
- 1常见银行英语词汇_银行常用英语单词
- 22021-06-17_autogluon-multimodal 0.8.2 requires torch<1.14,>=1
- 3AI 绘画 | Stable Diffusion 提示词扩展插件_stable diffusion 提示词 插件
- 4Linux shell编程学习笔记42:hdparm命令_hdparm help
- 5优雅草AI直播换脸deepfacelive-优化版实战-如何使用AI换脸进行直播换脸-高大上名字“数字克隆人”
- 6遥感影像时空融合数据获取_lgc cia数据集下载和处理
- 7图像超分辨率重建算法,让模糊图像变清晰(附数据和代码)_提高分辨率的算法
- 8好东西来了!2017云栖大会300+份重磅资料下载_云栖大会 胶片
- 9【Kubernetes】在 CentOS 7 上搭建 Kubernetes
- 10YOLOV8 环境部署(WIN+CUDA)_yolo v8 cuda安装
计算机视觉(秋招面试准备资料)_计算机视觉算法秋招学习指南
赞
踩
目录
最近准备面试,所以记录一下自己学习的进程。因为本人做分割相关(语义分割,显著性检测、视频目标检测、视频语义分割),所以在学习的过程中在基础知识以外主要侧重分割任务。
1. 基础知识
包括经典分类模型、卷积、正则化、激活函数、优化器、损失等
1.1 经典分类网络
ALexNet
- Group Convolution : 在AlexNet中首次被提出的GC,最初被用来解决单GPU显存不足的问题。在如今成为轻量级网络的主要解决方案,用以减少参数量。对于输入输出特征通道均为256的3 * 3 卷积层,其参数量为 256 ∗ 3 ∗ 3 ∗ 256 256*3*3*256 256∗3∗3∗256;如果使用n=8的GC,则参数量为 8 ∗ 32 ∗ 3 ∗ 3 ∗ 32 8*32*3*3*32 8∗32∗3∗3∗32。同样的思路被用在Group Normalization中,对 N ∗ G ∗ C / G ∗ H ∗ W N*G*C/G*H*W N∗G∗C/G∗H∗W中按Group计算统计量,避免了对mini-batch的依赖。
- Dropout:在训练的过程中随机关闭一些神经元,以避免因为适应样本分布带来的性能提升,避免过拟合。
- Relu优点:相比于Sigmoid的指数操作,在计算和反向传播计算梯度式,减少了计算量;由于Sigmoid在饱和区的梯度趋于0,会出现梯度消失的现象,ReLU在大于0的区域梯度为1,避免了梯度的衰减,一定程度上避免了梯度消失;ReLU在小于0的区域为硬饱和区,为网络提供了特征的稀疏表达能力,防止网络过拟合。
- ReLU缺点:偏移现象和神经单元死亡带来的网络收敛困难。
GoogleNet
GoogleNet致力于增加网络深度/宽度、减少参数量/计算量:
Inception V1:
- Inception模块:通过多个不同尺度的卷积核、池化层对图像进行多尺度特征融合。
- 1 ∗ 1 1*1 1∗1卷积:使用了 1 ∗ 1 1*1 1∗1卷积对特征进行降维度,减少了参数量和计算成本。
- 取消全连接:全连接层具有大量的参数,并且会引起过拟合,通过全局平均池化代替全连接层,减少了参数、训练更快并且抑制了过拟合。
Inception V2:
- Batch Normalization:
- 小卷积代替大卷积:使用两个连续的
3
∗
3
3*3
3∗3卷积来代替
5
∗
5
5*5
5∗5卷积,在维持感受野范围的同时减少了参数量。

VGG
- 更小的卷积核:持续性地使用 3 ∗ 3 3*3 3∗3卷积来代替更大的卷积,维持感受野的同时,降低参数量、增加深度。
- 卷积核和池化核的选择:卷积: 3 ∗ 3 3*3 3∗3 stride=1 padding=1; 池化 : 2 ∗ 2 2*2 2∗2 stride=2
ResNet
- 跨层连接:拟合残差项(Residual Representations)来解决深层网络难以训练的问题
- ResNet中使用了反弧形结构,其中包括了1x1、3x3、1x1卷积,通过1*1卷积依次实现了通道降维度、升维度的过程;同时在MobileNet的反弧形结构中使用了1x1卷积首先来提升卷积通道维度(expand size),再使用1x1卷积来降低通道维度。为什么在MoblieNet中提升通道维度?在ResNet中通过简单地减少卷积层维度从而减少操作空间维度来捕捉和利用信息。当考虑到非线性激活转换时,对于1 D空间时,得到一条射线,对于n维空间,可以能得到具有n个结点的分段曲线。当ReLU折叠通道时,不可避免的带来信息损失,当拥有足够多的通道时,信息仍可能保存在通道中。如果输入特征可以嵌入到激活空间的一个显着较低维的子空间中,那么 ReLU 变换会保留信息,同时将所需的复杂性引入到可表达的函数集中,所以在v2中由pointwise(更名了映射层)实现了由高维空间向低维空间的映射。低维张量是计算量减少的关键、但是在低维空间内的卷积会损失性能。
有效信息应该位于高维激活空间的低维子空间中。在低维空间中使用非线性激活会造成性能损失,通过线性层将特征迁移到高维特征中,再通过非线性卷积模块实现高维空间特征的捕捉,再映射回低维子空间中。

因为MobileNet中使用了深度可分离卷积,首先执行Group为out_channels的深度卷积,使用更高维度的特征图可以捕获更有效的特征,但是依旧可以维持着较少的参数量。在深度可分离卷积的第二层pointwise convolution中,使用1x1卷积来线性聚合输入通道的特征,使用更大的通道数可以捕获更有效的特征。在MobileNet v2中提出逆向的残差结构(Inverted residuals),使用残差链接输入,以提升梯度的传播能力。
Xception
- Depthwise Separable Convolution
DenseNet
DetNet
ShuffleNet
HRNet
1.2 卷积和池化
池化层主要用于采样,对特征进行降维压缩,加快运算速度:
- 保留主要特征的同时减少参数和计算量,防止过拟合
- 引入不变性,包括平移不变性、旋转不变性和尺度不变性。
卷积: - 卷积运算公式,o为输出尺寸,i为输入尺寸,p为padding,k为kernel size,s为stride:
o = ( i + 2 p − k ) / s + 1 o = (i +2p-k)/s +1 o=(i+2p−k)/s+1 - 参数量的计算:in_channels * kernel_size * kernel_size * out_channels
- 手写卷积代码及原理:
卷积的weight: out_channels * in_channels * kernel_size * kernel_size
卷积的bias: out_channels * 1
import numpy as np ''' np.pad函数的使用?np.pad(x, pad_width=((0, 0), (0, 0), (pad, pad), (pad, pad)), mode='constant', constant_values=0.0) img2col的实现? .flatten() batch样本可否并行? 可以,利用 feat_matrix 和 weight_matrix 做dot时broadcast的机制 ''' # 只有batchsize需要循环 class Conv2D(object): def __init__(self, in_channels, out_channels, kernel_size, stride, padding, bias=False): # settings self.in_channels = in_channels self.out_channels = out_channels self.kernel_size = kernel_size self.stride = stride self.padding = padding self.use_bias = bias # 卷积的权重 self.weights = np.random.rand(out_channels, in_channels, kernel_size, kernel_size).astype(np.float) # self.weights = np.ones((out_channels, in_channels, kernel_size, kernel_size)).astype(np.float) if self.use_bias: self.bias = np.random.rand(out_channels).astype(np.float) # self.bias = np.ones(out_channels).astype(np.float) else: self.bias = None def __call__(self, input_feat): b, c, h, w = input_feat.shape # kernel展开 weight_matrix = self._kernel2col() # padding # print(input_feat.shape) padded_input_feat = np.pad(input_feat, pad_width=((0,0), (0,0), (self.padding, self.padding), (self.padding, self.padding)), mode='constant', constant_values=0.0) # # padded_input_feat = input_feat.astype(np.float) # print(padded_input_feat.shape) self.out_h = (h + 2*self.padding - self.kernel_size) // self.stride + 1 self.out_w = (w + 2*self.padding - self.kernel_size) // self.stride + 1 # print(self.out_h, self.out_w) # ''' 对样本进行循环 ''' # out_lis = [] # for batch_no in range(b): # # print(padded_input_feat[batch_no, :, :, :]) # feat_matrix = self._img2col(padded_input_feat[batch_no, :, :, :]) # output_for_one_sample = np.dot(feat_matrix, weight_matrix) # out_h*out_w行, out_channel列 # output_for_one_sample = output_for_one_sample.transpose((1, 0)) # out_channel行, out_h*out_w列 # output_for_one_sample = output_for_one_sample.reshape((self.out_channels, self.out_h, self.out_w)) # output_for_one_sample = np.expand_dims(output_for_one_sample, axis=0) # out_lis.append(output_for_one_sample) # output = np.concatenate(out_lis, axis=0) ''' 不对样本进行循环 ''' feat_matrix_lis = [] for batch_no in range(b): # print(padded_input_feat[batch_no, :, :, :]) feat_matrix_for_one_sample = self._img2col(padded_input_feat[batch_no, :, :, :]) feat_matrix_for_one_sample = np.expand_dims(feat_matrix_for_one_sample, axis=0) feat_matrix_lis.append(feat_matrix_for_one_sample) feat_matrix = np.concatenate(feat_matrix_lis, axis=0) output = np.dot(feat_matrix, weight_matrix) # batchsize, out_h*out_w行, out_channel列 output = output.transpose((0, 2, 1)).reshape((b, self.out_channels, self.out_h, self.out_w)) # output_for_one_sample = np.dot(feat_matrix, weight_matrix) # out_h*out_w行, out_channel列 # output_for_one_sample = output_for_one_sample.transpose((1, 0)) # out_channel行, out_h*out_w列 # output_for_one_sample = output_for_one_sample.reshape((self.out_channels, self.out_h, self.out_w)) # output_for_one_sample = np.expand_dims(output_for_one_sample, axis=0) # out_lis.append(output_for_one_sample) if self.use_bias: temp_bias = np.expand_dims(self.bias, axis=0) temp_bias = np.expand_dims(temp_bias, axis=-1) temp_bias = np.expand_dims(temp_bias, axis=-1) # print(temp_bias.shape, '00000') output += temp_bias # b, out_channels, out_h, out_w 和 out_channels return output def _img2col(self, input_x): c, h, w = input_x.shape # print(c, h, w) feat_mat_height = self.out_h * self.out_w feat_mat_width = self.kernel_size * self.kernel_size * c # print(feat_mat_height) # print(feat_mat_width) feat_matrix = np.empty(shape=(feat_mat_height, feat_mat_width), dtype=np.float) for m in range(self.out_h): for n in range(self.out_w): temp = input_x[:, m*self.stride:m*self.stride+self.kernel_size, n*self.stride:n*self.stride+self.kernel_size].flatten() # channel height width # print(m, n, temp) feat_matrix[m * self.out_w + n, :] = temp return feat_matrix def _kernel2col(self): out_channel, in_channel, kernel_size, kernel_size = self.weights.shape # out_channel, in_channel, kernel_size, kernel_size weight_matrix = np.empty((in_channel*kernel_size*kernel_size, out_channel)).astype(np.float) for m in range(out_channel): for n in range(in_channel): temp = self.weights[m, n, :, :].flatten() weight_matrix[n*self.kernel_size*self.kernel_size:(n+1)*self.kernel_size*self.kernel_size, m] = temp return weight_matrix if __name__=='__main__': b, c, h, w = 2, 1, 4, 4 inputa_ = np.array(range(b*c*h*w)).reshape((b, c, h, w)).astype(np.float) + 1 print(inputa_) print(inputa_.shape) # in_channels, out_channels, kernel_size, stride, padding conv_layer = Conv2D(c, 2, kernel_size=3, stride=1, padding=1, bias=True) out_ = conv_layer(inputa_) print(out_) print(out_.shape)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
1.2.1 反卷积/转置卷积
- 上采样的常用方法有三种,包括双线性插值、反卷积、反池化。在FCN使用反卷积作为上采样来提升图像分辨率。
- 反卷积是一种特殊的卷积过程,当卷积核步长0<s<1时,按照一定比例为图像的每个像素点间padding空白像素,接着以stride=1对图像进行卷积操作。
- 当(o+2p-k)%s = 0时,反卷积的输入输出尺寸关系:
o = s ( i − 1 ) − 2 p + k o = s(i-1)-2p+k o=s(i−1)−2p+k
1.2.2 扩张卷积 语义分割/目标检测
- 诞生背景:在图像分割领域中FCN,通常使用pooling操作降低图像尺寸以提高感受野,对于pooling之后的低分辨率图像执行上采样,以达到原始图像尺寸,在这个过程中信息出现损失。
- 对标准卷积核添加‘空洞’,以达到更大的采样范围,在不使用pooling损失信息的同时,有效地提升了感受野。正常卷积核的dilation rate=1;当扩张率=Padding,维持输出特征图尺寸不变
- 在分割任务中,通过设置不同的dilation rate,获取不同尺度的感受野,以获取多尺度信息。在目标检测任务中,SSD和RFBNet也使用了空洞卷积。
- 空洞卷积存在gridding问题,即网格效应/棋盘问题。空洞卷积计算的相邻像素结果是从互相独立的子集中卷积得到的,相互间缺少依赖,存在局部信息丢失、远距离卷积信息缺乏相关性的问题。
1.2.3 可变形卷积 语义分割/目标检测
- 诞生背景:同样的物体在图像中可能呈现不同的大小、姿态、视角变化等,网络对物体几何形变的适应能力来自于数据多样性,单一的矩形卷积核,影响了对几何形变的建模。在同一层Conv中,所有的激活单元对应的感受野大小是一致的,但是不同位置可能对应着不同尺度或者形变的对象。
- 通过增加额外可学习的偏移量(对特征图的每个位置学习偏执),使得卷积核在特征图上的采样点发生偏移,集中在感兴趣的区域/目标。
1.2.4 可分离卷积 DepthWise convolution
- 在标准的卷积过程中,对于2*2的卷积核,其考虑了对应图像通道的所有通道。
- 主要用在轻量级网络,极大地减小了参数。
1.2.5 问题
- 卷积只能在一组进行吗?Group Convolution
最早在AlexNet中解决硬件资源有限的问题,后来被广泛应用在轻量级网络上。如果输入通道为256,输出通道为256,通过单一卷积的参数为25633256;当使用Group Convolution分为8 groups,则通过卷积的参数变为83233*32. - 33卷积核的使用
大的卷积核可以捕捉更大的感受野,但会导致计算量增加,影响计算效率;在VGG、Inception等网络中,使用2个33卷积代替代替1个5*5卷积,在减少参数的同时获得了相同的感受野。 - 11卷积核的作用
在模型中使用33、55卷积核时,如果channel极大,会带来大量的计算参数。使用11卷积降维度,使用33卷积,在通过11卷积调整维度,相比于直接使用33卷积,极大地降低了参数量。在全卷积网络中,使用11卷积来代替FC。 - 如何训练更深的模型?
当卷积层叠加增加深度时,容易发生的梯度爆炸或者梯度消散,导致反向传播很难训练浅层网络。自然地考虑,当网络深度增加时,即使网络没有作用,也不应该带来性能的衰减,所以设计了skip connection作为残差连接,使梯度能够更好的反传到浅层特征。 - 普通卷积和扩张卷积的区别?
当stride>1时,普通卷积可以实现扩大感受野,但是同时降低了图片分辨率。扩张卷积在维持分辨率的同时,提高了感受野。 - 普通卷积和反卷积的区别?
反卷积就是特殊的卷积过程,先为图片填充空白像素点,再执行卷积过程。 - 双线性插值中align_corners为True或者False有什么影响?
1.3 正则化
1.3.1 Normalization
对于机器学习模型需要的数据,通常需要数据满足独立同分布,可以简化常规机器学习模型的训练、提升机器学习模型的预测能力。所以白化 (whitening) 是一个重要的数据预处理过程;
- 去除特征之间的相关性。—独立
- 使得所有特征具有相同的均值和方差。 —同分布
在深度学习模型中由于层数较多,每一层的的参数更新,都影响了传递到下一层的输入数据分布变化。当浅层的输出数据发生变化时,在深层的输入特征分布会发生显著变化,所以导致高层网络需要不断重新适应新的输入数据分布,即Internal Covariate Shift。Covariate Shift指的是源空间和目标空间的条件概率是一致的,但是其边缘概率不同。对于网络每层的输入与输出的分布不同,并且差异随着网络深度增大而增大,因为是对层间信号分析,成为internal。
- 上层参数需要不断适应新的输入数据分布,降低学习速度。
- 每层的更新都会影响其他层,训练困难
在模型训练的过程中,使用可微(可以通过反向传播更新参数)的Normalization,对输入x进行平移和伸缩变换。同时添加再平移参数和再缩放参数,以保证模型的表达能力不因为规范化而下降。
好处:
- 输入通过Normalization,允许使用饱和性激活函数(tanh,sigmoid)等,输出结果会落在激活函数更敏感的位置,偏导稳定,能控制梯度爆炸和消失
- 对模型中的参数不那么敏感,简化调参过程,使得网络学习更加稳定
- 防止过拟合/延后过拟合发生的时间
- 保证输入数据近似同分布,加速收敛,加速网络训练
1.3.1.1 Batch Normalization
BN针对单个神经元进行规范化,即针对单个维度定义的纵向规范化,利用网络训练时一个mini-batch的数据来计算该神经元输入的均值和方差。规范化的参数是一个mini-batch的一阶统计量和二阶统计量,要求每一个mini-batch的统计量是整体统计量的近似估计,满足近似同分布。适用于mini-batch比较大、数据分布比较接近的情况。
1.3.1.2 Layer Normalization
LN考虑一层所有维度的输入,计算该层的输入平均值和输入方差。LN针对单个训练样本进行归一化,不依赖于其他数据,所以不受mini-batch中数据分布的影响,适用于小mini-batch、动态网络场景和RNN。此外,LN不需要保存mini-batch的均值和方差,节省了额外的空间。
1.3.1.3 Group Normalization
优化了BN在小mini-batch下的劣势,将Channels划分为多个Group,计算每个group内的均值和方差,以进行归一化。GN相当于BN和LN的折中,与Batch-Size无关,且同时处理多维度。
1.3.2 Dropout
dropout是指在训练过程中随机丢弃部分神经元,以降低模型对数据分布的依赖性,用于解决过拟合。经过交叉验证,dropout率等于0.5时效果最好,当其为0.5时dropout随机生成的网络结构最多。增加了网络表达的稀疏性。
1.3.3 L1/L2
L1/L2可以看作是损失函数的惩罚项,对损失函数中的某些参数进行限制。通过最小化损失函数和正则项,使模型拟合训练数据,并且同时防止模型过分拟合训练数据。
1.3.3.1 L1
L1正则化是指权值向量w中各个元素的绝对值之和,可以产生稀疏权值矩阵,即产生一个稀疏模型,用于特征选择。一定程度上,也可以防止过拟合。
1.3.3.2 L2
L2范数,又被称为“岭回归”或者“权值衰减 weight decay”,计算权值向量w中各元素的平方和再开平方根,以解决过拟合问题,提升模型的泛化能力。
CSDN
1.4 激活函数
激活函数的作用主要有:
- 添加了非线性激励函数,为模型添加非线性,理论上可以逼近复杂函数
- 输出有界,易于做下层的输入
为什么引入了Relu激活函数:
- 采用Sigmoid等激活函数时(指数运算),在计算和反向传播求导时计算量大
- 对于深层网络,Sigmoid会出现梯度消失/弥散的情况(当sigmoid接近饱和区时,导数趋于0) ,无法完成对深层网络的训练。(使用BN能够改善输入分布,就可以使用Sigmoid等激活函数)
- Relu会将部分神经元置为0,增加了网络的稀疏性,缓解了过拟合问题。
1.4.1 Sigmoid
Sigmoid具有指数函数形状,常被用在二分类任务中约束输出在(0-1)范围内。

1.4.2 tanh
t
a
n
h
(
x
)
=
2
∗
s
i
g
m
o
i
d
(
2
x
)
−
1
tanh(x) = 2*sigmoid(2x)-1
tanh(x)=2∗sigmoid(2x)−1
tanh的收敛速度快于sigmoid,输出均值接近于0

1.4.3 Relu
ReLU能够解决Sigmoid带来的梯度消失,解决了深层网络训练困难的问题。Relu在大于0的区域里维持梯度为1,不会造成梯度的衰减,从而缓解梯度消失问题。Relu将小于0的区域置为0,通过硬饱和区提供了网络的稀疏表达能力,但是在PReLU论文中指明了稀疏性并非性能提升的必要条件。
ReLU同样存在着问题,偏移现象(输出均值恒大于0)、神经元死亡(硬饱和区权重无法更新)影响了网络的收敛性。

1.4.4 PReLU
PReLU继承自ReLU和LReLU,为负半区提供可学习的斜率。PReLU的收敛速度更快,因为其输出均值接近于0,使得SGD更接近natural gradient。

1.4.5 Softmax (非激活函数
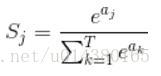
给出向量,计算每个向量位置的概率,每个向量位置的概率为(0-1),向量位置概率和为1,常用于多分类任务。
1.5 损失
1.5.1 均方差损失 Mean Squared Error Loss(MSE Loss/L2 Loss)
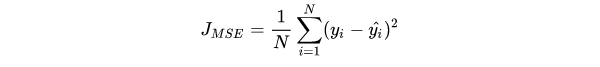
在模型输出与真实值的误差服从高斯分布的假设下,最小化均方差损失函数与极大似然估计本质上是一致的,所以适用于解决回归问题。
1.5.2 平均绝对误差损失 Mean Absolute Error Loss (MAE Loss/L1 Loss)
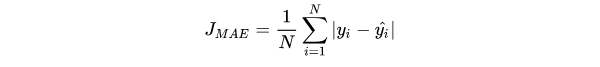
MSE通常比MAE更快地收敛,MAE对于outlier更加鲁棒。
1.5.3 Smooth L1 Loss 目标检测 (Faster RCNN/SSD)
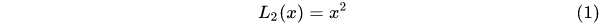
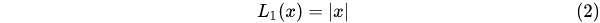
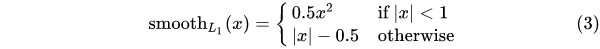
调整了损失梯度:
- 相比于L2 Loss,解决了在预测与真值差值较大时可能出现的梯度爆炸问题
- 相比于L1 Loss,解决了在预测与真值差值较小时依旧使用较大的梯度(1)进行训练。
1.5.4 交叉熵损失
在KL( Kullback–Leibler Divergence)散度来衡量两个分布的相似性,给定分布p和分布q,两者散度公式,其中第一项为分布p的信息熵,第二项为分布p和分布q的交叉熵:
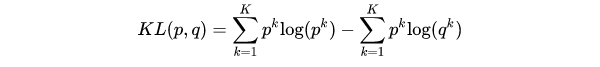
当希望分布尽可能的接近时,就要最小化KL散度,分布p的信息熵仅有p自身有关,所以可以通过实现最小化p、q的交叉熵来实现最小化KL散度。
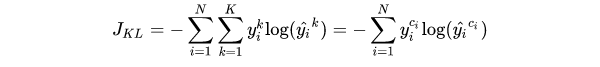
在二分类任务中,使用Sigmoid函数将输出压缩到(0,1),使用BCE Loss。
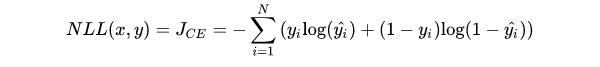
在多分类任务中,使用Softmax将每个维度的输出范围限定在(0,1)之间,所有维度的输出和为1,又称softmax loss:
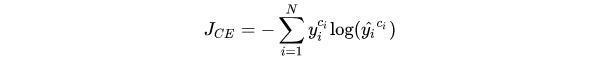
1.5.5 Focal Loss 目标检测 改自交叉熵
交叉熵对于所有样本‘一视同仁’,无法根据样本分布学习有效的特征。Focal Loss解决了分类问题中类别不平衡、分类难度差异的问题,其使用a作为类别权重,(1-p)^r作为难度权重。在解决二分类任务上,使用参数r来调整对该样本的重视程度,即对于标签为1的样本,预测得分越高,在训练的过程就降低其比重,从而学习到其他样本的信息,随着r的增大,对于样本的惩罚越大;当r为0时,Focal Loss退化为交叉熵损失。同时使用a来调整类别权重比例。
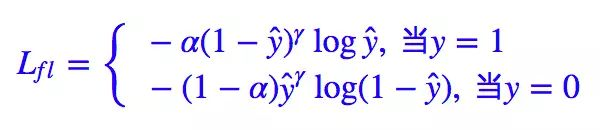
1.5.6 Dice Loss 语义分割
Dice Loss旨在应对语义分割中正负样本强烈不平衡的场景。相比于CE Loss、wCE Loss和Focal Loss的Pixel-level的损失,Dice Loss相当于Class-Level的Loss,把一个类别的所有像素作为一个整体去计算loss,当前像素的loss不仅和当前像素的预测值有关,与其他点的预测也相关,直接使用分割效果评估指标作为Loss去监督网络,并且忽略了大量的背景。
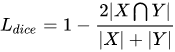
1.5.7 Iou Loss
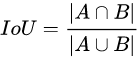
L
I
o
u
=
1
−
I
o
u
L_{Iou} = 1-Iou
LIou=1−Iou
1.6 优化器
资料

各种优化器的差异出现在第一步和第二步,设计出了不同的优化梯度、一阶动量和二阶动量的方法。
一阶动量: 指数平均梯度
二阶动量: 梯度和
1.6.1 梯度下降
梯度下降算法用来计算函数的最小值点/局部最小值点。对于凸函数,最小值点为梯度为0的位置。当前位置的函数梯度指向函数增长最快的方向,则当前梯度的反方向则指向函数减少最快的方向,朝着梯度下降的方向前进,当梯度趋向于0时,就会找到局部最优点/最优点。学习率Lr则为前进的步长。
问题:
- 对于初始点,可能收敛到局部极小值点,并且梯度下降机制无法从局部极小值点走出。
- 梯度为0的点无法逃离,比如鞍点在某个方向上可能达到了最小值点,但是在另一个方向上是局部最大值点。
梯度下降根据使用多少数据来计算目标函数的损失,被分为三类:
Batch gradient descent: 由于需要计算整个数据集的梯度以执行一次更新,因此批量梯度下降可能非常慢,并且难以处理对于内存敏感的数据集。 批量梯度下降也不允许在线更新模型,即即时更新新示例。Batch gradient descent保证能够收敛到凸平面的全局最优和非凸平面的局部最优。
Stochastic gradient descent:随机梯度下降对每个训练样本和真值执行一次参数更新。Batch梯度下降对大型数据集执行冗余计算,因为它在每次更新参数之前重新计算相似示例的梯度。 SGD 通过根据单样本依次执行更新来消除这种冗余,速度较快多,也可用于在线学习。SGD 以高方差执行频繁的更新,导致目标函数剧烈波动。
Mini-batch gradient descent
根据数据量,我们在参数更新的准确性和执行更新所需的时间之间进行权衡。
1.6.2 随机梯度下降(SGD)
如何在尝试收敛到全局最优值的同时摆脱局部极小值点和鞍点?使用随机梯度下降。
之前的方法对训练集上的所有可能样本的损失值求和得到的损失函数进行梯度下降,当进入局部极小值点或者鞍点时,无法继续优化。在随机梯度下降中,不是对所有损失函数求和来计算函数的梯度,而是通过计算一个随机抽样的样本的损失来执行梯度下降。
批梯度下降:我们使用固定数量的样本采样成一个mini-batch来构建损失函数。选择mini-batch的大小来保证我们有足够的随机性摆脱局部最小值,同时可以利用足够的并行计算力。
在SGD中没有动量的概念:
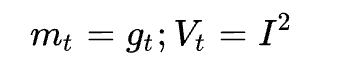
存在一些问题:
- 选择合适的学习率是非常困难的,学习率太小会导致收敛速度很慢,而学习率太大会阻碍收敛并导致损失函数在最小值附近波动甚至发散。
- 学习率计划(lr schedules)尝试通过在训练期间调整学习率例如退火,无法适应数据集的特征。
- 相同的学习率对所有的参数执行更新。如果数据表示稀疏或者特征频率不同,不希望以同等程度更新参数,而自适应调整学习,对于更新频繁的执行更小的更新,对更新次数较少对特征执行更大的更新。(引入二阶动量的AdaGrad)
- 最小化神经网络常见的高度非凸误差函数的关键挑战是避免陷入梯度为0的非全局最小值点,例如众多次优局部最小值和鞍点。SGD无法从这些陷阱中逃逸。
1.6.3 SGD with Momentum(SGDM)
为了抑制SGD的震荡,添加一阶动量(一阶动量是各个时刻梯度方向的指数移动平均值,约等于最近
1
/
(
1
−
β
1
)
1/(1-\beta_{1})
1/(1−β1)个时刻梯度向量和的平均值):
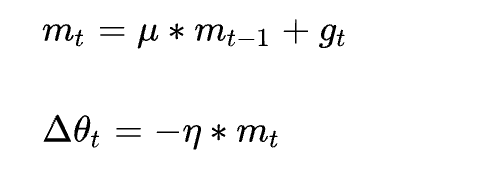
对于与动量方向相同的梯度更新,动量会增加;对于与动量方向相反,动量项会减少。即当下降方向相同时,加速下降;当下降方向不同时,抑制不同方向的下降;从而实现了快速的收敛并抑制震荡。
β
\beta
β通常被设置为0.9,表示在梯度下降的过程中依赖的方向主要来自于之前的累积方向,可以在相关方向加速SGD,抑制震荡,从而加速收敛。
1.6.4 SGD with Nesterov Acceleration(NAG)
NAG是基于SGD-M的改进,用于解决momentum梯度下降过猛的情况,即避免前进的太快,同时提升灵敏度。(即小球需要在上坡前减速)。SGDM没有直接改变计算梯度,而是使用先前的梯度动量影响当前的决策。在当前的位置的下降方向主要由累计动量决定,先按照该累阶动量前进一步,按照新位置的梯度方向与历史累计的动量结合,计算当前位置的累积动量。NAG的改变则是让之前的累积动量直接影响当前计算的梯度。

1.6.5 AdaGrad
- 引入了二阶动量,二阶动量的出现意味着“自适应学习率”,对学习率添加一个约束。SGD及其变种以相同的学习率更新每个参数。对于更新频繁的参数,我们累积了相关的知识,不希望被单个样本影响,希望能够使用较小的学习率;对于偶尔更新的参数,我们累积相关的知识较少,当有更新机会时,希望能够使用更大的学习率。
- 使用二阶动量(该维度上所有梯度值的平方和)来度量历史更新频率,这时的学习率,变为了学习率与二阶动量的比值。当更新频繁时,二阶动量较大,则对应的学习率较小;当更新频次较少,二阶动量较小,则对应的学习率稍大。
- 消除了手动调整学习率的必要,只需要选择一个合适的初始学习率。该方法在稀疏数据场景下表现的比较好。但是二阶动量单调递增,会使学习率单调递减至0,可能会导致训练提前结束,无法学习到一些知识。

1.6.6 Adadelta
在AdaGrad中累积全部历史梯度的平方和,对学习率进行了单调递减处理;而Adadelta累积固定窗口大小w的下降梯度的平方和,不是低效地存储 w 个先前的平方梯度,而是将梯度总和递归地定义为所有过去的平方梯度的衰减平均值,使用指数移动平均来计算二阶累积动量。

1.6.7 RMSprop
RMSprop是Adadelta的特例,

1.6.8 Adam
Adam利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
对于梯度使用一阶动量来约束,对于学习率使用二阶动量来约束:
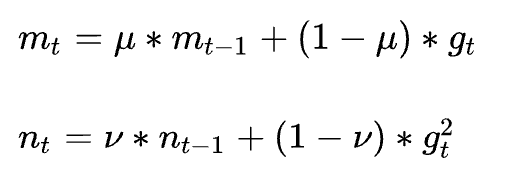
在Adam中引入了偏置较正:

在梯度更新的过程中引入一阶动量和二阶动量:
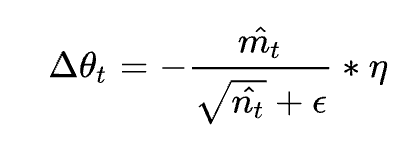
1.7 学习率策略
1.7.1 Warm-up
Warm-up指在早期epoch中使用较小的学习率,在之后增加到初始学习率,并执行正常的学习率衰减。
作用:
- 模型随机初始化,在训练开始时模型权重迅速改变,并且mini-batch样本方差较大,较大的学习率可能导致训练不稳定,使用小学习率维持训练的稳定
- 缓解在模型训练早期可能很轻易的造成对mini-batch过拟合现象
当模型训练时出现损失为NaN时或者过拟合时,可以尝试Warm-up。
1.7.2 Step衰减
每过固定的迭代次数,学习率乘以一个固定的衰减倍数,实现学习率的均匀降低。
l
r
=
l
r
∗
α
e
p
c
o
h
/
/
l
r
−
s
t
e
p
lr = lr * \alpha^{epcoh//lr-step}
lr=lr∗αepcoh//lr−step
lr-step为学习率衰减间隔,使用Step衰减在一定迭代次数内维持学习率的稳定。
1.7.3 Poly衰减
l
r
=
l
r
∗
(
1
−
i
t
e
r
/
t
o
t
a
l
−
i
t
e
r
)
p
o
w
e
r
lr = lr * (1-iter/total-iter)^{power}
lr=lr∗(1−iter/total−iter)power
power控制着学习率曲线的形状,当power<1,曲线为凸,学习率下降先慢再快;当power>1,曲线为凹,学习率下降先快再慢;当power=1时,为线性曲线。
poly学习率衰减被广泛地应用在分割任务中
1.8 梯度爆炸/消失
1.8.1 原因
梯度爆炸原因:
- 深层网络在梯度反向传播的过程中,对激活函数计算梯度,如果梯度大于1,当层数多时,最终的梯度更新以指数形式增加,即发生梯度爆炸。
- 权值初始化值太大或者初始化学习率太大
梯度消失原因:
- 深层网络在梯度反向传播的过程中,对激活函数计算梯度,如果梯度小于1,当层数多时,最终的梯度更新以指数形式衰减,即发生梯度消失。
- 采用了不合适的激活函数,如Sigmoid,tanh等。当使用Sigmoid作为激活函数时,其梯度不超过0.25,当层数多时,梯度以指数级衰减,出现梯度消失。
1.8.2 解决方案
- 梯度剪切,设置一个梯度剪切阈值,在更新梯度的过程中,如果梯度超过这个阈值,那么将梯度强行限制在阈值范围之内,可以防止梯度爆炸的发生。
- 权重正则化,比较常见的是L1正则和L2正则。正则项对模型参数进行限制,当发生梯度爆炸时,权重的范数会变的非常大,通过正则项可以部分限制梯度爆炸的发生。
- 使用更合适的激活函数如ReLU、LReLU等,在正数部分导数恒为1,避免了权重指数级衰减和增大,避免了梯度消失和梯度爆炸的问题。
- BatchNorm,对每层的输入样本分布进行规范化,保证了模型的输出落在非线性激活函数的敏感区域,从而得到合适的梯度,避免了梯度消失的问题。
- 残差结构,在反向传播时,可以沿shortcut反传参数,无损地传播梯度,可以有效地避免梯度消失。基于此,可以训练非常深的网络。
1.9 Python
-
python中的 ∗ * ∗ ∗ ∗ ** ∗∗都代表了什么意思?
∗ a r g s *args ∗args、 ∗ ∗ k w a r g s **kwargs ∗∗kwargs 都表示函数形参、表示未知数目的函数参数传递。 ∗ a r g s *args ∗args为位置参数,表示任意多个无名参数,以tuple的形式传递。 ∗ ∗ k w a r g s **kwargs ∗∗kwargs为关键词参数,表示一一对应的参数名,以dict的形式传递。在同时使用 ∗ * ∗、 ∗ ∗ ** ∗∗时, ∗ a r g s *args ∗args必须写在 ∗ ∗ k w a r g s **kwargs ∗∗kwargs 之前。 ∗ * ∗和 ∗ ∗ ** ∗∗还可以表示实参,为定长函数传入参数,对元组和字典进行解引用。(额外的, ∗ * ∗表示函数乘法, ∗ ∗ ** ∗∗表示乘方; ∗ * ∗还可以被用来解耦序列。) -
深拷贝、浅拷贝、赋值引用
赋值引用,默认浅拷贝传递对象的引用,相当于添加一个标签,并没有产生新对象;跟随原始对象的改变而改变;
浅拷贝,拷贝父对象(顶层引用),当顶层引用中的引用改变时,浅拷贝对象元素改变;为原始对象添加顶层时,元素不改变;
深拷贝,完全拷贝父对象及其子对象,直到所有的引用都是不可修改引用,原始对象的改变不会造成深拷贝里任何子元素的改变。 -
is和==的区别
is 比较的是两个实例对象是否完全相同,是否为同一个对象,占用的内存地址是否相同;== 比较的是两个对象的内容是否相等,即内存地址可以不一样,内容一样就可以了,其不严格限定对象的数据类型(1.0与1);IsEqual实现判断元素类型是否相同,再判断具体内容是否一致。 -
list和tuple的区别
list可变,tuple不可变,所以tuple没有insert、pop、append方法,不可变的tuple相对于代码来说更安全可靠;tuple可以转成列表,但是不可以转成字典;对于tuple中只有一个元素,必须要加‘,’,才会被识别为元组,否则为单元素。 -
python怎么使用c扩展
在python应用中,为了对性能进行优化(对于一些和系统相关的模块或者对性能要求很高的模块,通常会把这个模块C化),需要使用python的C扩展,将一些关键代码用C进行重写以提高性能,有两种常用方式:
可以直接使用Python C API,在C文件中加载Python.h头文件,使用PyObject作为C语言中返回的python对象;把写好的C语言代码编译成.so文件,就可以使用调包的方式在python中使用。
cython可以使用python的语法,来调用c程序的接口,并且可以同时方便的地用c函数和python函数。 -
utf-8、unicode的区别
-
生成器和迭代器
迭代器是一个可以遍历容器的对象,比如dataloader就是一个迭代器,其中封装了继承自DataSet的可迭代对象(定义了返回一个迭代器的__iter__或者支持下标索引的__getitem__)。
迭代器:实现了__iter__和__next__方法的对象都称为迭代器,其中__iter__()返回一个特殊的迭代器,next() 方法会返回下一个迭代对象。其并不将所有结果存入内存中,而是在调用时迭代产生。**优点:**节省内存,使用了一种不需要索引的检索方式。**缺点:**只能单向索引,不能回退。
生成器:本质上是一种迭代器,但是只能迭代一次;以函数的形式遍历,却不返回值,使用了yeild函数来处理值,类似于生成一个返回迭代器的函数,只能用于迭代操作。生成器最佳应用场景是:你不想同一时间将所有计算出来的大量结果集分配到内存当中,特别是结果集里还包含循环。 -
装饰器
修饰器修改其他函数的功能的函数。在MMLab系列的代码中被用来置换backbone、head等部分。使用@来封装函数,从而改变函数中功能。 -
匿名函数 lambda
1.10 Pytorch
1.10.1 上采样(反卷积、反池化、插值)
- 插值法的第一步是计算目标图的坐标点对应于原图的哪个坐标点来填充:

其中通过长宽缩放比,反求出原图的像素点坐标,但是通常该坐标点为小数。不同插值的方法的区别就在于如何利用策略将小数点坐标转换为整数点坐标。最近邻插值直接四舍五入寻找最接近的整数像素点,这样会导致像素变化不连续,在目标图像中产生锯齿边缘;双线性插值将小数点坐标转换为相邻的四个整数坐标点,权重与距离成反比,首先在x方向上进行两次插值,再在y方向上进行一次插值。双三次插值用了相邻的16个点,无法保证两个方向的坐标权重和为1,可能出现像素质越界的情况,需要截断。
def biliner(x, y): x_1 = int(x) x_2 = x_1 + 1 y_1 = int(y) y_2 = y_1 + 1 Q_11 = temp[x_1][y_1] Q_21 = temp[x_2][y_1] Q_12 = temp[x_1][y_2] Q_22 = temp[x_2][y_2] # 对x方向进行插值 R_1 = (x_2-x)/(x_2-x_1) * Q_11 + (x-x_1)/(x_2-x_1) * Q_21 R_2 = (x_2-x)/(x_2-x_1) * Q_12 + (x-x_1)/(x_2-x_1) * Q_22 # 对y方向进行插值 Q = (y_2-y)/(y_2-y_1) * R_1 + (y-y_1)/(y_2-y_1) * R_2 return Q
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 反池化:反平均池化将特征图恢复到原始尺寸,将池化结果对应的池化值填充到其对应的池化区域的每个位置。反最大池化要求在正向池化的过程中记录池化区域最大激活值的像素位置,在恢复到原始尺寸时,将池化值填入对应位置,其他位置补0。
- 反卷积:是一种特殊的正向卷积,先按照一定的比例通过补 来扩大输入图像的尺寸,接着旋转卷积核,再进行正向卷积。之前被应用在FCN的上采样。
1.10.2 卷积层参数量和计算量
对于输入特征为CxHxW,卷积核为3x3,输出通道为Cout
卷积层参数量为:Cx3x3xCout
卷积层计算量为:CoutxHxWx(3x3xC+1)
1.10.3 分布式计算(前向/后向)
现有的分布式计算方法主要有:
torch.nn.DataParallel(DP)-----> 单机多卡
torch.nn.parallel.DistributedDataParallel (DDP)-----> 单机多卡、多机多卡
DP的代码部署相对简单,它使用一个进程来计算模型参数,然后在前向传递过程中将数据和参数分发到每个GPU,然后每个GPU计算各自的梯度,然后在主GPU中汇总平均进行反向传播更新参数,然后再把模型的参数由主GPU传播给其他的GPU。即在反向传播的过程中需要算出每张卡上的Loss在主卡上更新。在基于DP训练的过程传递的是模型的参数,所以速度较慢。
DistributedDataParallel为多进程,其每个进程都有独立的优化器,在每张卡上独立执行自己的更新过程,但是梯度通过通信协议传递到每个进程,所有执行的内容是相同的;反向传播过程在每张卡上计算Loss分别进行更新。DDP后端backend,默认为“nncl”,为多个机器之间交互数据的协议。
syrcBN提供了跨卡batch normalization通信协议,在前向传播的过程中拿到所有GPU全局的样本和方差,在后向传播时得到相应的全局梯度。
1.10.4 高斯滤波
1.11 图像相关
- 无损图像编码和有损图像编码都有哪些?
JPEG是有损压缩、PNG是无损压缩。
其他有损压缩还有:GIF,MP3,MP4,MKV,OGG等;
其他无损压缩还有:RAW,BMP,PNG,WAV,FLAC,ALAC等; - 视频编码
1.12 C++
- 静态变量、全局变量、局部变量
static 用来控制变量的存储方式和可见性。
在函数体内定义的变量,通常被称为局部变量,当函数执行完成时,为该函数创建的空间站栈会被释放,对应的变量会被销毁;如果希望函数体内的变量在函数执行完毕后继续使用,可以定义全局变量,但是破坏了此变量的访问范围;使用静态变量可以解决这个问题。在 C++ 中,需要一个数据对象为整个类而非某个对象服务,同时又力求不破坏类的封装性,即要求此成员隐藏在类的内部,对外不可见时,可将其定义为静态数据。
在程序运行的过程中,静态数据变量仅被初始化一次,静态数据变量不能写在类的声明中(只定义数据成员),因为类定义中不实际分配空间。空间分配有三个可能的地方,一是作为类的外部接口的头文件,那里有类声明;二是类定义的内部实现,那里有类的成员函数定义;三是应用程序的 main() 函数前的全局数据声明和定义处。
全局变量和全局静态变量的区别:1)全局变量是不显式用 static 修饰的全局变量,全局变量默认是有外部链接性的,作用域是整个工程,在一个文件内定义的全局变量,在另一个文件中,通过 extern 全局变量名的声明,就可以使用全局变量。2)全局静态变量是显式用 static 修饰的全局变量,作用域是声明此变量所在的文件,其他的文件即使用 extern 声明也不能使用。
被static修饰的类变量/类方法,是所有实例对象间共有的。
不能通过类名来调用类的非静态成员函数。通过类的对象调用静态成员函数和非静态成员函数。
类的对象可以使用静态成员函数和非静态成员函数。在类的静态成员函数中使用类的非静态成员。
分割任务
VOS
SOD
指标
F1 Score
统计学中用来衡量二分类模型精确度的一种指标。
p
r
e
c
i
s
i
o
n
=
T
P
/
(
T
P
+
F
P
)
,
r
e
c
a
l
l
=
T
P
/
(
T
P
+
F
N
)
precision = TP / (TP+FP), recall = TP/(TP+FN)
precision=TP/(TP+FP),recall=TP/(TP+FN)
MAE
语义分割
全卷积网络 FCN
指标
Pixel Accurate(PA)
推断正确的像素点个数/全部像素点数量的比值,
P
i
j
P_{ij}
Pij表示类i元素被推断为类j。

Mean Pixel Accurate (MPA)
对于每一个像素类别计算其PA,最后对所有类别计算平均值。

Mean Intersection over Union(MIoU)

对每个类别计算其交集与并集之比,最后根据类别计算平均。相当于
TP/(TP+FN+FP)


