
- 1Debian 安装Nvidia官方显卡驱动
- 2leetcode561-Array Partition I
- 3智能客服--大厂对话系统实践 总结_智能客服 意图识别 槽位填充
- 4你需要跟踪分析产品知识库的哪些关键数据_知识库中通过哪些点可以提现数据
- 5python进行中文文本聚类实例(TFIDF计算、词袋构建)_中文文本聚类分析实例
- 601_推荐系统简介
- 7[IOS Metal] 运行错误 IOAF code 怎么办?_ioaf code 11
- 82020-12-07_english bruce lin博客
- 9商业开源MES+源码+可拖拽式数据大屏_拖拽开源mes系统
- 10python+appium+夜神模拟器刷快手极速版金币套现,帮你赚够早餐钱_用模拟器刷快手金币
知识图谱抽取LLM_llm提取
赞
踩
背景
基于chatglm构建agnet:chatglm实现Agent控制 - 知乎
向量检索增强LLM:向量检索增强chatglm生成 - 知乎
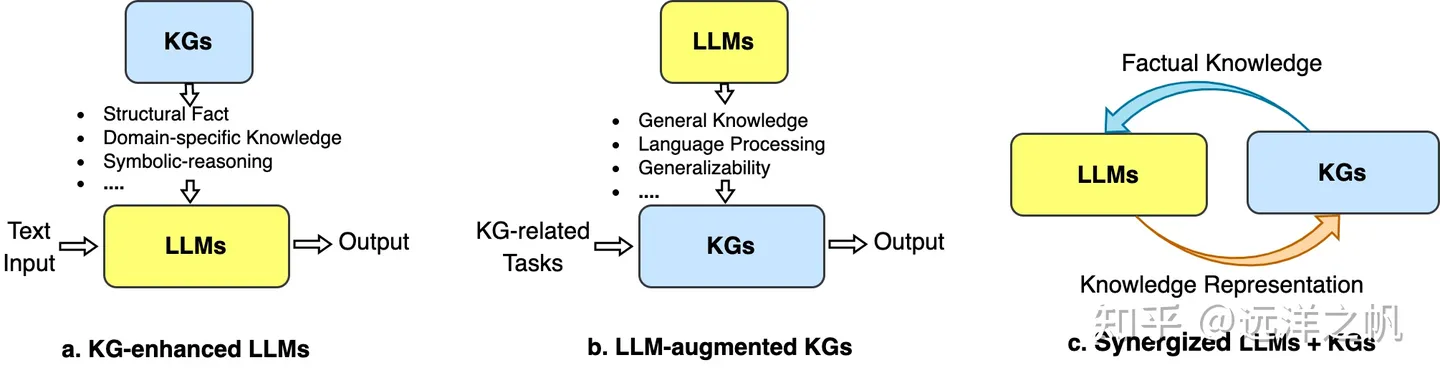
大型语言模型(LLM)在各种应用中取得了显着的成功和普遍性。 然而,他们常常无法捕捉和获取事实知识。 知识图(KG)是显式存储丰富事实知识的结构化数据模型。 然而,知识图谱很难构建,并且知识图谱中的现有方法不足以处理现实世界知识图谱的不完整和动态变化的性质。 因此,自然而然地将LLM和KG结合在一起,同时发挥各自的优势。
尽管 LLM 已有许多成功应用,但由于缺乏事实知识,它们还是备受诟病。具体来说,LLM 会记忆训练语料库中包含的事实和知识。但是,进一步的研究表明,LLM 无法回忆出事实,而且往往还会出现幻觉问题,即生成具有错误事实的表述。举个例子,如果向 LLM 提问:「爱因斯坦在什么时候发现了引力?」它可能会说:「爱因斯坦在 1687 年发现了引力。」但事实上,提出引力理论的人是艾萨克・牛顿。这种问题会严重损害 LLM 的可信度。
LLM 是黑箱模型,缺乏可解释性,因此备受批评。LLM 通过参数隐含地表示知识。因此,我们难以解释和验证 LLM 获得的知识。此外,LLM 是通过概率模型执行推理,而这是一个非决断性的过程。对于 LLM 用以得出预测结果和决策的具体模式和功能,人类难以直接获得详情和解释。
为了解决上述问题,一个潜在的解决方案是将知识图谱(KG)整合进 LLM 中。知识图谱能以三元组的形式存储巨量事实,即 (头实体、关系、尾实体),因此知识图谱是一种结构化和决断性的知识表征形式,例子包括 Wikidata、YAGO 和 NELL。

统一 LLM 和 KG 三个通用框架:1)KG增强型LLM,2)LLM增强型KG,以及3)协同LLM + KG。

LLM与知识图谱协同的一般框架,其中包含四层:数据、协同模型、技术、应用.
这篇文章会介绍如何构建一个抽取知识能力强的LLM模型,包括了如何对现有LLM做pretrain、sft构建知识图谱抽取LLM,以及如何把知识图谱LLM封装成tool给LLM Agent使用。后面文章会有专门文章去介绍如何把构建的知识图谱来增强LLM模型,提升模型的检索和意图理解能力,利用知识图谱增强LLM模型的生成能力,降低幻写的概率。
技术点介绍
这篇文章知识抽取模型选的是“智析”模型,这个模型是基于llama 13b利用自己的数据+公开数据对模型做了pretrain,然后在pretrain model之上用指令语料做了lora微调。

具备信息抽取能力,比如命名实体识别(NER)、事件抽取(EE)、关系抽取(RE);提供了prompt便于使用,也可以尝试使用自己的Prompt。
下图展示了训练的整个流程和数据集构造。整个训练过程分为两个阶段:
(1)全量预训练阶段。该阶段的目的是增强模型的中文能力和知识储备。
(2)使用LoRA的指令微调阶段。该阶段让模型能够理解人类的指令并输出合适的内容。

Pretrain model在5500K条中文样本、1500K条英文样本、900K条代码样本进行预训练。我们使用了transformers的trainer搭配Deepspeed ZeRO3(实测使用ZeRO2在多机多卡场景的速度较慢),在3个Node(每个Node上为8张32GB V100卡)进行多机多卡训练。
sft训练构建了指令数据集:对于信息抽取(IE)数据集,英文部分,使用CoNLL ACE CASIS等开源的IE数据集,构造相应的英文指令数据集。中文部分:使用了开源的数据集如DuEE、PEOPLE DAILY、DuIE等,还采用了自己构造的KG2Instruction,构造相应的中文指令数据集。具体来说,KG2Instruction(InstructIE)是一个在中文维基百科和维基数据上通过远程监督获得的中文信息抽取数据集,涵盖广泛的领域以满足真实抽取需求。在1个Node进行多卡训练。
| 数据集类型 | 条数 |
| COT(中英文) | 202,333 |
| 通用数据集(中英文) | 105,216 |
| 代码数据集(中英文) | 44,688 |
| 英文指令抽取数据集 | 537,429 |
| 中文指令抽取数据集 | 486,768 |
训练部分不是这篇文章介绍重点,对这部分感兴趣的同学可以参考:https://github.com/zjunlp/KnowLM/blob/main/README_ZH.md
接下来我们介绍如何把这个模型封装成tool供LLM agent来使用:1.环境部署 2.封装服务。
- #环境部署
- #下载智析项目代码
- git clone https://github.com/zjunlp/KnowLM.git
- cd KnowLM
- #下载zhixi fp16模型参数
- python tools/download.py --download_path ./zhixi-diff-fp16 --only_base --fp16
- #下载llama参数
- git clone https://huggingface.co/huggyllama/llama-13b
-
- #把zhixi模型参数和llama参数做数值合并得到实际可用的zhixi推理参数“./converted”这个地址换成llama参数地址
- python tools/weight_diff.py recover --path_raw ./converted --path_diff ./zhixi-diff-fp16 --path_tuned ./zhixi --is_fp16 True
-
- #指令微调后的lora参数下载
- python tools/download.py --download_path ../lora --only_lora
封装服务:
- #封装prompt模版
- import sys
- import json
- import fire
- import os.path as osp
- from typing import Union
- import torch
- import transformers
- from peft import PeftModel
- from transformers import GenerationConfig, LlamaForCausalLM, LlamaTokenizer
-
- class Prompter(object):
- __slots__ = ("template", "_verbose")
-
- def __init__(self, template_name: str = "", verbose: bool = False):
- self._verbose = verbose
- # file_name = osp.join("templates", f"{template_name}.json")
- file_name = template_name
- if not osp.exists(file_name):
- raise ValueError(f"Can't read {file_name}")
- with open(file_name) as fp:
- self.template = json.load(fp)
- if self._verbose:
- print(
- f"Using prompt template {template_name}: {self.template['description']}"
- )
-
- def generate_prompt(
- self,
- instruction: str,
- input: Union[None, str] = None,
- label: Union[None, str] = None,
- ) -> str:
- # returns the full prompt from instruction and optional input
- # if a label (=response, =output) is provided, it's also appended.
- if input:
- res = self.template["prompt_input"].format(
- instruction=instruction, input=input
- )
- else:
- res = self.template["prompt_no_input"].format(
- instruction=instruction
- )
- if label:
- res = f"{res}{label}"
- if self._verbose:
- print(res)
- return res
-
- def get_response(self, output: str) -> str:
- return output.split(self.template["response_split"])[1].strip()
- #封装tool
- from transformers import LlamaTokenizer, LlamaForCausalLM, GenerationConfig
- import torch
- from typing import Optional, Type
- from langchain.base_language import BaseLanguageModel
- from langchain.tools import BaseTool
- from langchain.callbacks.manager import (
- AsyncCallbackManagerForToolRun,
- CallbackManagerForToolRun,
- )
-
-
- class functional_Tool(BaseTool):
- name: str = ""
- description: str = ""
- url: str = ""
-
- def _call_func(self, query):
- raise NotImplementedError("subclass needs to overwrite this method")
-
- def _run(
- self,
- query: str,
- run_manager: Optional[CallbackManagerForToolRun] = None,
- ) -> str:
- return self._call_func(query)
-
- async def _arun(
- self,
- query: str,
- run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
- ) -> str:
- raise NotImplementedError("APITool does not support async")
-
- class LLM_KG_Generator(functional_Tool):
-
- model: LlamaForCausalLM #BaseLanguageModel
- tokenizer:LlamaTokenizer
- max_length:int
- prompter:Prompter
-
-
- def _call_func(self, query) -> str:
- #self.get_llm_chain()
- self.model.config.pad_token_id = self.tokenizer.pad_token_id = 0 # same as unk token id
- self.model.config.bos_token_id = self.tokenizer.bos_token_id = 1
- self.model.config.eos_token_id = self.tokenizer.eos_token_id = 2
-
- prompter = self.prompter
- prompt_temple = "我将给你个输入,请根据事件类型列表:['旅游行程'],论元角色列表:['旅游地点', '旅游时间', '旅游人员'],从输入中抽取出可能包含的事件,并以(事件触发词,事件类型,[(事件论元,论元角色)])的形式回答。"
- prompt = prompter.generate_prompt(prompt_temple,query)
- inputs = self.tokenizer(prompt, return_tensors="pt")
- input_ids = inputs["input_ids"].to("cuda")
- s = self.model.generate(input_ids,max_length=self.max_length)
- resp = self.tokenizer.decode(s[0])
- return resp
- #测试例子
- model = LlamaForCausalLM.from_pretrained(
- "/root/autodl-tmp/KnowLM/zhixi",
- load_in_8bit=False,
- torch_dtype=torch.float16,
- device_map="auto",
- )
- tokenizer = LlamaTokenizer.from_pretrained("/root/autodl-tmp/llm_model/llama-13b-hf")
- prompter = Prompter("../finetune/lora/templates/alpaca.json")
- KG_tool = LLM_KG_Generator(model = model,tokenizer = tokenizer,max_length =4096,prompter = prompter )
- input="John昨天在纽约的咖啡馆见到了他的朋友Merry。他们一起喝咖啡聊天,计划着下周去加利福尼亚(California)旅行。他们决定一起租车并预订酒店。他们先计划在下周一去圣弗朗西斯科参观旧金山大桥,下周三去洛杉矶拜访Merry的父亲威廉。"
- KG_tool.run(input)
-
- #和llm agent配合使用
- from langchain.agents import AgentExecutor
- from custom_search import DeepSearch
- from tool_set import *
- from intent_agent imprt IntentAgent
- from llm_model import ChatGLM
-
- #model_path换成自己的模型地址
- llm = ChatGLM(model_path="/root/autodl-tmp/ChatGLM2-6B/llm_model/models--THUDM--chatglm2-6b/snapshots/8eb45c842594b8473f291d0f94e7bbe86ffc67d8")
- llm.load_model()
- agent = IntentAgent(tools=tools, llm=llm)
-
- tools = [KG_tool]
-
- agent_exec = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True, max_iterations=1)
- agent_exec.run(input)

下面是测试例子生成的结果:

理论上讲是可以把上面的抽取的知识存储到各种图数据库,比如neo4j,gstore,TuGraph...在业务需要用到知识的时候在通过输入的检索词,从图数据库里面找到需要的相关知识,作为上下文或者通过知识来构建推理策略来供LLM模型生成最后答案。
小结
1.介绍了LLM和KG结合的三种模式:LLM增强KG抽取和构建知识图谱能力,KG增强LLM检索生成推理能力,KG和LLM协同
2.介绍“智析”项目来讲解了了LLM增强KG抽取模型,构建模型需要的两个流程:pretrain、sft,以及pretrain需要的数据和sft需要指令集构建
3.介绍了如何把"智析"封装成tool成为LLM agent的工具构建应用生态
4.理论讲知识构建过程比较耗费时间,是可以提前构建好,在需要使用知识的时候对知识图谱检索召回需要知识,构建各种应用场景,当然在语意理解时候也可以即时对用户输入构建知识提高意图理解能力
项目代码:https://github.com/liangwq/Chatglm_lora_multi-gpu/tree/main/APP_example/chatglm_agent

