
- 1基于Java+SpringBoot+vue+node.js的图书购物商城系统详细设计和实现_购物网站代码设计
- 2Ubuntu20.04安装教程_安装ubuntu20分区安装
- 3数据结构之Set和Map
- 4学习python需要多长时间?_pyqt6的库需要多久才能掌握
- 5Flutter学习笔记-与原生(iOS swift)交互_flutter调用ios原生几种通信方法
- 6Postman Post请求四种参数传递方式与Content-Type对应关系_postman content type
- 7python除法向下取整函数_除法:经典除法,向下取整除法和真除法
- 8文生视频Sora模型发布,是否引爆AI芯片热潮
- 9python pytorch模型转onnx模型(多输入+动态维度)_torch.onnx.export 多输入
- 10ChatGPT中文版Prompt提示工程超详细指南《提示工程高级技巧与技术》Github最新破万星项目Meta AI前工程师解密百万年薪提示工程师GPT-4模型优化利器(二)不定期更新_零样本提示谁提出的
论文阅读:《Bag of Tricks for Efficient Text Classification》
赞
踩
重磅推荐专栏: 《大模型AIGC》;《课程大纲》
本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展
https://blog.csdn.net/u011239443/article/details/80076720
论文地址:https://arxiv.org/pdf/1607.01759v2.pdf
摘要
本文提出了一种简单而有效的文本分类和表示学习方法。 我们的实验表明,我们的快速文本分类器fastText在准确性方面通常与深度学习分类器保持一致,并且在训练和评估中速度快很多。 我们可以在不到10分钟的时间内使用标准的多核CPU对超过10亿个单词进行快速文本训练,并在不到一分钟的时间内对312K类中的50万个句子进行分类。
介绍
建立良好的文本分类表示是许多应用程序的重要任务,如Web搜索,信息检索,排序和文档分类。 最近,基于神经网络的模型在计算句子表示方面越来越受欢迎。 虽然这些模型在实践中取得了非常好的表现,但是在训练和测试时间,它们往往相对较慢,限制了它们在非常大的数据集上的使用。
与此同时,简单的线性模型也显示出令人印象深刻的性能,同时计算效率非常高。 他们通常学习单词级别的表示,后来组合起来形成句子表示。 在这项工作中,我们提出了这些模型的扩展,以直接学习句子表示。 我们通过引入其他统计数据(如使用n-gram包)来显示,我们减少了线性和深度模型之间精度的差距,同时速度提高了许多个数量级。
我们的工作与标准线性文本分类器密切相关。 与Wang和Manning类似,我们的动机是探索由用于学习无监督词表示的模型启发的简单基线。 与Le和Mikolov不同的是,我们的方法在测试时不需要复杂的推理,使得其学习表示很容易在不同问题上重复使用。 我们在两个不同的任务中评估模型的质量,即标签预测和情感分析。
模型架构
句子分类的简单而有效的基线是将句子表示为词袋(BoW)并训练线性分类器,例如逻辑回归或支持向量机。 但是,线性分类器不能在特征和类之间共享参数,可能会限制泛化。 这个问题的常见解决方案是将线性分类器分解成低秩矩阵或使用多层神经网络。在神经网络的情况下,信息通过隐藏层共享。
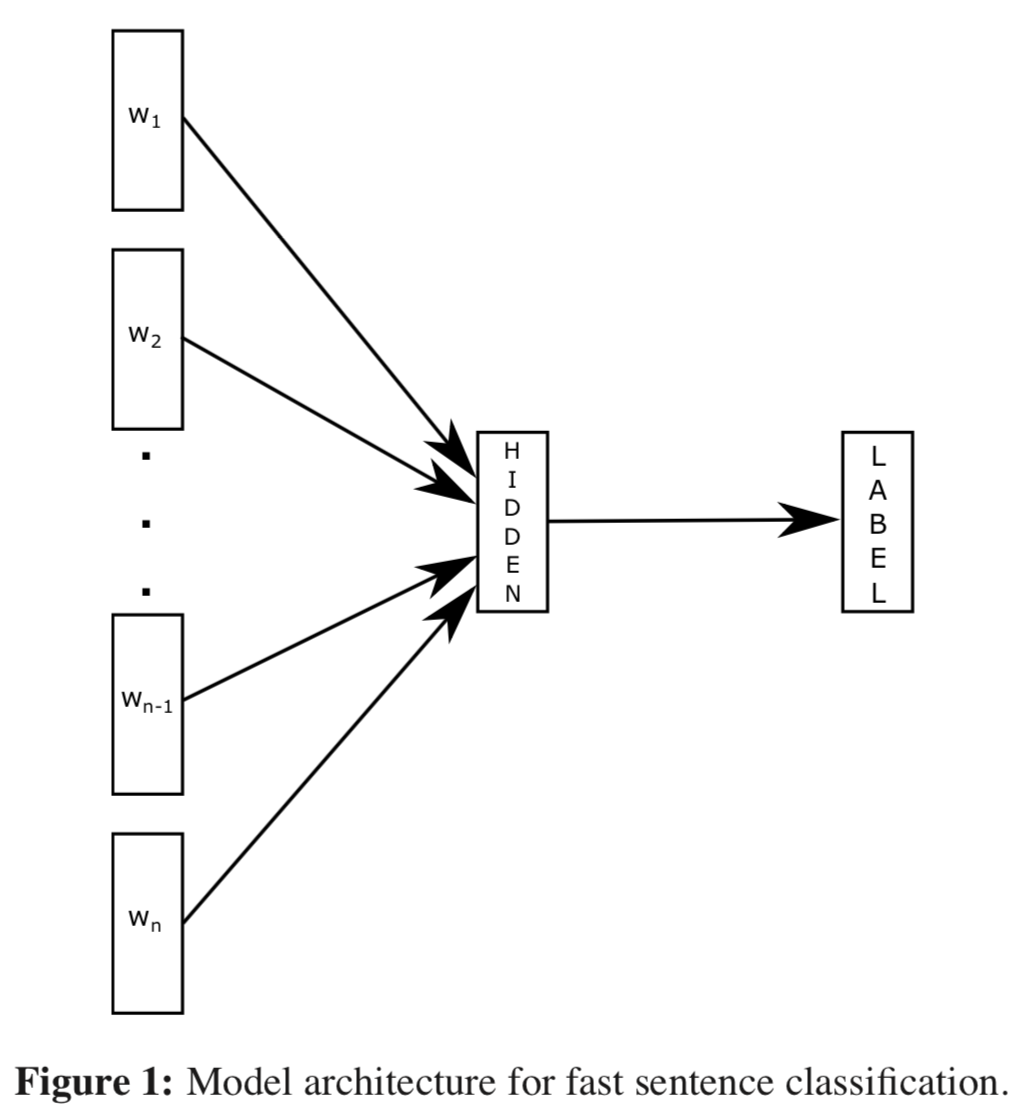
图1显示了一个带有1个隐藏层的简单模型。 第一个权重矩阵可以看作是一个句子单词的查找表。 词表示被平均为文本表示,然后反馈给线性分类器。 这种结构类似于Mikolov等人的cbow模型,其中中间的单词被标签取代。 该模型将一系列单词作为输入,并在预定义的类上生成概率分布。 我们使用softmax函数来计算这些概率。
训练这样的模型本质上与word2vec相似,也就是说,我们使用随机梯度下降和反向传播以及线性衰减的学习速率。 我们的模型在多个CPU上异步训练。
分层softmax
当目标数量很大时,计算线性分类器的计算量很大。 更准确地说,计算复杂度为 O ( K d ) O(Kd) O(Kd),其中K是目标的数量,d是隐藏层的维数。 为了改善我们的运行时间,我们使用基于霍夫曼编码树的分层softmax。 在训练期间,计算复杂度降至 O ( d l o g 2 ( K )) O(d log2(K)) O(dlog2(K))。 在这棵树上,目标是树叶。
当搜索最可能的类别时,分层softmax在测试时间也是有利的。 每个节点都与从根节点到该节点的路径概率相关联。 如果节点与父节点n1,…,nl处于深度l + 1,则其概率为

这意味着节点的概率总是低于其父节点的概率。 通过深度遍历探索树并跟踪叶子之间的最大概率允许我们丢弃与较小概率相关的任何分支。 在实践中,我们观察到在测试时 O ( d l o g 2 ( K )) O(dlog2(K)) O(dlog2(K))的复杂度降低。 这种方法进一步扩展到以 O ( l o g ( T )) O(log(T)) O(log(T))为代价,使用二进制堆计算T-top目标。
N-gram特征
单词包对于词序是不变的,但考虑到这个顺序通常在计算上非常昂贵。 相反,我们使用一袋n-gram作为附加功能来捕获有关本地词序的部分信息。 这在实践中非常高效,同时实现了与明确使用订单的方法类似的结果。
如果我们只使用bigrams,则使用与Mikolov和10M bin相同的哈希函数,否则我们使用哈希函数保持n-gram的快速和高效内存映射。
实验
情绪分析
数据集和基线 我们使用Zhang等人的相同的8个数据集和评估协议。我们报告Zhang等人的N-gram和TFI-DF基线以及Zhang和LeCun的字符级卷积模型(char-CNN)和 Conneau等人的非常深的卷积网络(VDCNN)。我们还与Tang等人的评估协议进行了比较。 我们报告他们的主要基线以及基于递归网络(Conv-GRNN和LSTM-GRNN)的两种方法。
结果 我们在图1中给出了结果。我们使用10个隐藏单元并运行5个纪元的fastText,并在{0.05,0.1,0.25,0.5}的验证集上选择了一个学习率。 在这项任务中,添加bigram信息将使性能提高1 - 4%。 总体而言,我们的准确度略好于char-CNN,稍差于VDCNN。 请注意,我们可以通过使用更多的n-gram来稍微提高精度,例如,搜狗的性能上升到97.1%。 最后,图3(文中找不到图3 = =,说的应该是表1吧)表明我们的方法与Tang等人提出的方法相比是有竞争力的。
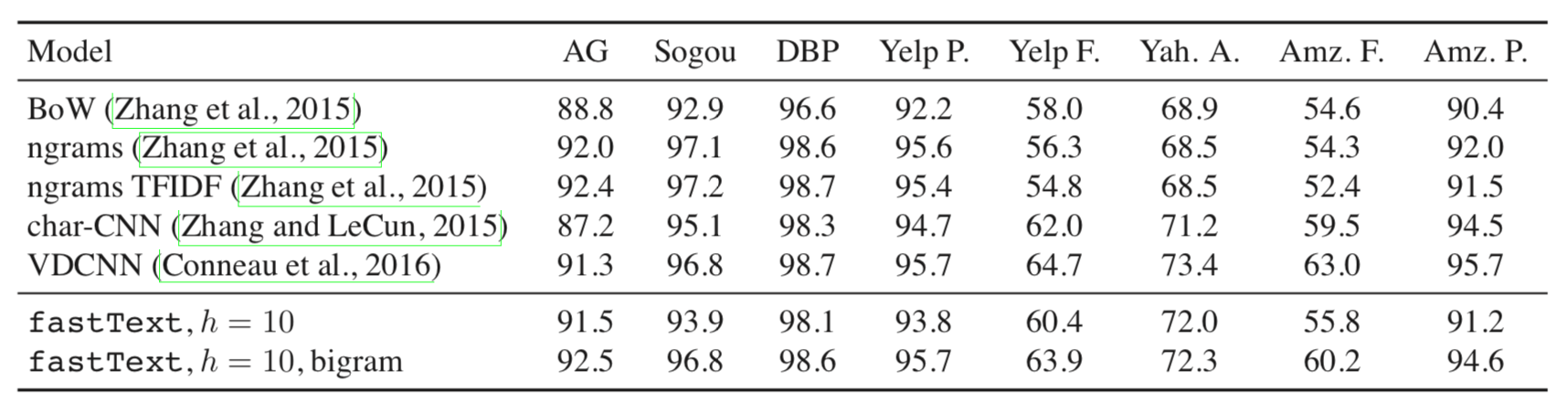
表1:情绪数据集的测试准确度[%]。 所有数据集都使用相同的参数运行FastText。 它有10个隐藏的单位,我们评估它有没有bigrams。 对于VDCNN和char-CNN,我们显示没有数据增加的最佳报告数字。

表3:与Tang等人的比较。在验证集上选择超参数。
我们调整验证集上的超参数,并观察使用多达5个导联的n-grams 达到最佳性能。 与Tang等人不同,fastText不使用预先训练的词嵌入,这可以解释1%的差异。
训练时间 char-CNN和VDCNN都使用NVIDIA Tesla K40 GPU进行培训,而我们的模型则使用20个线程在CPU上进行培训。 表2显示使用卷积的方法比fastText慢几个数量级。
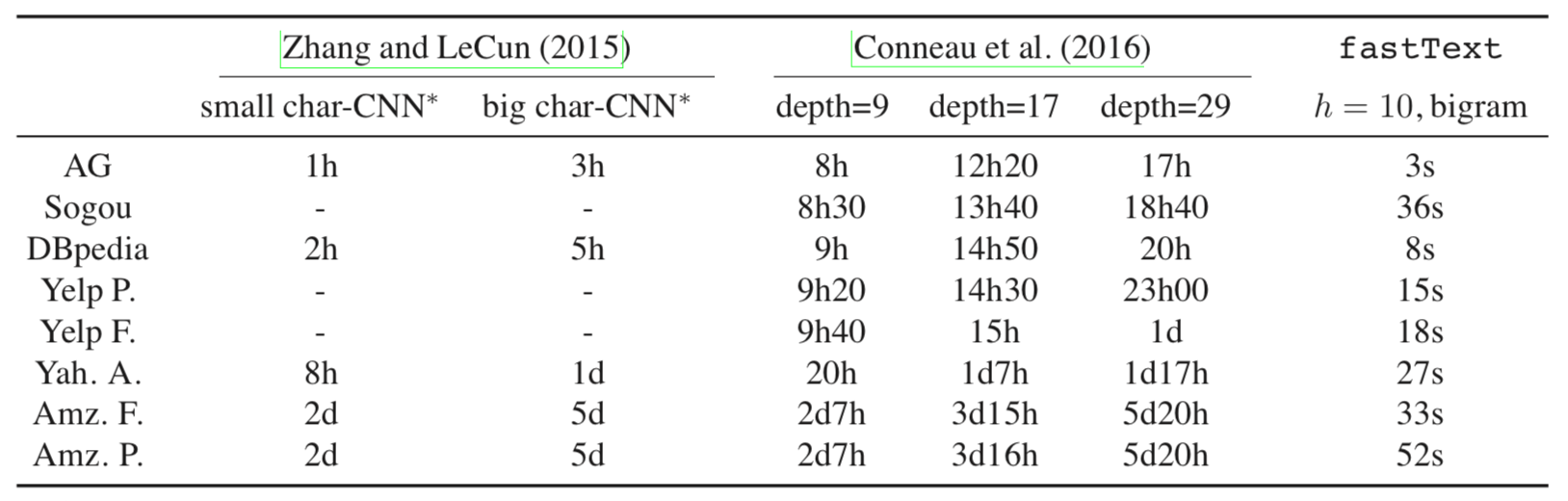
表2:与char-CNN和VDCNN相比,情绪分析数据集的训练时间。 我们报告整个培训时间,除了char-CNN,我们报告每个时间。
请注意,对于char-CNN,我们报告每个时期的时间,同时报告其他方法的整体训练时间。 虽然使用更新的CUDA实现的卷积可以使char-CNN的速度提高10倍,但fastText只需不到一分钟的时间就可以训练这些数据集。 与基于CNN的方法相比,我们的加速比随着数据集的大小而增加,至少达到15,000倍的加速。
标签预测
数据集和基线为了测试我们方法的可伸缩性,对YFCC100M数据集进行了进一步评估,该数据集由几乎100M的带有字幕,标题和标签的图像组成。我们专注于根据标题和标题预测标签(我们不使用图像)。我们删除少于100次的字词和标签,并将数据分成训练,验证和测试集。该训练集包含91,188,648个样本。验证有930,497个样本和测试集543,424个样本。词汇大小为297,141,并且有312,116个标签。我们将发布一个脚本来重新创建这个数据集,以便我们的数据可以被复制。
我们考虑预测最频繁标签的基于频率的基线。我们还将它与标签预测模型Tagspace进行了比较,标签预测模型与我们的标签预测模型相似,但基于Weston等人的Wsabie模型。虽然使用卷积描述了标签空间模型,但我们认为线性版本具有可比较的性能,更快。
结果和训练时间 表5给出了fastText和基线的比较。
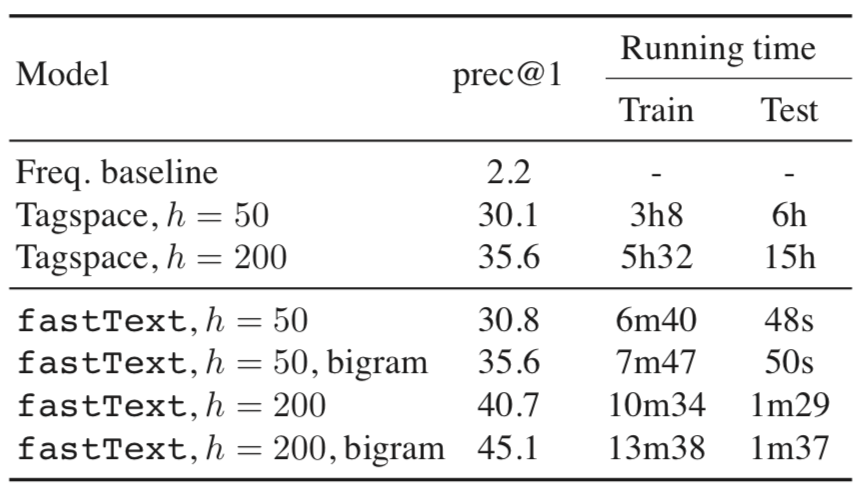
表5:YFCC100M上用于标记预测的测试集上的Prec @ 1。 我们还会报告训练时间和测试时间。 测试时间是单线程的报告,而两种模式的训练使用20个线程。
我们运行5个周期的fastText,并将它与Tagspace的两种尺寸的隐藏层(即50和200)进行比较。两种模型都实现了与隐藏层相似的性能,但增加了巨大值使我们在精度上有了显着提升。 在测试时间,Tagspace需要计算所有类别的分数,这使得它相对较慢,而当类别数量很多(此处超过300K)时,我们的快速推理会显着提高速度。 总体而言,获得质量更好的模型的速度要快一个数量级。 测试阶段的加速更加重要(600倍加速)。
表4显示了一些定性的例子。

表4:使用具有200个隐藏单元和两个bigrams的fastText获取的YFCC100M数据集验证集的示例。 我们展示了一些正确和不正确的标签预测。
FastText学习将标题中的单词与他们的主题标签相关联,例如“christmas”与“#christmas”。 它还捕捉单词之间的简单关系,如“snowfall”和“#snow”。 最后,使用bigrams还可以捕捉诸如“twin cities”和“#minneapolis”之类的关系。
讨论和结论
在这项工作中,我们开发了fastText,它扩展了word2vec来处理句子和文档分类。 与来自word2vec的无监督训练的单词向量不同,我们的单词特征可以平均在一起形成好的句子表示。 在几项任务中,我们获得的性能与最近提出的深度学习方法相媲美,同时观察到了大幅度的加速。 尽管深层神经网络在理论上比浅层模型具有更高的表征能力,但是如何分析简单的文本分类问题(如情感分析)是否正确评估它们并不明确。 我们将发布我们的代码,以便研究团体可以轻松构建我们的工作。
FastText词向量与word2vec对比
FastText= word2vec中 cbow + h-softmax的灵活使用
灵活体现在两个方面:
1. 模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是 分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用;
2. 模型的输入层:word2vec的输出层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容;
两者本质的不同,体现在h-softmax的使用:
Wordvec的目的是得到词向量,embedding层 到 input层的 共享权重矩阵 就是 词向量矩阵,输出层对应的 h-softmax 也会生成一系列的向量,但最终都被抛弃,不会使用。
fasttext则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)


