
- 1【深度学习】李宏毅2021/2022春深度学习课程笔记 - Generative Adversarial Network 生成式对抗网络(GAN)
- 2使用NLTK进行自然语言处理:英文和中文示例_如何利用nltk处理中文
- 3没有USB线连接PC的情况下,通过WIFI ADB的方式查看LOG信息_adb logcat 不插usb线抓离线
- 4LINUX升级glibc失败后的补救_libc.2.12 升级失败
- 5Unity 工具类 之 简单网络下载管理类 UnityWebRequestManager 实现_unity webrequest netmgr
- 6李宏毅机器学习——对抗生成网络(GAN)_李宏毅 gan
- 7【边缘端环境配置】英伟达Jetson系列安装pytorch/tensorflow/ml/tensorrt环境(docker一键拉取)_jetson docker算法部署
- 8echarts tooltip属性_echarts地图tooltip属性
- 9基于宝塔搭建nginx负载均衡服务器_宝塔session拓展
- 10Pytorch实用教程:Pytorch中enumerate(test_loader, start=0)的解释
得物AI平台-KubeAI推理训练引擎设计和实践_ai推理引擎
赞
踩
1.KubeAI介绍
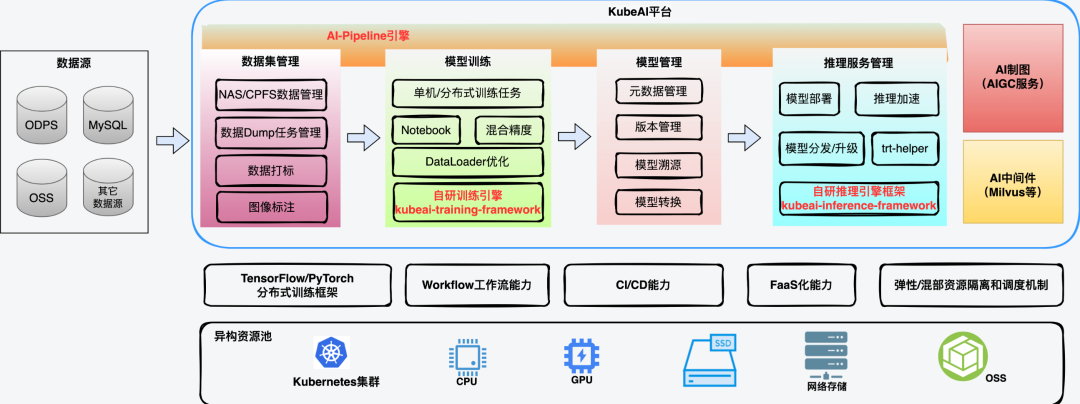
KubeAI是得物AI平台,是我们在容器化过程中,逐步收集和挖掘公司各业务域在AI模型研究和生产迭代过程中的需求,逐步建设而成的一个云原生AI平台。KubeAI以模型为主线提供了从模型开发,到模型训练,再到推理(模型)服务管理,以及模型版本持续迭代的整个生命周期内的解决方案。
在数据方面,KubeAI提供基于cvat的标注工具,与数据处理及模型训练流程打通,助力线上模型快速迭代;提供任务/Pipeline编排功能,对接ODPS/NAS/CPFS/OSS数据源,为用户提供一站式AI工作站。平台自研推理引擎助力业务在提高模型服务性能的同时还能控制成本;自研训练引擎提高了模型训练任务吞吐量,缩短了模型的训练时长,帮助模型开发者加速模型迭代。
此外,随着AIGC的火热发展,我们经过调研公司内部AI辅助生产相关需求,上线了AI制图功能,为得物海报、营销活动、设计师团队等业务场景提供了基础能力和通用AI制图能力。
此前,我们通过一文读懂得物云原生AI平台-KubeAI的落地实践过程一文,向大家介绍了KubeAI的建设和在业务中的落地过程。本文,我们将重点介绍下KubeAI平台在推理、训练和模型迭代过程中的核心引擎能力实践经验。
2.AI推理引擎设计实现
2.1 推理服务现状及性能瓶颈分析
Python语言以其灵活轻盈的特点,以及其在神经网络训练与推理领域提供了丰富的库支持,在模型研究和开发领域被广泛使用,所以模型推理服务也主要以Python GPU推理为主。模型推理过程一般涉及预处理、模型推理、后处理过程,单体进程的方式下CPU前/后处理过程,与GPU推理过程需要串行,或者假并行的方式进行工作,大致流程如下图所示:
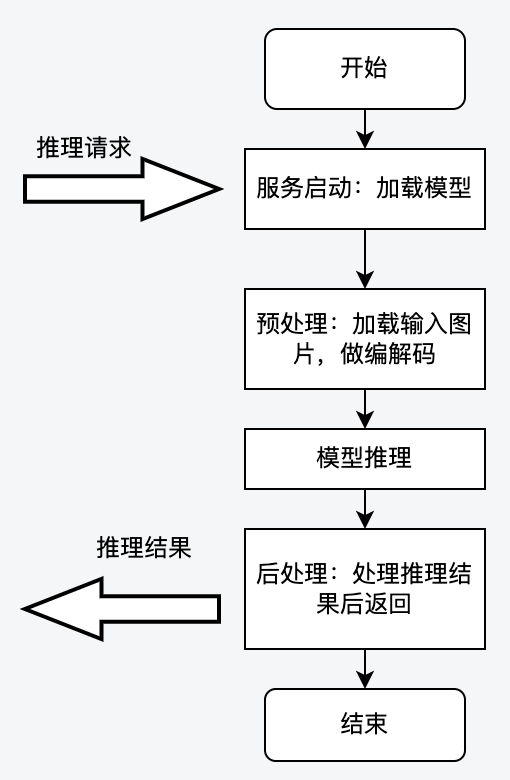
上述架构的优势是代码写起来比较通俗易懂,但在性能上有很大的弊端,所能承载的QPS比较低。通过在CV域的模型上进行压测,我们发现推理QPS很难达到5,深入分析发现造成这一问题的原因如下:
(1)单线程模式下,CPU逻辑与GPU逻辑相互等待,GPU Kernel函数调度不足,导致GPU使用率不高,无法充分提升服务QPS。这种情况下只能开启更多进程来提升QPS,但是更多进程会带来更大的GPU显存开销。
(2)多线程模式下,由于Python的GIL锁的原因,Python的多线程实际上是伪的多线程,并不是真正的并发执行,而是多个线程通过争抢GIL锁来执行,这种情况下GPU Kernel Launch线程不能得到充分的调度。此外,在Python推理服务中开启多线程反而会导致GPU Kernel Launch线程频繁被CPU的线程打断,所以GPU算力也会一直“萎靡不振”,持续低下。
以上问题使得 如果推理服务想要支撑更多的流量,只能做横向的增加服务实例数,伴随着成本的上涨。
2.2 自研推理服务统一框架kubeai-inference-framework
针对以上问题,KubeAI的解决方案是把CPU逻辑与GPU逻辑分离在两个不同的进程中:CPU进程主要负责图片的前处理与后处理,GPU进程则主要负责执行CUDA Kernel 函数,即模型推理。
为了方便模型开发者更快速地接入我们的优化方案,我们基于Python开发了一个CPU与GPU进程分离的统一框架kubeai-inference-framework,旧有Flask或Kserve的服务,稍作修改即可接入推理引擎统一框架,新增服务按照框架实现指定function即可。推理服务统一框架构如下图所示:

如前所述,推理服务统一框架的主要思路是把GPU逻辑与CPU逻辑分离到两个进程,除此之外,还会拉起一个Proxy进程做路由转发。
CPU进程
CPU进程主要负责推理服务中的CPU相关逻辑,包括前处理与后处理。前处理一般为图片解码,图片转换,后处理一般为推理结果判定等逻辑。CPU进程在前处理结束后,会调用GPU进程进行推理,然后继续进行后处理相关逻辑。CPU进程与GPU进程通过共享内存或网络进行通信,共享内存可以减少图片的网络传输。
GPU进程
GPU进程主要负责运行GPU推理相关的逻辑,它启动的时候会加载很多模型到显存,然后在收到CPU进程的推理请求后,直接触发Kernel Lanuch调用模型进行推理。
kubeai-inference-framework框架中对模型开发者提供了一个Model类接口,他们不需要关心后面的调用逻辑,只需要填充其中的前处理,后处理的业务逻辑,就可以快速上线模型服务,自动拉起这些进程。
Proxy进程
Proxy进程是推理服务入口,对外提供调用接口,负责路由分发与健康检查。当Proxy进程收到请求后,会轮询调用CPU进程,分发请求给CPU进程进行处理。
自研的推理服务统一框架,把CPU逻辑(图片解码,图片后处理等)与GPU逻辑(模型推理)分离到两个不同的进程中后,有效解决了Python GIL锁带来的GPU Kernel Launch调度问题,提升了GPU利用率,提高了推理服务性能。针对线上的某个推理服务,使用我们的框架进行了CPU与GPU进程分离,压测得出的数据如下表所示,可以看到QPS提升了近7倍。
| 推理服务框架类型 | QPS | 耗时(s) | GPU算力使用率(%) |
| 传统多线程架构 | 4.5 | 1.05 | 2.0 |
| 自研推理服务框架(6个CPU进程+1个GPU进程) | 27.43 | 0.437 | 12.0 |
2.3 做的更好 — 引入TensorRT优化加速
在支持推理服务接入kubeai-inference-framework统一框架的过程中,我们继续尝试在模型本身做优化提升。经过调研和验证,我们将现有pth格式模型通过转成TensorRT格式,并开启FP16,在推理阶段取得了更好的QPS提升,最高可到10倍提升。
TensorRT是由英伟达公司推出的一款用于高性能深度学习模型推理的软件开发工具包,可以把经过优化后的深度学习模型构建成推理服务部署在实际的生产环境中,并提供基于硬件级别的推理引擎性能优化。业内最常用的TensorRT优化流程,是把pytorch / tensorflow等模型先转成onnx格式,然后再将onnx格式转成TensorRT(trt)格式进行优化,如下图所示:

TensorRT所做的工作主要在两个时期,一个是网络构建期,另外一个是模型运行期。
-
网络构建期
-
模型解析与建立,加载onnx网络模型。
-
计算图优化,包括横向算子融合,或纵向算子融合等。
-
节点消除,去除无用的节点。
-
多精度支持,支持FP32/FP16/int8等精度。
-
基于特定硬件的相关优化。
-
模型运行期
-
序列化,加载RensorRT模型文件。
-
提供运行时的环境,包括对象生命周期管理,内存显存管理等
为了更好地帮助模型开发者使用TensorRT优化,KubeAI平台提供了kubeai-trt-helper工具,用户可以使用该工具把模型转成TensorRT格式,如果在模型转换的过程中出现精度丢失等问题,也可以使用该工具进行问题定位与解决。kubeai-trt-helper主要在两个阶段为用户提供帮助:一个是问题定位,另一个阶段是模型转换。
问题定位
问题定位阶段主要是为了解决模型转TensorRT开启FP16模式时出现的精度丢失问题。一般分类模型,对精度的要求不是极致的情况下,尽量开启FP16,FP16模式下,NVIDIA对于FP16有专门的Tensor Cores可以进行矩阵运算,相比FP32来说吞吐量提升一倍以上。比如在转TensorRT时,开启FP16出现了精度丢失问题,kubeai-trt-helper工具在问题定位阶段的大致工作流程如下:
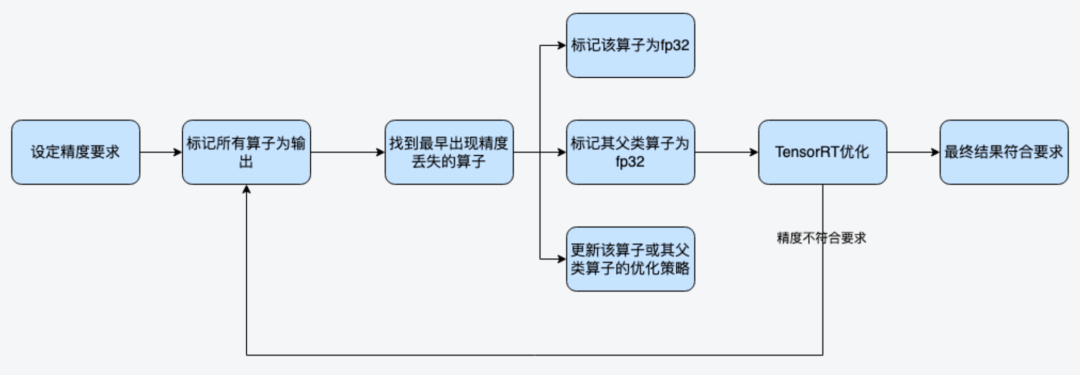
第1步:设定模型转换精度要求后,标记所有算子为输出,然后对比所有算子的输出精度。
第2步:找到最早的不符合精度要求的算子,对该算子进行如下几种方式干预。
-
标记该算子为FP32。
-
标记其父类算子为FP32。
-
更改该算子的优化策略。
循环通过以上2个步骤,最终找到符合目标精度要求的模型参数。这些参数比如:需要额外开启FP32的那些算子等。相关参数会输出到配置文件中,如下:
| 配置项 | 释义 |
| FP32_LAYERS_FOR_FP16 | 开启FP16模式下,哪些算子需要额外开启FP32 |
| TRT_EXCLUDE_TACTIC | TensorRT算子需要忽略的tactic策略(tactic可参考TensorRT相关资料) |
| atol | 相对误差 |
| rtol | 绝对误差 |
| check-error-stat | 误差的计算方法包括:mean, median, max |
模型转换
模型转换阶段则直接使用上面问题定位阶段得到的参数,调用TensorRT相关接口与工具进行转换。此外,我们在模型转换阶段,针对TensorRT原有参数与API过于复杂的问题也做了一些封装,提供了更为简洁的接口,比如工具可以自动解析onnx,判断模型的输入与输出shape,不需要用户再提供相关shape信息等。
2.4 落地实践成果
在实际应用中,我们帮助算法域的模型开发同学,能够对一个推理基于自研推理服务统一框架进行实现的同时,也开启TensorRT优化,这样往往可以得到QPS两次优化的叠加效果。
2.4.1 分类模型,CPU与GPU分离,TensorRT优化,并开启FP16,得到10倍QPS提升
线上某个基于Resnet的分类模型,对精度损失可以接受误差在0.001(误差定义:median,atol,rtol)范围内。因此我们对该推理服务进行了3项性能优化:
-
-
使用kubeai-inference-framework统一框架,对CPU进程和GPU进程进行分离改造。
-
对模型转ONNX后,转TensorRT。
-
开启FP16模式,并使用自研工具定位到中间出现精度损失的算子,把这些算子标记为FP32。
-
经过以上优化,最终得到了10倍QPS的提升(与原来Pytorch直接推理比较),服务成本大幅削减。
2.4.2 检测模型,CPU与GPU分离,TensorRT模型优化,QPS提升4-5倍左右。
线上某个基于Yolo的检查模型,由于对精度要求比较高,所以不能开启FP16,我们直接在FP32的模式下进行了TensorRT优化,并使用kubeai-inference-framework统一框架对GPU进程与CPU进程分离,最终得到QPS 4-5倍的提升。
2.4.3 模型推理进程多实例化,充分利用GPU算力资源
在实际的场景中,往往GPU的算力是充足的,而GPU显存是不够的。经过TensorRT优化后,模型运行时需要的显存大小一般会降低到原来的1/3到1/2。所以为了充分利用GPU算力,kubeai-inference-framework统一框架进一步优化,支持可以把GPU进程在一个容器内复制多份,这种架构即保证了CPU可以提供充足的请求给GPU,也保证了GPU算力充分利用。
线上某个模型,经过TensorRT优化后,显存由原来的2.4G降低到只需要1.2G。在保持推理服务配置5G显存不变的情况下,我们将GPU进程为复制4份,充分利用了5G显存,使得服务吞吐达到了原来的4倍。
3.AI训练引擎优化实践
3.1 PyTorch框架概况
PyTorch是近年来较为火爆的深度学习框架,几乎占据了CV(Computer Vision,计算机视觉)、NLP(Natural Language Processing,自然语言处理)领域各业务方向,算法同学基本都在使用PyTorch框架来进行模型训练。下图是基于PyTorch框架进行模型训练时的代码基本流程:
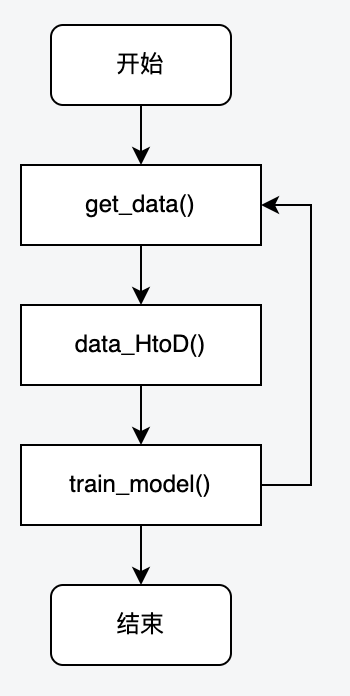
第1步:从pytorch dataloader中将本step训练过程中需要的数据拉出来。
第2步:将获取到的数据,例如:样本图片、样本标签的tensor等数据,复制到GPU显存里。
第3步:开始正式的模型训练:前向计算、计算损失、计算梯度、 更新参数。
整个训练过程的耗时,也主要分布在上面3个步骤。通常第2步不会是瓶颈,因为大部分训练样本图片都是被resize变小之后才从内存拷贝到到GPU显存上的。但由于模型的差异性、训练数据的差异性,经常是第1、2步会在训练过程中出现性能瓶颈,导致训练耗时长,GPU利用率低下,影响模型迭代效率。
3.2 Dataloader瓶颈分析及优化
3.2.1 PyTorch Dataset/Dataloader分析
PyTorch训练读取数据部分主要是通过Dataset、Dataloader的方式完成的,其中Dataset为用户自定义读取数据的类(继承自 torch.utils.data.Dataset),而Dataloader是PyTorch实现的在训练过程中对Dataset的调度器。
-
- torch.utils.data.dataloader
- torch.utils.data.Dataset
-
- train_loader = torch.utils.data.DataLoader( MyDataset,
- batch_size=16,
- num_workers=4,
- shuffle=True,
- drop_last=True,
- pin_memory=False)
-
- val_loader = torch.utils.data.DataLoader(MyDataset,
- batch_size=batch_size,
- num_workers=4,
- shuffle=False)
参数解释如下:
-
dataset(Dataset):传入的自定义Dataset(数据读取的具体步骤)。
-
batch_size(int, optional):每个batch有多少个样本,每个iter可以从dataloader中取出多少数据。
-
shuffle(bool, optional):在每个epoch开始的时候,对数据进行重新排序,可以使每个epoch读取数据的组合和顺序不同。
-
num_workers (int, optional):这个参数决定dataloader启动几个后台进程来做数据拉取。0意味着所有的数据都会被load进主进程,默认为0。
-
collate_fn (callable, optional):将一个list的sample组成一个mini-batch的函数,一般CV场景是concat函数。
-
pin_memory (bool, optional):如果设置为True,那么data loader将会在返回batch之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中, 这个参数某些场景下有妙用。
-
drop_last (bool, optional):该参数是对最后的未完成的batch来说的,比如batch_size设置为64,而一个epoch只有100个样本,如果设置为True,那么训练的时候后面的36个就被扔掉了,否则会继续正常执行,只是最后的batch_size会小一点。默认设置为False。
上述参数中,比较重要的是num_workers,Dataloader在构造的时候,会启动num_workers个worker进程,然后主进程会向worker进程分发读取任务,worker进程读到数据之后,再把数据放到队列中供主进程取用。多进程模式使用的是torch.multiprocessing接口,可以实现worker进程与主进程之间共享内存,而且共享内存中可以存放tensor,这样进程中如果返回tensor,可以通过共享内存的方式直接将结果返回给主进程,减少多进程间的通讯开销。
当num_workers 为0 的时候: get_data()流程与train_model()过程是串行,效率非常低下,如下图所示:

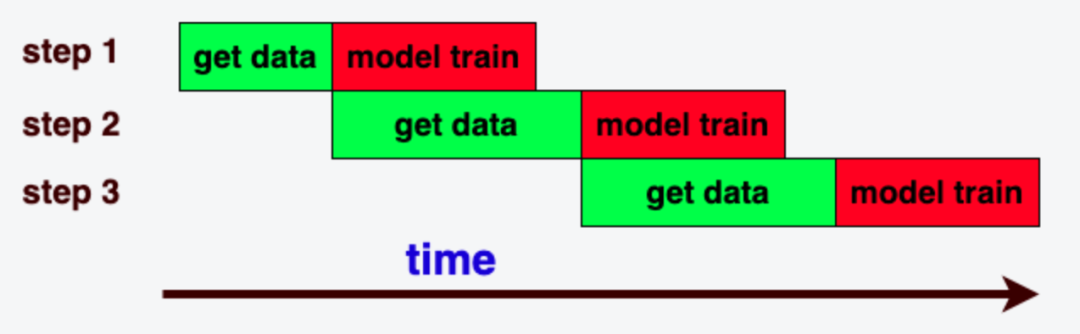
当num_workers 大于0开启多进程读取数据, 并且读取一个batch数据的时间小于一个step训练的时间时效率最高,GPU算力被充分利用,如下图所示:
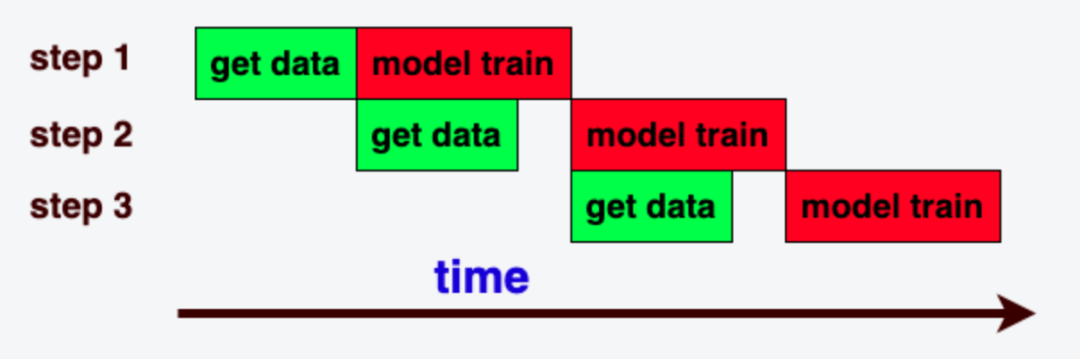
当num_workers 大于0开启多进程度数据, 但是读取一个batch数据的时间大于一个step训练的时间时,会出现GPU训练过程等待数据拉取,就会出现GPU算力空闲,训练耗时增加,如下图所示:
由此可见Dateset中的__getitem__函数非常重要,详细分析它的源码实现后我们发现,该函数的耗时主要包含2段时间:
-
load_image_time:从磁盘或者远程盘上读取数据的耗时。
-
transform_image_time:将图片或文本数据进行预处理的耗时。
3.2.2 解问题 — 设置合理的参数很重要
通过上一小节的分析,训练时相关参数的选择至关重要。总结如下:
-
batch_size:根据数据量,以及期望训练时长,用户合理自定义设置
-
训练环境(KubeAI Notebook/任务/流水线节点)的CPU配置:建议CPU配置为 GPU卡数*(单GPU卡配置的CPU核数)。
-
num_workers:参数最小设置为 训练环境的CPU配置-1,比如:任务配置为12C时,建议该参数设置为11 。另外,num_workers数值可以适当调大,因为
dataset iter中有部分时间是在网络或者磁盘IO, 这部分不消耗CPU;但是也不能设置太大,因为数据预处理部分是CPU密集型任务,并行进程过多,会造成CPU争抢从而降低预处理效率。
优化案例一
线上一个基于MMDetection框架(其底层也是调用PyTorch框架)的CV模型训练任务,在做参数调整之前,单个step耗时不稳定,平均在1.12s左右,其中拉取数据时长在0.3s左右:
- mmengine - INFO - Epoch(train) [2][3050/6005] time: 1.1128 data_time: 0.1032
- mmengine - INFO - Epoch(train) [2][3100/6005] time: 1.0193 data_time: 0.0055
- mmengine - INFO - Epoch(train) [2][3150/6005] time: 1.0928 data_time: 0.3230
- mmengine - INFO - Epoch(train) [2][3200/6005] time: 0.9927 data_time: 0.2304
- mmengine - INFO - Epoch(train) [2][3250/6005] time: 1.3224 data_time: 0.5135
- mmengine - INFO - Epoch(train) [2][3300/6005] time: 1.1044 data_time: 0.3427
- mmengine - INFO - Epoch(train) [2][3350/6005] time: 1.0574 data_time: 0.2842
调整参数之后,单个step耗时稳定,平均在0.78 s左右,其中拉取数据耗时0.004s,基本可以忽略。
- mmengine - INFO - Epoch(train) [1][100/5592] time: 0.8508 data_time: 0.0049
- mmengine - INFO - Epoch(train) [1][150/5592] time: 0.7743 data_time: 0.0043
- mmengine - INFO - Epoch(train) [1][200/5592] time: 0.7736 data_time: 0.0044
- mmengine - INFO - Epoch(train) [1][250/5592] time: 0.7880 data_time: 0.0044
- mmengine - INFO - Epoch(train) [1][300/5592] time: 0.7761 data_time: 0.0045
该模型训练任务,通过上述优化调整,数据拉取时间缩短为0,单个step的耗时从原来的1.12s降到0.78s,整体训练时间减少30%(从2天缩短到33小时),效果显著。
优化案例二
线上某个多模态模型(输入包含图片和文字)训练任务,使用2卡V100训练,参数调整如下:
- batch_size=32
- CPU = 12 ---> 调整为 24
- num-workers = 4 ---> 调整为 11
调整后训练300 step总消耗时405s,整体训练时间减少45%左右(从10天缩短到5天左右)。
优化案例三
线上某YoloX模型训练任务,使用单卡A100训练,参数调整如下:
- batch size :48
- num-workers = 4 ---> 调整为 16
调整后整体训练时长减少80%左右(从10天19小时,缩短至1天16小时)。
3.2.3 数据拉取IO瓶颈分析
当前,KubeAI平台为训练场景提供3种存储介质:
-
本地盘:空间小,读写性能最好,单盘500G~3T空间可用。
-
NAS网络存储:空间大,读写性能较差,成本适中。
-
CPFS并行文件系统存储:空间大,读写性能好,成本高。
对于小数据集,可以先将数据一次性拉取到本地盘,然后每个epoch从本地盘来读数据,这样避免了每一个epoch重复的从远程NAS来拉取数据,相当于整个训练只需要从远程NAS拉取一次数据。对于大数据集,有2种解决方案:
-
将大数据集提前进行resize,存储比较小的图片来进行训练,这样避免了每个epoch都需要resize,而且resize之后,图片变小,读取更快。
-
将数据集放入并行文件系统CPFS存储上,提高训练吞吐。实验表明CPFS 在图片场景下是NAS盘读性能的3~6倍。
3.3 TrainingModel优化
数据部分优化后,训练过程中的主要时间开销就在GPU训练部分了。目前业内有一些比较成熟的方法可以参考,我们总结如下。
3.3.1 混合精度训练(AMP)
PyTorch混合精度训练在PyTorch官网有详细介绍,以及开启混合精度训练的方法,可以阅读这里获取实现方法。当前许多CV训练框架已经支持AMP训练,比如:
-
MMCV框架中AMP参数就是开启混合精度训练的选项。
-
Pytorch Vision中也有相关参数来开启AMP训练。
需要说明的是,混合精度训练过程中并不是将所有模型参数都转为FP16来计算,只有部分做转换。混合精度之所以能加速训练过程,是因为大部分英伟达GPU机型在FP16这种数据格式的浮点算力比FP32要快一倍;此外,混合精度训练显存占用会更小。
- scaler = GradScaler()
-
- for epoch in epochs:
- for input, target in data:
- optimizer.zero_grad()
- with autocast(device_type='cuda', dtype=torch.float16):
- output = model(input)
- loss = loss_fn(output, target)
- scaler.scale(loss).backward()
-
- # Unscales the gradients of optimizer's assigned params in-place
- scaler.unscale_(optimizer)
-
- # Since the gradients of optimizer's assigned params are unscaled, clips as usual:
- torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
-
- # optimizer's gradients are already unscaled, so scaler.step does not unscale them,
- # although it still skips optimizer.step() if the gradients contain infs or NaNs.
- scaler.step(optimizer)
-
- # Updates the scale for next iteration.
- scaler.update()

3.3.2 单机多卡数据并行训练
Pytorch原生支持多卡数据并行训练,详细开启多卡训练的方式参考官方文档。多卡训练过程中每一张卡的backword计算会多加一次多卡之间集合通讯all-reduce操作,用来计算多张卡上的梯度的平均值。
3.4 自研训练引擎框架kubeai-training-framework
通过前面的分析我们可以看到,虽然PyTorch框架本身已经做的很好了,训练方式、参数支持丰富,但在实际的模型研究和生产过程中,由于模型的差异性、训练数据的差异性,以及模型开发者的经验差异性,PyTorch框架本身的优势不一定能够发挥出来。
基于前述分析和实践,KubeAI平台开发了训练引擎框架kubeai-training-framework,帮助模型开发者更好地匹配训练脚本参数,快速接入使用合适的训练方式。kubeai-training-framework中包含PyTorch Dataloader优化、GPU TrainModel(AMP)提速以及各种功能函数等。以Dataloader为例,用户可通过以下方式使用:
- import torch
- from kubeai_training_framework.dataloader import Dataloader
-
- def train(train_loader, model, criterion, optimizer, epoch):
- train_dataset = .......
- train_loader = torch.utils.data.DataLoader(
- train_dataset, batch_size=args.batch_size, shuffle=True,
- num_workers=args.workers, pin_memory=True)
-
- model.train()
- my_train_loader = Dataloader(train_loader)
- input, target = my_train_loader.next()
-
- while input is not None:
- ## model train 代码 input, target
- ..........
- input, target = my_train_loader.next()
4.AI Pipeline引擎助力AI业务快速迭代
通常模型的开发可以归纳为如下图所示的过程:

可以看到,在需求场景确定、第一个模型版本上线之后,模型是需要反复迭代的,以期望取得更好的业务效果。KubeAI平台在迭代建设的过程中,逐步上线了Notebook、模型管理、训练任务管理、推理服务管理等一个个相对独立的功能模块。随着业务需求的不断变化,模型迭代效率直接影响了业务的上线效率,KubeAI平台建设了AI Pipeline能力,重点解决AI场景的周期性迭代类需求,提高生产效率。
AI Pipeline是在ArgoWorkflow基础上做了二次开发,以满足模型迭代、推理任务管理、数据处理等对定时需求、任务启动触发方式、通用模板任务、指定节点启动等需求。AI Pipeline上线之前,一个迭代任务可能会被配置为多个分散的任务,维护工作量大,调试周期长。如下图是做一个类似任务需要单独配置的任务情况:

AI Pipeline可以将整个工作流设计成如下图所示:

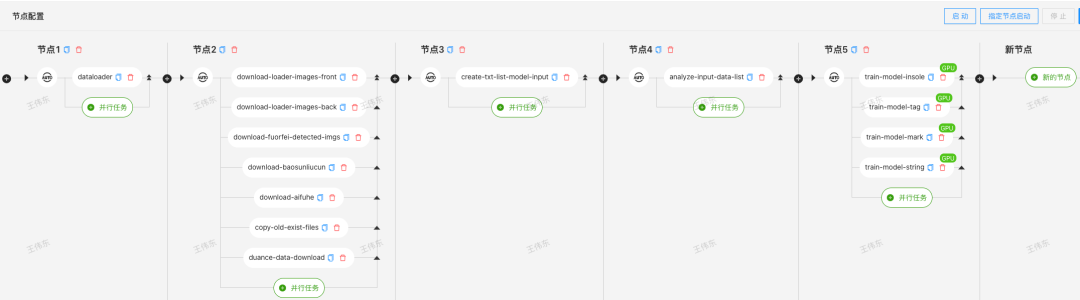
Pipeline编排的方式,减少了模型开发者浪费在重复工作上的时间,可以将更多的时间投入到模型研究上。同时,通过合理编排任务,可以对有限的资源进行充分地利用。
5.展望
KubeAI平台从得物AI业务场景的实际需求出发,以三大核心引擎为建设目标,着力解决AI模型研发过程中的训练、推理性能问题,以及模型版本迭代过程中的效率问题。
在推理服务性能上,我们会以kubeai-inference-framework为起点,继续在模型量化、算子优化、图优化等方面进行深入探索。在模型训练方面,我们会继续在图像数据预处理、Tensorflow GPU训练框架支持、NLP模型训练支持上发力,以kubeai-training-framework训练引擎框架为接口,为模型开发者提供更高效、性能更高的训练框架。此外,AI Pipeline引擎上,我们会支持更丰富的预置模型,以满足通用数据处理任务、推理任务等需求。
文:伟东
线下活动推荐:
时间:5月14日(周日)14:00-18:00
主题:得物技术沙龙第17期-稳定生产专场
地点:上海市杨浦区黄兴路221号互联宝地C2栋5楼 培训教室
活动亮点:你知道得物App稳定性是怎么从99.91%提升到99.996%吗?《得物技术沙龙-稳定生产专题》将揭秘,不仅如此,我们还特别邀请了来自AWS(亚马逊中国)、SkyWalking 社区、Greptime(格睿科技)等知名企业的技术专家,将和大家分享他们在保障系统稳定性方面的经验和心得。
点击了解详情:叮~查收你的稳定生产得物技术沙龙邀请函
本文属得物技术原创,来源于:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!

