成后点击“确定”创建数据库,在左侧会出现刚才创建的数据库,双击打开
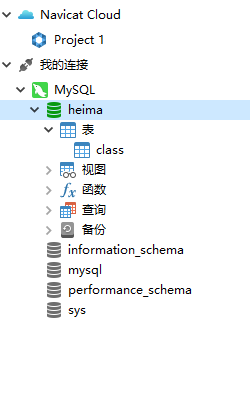
3.编辑数据库
①.在左侧栏数据库上右击,弹出菜单, 选择 “删除数据库”, 可以将数据库删除
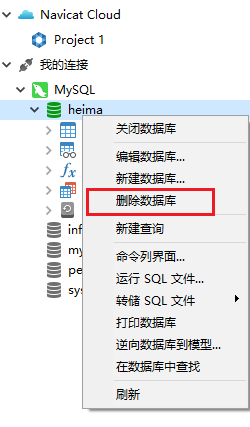
②.选择“编辑数据库”,可以修改字符集、排序规则

4.创建数据表
①.点击工具栏“表”,在第二行显示关于表的命令,点击“新建表”

5.编辑数据表
①.弹出新窗口,输入表名,填写各字段

②.点击某个单元格,即可编辑值,修改完后,点击底部的勾生效。
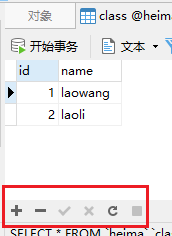
③.点击某个单元格,再点击减号,可以删除
六、MySQL数据类型
1.数据类型
酒分为很多种:白酒、红酒、啤酒等等。
同样的,程序中的数据也分为不同的类型。
储存和运输酒的时候要根据酒的特点选用合适的==容器 ==
常用数据类型:int、decimal、varchar
2.整型类型
MySQL中定义数据字段的类型是非常重要的。MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符) 类型。

3.浮点型
float:单精度型,只保证6位有效数字的准确性
double:双精度型,只保证16位有效数字的准确性
decimal:定点数,其中decimal(5,2)代表共5位数字,其中2位是小数,比如:888.88
4.字符串
MySQL中提供了丰富的存储字符串数据的类型,如下:
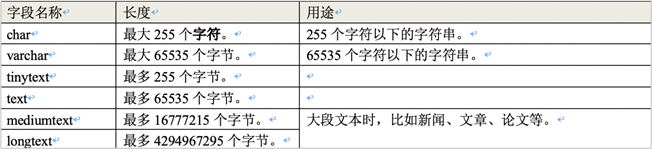
我们这里介绍char, varchar, text这三个比较常用的
5.char和varchar的区别

6.text
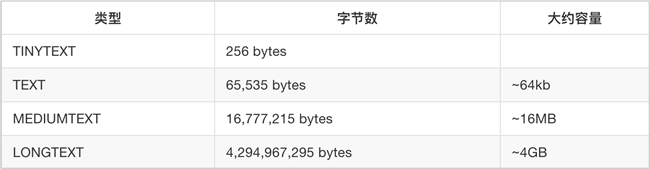
注意:text与char和varchar不同的是,text不可以有默认值,其最大长度是2的16次方-1
7.选择字符串类型的原则
varchar:适用于经常变化的字段用
char:适用于知道固定长度的字符串
尽量用varchar
超过255字节的只能用varchar或者text,能用varchar的地方不用text
8.枚举类型
枚举类型enum,在定义字段时就预告规定好固定的几个值,然后插入记录时值只能在这几个固定好的值中选择一个。
语法定义:==gender enum(‘男’,’女’,’妖’) ==
应用场景:当值是几个固定可选时,比如:性别、星期、月份、表示状态时(比如:是、否)
9.时间类型
MySQL提供了几个专门用来保存日期、时间的类型。
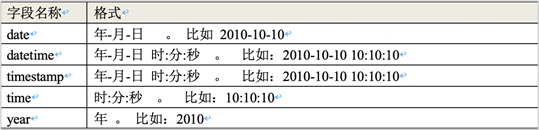
- datetime保存时间的范围: ‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’
- timestamp保存时间的范围: ‘1970-01-01 00:00:01’ 到 ‘2038-01-19 03:14:07’
七、数据完整性和约束
1.数据完整性
数据完整性用于保证数据的正确性。系统在更新、插入或删除等操作时都要检查数据的完整性,核实其约束条件。
参照完整性属于表间规则。在更新、插入或者删除记录时,如果只改其一,就会影响数据的完整性。如删除表2的某记录后,表1的相应记录未删除,致使这些记录成为孤立记录。
如下图:删除了老李的101车,表2的id101就没有了意义

2.约束

3.总结
- 数据完整性用于保证数据的正确性,如:年龄使用tinyint 数值最大为 127
- 约束作用是保证数据的完整性和一致性,如:把性别字段设置为default “保密”, 当不输入张三性别信息时,依然用”保密”保证张三信息的完整
八、登陆和退出数据库命令
1.数据库操作基本步骤
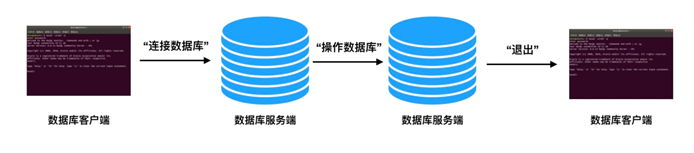
- 连接数据库
- 输入用户名和密码
- 完成对数据库的操作(SQL语句完成)
- 完成对表结构和表数据的操作(SQL语句完成)
- 退出数据库
2.连接数据库命令
打开终端,运行命令:mysql –uroot –p
回车后输入密码,当前设置的密码为mysql
注:mysql -uroot –pmysql也可以登录
3.退出数据库命令
在终端中,运行命令:
quit 和 exit
或 ctrl+d
注:SQL语句不区分大小写
4.显示版本和时间命令
| 命令 | 作用 |
|---|---|
| select version(); | 显示版本 |
| select now(); | 显示时间 |
注:SQL语句以 “;” 为结束符
九、数据库基本操作命令
| 命令 | 作用 | 示例 |
|---|---|---|
| show databases; | 查看所有数据库 | show databases; |
| select database(); | 查看当前使用的数据库 | select database(); |
| create database 数据库名 charset=utf8; | 创建数据库 | create database python charset=utf8; |
| use 数据库名 | 使用数据库 | use python; |
| drop database 数据库名; | 删除数据库(慎重) | drop database python; |
十、数据表基本操作命令
1.创建数据表命令

2.创建数据表示例
例:创建学生表

注:auto_increment表示自动增长
3.查看表结构命令
| 命令 | 作用 |
|---|---|
| show tables; | 查看当前数据库中所有表 |
| desc 表名; | 查看表结构 |
| show create table 表名; | 查看表结构 |
| show create table 表名; | 查看表的创建语句-详细过程 |
在开发过程中,不需要高频度的操作表结构,所以该章节的目的就是让我们能够在需要的时候根据这些语法写出符合要求的SQL语句即可。
十一、数据表结构修改命令
1.表结构修改命令
| 命令 | 作用 |
|---|---|
| alter table 表名 add 列名 类型; | 添加字段 |
| alter table 表名 change 原名 新名 类型及约束; | 重命名字段 |
| alter table 表名 modify 列名 类型及约束; | 修改字段类型 |
| alter table 表名 drop 列名; | 删除字段 |
| drop table 表名; | 删除表 |
十二、表结构操作命令
1.添加数据
| 命令 | 作用 |
|---|---|
| insert into 表名 values(…); | 全列插入:值的顺序与表结构字段的顺序完全一一对应 |
| insert into 表名(列1,…) values(值1,…); | 部分列插入:值的顺序与给出的顺序对应 |
| insert into 表名 values(…),(…)…; | 一次性插入多行数据 |
| insert into 表名(列1,…) values(值1,…),(值1,…)…; | 部分列多行插入 |
主键字段可以用0 / null / default 来占位,因为有自增
2.修改查询数据
| 命令 | 作用 |
|---|---|
| select * from 表名; | 查询所有列数据 |
| select 列1,列2,… from 表名; | 查询指定列数据 |
| update 表名 set 列1=值1,列2=值2… where 条件; | 修改数据 |
3.删除数据
物理删除:
| 命令 | 作用 |
|---|---|
| delete from 表名 where 条件; | 删除数据 |
逻辑删除:
alter table students add is_delete bit default 0;
update xxxxx set is_delete=1 where id=1;
- 1
- 2
十三、where语句
1.where语句的作用
使用where子句对表中的数据筛选,结果为true的记录会出现在结果集中。
条件查询语法:

where后面支持多种运算符,进行条件的处理:
- 比较运算符
- 逻辑运算符
- 模糊查询
- 范围查询
- 空判断
2.where之比较运算查询
常见的比较运算符:
- 等于:=
- 大于:>
- 大于等于:>=
- 小于:<
- 小于等于:<=
- 不等于:!= 或 <>
3.where之逻辑运算查询
and 表示有多个条件时, 多个条件必须同时成立(值为True)
or 表示有多个条件时,满足任意一个条件时成立
not 表示取反操作
例子:
- select * from students where id=1;
- select * from students where age >18 and not gender=“女”;
4.where之模糊查询
模糊查询关键字:like
like后跟:
- % 表示任意多个任意字符
- _ 表示一个任意字符
例如:查询students表中姓为黄的人

5.where之范围查询
范围查询分为连续范围查询和非连续范围查询:
- in 表示在一个非连续的范围内
- between … and … 表示在一个连续的范围内
查询编号为3和8的学生:select name from students where age in (3,8);
查询编号为3至8的学生:select name,age from students where id between 3 and 8
注意:between A and B 在匹配数据的时候匹配的范围空间是 [A,B]
6.where之空值判断
判断为空:is null

注意: null 与 ‘ ’ 是不同的
判断为非空:is not null

注意: is not null 顺序不要错误
十八、order排序查询
1.排序查询
程序中的排序: 以百度搜索为例。用户在百度上搜索 , 作为一个网站往往 需要把和用户最为需要的网页和数据发送给客户, 那么如何才能 认定这个数据是用户最需要的呢? 百度就会把用户搜索的关键字和数据库中已经存在的网页进行关联性的分析,将关联度高的 网页准备发送给用户浏览,但是问题来了 有很多关联性几乎一致 的网页到底应该给用户优先推送哪个网页呢, 谁在前面谁在后面呢?
答案就是排序: 先将所有的数据的关联程度进行排序,然后将关联程度一样的数据 根据比如用户的点击量等属性进行排序。

2.排序查询语法
select * from 表名 order by 列1 asc|desc [,列2asc|desc,…]
语法说明:
- 将’行数据按照列1进行排序,如果某些行 列1 的值相同时,则按照 列2 排序,以此类推
- asc从小到大排列,即升序
- desc从大到小排序,即降序
- 4默认按照列值从小到大排列(即asc关键字)
上一篇:Python数据结构和算法
下一篇:MySQL数据库高级使用

