- 1图像分割UNet系列------UNet3+(UNet3plus)详解
- 2在线租房网站毕业设计源码_毕设包调试
- 3两级运算放大器设计与仿真_两级运算放大器测试
- 4深入 Java 调试体系,第 2 部分
- 5【动手学深度学习-pytorch】8.5 循环神经网络的从零开始实现
- 6最新ChatGPT网站源码运营版+支持ai绘画(Midjourney)+GPT4.0+GPT官方3.5key绘画+实时语音识别输入+后台一键版本更新!_最新chatgpt源码
- 7Android开发基础——广播机制_android广播的实现方式
- 8MySql查看数据库变量信息常用脚本_3、使用“show variables like '%storage_engin-%;”查看当前m
- 9经典图像分割网络:Unet 支持libtorch部署推理【附代码】_libtorch 分类推理
- 10李宏毅深度学习 自注意力机制_李宏毅 深度学习 自注意力机制
【论文解读】文本分类上分利器:Bert微调trick大全_基于文本挖掘的企业隐患排查质量分析模型
赞
踩
论文标题:How to Fine-Tune BERT for Text Classification?
中文标题:如何微调 BERT 进行文本分类?
论文作者:复旦大学邱锡鹏老师课题组
实验代码:https://github.com/xuyige/BERT4doc-Classification
前言
大家现在打比赛对预训练模型非常喜爱,基本上作为NLP比赛基线首选(图像分类也有预训练模型)。预训练模型虽然很强,可能通过简单的微调就能给我们带来很大提升,但是大家会发现比赛做到后期,bert等预训练模型炼丹一定程度的时候很难有所提升,分数达到了瓶颈,这个时候需要针对具体的任务如何进行微调使用,就涉及到了考经验积累的tricks,这篇论文做了非常大的充足实验,为我们提供了宝贵的BERT微调经验及方法论,当需要应用BERT到具体的现实任务上时,可以参照这篇论文提供的调参路线进行优化,我在NLP比赛中也屡试不爽,总有一个trick是你的菜,推荐大家读一读这篇论文!
论文摘要
这篇论文的主要目的在于在文本分类任务上探索不同的BERT微调方法并提供一种通用的BERT微调解决方法。这篇论文从三种路线进行了探索:(1) BERT自身的微调策略,包括长文本处理、学习率、不同层的选择等方法;(2) 目标任务内、领域内及跨领域的进一步预训练BERT;(3) 多任务学习。微调后的BERT在七个英文数据集及搜狗中文数据集上取得了当前最优的结果。有兴趣的朋友可以点击上面的实验代码,跑一跑玩一玩~
论文背景与研究动机
文本分了是NLP中非常经典的任务,就是判断给定的一个文本所属的具体类别,比如判断文本情感是正向还是负向。尽管已经有相关的系研究工作表明基于大语料预训练模型可以对文本分类以及其他NLP任务有非常不错的效果收益和提升,这样做的一个非常大的好处我们不需要从头开始训练一个新的模型,节省了很大资源和时间。一种常见的预训练模型就是我们常见的词嵌入,比如Word2Vec,Glove向量,或者一词多义词向量模型Cove和ELMo,这些词向量经常用来当做NLP任务的附加特征。另一种预训练模型是句子级别上的向量化表示,如ULMFiT。其他的还有OpenAI GPT及BERT。
虽然BERT在许多自然语言理解任务上取得了惊人的成绩,但是它的潜力还尚未被完全探索出来。很少有研究来进一步改进BERT在目标任务上的性能。这篇论文的主要目的就是通过探索多种方式最大化地利用BERT来增强其在文本分类任务上的性能。
本篇论文的主要贡献如下:
(1)提出了一个通用的解决方案来微调预训练的 BERT 模型,它包括三个步骤:(1)进一步预训练 BERT
任务内训练数据或领域内数据; (2) 如果有多个相关任务可用,可选用多任务学习微调 BERT; (3) 为目标任务微调BERT。
(2)本文研究了 BERT 在目标任务上的微调方法,包括长文本预处理、逐层选择、逐层学习率、灾难性遗忘
(3)我们在七个广泛研究的英文文本分类数据集和一个中文新闻分类数据集上取得了SOTA成果
论文核心
-
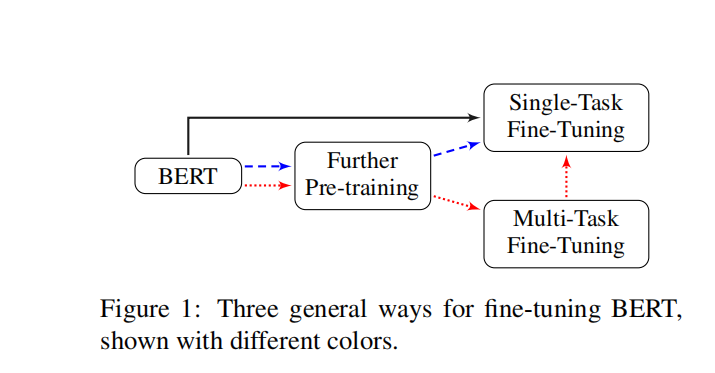
Fine-Tuning Strategies:当我们为目标任务微调 BERT 时,有很多方法可以
使用 BERT。 例如,BERT 的不同层捕获不同级别的语义和句法信息,哪一层更适合目标任务? 我们如何选择更好的优化算法和学习率? -
Further Pre-training:BERT 在通用域中训练,其数据分布与目标域不同。 一个自然的想法是使用目标域数据进一步预训练 BERT。这个真的非常有效,在微调达到一定瓶颈之后,可以尝试下在比赛语料上ITPT,也就是继续预训练。在海华阅读理解比赛以及基于文本挖掘的企业隐患排查质量分析模型都得到了成功验证~
-
Multi-Task Fine-Tuning:在没有预先训练的 LM 模型的情况下,多任务学习已显示出其利用多个任务之间共享知识优势的有效性。 当目标域中有多个可用任务时,一个有趣的问题是,在所有任务上同时微调 BERT 是否仍然带来好处。
微调策略
1. 处理长文本
我们知道BERT 的最大序列长度为 512,BERT 应用于文本分类的第一个问题是如何处理长度大于 512 的文本。本文尝试了以下方式处理长文章。
Truncation methods 截断法
文章的关键信息位于开头和结尾。 我们可以使用三种不同的截断文本方法来执行 BERT 微调。
- head-only: keep the first 510 tokens 头部510个字符,加上两个特殊字符刚好是512 ;
- tail-only: keep the last 510 tokens;尾部510个字符,同理加上两个特殊字符刚好是512 ;
- head+tail: empirically select the first 128and the last 382 tokens.:尾部结合
Hierarchical methods 层级法
输入的文本首先被分成k = L/510个片段,喂入 BERT 以获得 k 个文本片段的表示向量。 每个片段的表示是最后一层的 [CLS] 标记的隐藏状态,然后我们使用均值池化、最大池化和自注意力来组合所有片段的表示。
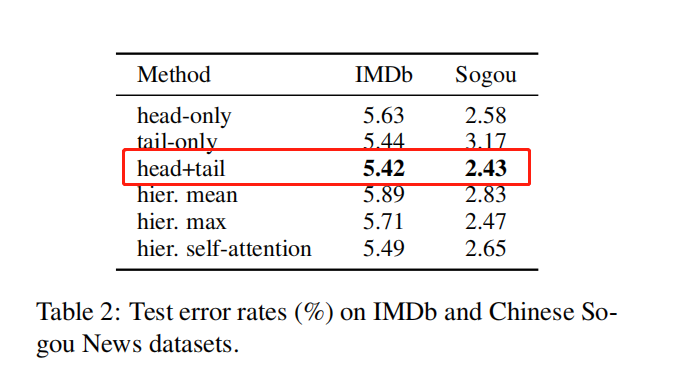
上表的结果显示,head+tail的截断法在IMDb和Sogou数据集上表现最好。后续的实验也是采用这种方式进行处理。
2. 不同层的特征
BERT 的每一层都捕获输入文本的不同特征。 文本研究了来自不同层的特征的有效性, 然后我们微调模型并记录测试错误率的性能。
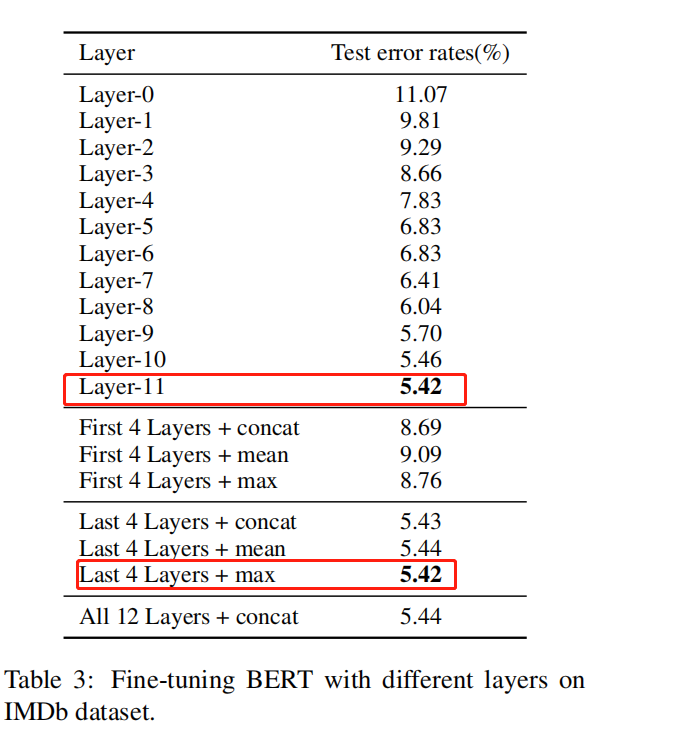
我们可以看到:最后一层表征效果最好;最后4层进行max-pooling效果最好
3. 灾难性遗忘
Catastrophic forgetting (灾难性遗忘)通常是迁移学习中的常见诟病,这意味着在学习新知识的过程中预先训练的知识会被遗忘。
因此,本文还研究了 BERT 是否存在灾难性遗忘问题。 我们用不同的学习率对 BERT 进行了微调,发现需要较低的学习率,例如 2e-5,才能使 BERT 克服灾难性遗忘问题。 在 4e-4 的较大学习率下,训练集无法收敛。
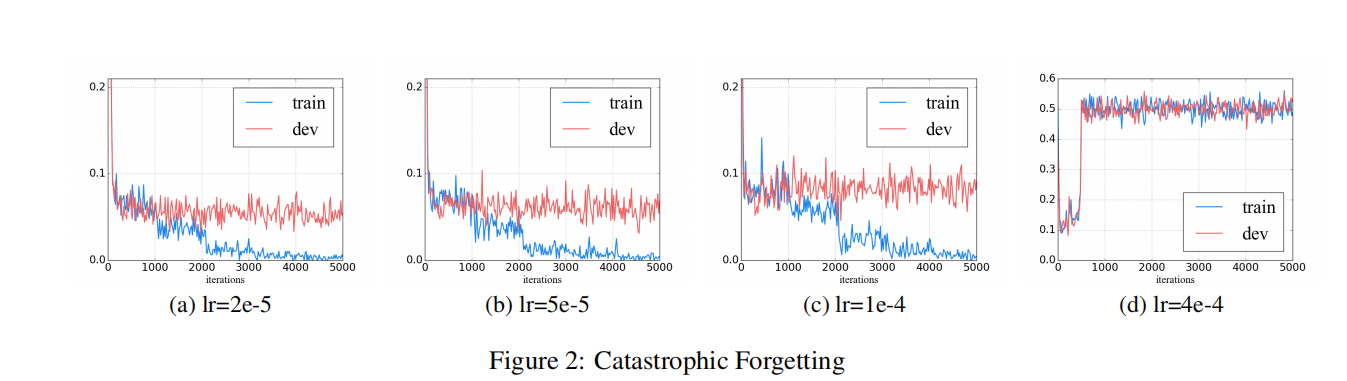
这个也深有体会,当预训练模型失效不能够收敛的时候多检查下超参数是否设置有问题。
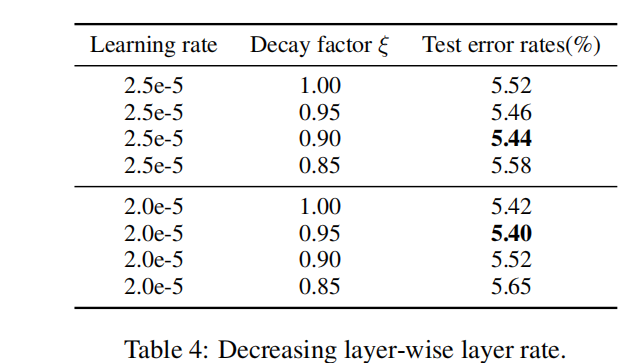
4. Layer-wise Decreasing Layer Rate 逐层降低学习率
下表 显示了不同基础学习率和衰减因子在 IMDb 数据集上的性能。 我们发现为下层分配较低的学习率对微调 BERT 是有效的,比较合适的设置是 ξ=0.95 和 lr=2.0e-5
为不同的BERT设置不同的学习率及衰减因子,BERT的表现如何?把参数θ \thetaθ划分成{ θ 1 , … , θ L } {\theta1,\dots,\thetaL}{θ
1
,…,θ
L
},其中θ l \theta^lθ
l
ITPT:继续预训练
Bert是在通用的语料上进行预训练的,如果要在特定领域应用文本分类,数据分布一定是有一些差距的。这时候可以考虑进行深度预训练。
Within-task pre-training:Bert在训练语料上进行预训练
In-domain pre-training:在同一领域上的语料进行预训练
Cross-domain pre-training:在不同领域上的语料进行预训练
- Within-task pretraining
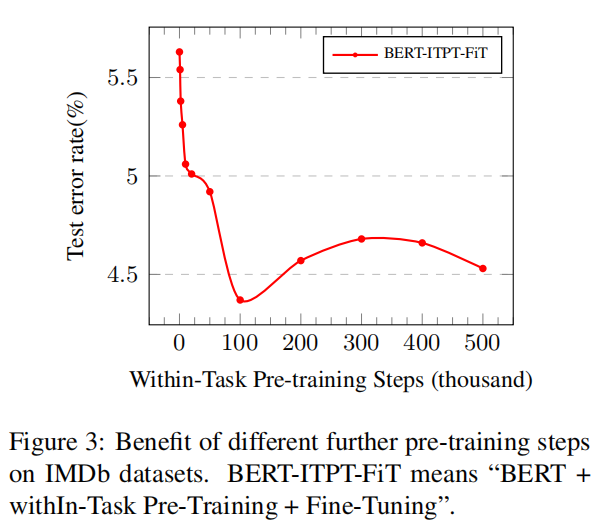
BERT-ITPT-FiT 的意思是“BERT + with In-Task Pre-Training + Fine-Tuning”,上图表示IMDb 数据集上进行不同步数的继续预训练是有收益的。
2 In-Domain 和 Cross-Domain Further Pre-Training
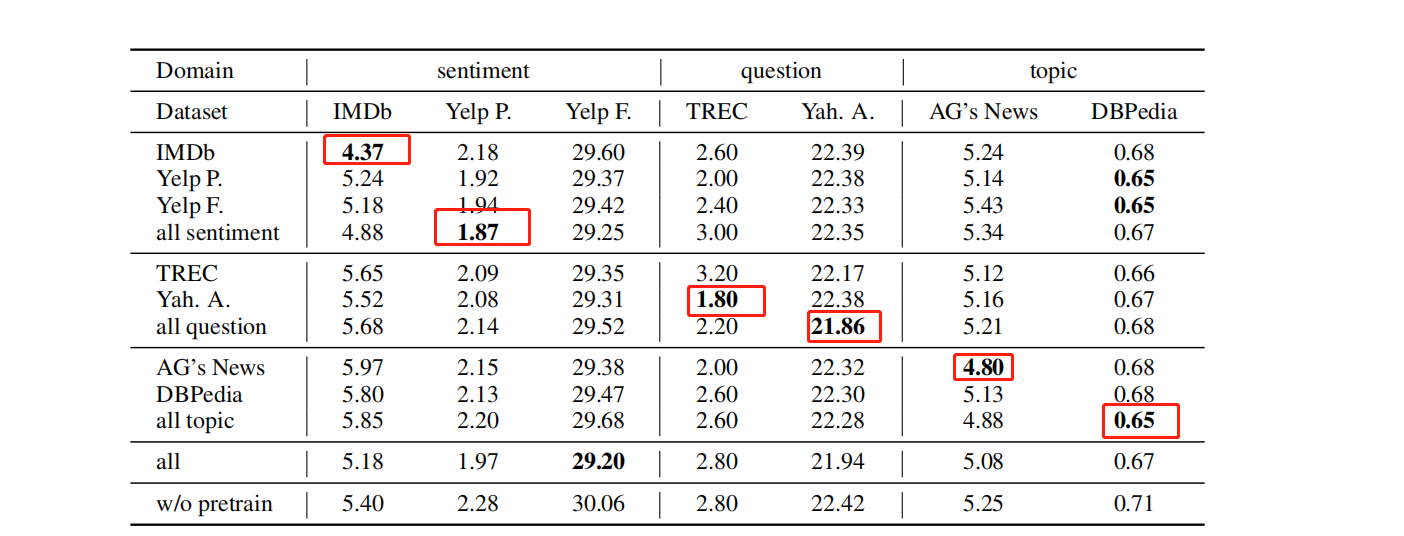
我们发现几乎所有进一步的预训练模型在所有七个数据集上的表现都比原始 BERT 基础模型。 一般来说,域内预训练可以带来比任务内预训练更好的性能。 在小句子级 TREC 数据集上,任务内预训练会损害性能,而在使用 Yah 的领域预训练中。Yah. A.语料库可以在TREC上取得更好的结果。
这篇论文与其他模型进行了比较,结果如下表所示:
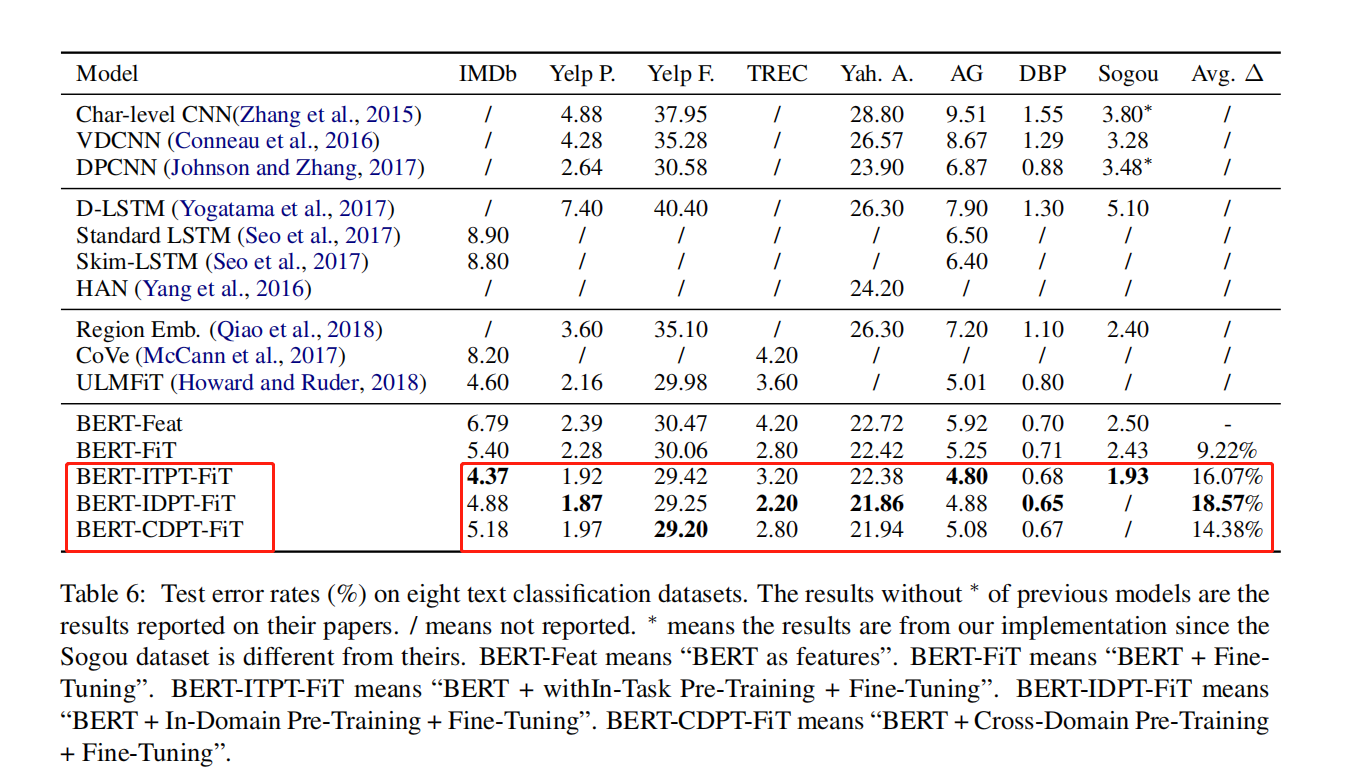
我们可以看到ITPT和IDPT以及CDPT的错误率相比其他模型在不同数据集有不同程度下降。
多任务微调
所有任务都会共享BERT层及Embedding层,唯一不共享的层就是最终的分类层,每个任务都有各自的分类层。
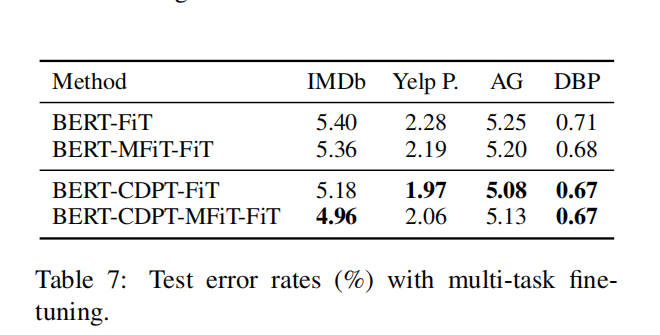
上表表明对于基于BERT多任务微调,效果有所提升,但是对于CDPT的多任务微调是有所下降的,所以说多任务学习对于改进对相关文本分类子任务的泛化可能不是必要的。
小样本学习 Few-Shot Learning
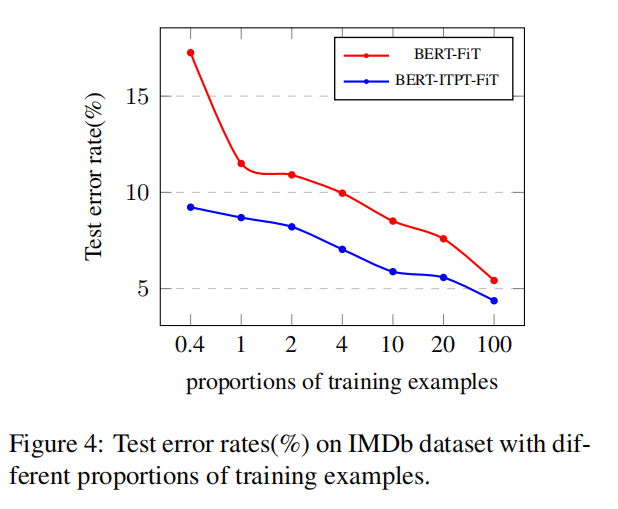
实验表明:BERT能够为小规模数据带来显著的性能提升。
BERT Large模型上进一步预训练
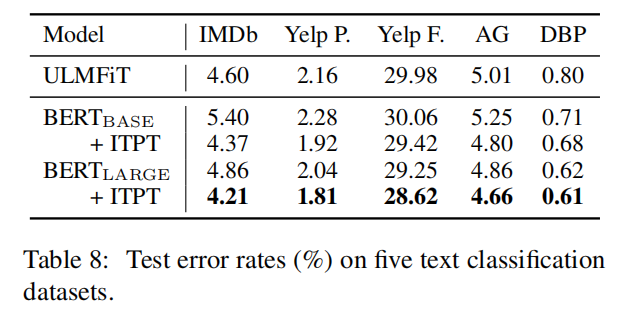
实验结果表明:在特定任务上微调BERT Large模型能够获得当前最优的结果。
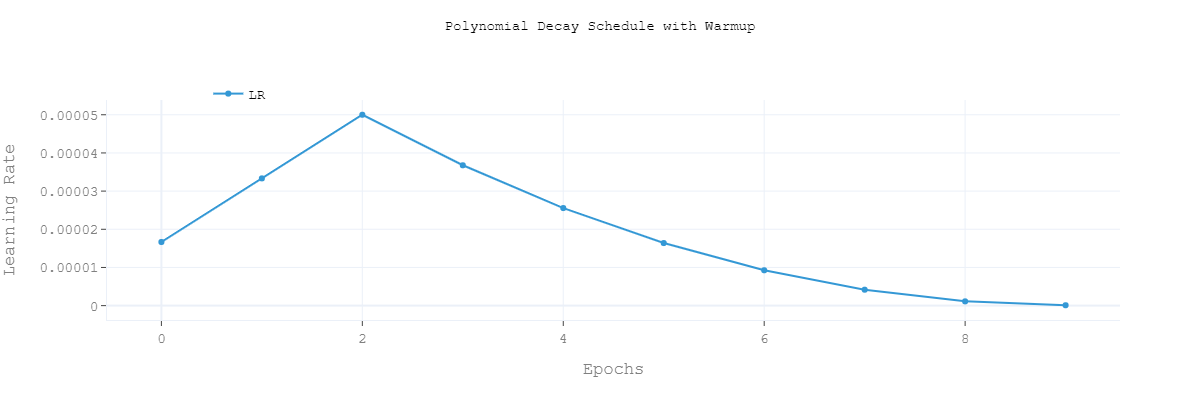
接下来给大家带来干货部分:不同学习率策略的使用
不同学习率策略
完整代码回复“学习率”获取
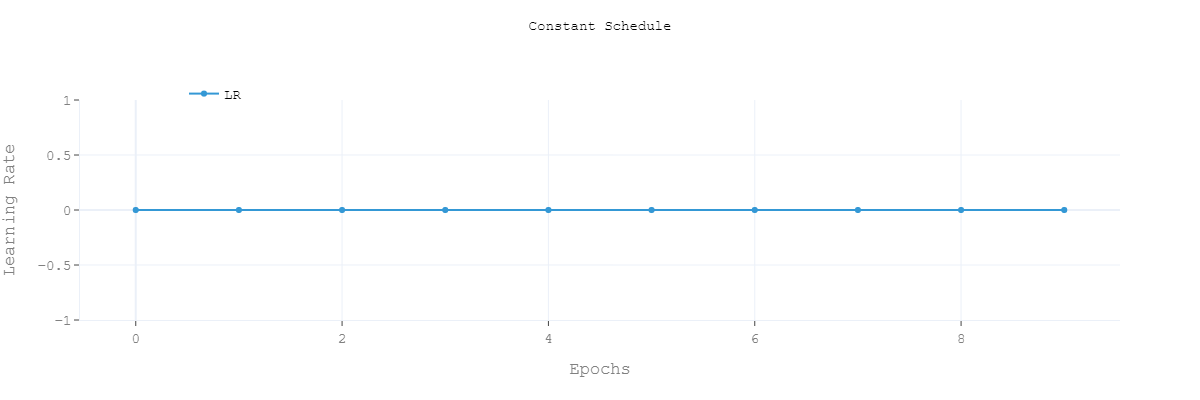
- Constant Schedule
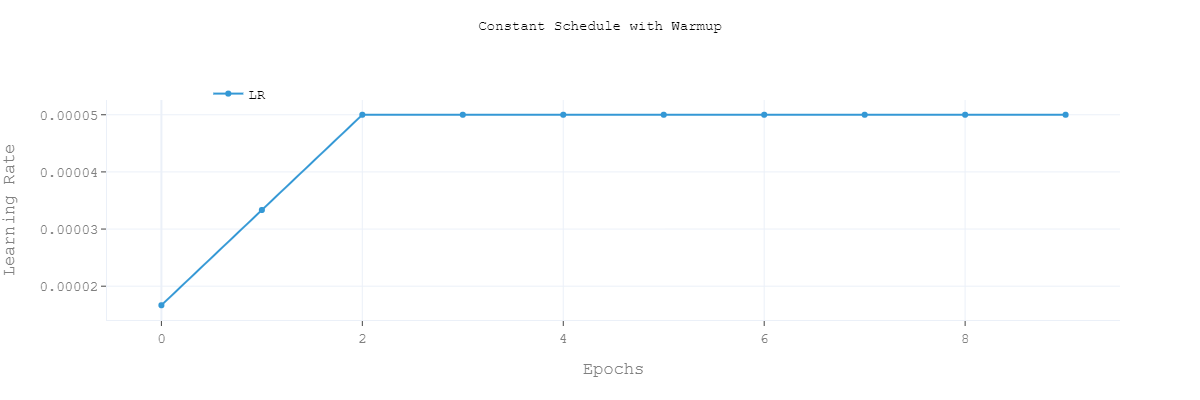
- Constant Schedule with Warmup
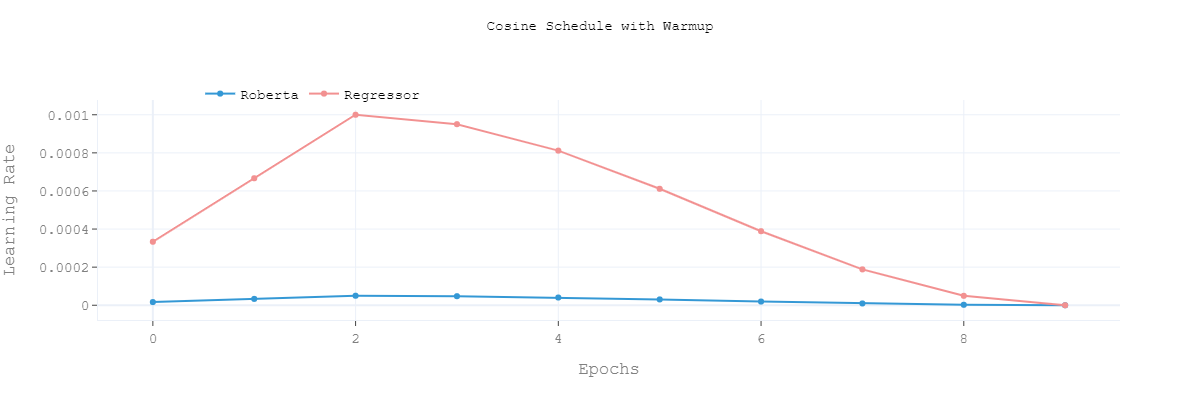
- Cosine with Warmup
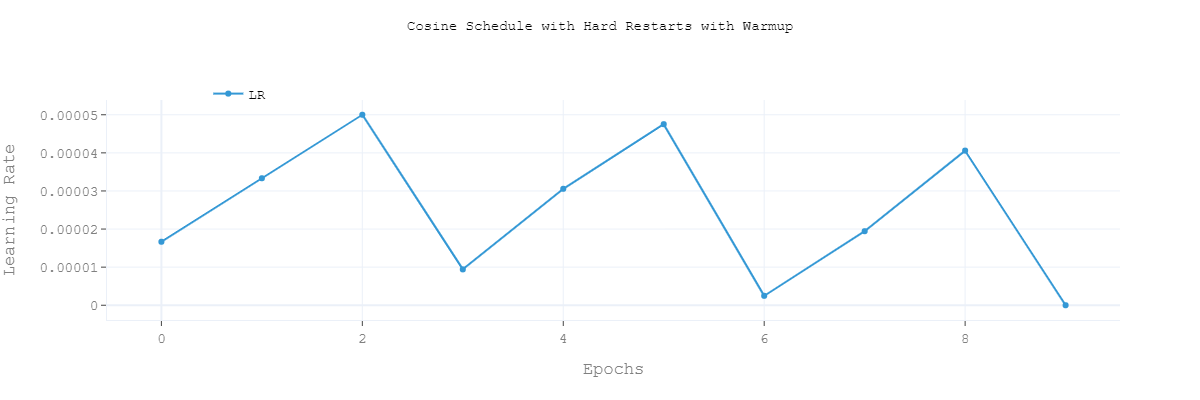
- Cosine With Hard Restarts
- Linear Schedule with Warmup
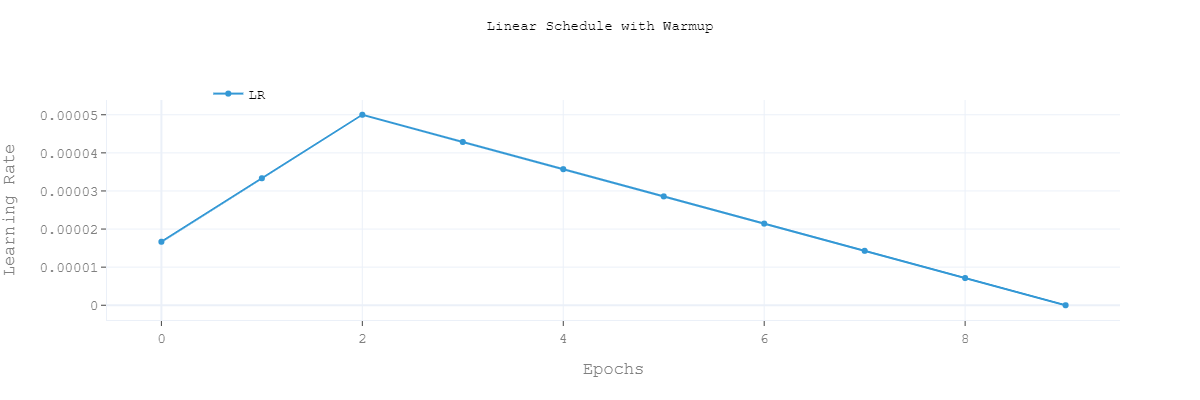
- Polynomial Decay with Warmup