
- 1ViLBERT:视觉语言多模态预训练模型_视觉-语言多模态训练模型
- 2深度之眼Paper带读笔记NLP.11:FASTTEXT.Baseline.06_in this work, we explore ways to scale thesebaseli
- 3matlab accumarray_32个实用matlab编程技巧
- 4【科研新手指南2】「NLP+网安」相关顶级会议&期刊 投稿注意事项+会议等级+DDL+提交格式_ccs投稿须知文件
- 5spring-boog-测试打桩-Mockito_org.mockito.exceptions.base.mockitoexception: chec
- 6Git将当前分支暂存切换到其他分支_如何暂存修改切换分支git
- 7solidity实现智能合约教程(3)-空投合约
- 8上位机图像处理和嵌入式模块部署(qmacvisual寻找圆和寻找直线)
- 930天拿下Rust之错误处理
- 10基于springboot的在线招聘平台设计与实现 毕业设计开题报告_招聘app的设计与实现的选题背景怎么写
LayoutLM——文本与布局的预训练用于文档图像理解
赞
踩
摘要: 预训练技术近年来在多种NPL任务中取得了广泛的成功。尽管广泛的NPL应用的预训练模型,其大多聚焦于文本级别的操作,而忽略了布局与风格信息,这对文档图像的理解至关重要。该篇论文提出了LayoutLM来联合建模扫描文档图像的文本与布局信息关系,这将有益于真实世界中大量的图像理解任务,如文档图像的信息提取。此外,可以利用图像特征合并文字的视觉信息到LayoutLM中。这是第一次在单独的文档级预训练结构将文字与布局联合学习。其在一些下游任务中达到了新的高水平结果,包括表格理解,收据理解,文档图像分类。代码与已经训练好的LayoutLM模型在https://github.com/microsoft/unilm/tree/master/layoutlm开源。
一、介绍
商业文档如图1,可能由数字化的产生,成为电子文件,或从手写或打印的纸张中被扫描。其格式多样,但信息经常由自然语言表述,并由纯文本,多列的布局,多种表格、图等以多种方式组成。布局与格式的多样性,低质量的扫描与模板结构的复杂性导致了商业文档理解任务的困难。
图1:不同布局与格式的商业文档扫描图像。
如今,人工提取数据耗时且昂贵,为了解决这个问题,文档AI模型与算法被设计出来以自动分类,提取并结构化信息。当代的文档AI方法通常基于计算机视觉角度或自然语言处理角度,或两者结合的的深度神经网络。早些方法聚焦于检测并分析文档的某个位置,例如表格区域。大多数先前的方法由两个限制:(1)依赖于一些人工标记的训练样本,然而没有充分探索使用大规模未标记的训练样本的可能性;(2)其取决于预训练的CV模型与NLP模型,但没有考虑文本与布局信息的联合训练。因此需要调查如何自监督的预训练文本与布局将有助于文档AI领域。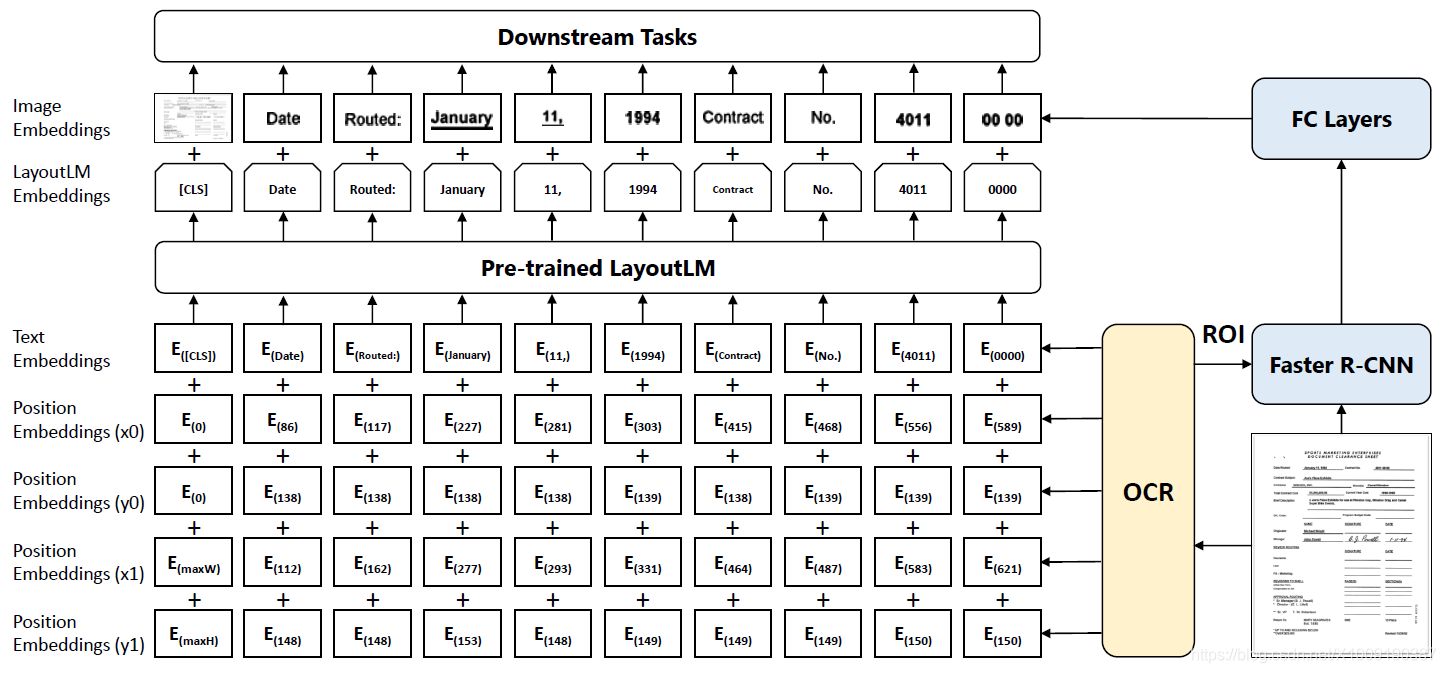
图2:LayoutLM的样例,其中2D的布局与图像嵌入向量整合到原始的BERT架构。LayoutLM嵌入向量和从Faster R-CNN得到的图像的嵌入向量一起为下游任务工作。
最后,本文提出的LayoutLM是对于文档图像理解任务简单但有效的预训练模型。受到BERT模型的启发,输入的文本信息主要由文本与位置嵌入向量代表,LayoutLM额外加入输入的嵌入向量的两项:(1)一个2D位置嵌入向量用于表示文档内的相对位置标记;(2)文档内的内的图像嵌入向量用于扫描标记。LayoutLM的架构如图2,加入两个嵌入向量的原因是2D位置嵌入向量捕捉文档内的符号之间的关系,同时图像嵌入向量捕捉一些表现特征,例如字的方向,类型与颜色。此外LayoutLM加入多任务学习目标,包括遮罩视觉语言模型【Masked Visual-Language Model,MVLM】损失与多标签文档分类【Multi-label Document Classification,MDC】损失,这会更加驱动文本与布局的结合预训练。该工作聚焦于基于扫描文档图像的文档预训练,数字化生成的文档较为简单因为其不需要OCR,因此本论文不考虑。本论文的贡献总结下:
——第一次在一个简单的结构中预训练扫描文档图像的文本与布局信息;
——LayoutLM使用标记视觉语言模型与多标签文档分类作为训练目标,显著的胜过文档图像理解任务中其他高水准的预训练模型。
——代码与已经训练好的LayoutLM模型https://github.com/microsoft/unilm/tree/master/layoutlm开源,以用于更多下游任务。
二、LayoutLM
简要回顾BERT模型,并介绍如何延申到在LayoutLM结构建模联合文本与布局的信息。
2.1 BERT模型
BERT模型是基于注意力的双向语言建模方法。其架构是基础的多层双向编码转换器。详细的,给出一个序列的符号,输入嵌入向量通过相关的词语嵌入向量,位置嵌入向量以及语义嵌入向量求和得到。然后,输入嵌入向量通过多层双向转换器以基于自适应注意力机制生成状态化的表现。
BERT结构有预训练与微调两步。在与训练期间,模型使用两个目标学习语言表现:遮罩语言模型【Masked Language Modeling,MLM】与后续语句预测【Next Sentence Prediction,NSP】,其中MLM随机遮挡输入符号,目的是恢复被遮盖的符号,以及NSP是一个二分类任务,其将一对语句作为输入,判断其是否为连贯的语句。在微调中,特定任务的数据集用于以端到端的方式更新所有的参数。BERT模型在NLP任务已经广泛的应用。
2.2 LayoutLM模型
高水准的BERT类模型在所有类型的输入中通常只利用文本信息。而视觉信息丰富的文档有更多的信息可以被编码到预训练模型中。因此提出使用文档布局中丰富信息,并使之与输入本文对齐。基本来讲有两种特征可以显著的改善视觉信息丰富的文档的语言表现,分别是:
文档布局信息: 文字的对应位置有丰富的语义表现,例如表格。基于转换器中自注意力机制,将2D位置特征嵌入到语言表现中将会更好的对齐带有语义表现的布局信息。
视觉信息:在文档中,相比于文字信息,视觉信息是另一个至关重要的特征,例如文档的一些视觉标志表示文档语义的优先级。对于文档级别的视觉特征,整张图象可以表明文档布局,其是一个文档图像分类的基本特征。对于文字级别的视觉特征,文字风格是语句标记任务的重要标志。因此,传统文字表现联结图像特征能够带来文档中更丰富的语义表现。
2.3 模型架构
以BERT为主干,增加两种类型的输入嵌入向量:一个2D位置嵌入向量与一个输入图像嵌入向量。
2D位置嵌入向量: 2D位置嵌入向量旨在建模文档的相对空间位置。将文档考虑成坐标系统,则边界块可以清晰的由(x0,y0,x1,y1)
(x0,y0,x1,y1)定义,在模型中使用两个嵌入表加入四个位置嵌入向量层,嵌入层表现为有着相同嵌入表的相同维度,即在嵌入表XX中访问位置嵌入向量(x0,y0)(x0,y0),嵌入表Y
Y同理。
图像嵌入向量: 为了使用文档的图像特征并将图像特征与文字对齐,在模型中添加一个图像嵌入向量层以在语言表现中代表图像特征。更详细的,使用OCR结果中每个文字的边界块,将图像分为若干块,其与文字有一对一的相关关系。使用这些图像块从Faster R-CNN模型中得到图像区域特征作为图像符号的嵌入向量。对于公共语言规范【CLS】的符号,也使用Faster R-CNN模型将整个扫描文档图像作为关注区域【Region of Interest,ROI】生成嵌入向量,以改善需要公共语言规范符号表现的后续任务。
2.4 LayoutLM的预训练
任务1:遮罩视觉语言模型 :使用MVLM通过2D位置插入向量与文字插入向量的线索学习语言表现。在预训练中随机遮盖输入符号,但保持2D位置插入向量与其他文字插入向量,之后模型被训练通过给出的状态预测遮盖的符号。由此,LayoutLM模型理解了语言状态,并使用相应的2D位置信息在视觉与语言形态之间的建立关系。
任务2:多标签文档分类 :对于给出的扫描文档集合,使用文档标签监督与训练过程,使模型从不同的域收集知识,生成更佳的文档水平的表现。MDC损失需要每个文档图像的标签,对于大型数据集可能不存在,因此再预训练是可选的,并且在未来预训练更大的模型时可能不使用。
2.5 LayoutLM的微调
预训练LayoutLM模型在三个文档图像理解任务上微调,包括表格理解任务,收据理解任务与文档图像分类任务。对于表格与收据理解任务,LayoutLM为每个符号预测{B, I, E, S, O}标签并使用连续的标记检测数据集中的每种样本。对于文档图像分类任务,LayoutLM使用公共语言规范【CLS】的符号表现预测分类标签。
三、实验
3.1 预训练数据集
IIT-CDIP测试集1.0,包含6M文档,并带有超过11M标记文档图像,每个文档有相应的文本与元数据,并保存在XML文件中。
3.2 微调数据集
FUNSD数据集: 用于在噪声的扫描文档中评估表格理解,包括199张真实、注释完整的扫描表格,并带有9707个语义单位与31485个文字。
SROIR数据集: 用于评估收据信息提取,包含626张收据用于训练与347张收据用于测试。
RVL-CDIP数据集: 包含400K灰度图,分为16类,其中320K训练,40K验证图像,40K测试图像。
3.3 文档预处理
使用开源OCR引擎Tesseract较容易的识别并获取2D位置,以hOCR格式存储,这是一种使用层次表示定义单个文档图像的OCR结果的清晰的标准规范格式。
3.4 模型预训练
使用预训练的BERT基础模型初始化LayoutLM模型。特别的,这些基础模型有着相同的架构:带有768个隐藏规格的12层的转换层,包含113M参数的12个注意力单位,并选择15%的输入符号用于预测。在80%的时间内将标记的符号替换为遮罩,10%的时间内替换为随机符号,以及10%的时间不改变。然后,模型将会使用交叉熵预测相应的符号。
此外,加入2D位置嵌入向量,考虑到文档的布局会随着纸张的尺寸变化,将真实的坐标衡量为虚拟坐标,其值为0~100。此外,使用ResNet101模型作为Faster R-CNN模型的主干网络,并在Visual Genome数据集上预训练。
使用8块NVIDIA特斯拉V100 32GB GPUs与80的批尺寸训练。使用Adam优化器,初始化学习率为5e-5并线性衰减。基础模型在11M数据集中每轮花费80个小时完成,而大型模型花费近170个小时。
3.5 特定任务微调
LayoutLM模型在三个不同的图像理解任务中评估,使用典型的微雕策略,并在特定的数据集以端到端的方式更新全部参数。
3.6 结果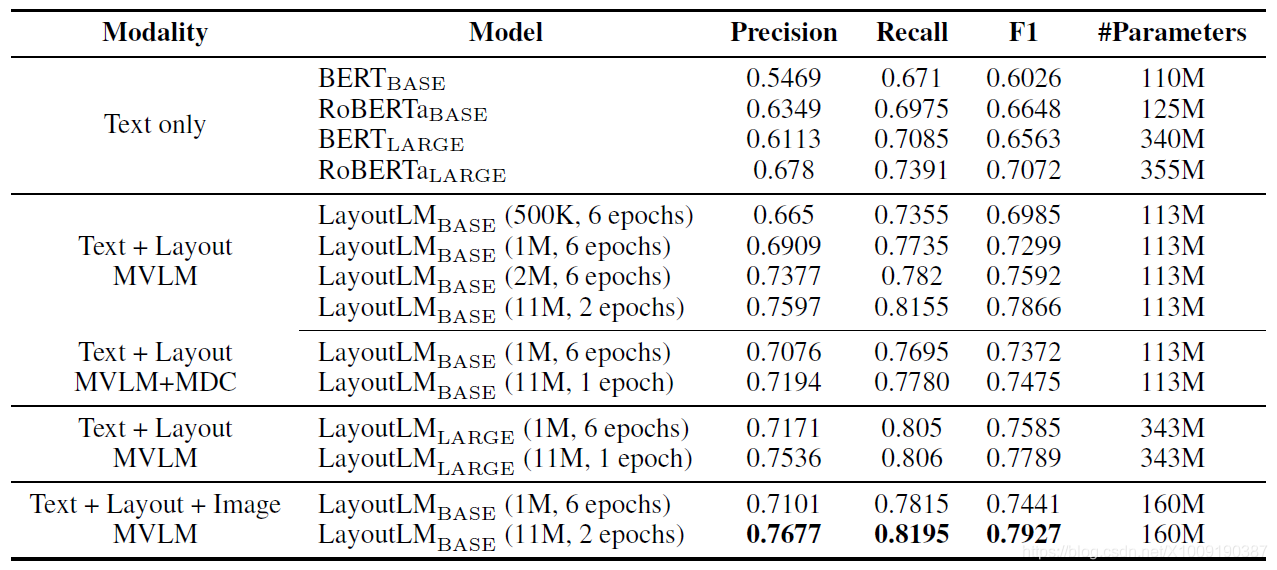
表1:在FUNSD数据集上模型精准度(准确率,召回率,综合评价1指标)
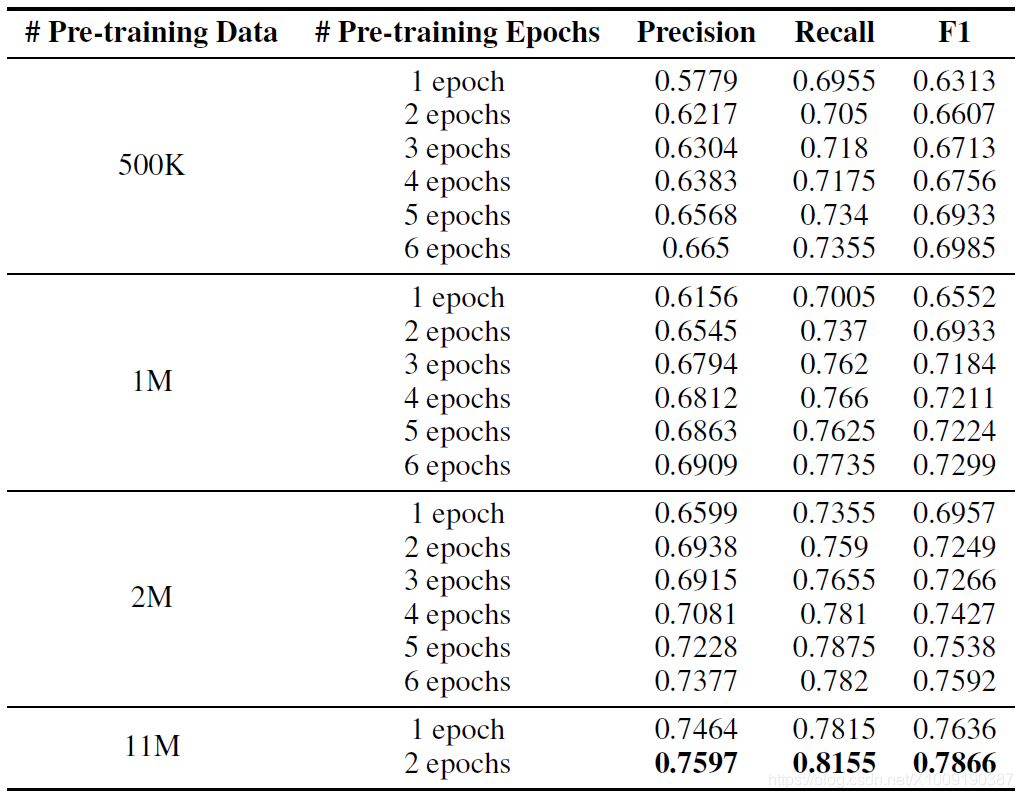
表2:在FUNSD数据集上基础LayoutLM(文本+布局,MVLM)不同的数据与迭代轮数的精准度

表3:基础与大型LayoutLM(文本+布局,MVLM)使用不同的初始化方法
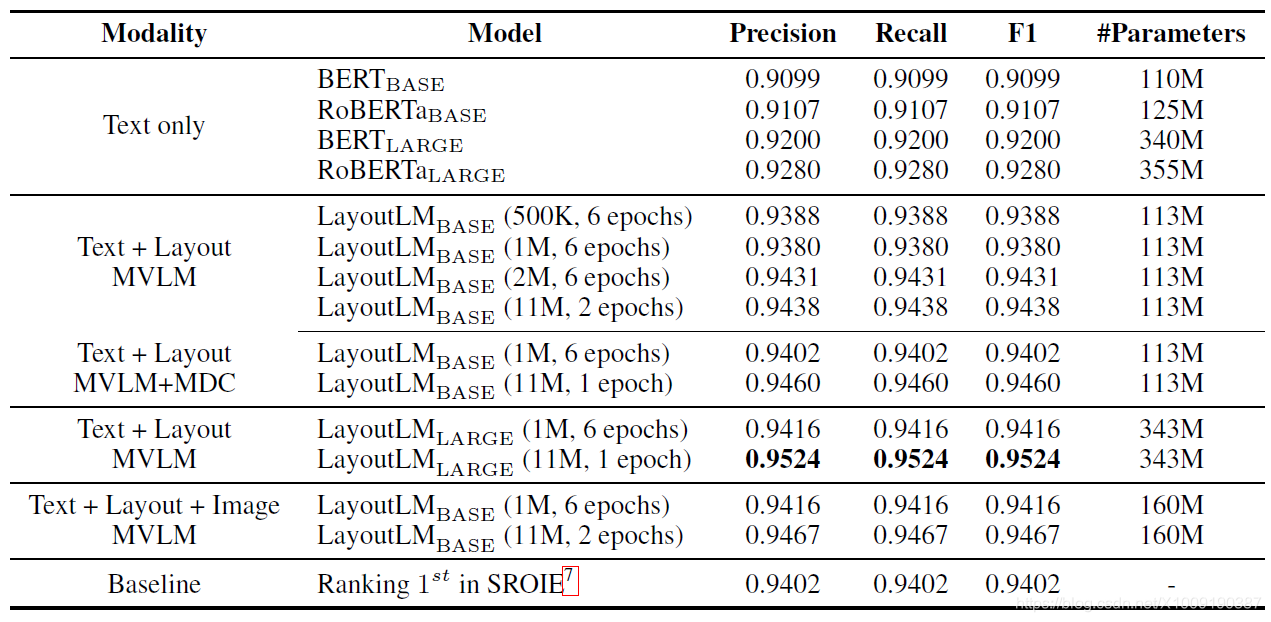
表4:在SROIE数据集上模型精准度(准确率,召回率,综合评价1指标)
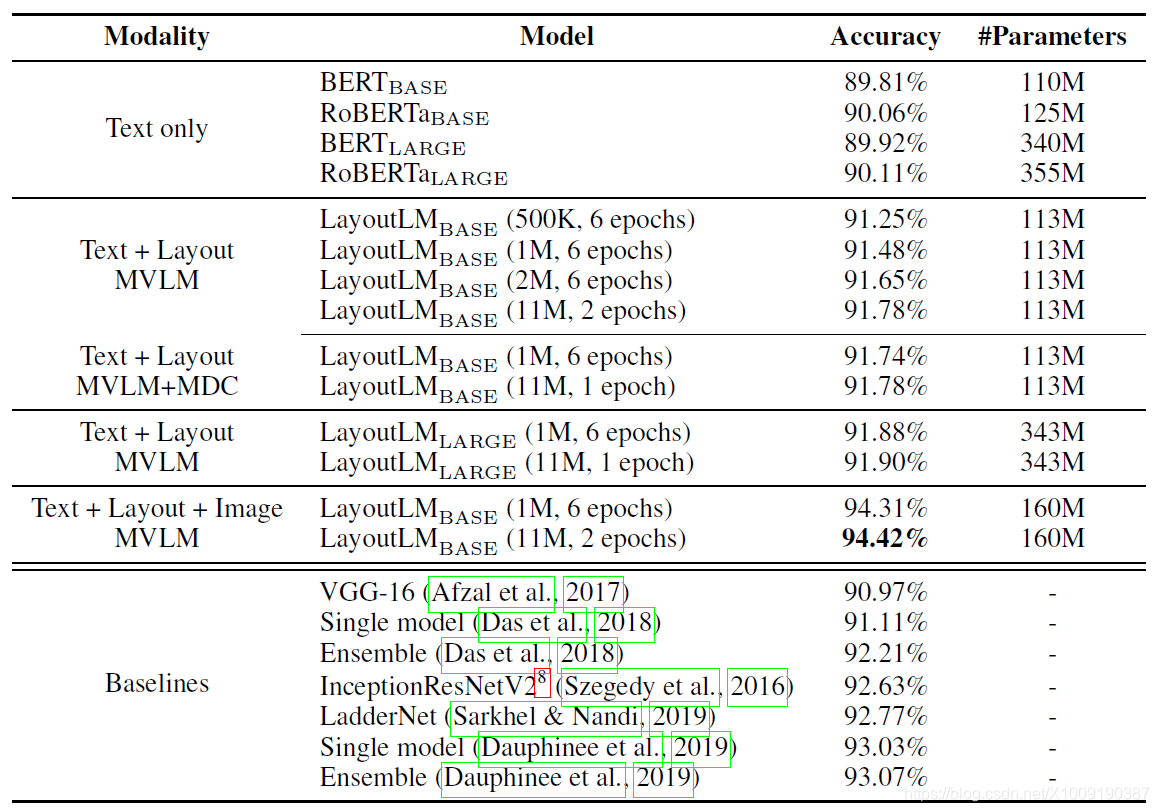
表5:在RVL-CDIP数据集上分类精准度
四、相关工作
文档分析识别【Document Analysis and Recognition,DAR】的研究可以追溯到20世纪90年代。主流方法包括基于规则的方法,传统机器学习方法与深度学习方法。
4.1 基于规则的方法
4.2 机器学习方法
4.3 深度学习方法
五、结论与未来的工作

