
- 1AI发电厂——数据标注公司(国内数据标注公司服务调研)_数据标注外包公司
- 2yolov8 pycharm运行(predict,不用command line)_self.run_callbacks
- 3如何应对spring框架的HTTP ERROR 400 Bad Request错误返回_org.springframework.web.client.httpclienterrorexce
- 4在conda 虚拟环境中快速卸载安装包(操作详解)_conda删除当前环境中的包
- 5Redis Desktop Manager可视化工具
- 62023全国大学生数据统计与分析竞赛选题建议及思路_2023统计建模大赛论文选题
- 7NLP深入学习:《A Survey of Large Language Models》详细学习(三)
- 8AI嵌入式K210项目(4)-FPIOA_k210 fpioa文档
- 9大语言模型LLM《提示词工程指南》学习笔记01
- 10GPT系列初探_gpt 自回归
【深度学习基础】深度学习符号定义(符号表示,符号惯例,符号约定)_深度学习不同符号含义
赞
踩
实现神经网络的时候,一个好的符号约定能够对繁多的样本数据和网络参数,神经网络的复杂计算等进行有条理地 组织 和 表示。
数据标记与上下标
- x x x:表示输入数据,维度为 n x n_x nx;
- y y y:表示输出结果,维度(或者说类别数)为 n y n_y ny;
- 上标 ( i ) ^{(i)} (i)(小括号):代表第 i i i 个训练样本, x ( i ) x^{(i)} x(i) 和 x i x_i xi 存在混用的情况,注意识别;
- ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i)):表示第 i i i 组数据,可能是训练数据,也可能是测试数据;
- m m m:数据集的样本数。有时候为了强调,会使用 M t r a i n M_{train} Mtrain 表示训练集的样本数,用 M t e s t M_{test} Mtest 表示测试集的样本数;
- 上标 [ l ] ^{[l]} [l](方括号):代表第 l l l 层
-
n
h
[
l
]
n^{[l]}_h
nh[l]:代表第
l
l
l 层的隐藏单元数
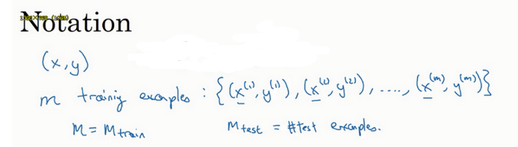
模型参数
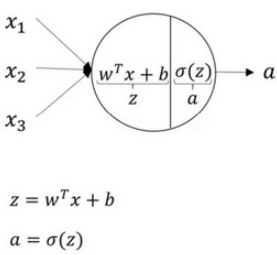
对神经网络进行编程时经常会让参数 w w w 和参数 b b b 分开,这里 w w w 表示 特征权重, b b b 对应 偏置。在其它的符号惯例中,有用 θ \theta θ 来统一表示模型参数的。
神经网络模型
为了能把训练集表示得更紧凑一点,我们会定义一个矩阵用大写
X
X
X 的表示,它由输入向量
x
(
1
)
x^{(1)}
x(1)、
x
(
2
)
x^{(2)}
x(2)等 按列堆叠 而成叠。所以这个矩阵有
m
m
m 列,是训练集的样本数量,然后这个矩阵的高度记为
n
x
n_x
nx,即 X.shape 为
(
n
x
,
m
)
(n_x,m)
(nx,m)。在实现神经网络的时候,使用按列堆叠的这种形式,会让整个实现的过程变得更加简单。
对于输出标签
y
y
y,我们同样按列堆叠,即
Y
Y
Y 等于
{
y
(
1
)
,
y
(
2
)
,
.
.
.
,
y
(
m
)
}
\{ y^{(1)},y^{(2)},...,y^{(m)}\}
{y(1),y(2),...,y(m)},以便后续计算。Y.shape等于
(
1
,
m
)
(1,m)
(1,m)。
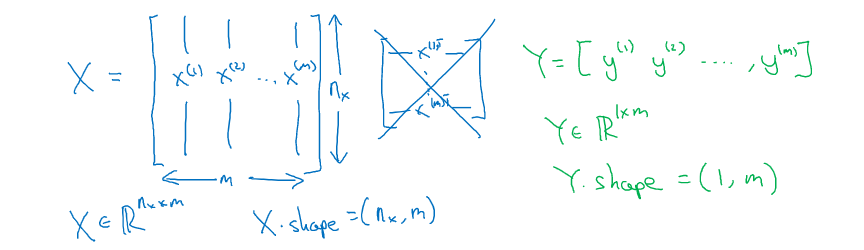
- X ∈ R n x × m X\in\mathbb{R}^{n_x×m} X∈Rnx×m:代表输入矩阵
- x ( I ) ∈ R n x x^{(I)}\in\mathbb{R}^{n_x} x(I)∈Rnx:代表第 i i i 个样本的列向量
- Y ∈ R n y × m Y\in\mathbb{R}^{n_y×m} Y∈Rny×m:代表标注矩阵
- y ( i ) ∈ R n y y^{(i)}\in\mathbb{R}^{n_y} y(i)∈Rny:代表第 i i i 个样本的标签
- W [ l ] ∈ R n h [ l ] × n h [ l − 1 ] W^{[l]}\in\mathbb{R}^{n^{[l]}_h×n^{[l-1]}_h} W[l]∈Rnh[l]×nh[l−1]:代表第 l l l 层的权重矩阵
- b [ l ] ∈ R n h [ l ] b^{[l]}\in\mathbb{R}^{n^{[l]}_h} b[l]∈Rnh[l]:代表第 l l l 层的权重矩阵
- y ^ \hat {y} y^:表示模型预测输出向量
正向传播公式
损失函数
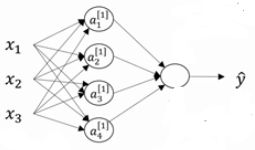
神经网络示意图
- 节点:代表输入、激活或者输出
- 边:代表权重或者误差
简单前馈网络
单个神经元
卷积神经网络
吴恩达 deeplearning.ai

