- 1【深度学习】基于Python Qt的口罩检测与报警系统_python实现检测后报警
- 2【添加公众号/订阅号】CSDN官方指定推广功能_csdn文章能否插入公众号链接
- 3Android Studio下项目构建的Gradle配置及打包应用变体
- 4深度学习在遥感图像处理中的应用
- 5html5 js获取设备信息,js怎么获取电脑硬件信息
- 6自定义Dialog弹窗_el-form-item内自定义选择弹框组件
- 7工具系列:TimeGPT_(2)使用外生变量时间序列预测_timegpt 源码
- 8使用frp进行内网穿透,让本地HTTP网站公开访问_frp toml
- 9「ds」Monolithic && Microkernel区别_servers. microkernel
- 10阿里云物联网物模型TSL字段详细说明
ASR(自动语音识别)任务中的LLM(大语言模型)_语音 识别 大模型
赞
踩
一、LLM大语言模型的特点
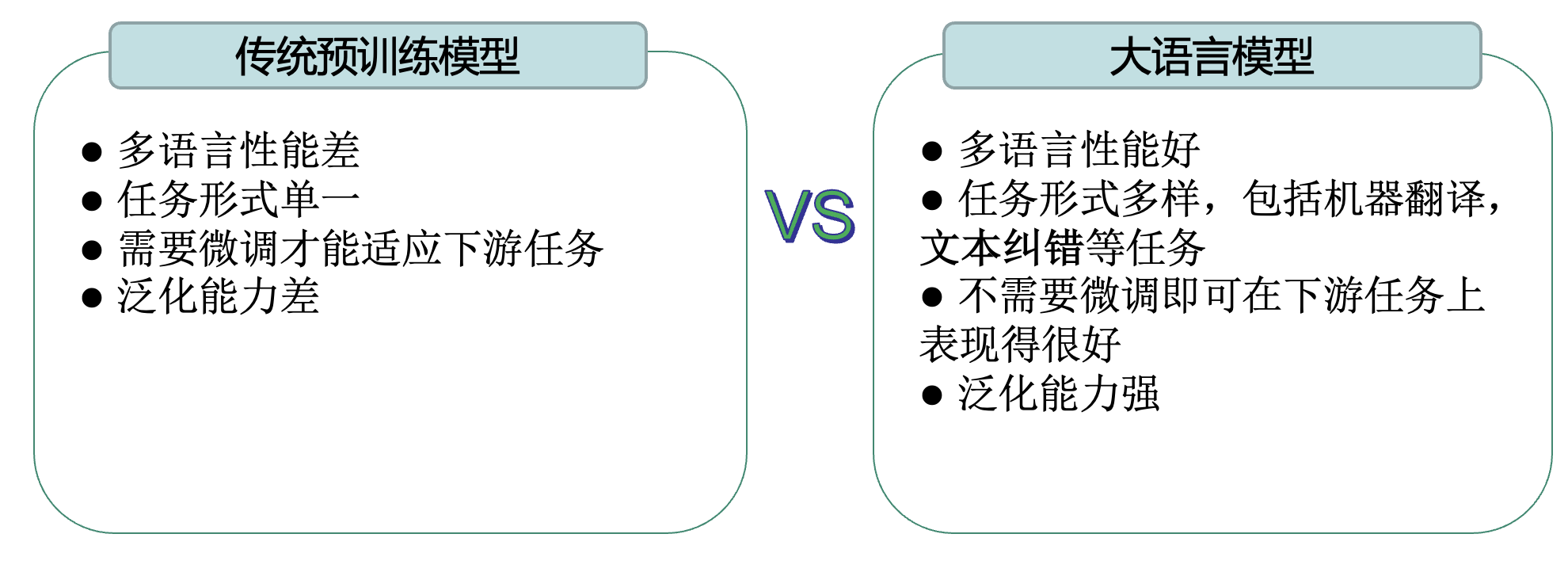
二、大语言模型在ASR任务中的应用
浅度融合
浅层融合指的是LLM本身并没有和音频信息进行直接计算。其仅对ASR模型输出的文本结果进行重打分或者质量评估。
深度融合
LLM与ASR模型进行深度结合,统一语音和文本的编码空间或者直接利用ASR编码器的隐状态参与计算,利用大语言模型的能力得到更好的解码结果。
三、浅度融合
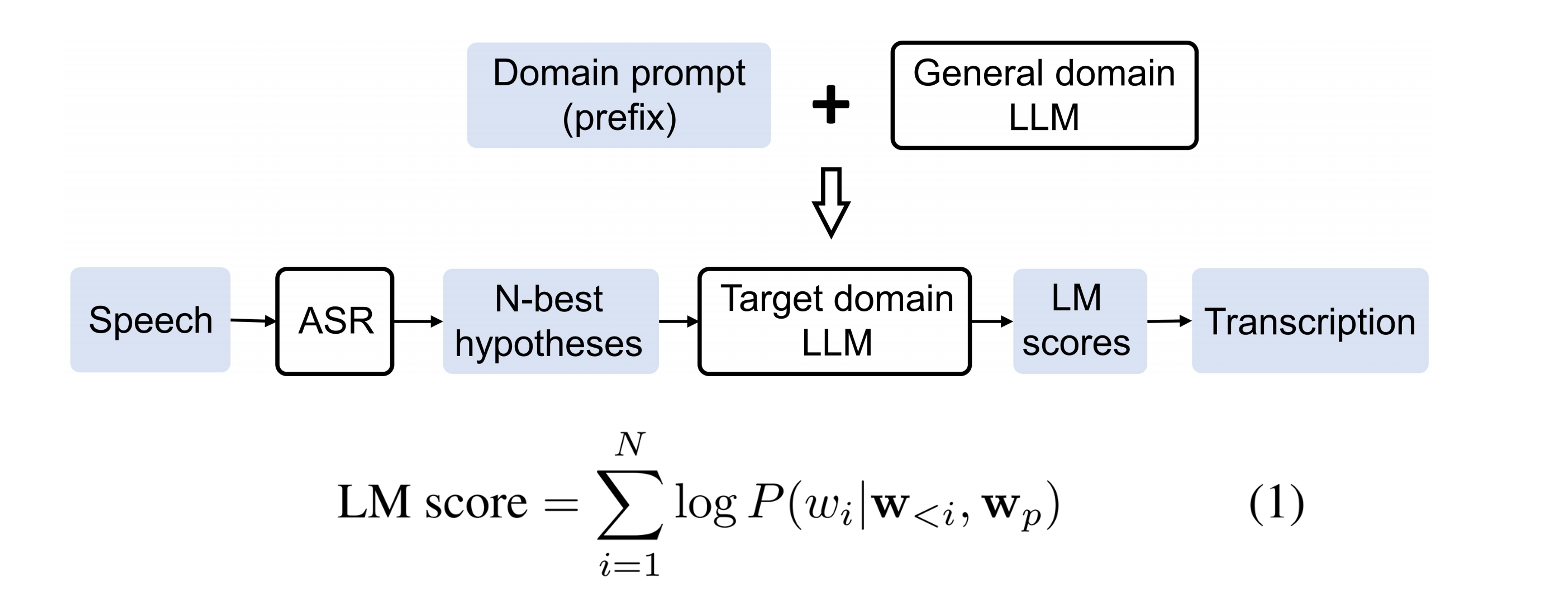
1、Large-scale Language Model Rescoring on Long-Form Data
利用能力更加强大的LLM为ASR模型的推理结果进行质量评分

2、Prompting Large Language Models For Zero-Shot Domain Adaptation in Speech Recognition
利用能力更加强大的LLM为语言模型的输出进行重打分
四、深度融合
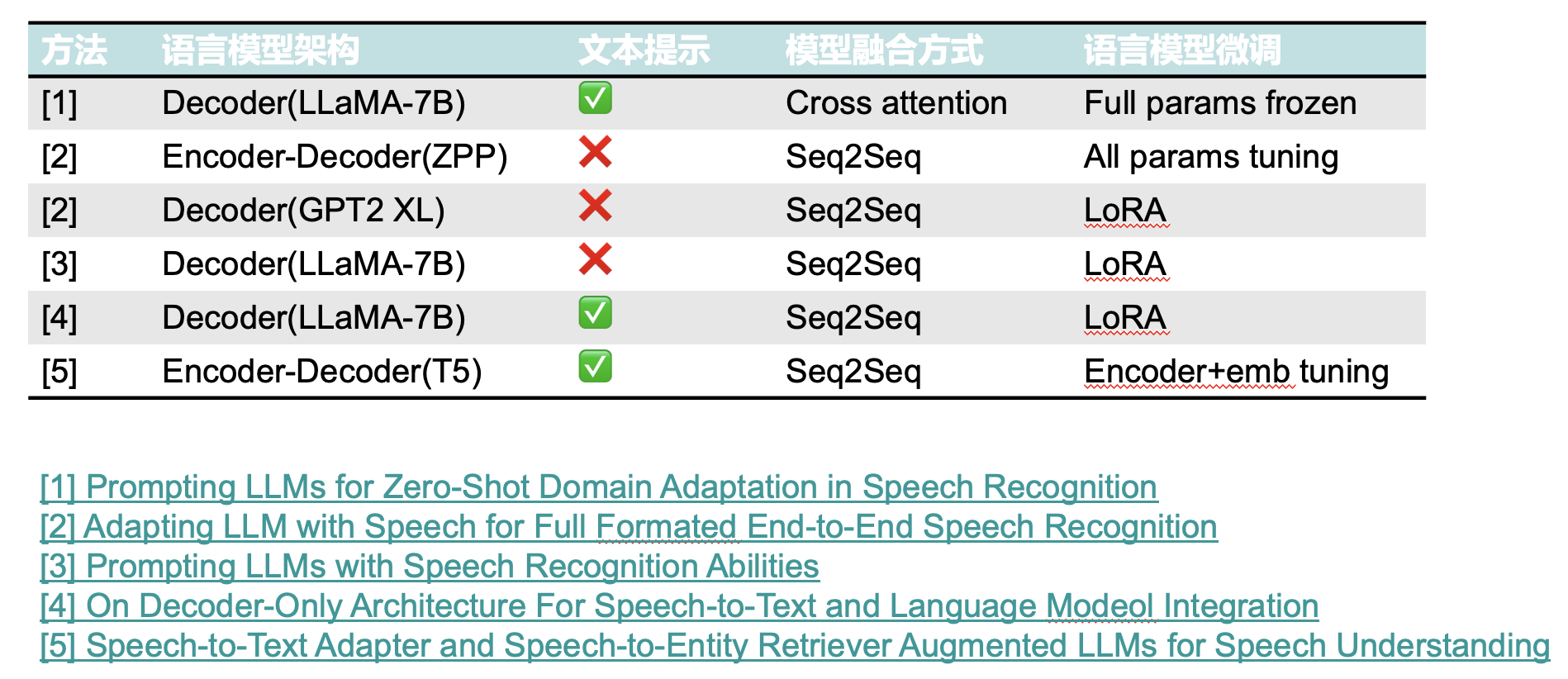
1、Prompting Large Language Models For Zero-Shot Domain Adaptation in Speech Recognition
使用语音编码器编码和提示文本的信息输入到大语言模型中预测下一个token

编码器:使用HuBERT处理语音序列,并使用卷积网络对其进行下采样;
解码器:使用LLaMA作为解码器并融入Gated-XATT-FFN;
Cross-attention:使用编码器的输出作为key、value,解码器的domain prompt和历史输出作为query计算注意力,注意力使用Gated cross attention。
在训练时,保持LLaMA的参数固定,其他模块参数更新。
2、Adapting LLM with Speech for Full Formatted End-to-End Speech Recognition
使用语音编码器编码的信息输入到大语言模型中预测下一个token
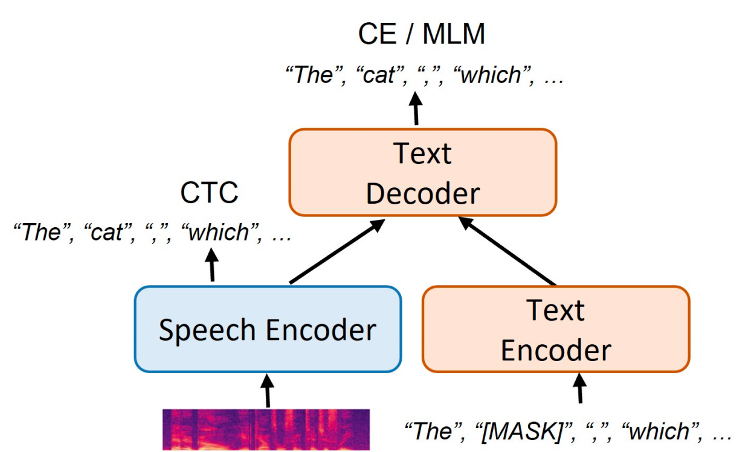
Text Encoder:用于在训练阶段提供更多的文本数据使解码器可以更好地被训练,在推理阶段不再被使用;
Speech Encoder:用于编码语音并使用CTC进行解码获得对应的token;
Text Decoder:在训练时对Text Encoder计算MLM损失,对Speech Encoder计算CE损失,用来预测下一个token。在推理时对Speech Encoder的输出进行修正。

Speech Encoder:用于编码语音信息;
LM:对Speech Encoder下采样之后的输出进行下一个token预测。
3、Prompting Large Language Models with Speech Recognition Abilities
使用语音编码器编码的信息输入到大语言模型中预测下一个token

Encoder:基于Conformer的声学编码器,最后使用n个帧进行堆叠投影,得到和LLaMA相同的维度;
Decoder:基于LLaMA 7B的解码器结构;
在训练时,LLaMA使用了基于LoRA的微调方法。
4、On Decoder-Only Architecture For Speech-to-Text and Large Language Model Integration
使用语音编码器编码和提示文本的信息输入到大语言模型中预测下一个token
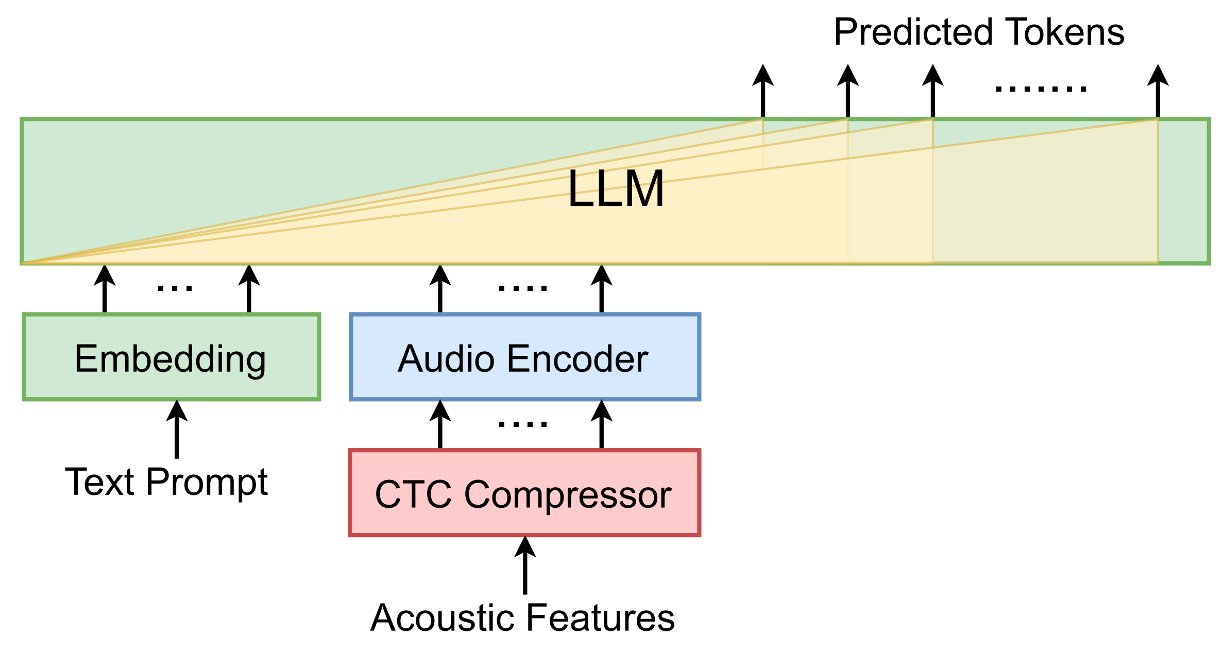
LLM:LLaMA 7B
CTC Compressor:通过过滤语音空白匹配标签序列文本的长度;
Audio Encoder:对CTC过滤后的语音信号进行编码;
Text Prompt:手工设计的提示词,为了达到instruct tuning的效果,本文在训练时设计了多种提示词;
为了稳定训练,在训练时第一阶段训练CTC Compressor,对LLM进行冻结;第二阶段使用LoRA对LLM进行微调。
5、Speech-to-Text Adapter and Speech-to-Entity Retriever Augmented LLMs for Speech Understanding
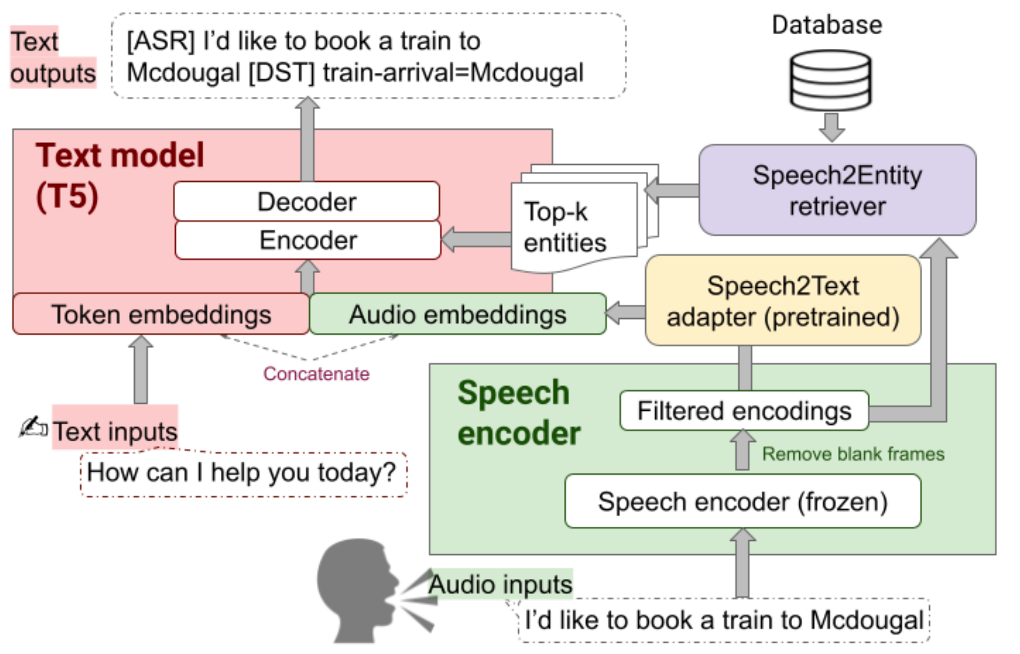
Speech2Text adapter:由一些自注意力子层组成,主要作用是将CTC过滤后的张量转换为可由LLM模型处理的张量。在训练期间,其他部分保持不动,仅训练此部分从而得到一个speech2text性能较好的适配器。
Speech2Entity retriever:根据过滤后的语音表征从数据库中查找与该段语音相关的topk个实体。
T5 Encoder输入:由三部分组成,分别是提示文本表征,输入语音表征以及检索到的topk实体文本表征。Topk实体会被添加到到提示文本输入前,从而提高T5模型语音识别实体的准确率。
五、深度学习方法对比