
LLM 推理优化
赞
踩
LLM 推理服务重点关注两个指标:吞吐量和时延:
- 吞吐量:主要从系统的角度来看,即系统在单位时间内能处理的 tokens 数量。计算方法为系统处理完成的 tokens个数除以对应耗时,其中 tokens 个数一般指输入序列和输出序列长度之和。吞吐量越高,代表 LLM服务系统的资源利用率越高,对应的系统成本越低。
- 时延:主要从用户的视角来看,即用户平均收到每个 token所需位时间。计算方法为用户从发出请求到收到完整响应所需的时间除以生成序列长度。一般来讲,当时延不大于 50 ms/token时,用户使用体验会比较流畅。
吞吐量关注系统成本,高吞吐量代表系统单位时间处理的请求大,系统利用率高。时延关注用户使用体验,即返回结果要快。这两个指标一般情况下需要会相互影响,因此需要权衡。例如, 提高吞吐量的方法一般是提升 batchsize,即将用户的请求由串行改为并行。但 batchsize 的增大会在一定程度上损害每个用户的时延,因为以前只计算一个请求,现在合并计算多个请求,每个用户等待的时间变长。
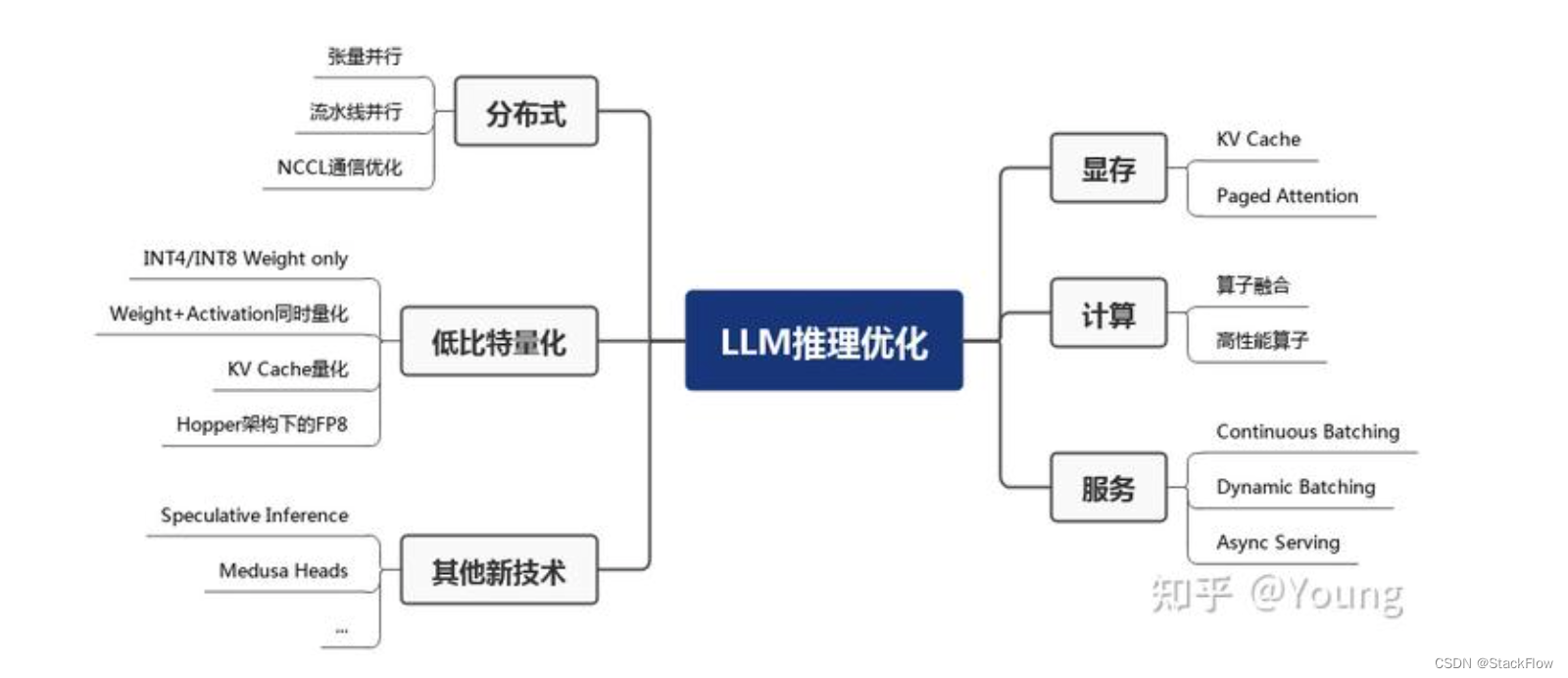
01.“Short” Summary

推理优化主要出于几个问题去解决
一)单request单次推理中的算子级优化问题,如算子融合、算子加速,后者主要就是以FlashAttention、FlashDecoder为代表工作。核心问题还是在矩阵分块的时候设计好一个能够充分利用高速访存HBM的分块方法,让一次搬运进HBM中的参数可以全部和该做乘加操作的算子都计算完再丢弃,达到数量单次访存利用率最大化。
二)面向多request多用户推理服务系统中的优化问题,这里通俗的讲就是说如果当个算子优化的再好,但是用户在使用时都是排队等待前面用户任务执行完再跑自己的,那估计系统服务就没有人用了。并且大模型推理中潜在的访存墙问题也会因为多服务合并出来的大batch,每次共享(复用)读取到的参数,增加单位访存的利用率,进而增加芯片计算利用率。目前来说比较有代表性的工作就是continuing batch等工作。
三)当模型大到一块卡甚至一台机器放不下的情况,包括模型放得下但是多请求服务系统中形成的规模放不下的情况,都会涉及到分布式系统和分布并行方法来帮忙解决其中的瓶颈。包括并行机制、分布调度、通信优化、容错优化等等方面。
四)改进推理算法类的工作:比如在推理时不再是一个词一个词蹦,可能一次多出来几个词作为候选的投机推理方法,比较有名如SpecInfer等工作;还有改变自回归机制的方法。不过这些方法大体上都需要训练配合。还有就是新的循环结构,如RWKV等。
五)模型小型化的工作:这里又会细分为小模型设计、模型稀疏化、模型剪枝、量化推理、蒸馏等方面
这篇文章有些长,以下是主要内容要点:
0. 算法优化: kvcache,连续批处理,pagedattention,算子融合
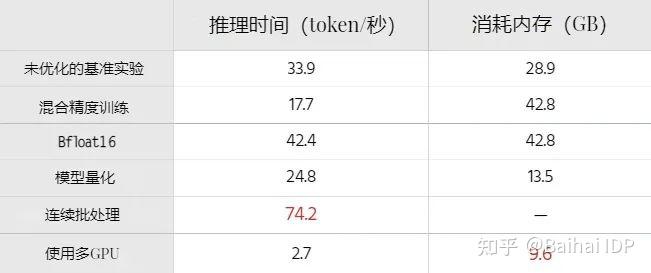
1. 降低精度: 使用float16或bfloat16。这将使模型加速约20%,内存消耗减少2倍。
2. 使用8位或4位量化: 使用8位或4位的模型量化方式可以将内存消耗减少2倍或3倍。这种方法对需要运行于内存受限的小型设备上的模型效果最好。需注意:量化会降低模型预测的质量。
3. **使用adapters(LoRA[2]、QLoRA[3])进行微调,**能够提高模型在特定数据上的预测准确性和性能。与模型量化技术结合使用效果良好。
4. **使用并行技术(tensor parallelism)**能够加速大模型在多GPU上的推理。
5. 如果可能,尽可能使用LLM推理和服务库,如Text Generation Inference、DeepSpeed[4]或vLLM[5]。这些库已经包含了各种优化技术:张量并行(tensor parallelism)、模型量化(quantization)、对连续到达的请求进行批处理操作(continuous batching of incoming requests)、经过优化的CUDA核函数(optimized CUDA kernels)等等。
6. 在将大模型投入生产环境之前进行一些初步测试。 我在使用某些库时花了很多时间去修复Bugs。此外,并非所有LLM都有可行的推理加速解决方案。
7. 不要忘记评估最终的解决方案。 最好准备好数据集进行快速测试。
下面我们将开始详细讨论这些要点。
1.1 显存相关优化
| 技术名称 | 解决问题 | 加速方法 | 备注 |
|---|---|---|---|
| KV Cache | 自回归推理中的键值对重复计算问题 | 缓存之前 token 的键(K)和值(V)对,避免重复计算 | 占用一定的存储空间,但提高推理效率 |
| Flash Attention | 自注意力计算中的冗余操作 | 通过数学变换减少计算量,保持或近似保持原有的注意力分布 | 软件层面的优化,提高推理速度 |
| Continuous Batching | 提升大型语言模型部署吞吐量 | 动态地组织和处理批次,提高数据处理速度 | 通过内存优化实现,不需要修改模型权重 |
| Paged Attention | 显存碎片化问题 | 在不连续的物理空间中存储连续的 K-V 键值对,分页管理关系 | 减少显存占用,提高 KV Cache 可使用的显存空间,提升推理性能 |
1.1.1 KV Cache
大模型推理性能优化的一个最常用技术就是 KV Cache,该技术可以在不影响任何计算精度的前提下,通过空间换时间思想,提高推理性能。目前业界主流 LLM 推理框架均默认支持并开启了该功能。
Transformer 模型具有自回归推理的特点,即每次推理只会预测输出一个 token,当前轮输出token 与历史输入 tokens 拼接,作为下一轮的输入 tokens,反复执行多次。该过程中,前后两轮的输入只相差一个 token,存在重复计算。KV Cache 技术实现了将可复用的键值向量结果保存下来,从而避免了重复计算。

具体来讲,KV Cache 技术是指每次自回归推理过程中,将 Transformer 每层的 Attention 模块中的 X_i_W_k 和 X_iW_v 结果保存保存在一个数据结构(称为 KV Cache)中(如图 2 所示),当执行下一次自回归推理时,直接将 X_i+1*W_k 和 X_i+1*_W_v 与 KV Cache 拼接在一起,供后续计算使用(如下图所示)。其中,X_i 代表第 i 步推理的输入,W_k 和 W_v 分别代表键值权重矩阵。
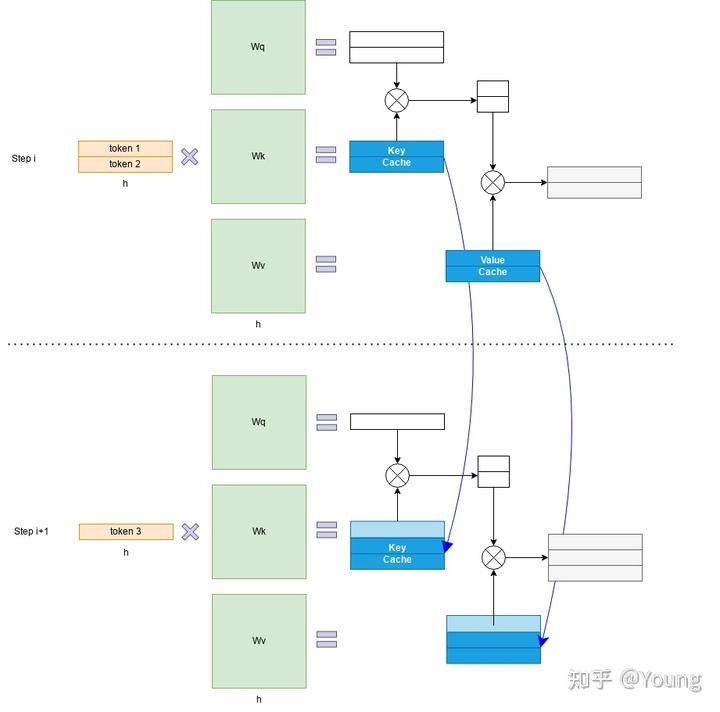
KV Cache 缓存每一轮已计算完毕的键值向量,因此会额外增加显存开销。
KV Cache 与 batchsize 和序列长度呈线性关系
KV Cache 的引入也使得推理过程分为如下两个不同阶段,进而影响到后续的其他优化方法。
- 预填充阶段:发生在计算第一个输出 token 过程中,计算时需要为每个 Transformer layer 计算并保存 key cache 和 value cache;FLOPs 同 KV Cache 关闭一致,存在大量 GEMM (GEneral Matrix-Matrix multiply) 操作,属于 Compute-bound 类型计算。
- 解码阶段:发生在计算第二个输出 token 至最后一个 token 过程中,这时 KV Cache 已存有历史键值结果,每轮推理只需读取 Cache,同时将当前轮计算出的新的 Key、Value 追加写入至 Cache;GEMM 变为 GEMV (GEneral Matrix-Vector multiply) 操作,FLOPs 降低,推理速度相对预填充阶段变快,这时属于 Memory-bound 类型计算。
1.1.2 Paged Attention
LLM 推理服务的吞吐量指标主要受制于显存限制。研究团队发现现有系统由于缺乏精细的显存管理方法而浪费了 60% 至 80% 的显存,浪费的显存主要来自 KV Cache。因此,有效管理 KV Cache 是一个重大挑战。
在 Paged Attention 之前,业界主流 LLM 推理框架在 KV Cache 管理方面均存在一定的低效。HuggingFace Transformers 库中,KV Cache 是随着执行动态申请显存空间,由于 GPU显存分配耗时一般都高于 CUDA kernel 执行耗时,因此动态申请显存空间会造成极大的时延开销,且会引入显存碎片化。FasterTransformer 中,预先为 KV Cache 分配了一个充分长的显存空间,用于存储用户的上下文数据。例如 LLaMA-7B 的上下文长度为 2048,则需要为每个用户预先分配一个可支持 2048 个 tokens 缓存的显存空间。如果用户实际使用的上下文长度低于2048,则会存在显存浪费。Paged Attention 将传统操作系统中对内存管理的思想引入 LLM,实现了一个高效的显存管理器,通过精细化管理显存,实现了在物理非连续的显存空间中以极低的成本存储、读取、新增和删除键值向量。
具体来讲,Paged Attention 将每个序列的 KV Cache 分成若干块,每个块包含固定数量token 的键和值。
首先在推理实际任务前,会根据用户设置的 max_num_batched_tokens 和 gpu_memory_util 预跑一次推理计算,记录峰值显存占用量 peak_memory,然后根上面公式获得当前软硬件环境下 KV Cache 可用的最大空间,并预先申请缓存空间。其中,max_num_batched_tokens 为部署环境的硬件显存一次最多能容纳的 token 总量,gpu_memory_util 为模型推理的最大显存占用比例,total_gpu_memory 为物理显存量, block_size 为块大小(默认设为 16)。
在实际推理过程中,维护一个逻辑块到物理块的映射表,多个逻辑块可以对应一个物理块,通过引用计数来表示物理块被引用的次数。当引用计数大于一时,代表该物理块被使用,当引用计数等于零时,代表该物理块被释放。通过该方式即可实现将地址不连续的物理块串联在一起统一管理。
Paged Attention 技术开创性地将操作系统中的分页内存管理应用到 KV Cache 的管理中,提高了显存利用效率。另外,通过 token 块粒度的显存管理,系统可以精确计算出剩余显存可容纳的 token 块的个数,配合后文 Dynamic Batching 技术,即可避免系统发生显存溢出的问题。
1.2 计算相关优化
1.2.1 算子融合
算子融合是深度学习模型推理的一种典型优化技术,旨在通过减少计算过程中的访存次数和 Kernel 启动耗时达到提升模型推理性能的目的,该方法同样适用于 LLM 推理。
以 HuggingFace Transformers 库推理 LLaMA-7B 模型为例,经分析模型推理时的算子执行分布如下图所示,该模型有 30 个类型共计 2436 个算子,其中 aten::slice 算子出现频率为 388 次。大量小算子的执行会降低 GPU 利用率,最终影响推理速度。

目前业界基本都针对 Transformer layer 结构特点,手工实现了算子融合。以 DeepSpeed Inference 为例,算子融合主要分为如下四类:
- 归一化层和 QKV 横向融合:将三次计算 Query/Key/Value 的操作合并为一个算子,并与前面的归一化算子融合。
- 自注意力计算融合:将自注意力计算涉及到的多个算子融合为一个,业界熟知的 FlashAttention 即是一个成熟的自注意力融合方案。
- 残差连接、归一化层、全连接层和激活层融合:将 MLP 中第一个全连接层上下相关的算子合并为一个。
- 偏置加法和残差连接融合。

由于算子融合一般需要定制化实现算子 CUDA kernel,因此对 GPU 编程能力要求较高。随着编译器技术的引入,涌现出 OpenAI Triton 、TVM 等优秀的框架来实现算子融合的自动化或半自动化,并取得了一定的效果。
2.2.2 高性能算子
针对 LLM 推理运行热点函数编写高性能算子,也可以降低推理时延。
- GEMM 操作相关优化:在 LLM 推理的预填充阶段,Self-Attention 和 MLP 层均存在多个 GEMM 操作,耗时占据了推理时延的 80% 以上。GEMM 的 GPU 优化是一个相对古老的问题,在此不详细展开描述算法细节。英伟达就该问题已推出 cuBLAS、CUDA、CUTLASS 等不同层级的优化方案。例如,FasterTransformer 框架中存在大量基于 CUTLASS 编写的 GEMM 内核函数。另外,Self-Attention 中存在 GEMM+Softmax+GEMM 结构,因此会结合算子融合联合优化。
- GEMV 操作相关优化:在 LLM 推理的解码阶段,运行热点函数由 GEMM 变为 GEMV。相比 GEMM,GEMV 的计算强度更低,因此优化点主要围绕降低访存开销开展。
高性能算子的实现同样对 GPU 编程能力有较高要求,且算法实现中的若干超参数与特定问题规模相关。因此,编译器相关的技术如自动调优也是业界研究的重点。
2.3 服务相关优化
服务相关优化主要包括 Continuous Batching、Dynamic Batching 和 异步 Tokenize / Detokenize。其中 Continuous Batching 和 Dynamic Batching 主要围绕提高可并发的 batchsize 来提高吞吐量,异步 Tokenize / Detokenize 则通过多线程方式将 Tokenize / Detokenize 执行与模型推理过程时间交叠,实现降低时延目的。
| 问题分类 | 现象 | 解决方法 | 实现原理 | 特点 |
|---|---|---|---|---|
| 问题一 | 同批次序列推理时,存在“气泡”,导致 GPU 资源利用率低 | Continuous Batching | 由 batch 粒度的调度细化为 step 级别的调度 | 在时间轴方向动态插入新序列 |
| 问题二 | 批次大小固定不变,无法随计算资源负载动态变化,导致 GPU 资源利用率低 | Dynamic Batching | 通过维护一个作业队列实现 | 在 batch 维度动态插入新序列 |
| 问题三 | Tokenize / Detokenize 过程在 CPU 上执行,期间 GPU 处于空闲状态 | 异步 Tokenize / Detokenize | 多线程异步 | 流水线 overlap 实现降低时延 |
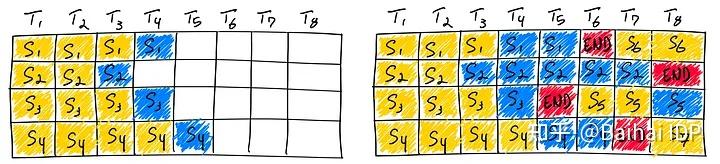
大语言模型的输入和输出均是可变长度的。对于给定问题,模型在运行前无法预测其输出长度。在实际服务场景下,每个用户的问题长度各不相同,问题对应的答案长度也不相同。传统方法在同批次序列推理过程中,存在“气泡”现象,即必须等同批次内的所有序列完成推理之后,才会执行下一批次序列,这就会引起 GPU 资源的浪费,导致 GPU 利用率偏低。
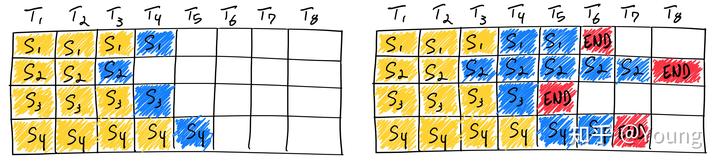
图中序列 3 率先结束,但由于其他序列尚未结束,因此需要等待直至所有序列计算完毕。理想情况下,同批次的所有序列的输入加输出的长度均相同,这时不存在“气泡”现象;极端情况下则会出现超过 50\% 以上的资源浪费。
另一方面,传统方法推理时 batchsize 是固定不变的,无法随计算资源负载动态变化。比如某一段时间内,同批次下的序列长度都偏短,原则上可以增加 batchsize 以充分利用 GPU 计算资源。然而由于固定 batchsize,无法动态调整批次大小。
Continuous Batching 和 Dynamic Batching 思想最早来自论文 Orca: A Distributed Serving System for Transformer-Based Generative Models。针对问题一,提出 Continuous Batching,原理为将传统 batch 粒度的任务调度细化为 step 级别的调度。首先,调度器会维护两个队列,分别为 Running 队列和 Waiting 队列,队列中的序列状态可以在 Running 和 Waiting 之间转换。在自回归迭代生成每个 token 后,调度器均会检查所有序列的状态。一旦序列结束,调度器就将该序列由 Running 队列移除并标记为已完成,同时从 Waiting 队列中按 FCFS (First Come First Service) 策略取出一个序列添加至 Running 队列。

图中,序列 3 率先在 T5 时刻结束,这时调度器会检测到序列 3 已结束,将序列 3 从 Running 队列中移除,并从 Waiting 队列中按 FCFS 策略取出序列 5 添加至 Running 队列并启动该序列的推理。通过该方法,即可最大限度地消除“气泡”现象。
问题一可以理解为在时间轴方向动态插入新序列,问题二则是在 batch 维度动态插入新序列,以尽可能地充分利用显存空间。具体来讲,在自回归迭代生成每个 token 后,调度器通过当前剩余显存量,动态调整 Running 队列的长度,从而实现 Dynamic Batching。例如,当剩余显存量较多时,会尽可能增加 Running 队列长度;当待分配的 KV Cache 超过剩余显存时,调度器会将 Running 队列中低优先级的序列换出至 Waiting 队列,并将换出序列占用的显存释放。
如上两个 batching 相关的优化技术可有效提升推理吞吐量,目前已在 HuggingFace Text-Generation-Interface (TGI)、vLLM、OpenPPL-LLM 等多个框架中实现。
3.1 使用 16 位精度-降低精度
在使用GPU训练深度神经网络时,通常我们会使用低于最高精度的32位浮点运算(实际上,PyTorch就是默认使用32位浮点数)。在浮点表示法中,数值由三个组成部分构成:符号(the sign)、指数(the exponent)和有效数字(the significand)(或称为尾数 mantissa)。

一般来说,位数越多,精度越高,从而降低了计算过程中错误累积的几率。 然而,如果我们想要加快模型的训练速度,可以将精度降低到例如16位。这样做有以下几个好处:
1.减少显存占用:32 位精度所需的 GPU 显存是 16 位精度的两倍,而降低精度则能够更有效地利用GPU显存资源。
2.提高计算能力和计算速度:由于低精度张量(lower precision tensors)的操作所需的显存更少,因此GPU能够更快地进行计算处理,从而提高模型的训练速度。
Lit-GPT 使用 Fabric 库,只需几行代码就能改变精度。
python generate/base.py \
--prompt "I am so fast that I can" \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--max_new_tokens 50 \
--precision "16-true"
# Time for inference: 1.19 sec total, 42.03 tokens/sec
# Memory used: 14.50 GB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.2 混合精度训练 Mixed-precision training
混合精度训练(Mixed-precision training)是一项比较重要的技术,可以较大地提高在GPU上的训练速度。这种方法并不会将所有参数和操作都转换为16位浮点数,而是在训练过程中在32位和16位之间切换操作,因此被称为“混合“精度。

这种方法可以在保持神经网络的准确性和稳定性的同时,进行高效训练。
python generate/base.py \
--prompt "I am so fast that I can" \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--max_new_tokens 50 \
--precision "16-mixed"
# Time for inference 1: 2.82 sec total, 17.70 tokens/sec
# Memory used: 42.84 GB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.3 16位脑浮点(Brain Floating Point)
Bfloat16是由Google提出的一种浮点数格式,名称代表着“Brain Floating Point Format(脑浮点格式)”,其源自于Google旗下的Google Brain[16]人工智能研究小组。可以在此[17]了解更多关于Bfloat16的相关内容。

Google为机器学习和深度学习应用,特别是在Tensor Processing Units(TPUs)中开发了这种格式。虽然 bfloat16 最初是为 TPU 开发的,但现在一些英伟达(NVIDIA)GPU 也支持这种浮点数格式。
python -c "import torch; print(torch.cuda.is_bf16_supported())"
- 1
如果您需要使用bfloat16,您可以运行以下命令:
python generate/base.py \
--prompt "I am so fast that I can" \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--max_new_tokens 50 \
--precision "bf16-true"
# Time for inference: 1.18 sec total, 42.47 tokens/sec
# Memory used: 14.50 GB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
下图汇总了上述结果:

04. 模型量化
回归到 LLM 模型推理吞吐量和时延这两个重要的性能指标上:吞吐量的提升主要受制于显存容量,如果降低推理时显存占用量,就可以运行更大的 batchsize,即可提升吞吐量;LLM 推理具有 Memory-bound 特点,如果降低访存量,将在吞吐量和时延两个性能指标上都有收益。低比特量化技术可以降低显存占用量和访存量,其能取得加速的关键在于显存量和访存量的节省以及量化计算的加速远大于反量化带来的额外开销。
| 被量化的对象 | 量化方法 | 特点 |
|---|---|---|
| 权重量化 | LLM.int8(), GPTQ | 显存占用减半,但由于计算结果需反量化,时延基本无收益 |
| 权重和激活同时量化 | SmoothQuant | 显存占用减半,时延有收益,精度几乎匹配 FP16 |
| KV Cache量化 | INT8 或 FP8 量化 | 方法简单,吞吐量收益明显 |
| 基于硬件特点的量化:英伟达 Hopper 架构下的 FP8 | 直接利用 TensorCore FP8 计算指令 | 不需要额外的量化/反量化操作,时延收益明显 |
表中的四类量化方法各有特点,业界在低比特量化方向的研究进展也层出不穷,希望探索出一个适用于大语言模型的、能够以较高压缩率压缩模型、加速端到端推理同时保证精度的量化方法。
PTQ由于实现方式简单,不涉及对模型架构的改动也无需额外的训练,因此成为多数LLM首选的量化方式。PTQ大体可分为两类,一类只量化模型参数,如LLM.int8()、ZeroQuant、GPTQ等,另一类同时量化模型参数和激活值,如SmoothQuant、RPTQ、OliVe等。PTQ的缺点也很明显,若将模型量化至更低bit(如int4),会产生较明显的精度损失。
如果我们想在推理时进一步提高模型性能,在使用较低的浮点精度之外,我们还可以使用量化技术。量化是将模型中的浮点数权重或激活值转换为较低精度的表示方式,从浮点数转换为低位整数表示,例如 8 位整数(甚至是 4 位整数)。 对深度神经网络应用量化技术通常有两种常见方法:
QAT(Quant-Aware Training) 也可以称为在线量化(On Quantization)。它需要利用额外的训练数据,在量化的同时结合反向传播对模型权重进行调整,意在确保量化模型的精度不掉点。
PTQ (Post Training Quantization)也可以称为离线量化(Off Quantization)。它是在已训练的模型上,使用少量或不使用额外数据,对模型量化过程进行校准,可能伴有模型权重的缩放。
其中:
训练后动态量化(PostDynamic Quantization)不使用校准数据集,直接对每一层 layer 通过量化公式进行转换。QLoRA 就是采用这种方法。
训练后校正量化(Post Calibration Quantization)需要输入有代表性的数据集,根据模型每一层 layer 的输入输出调整量化权重。GPTQ 就是采用这种方法。
05. 使用Adapters进行微调
适配器是一种针对特定任务的模型优化技术。通过使用适配器,可以对模型进行微调,使其更好地适应特定任务。常用的适配器包括LoRA和QLoRA等。这些适配器可以对模型进行剪枝、权重蒸馏等操作,从而减小模型大小和提高推理速度。需要注意的是,适配器需要针对特定任务进行训练和调整,因此需要一定的时间和资源投入。
虽然微调(fine-tuning)可能并非是一种加快最终模型推理过程的直接方法,但有几种技巧可以用来优化其性能:
1. 预训练和模型量化(Pre-training and Quantization):首先在特定领域的问题上对模型进行预训练,然后进行模型量化。模型量化通常会导致模型质量略有下降,但最初的预训练可以稍微缓解这一问题。
2. 小型适配器(Small Adapters):另一种方法是为不同任务引入小型适配器。适配器的工作原理是在现有模型层中添加紧凑的额外层(compact additional layers),并仅针对它们进行训练。这些适配器层拥有轻量级参数(lightweight parameters),使得模型能够快速适应和学习。
通过结合使用这些方法,可以实现模型的效果增强。
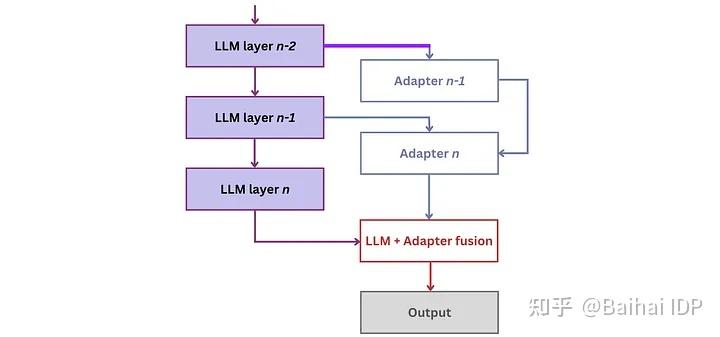
在适配器领域,出现了几种变体,包括LLaMA-Adapter(v1[22]、v2[23])、LoRa和QLoRa。其中,低秩自适应技术(Low-Rank Adaptation,LoRA)[24]表现最为突出。LoRA通过在LLM的每一层引入少量的可训练参数,即适配器,并同时冻结所有原始参数。这种方法简化了微调过程,只需更新适配器权重,大大降低了内存消耗。
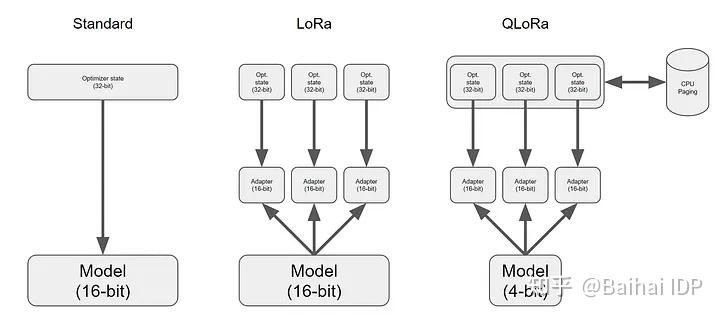
QLoRA[25]方法是在LoRA的基础上增加了模型量化技术其他一些优化,彻底改变了我们在Google Colab实例上对模型进行微调的方式![26]
微调LLM可能需要耗费大量的资源,包括时间和算力。例如,如果使用8个A100 GPU对Falcon-7B进行微调,大约需要半小时左右,而如果只使用单个GPU,大约需要三个小时。 此外,为了获得最佳的微调结果,前期需要对数据集进行一些适当的准备工作。虽然我并没有亲自执行过模型的微调过程,但如果您想要自己动手,可以通过运行以下命令来启动微调过程(在这里[28]可以阅读更多相关信息):
06. 模型剪枝(Pruning)
网络剪枝(Network pruning)通过去除不重要的模型权重或连接来减小模型大小,且同时还保持着模型容量。
另一种新方法 LLM-Pruner[33] 能够根据梯度信息(gradient information)选择性地移除非关键的耦合结构(non-critical coupled structures),采用的是结构剪枝(structural pruning),最大程度地保留了大型语言模型的功能。作者展示压缩后的模型在零样本分类和生成(zero-shot classification and generation)方面表现良好。
(译者注:LLM-Pruner根据参数梯度判断重要性,通过移除不重要的模型结构部分来进行模型压缩。选择哪部分移除的依据是参数梯度的大小。)

LLM-Pruner这篇论文的作者公开了相关代码,但仅支持 LLaMA-7B[34] 和 Vicuna-7B[35] 这两个大语言模型。
还有另一个有趣的剪枝器(pruner)——Wanda[36](根据权重值和激活值剪枝)。该方法会根据每个输出的基础,利用权重与对应输入激活值相乘的结果来剪枝权重。

值得注意的是,Wanda不需要重新训练或更新权重,剪枝后的LLM可以直接使用。此外,它允许我们将LLM剪枝至原来大小的50%。
07. 批量推理 Batch Inference
GPU以其大规模并行计算架构而闻名,在A100[37]上,模型的计算速率甚至以每秒万亿次浮点运算(teraflops)计量,而在像H100[38]这样的GPU上,模型甚至可达到每秒千万亿次浮点运算(petaflops)的水平。尽管有着巨大的计算能力,但由于GPU芯片的一大部分显存带宽被用于加载模型参数,LLM在如果想要充分发挥潜力经常面临困难。
其中一种有效的解决方法是使用批处理技术。与为每个输入序列加载新的模型参数不同,批处理只需要加载一次模型参数,并利用它们处理多个输入序列。这种优化策略高效利用了芯片的显存带宽,从而提高了算力利用率,改善了吞吐量,并使LLM推理更加经济高效。 通过采用批处理技术,可以显著提升LLM的整体性能。
还有一种最近提出的优化方法——连续批处理(continuous batching)。Orca实施了iteration-level scheduling,而不再需要等待批处理(batch)中的每个序列都完成生成,而是根据每次迭代来确定批大小(batch size)。这样做的结果是,一旦批中的一个序列完成生成,就可以插入一个新的序列,从而实现比静态批处理更高的GPU利用率。
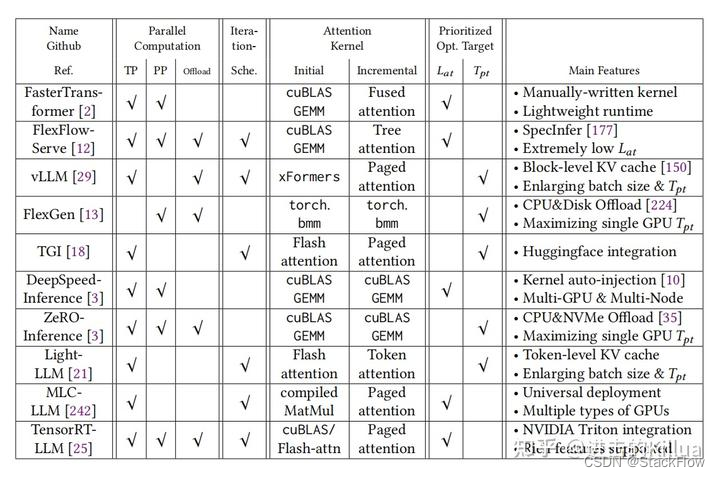
你可以在以下几个框架中使用这种算法:
1. Text Generation Inference[39]— 用于文本生成推理的服务端;
2. vLLM[40] — LLM的推理和服务引擎。
经过仔细评估,我选择了vLLM作为首选。vLLM采用了PagedAttention,这是一种新的注意力算法,可以有效地管理注意力键(keys)和值(values):在无需进行任何模型架构更改的情况下,它的吞吐量比HuggingFace Transformers高出多达24倍。
08. 使用多GPU
数据并行(Data Parallelism)
介绍:
数据并行是一种将大型数据集分割成小块,然后在多个GPU上并行处理的技术。每个GPU处理数据的一个子集,并独立地执行相同的模型计算。最后,将所有GPU的结果汇总以得到最终输出。
缺点:
- 资源利用率不均:如果数据分割不均匀,可能导致某些GPU资源闲置。
- 同步开销:在训练过程中,模型更新需要在所有GPU间同步,可能会增加额外的延迟。
考虑问题:
- 负载均衡:确保数据分割策略能够均匀分配工作负载。
- 同步策略:优化模型参数更新的同步过程,减少等待时间。
张量并行(Tensor Parallelism)
介绍:
张量并行涉及将单个大型张量分割成多个部分,并在不同的GPU上并行计算。这适用于单个模型太大而无法在单个GPU内存中完全加载的情况。
缺点:
- 通信开销:GPU之间需要频繁交换数据,可能导致网络通信成为瓶颈。
- 实现复杂性:需要处理跨GPU的张量分割和重组,增加了实现的复杂度。
考虑问题:
- 通信优化:使用高效的通信库和算法来减少数据传输时间。
- 容错性:设计能够处理通信失败的策略。
流水线并行(Pipeline Parallelism)
介绍:
流水线并行将模型的计算过程分解成一系列阶段,每个阶段由不同的GPU处理。每个GPU完成其特定任务后,将结果传递给下一个GPU,类似于生产线上的流程。
缺点:
- 瓶颈风险:流水线中的任何瓶颈环节都会拖慢整个流程。
- 错误传播:一个环节的错误可能影响后续所有环节。
考虑问题:
- 性能监控:实时监控每个环节的性能,以便快速发现并解决瓶颈。
- 错误处理:实现有效的错误检测和恢复机制,防止错误传播。
在实施这些并行策略时,需要综合考虑模型的大小、复杂性、数据分布、硬件资源以及通信开销等因素,以确保并行推理能够有效地提高性能。
09. 总结
LLM推理加速领域情况比较复杂,目前仍处于初级阶段。在准备本文时,我发现了许多最近被开发的方法,其中一些看起来十分有潜力(这些方法都出现在最近1-2个月内)。
然而,需要注意的是,并非所有的推理加速方法都能稳妥地发挥作用。有些方法甚至可能会降低模型的质量。 因此,盲目接受和应用所有的推理加速建议是不明智的,必须经过慎重考虑。 您必须保持谨慎,控制加速模型(the accelerated model)的质量。
理想情况下,在软件优化(software optimization)和模型架构(model architecture)之间取得平衡是实现LLM推理高效加速的关键。
ref
如何对大语言模型推理进行优化?7策详解
大语言模型推理性能优化综述
LLM量化综合指南(8bits/4bits)

