
- 1【探索Linux】—— 强大的命令行工具 P.30(序列化和反序列化 | JSON序列化库 [ C++ ] )
- 2后端返回文件流pdf 下载
- 3【深度学习 九】transformer_transformer的encoder输出什么
- 4分布式并行训练基础样例(CPU)_在cpu上分布式训练
- 5Bag of Tricks for Efficient Text Classification (fastText) 学习笔记_fasttext model 镜像网站
- 6SER | 语音情绪识别 | TIM-NET_SER项目实现,以及训练自己的语音数据集,后期修改网络_timnet
- 7adb pull 使用
- 8c++实验7——数组素数排序_c++素数升序排序
- 9卷积神经网络CNN基本原理和相关基本概念_卷积核的值是固定的吗
- 10Arcpy基础方法之Tools&Toolboxes_ta import concatenatedateandtimefields as concaten
这个入门级 AI 项目,让你一看就会_ai入门实战项目
赞
踩
随着AI的发展,美国橡树岭国家实验室的一些专家预测,到2040年,AI技术将会强大到足以替代程序员。AI技术将会强大到足以替代程序员,AI编写软件将比人类程序员更好、更快。换句话说,软件编写的软件比人类编写的更好。
这是怎么发生的?AI能真正学会如何做需要高度创造性的智力工作吗?毕竟创造性一直被认为是人类特有的。AI能学到的东西会比我们教它的更多吗?
稳住,别慌今天本文将分享一篇AI入门实战的项目经验分享,专门为对于没有动过手的同学准备,以此来启发新手们如何开动,了解AI技术~
前段时间参加了一次TinyMind举办的汉字书法识别挑战赛,说是挑战赛其实就是一场练习赛。为一些刚刚入门的同学和没有比赛经验的同学提供了一个探索图像识别领域的平台。我目前是暂列榜首(没想到转眼就被超越了),所以把自己的思路和想法稍微做一个分享,给有需要的人提供一个base line。
先来看数据集~~
100个汉字的训练集
10000张书法图片的测试集
上面的训练集总共有100个汉字,每一个汉字都有400张不同字体的图片,数据量上来看算是一个比较小的数据集。
等等,看到的确定是汉字吗,第一眼望过去我是真的emmmmm......甲骨文,篆体各种字体都冒出来了。先喝口水冷静一下,仔细看一看发现图片都是gray的。想了一想突然觉得这个和MNIST并没有太大的区别只是字体更加复杂一些,可能要用稍微深一点的网络来训练。
图片看完了,那么开始撸代码了。分析终究是分析,还是实践才能说明一切。
竞赛中只给了Train和test,所以需要自己手动划分一个Val来做模型训练的验证测试。在这里简单说明一下经常用的两种划分数据集的方法。
本地划分;内存划分。
本地划分:图片是按照文件夹分类的,所以只需要从每个文件夹中按Ratio抽取部分图片到val中即可,当然不要忘记了shuffle。
内存划分:把所有图片和标签读进内存中,存为list或者Array然后shuffle后按长度划分。前提是把数据读进去内存不会爆炸掉。内存划分只适合小型数据集,不然会Boom!!!
注:划分数据集的时候一定要打乱数据,shuffle很重要!!!
1def move_ratio(data_list, original_str, replace_str):
2 for x in data_list:
3 fromImage=Image.open(x)
4 x=x.replace(original_str, replace_str)
5 fromImage.save(x)
注:这里只给出部分代码,文章最下面GitHub有完整链接。
1for d in $(ls datadir); do
2 for f in $(ls datadir/$d | shuf | head -n 100 ); do
3 mkdir -p valid_dir/$d/
4 mv datadir/$d/$f valid_dir/$d/;
5 done;
6done
注:这里引用dwSun的Linux Shell脚本,
如果想用简单脚本实现也可以采用他的代码~
模型建立与数据预处理
对于CNN网络来说,大的数据集对应大的训练样本,如果小的数据集想要用深层次的网络来训练的话,那么必不可少的一步就是数据增强。
数据增强的大部分方法,所有深度学习框架都已经封装好了。这里我采用的是Keras自带的数据增强方法。
1from keras.preprocessing.image import ImageDataGenerator
2datagen=ImageDataGenerator(
3 # horizontal_flip=True,
4 width_shift_range=0.15,
5 height_shift_range=0.15,
6 rescale=1 / 255
7)
由于汉字是具有笔画顺序的,所以做了翻转以后训练的效果不是很好。这里就做了一个宽度和高度的偏移,由于给的数据集图片长宽不是固定的而且字体的内容也是有长有短。所以用这两种增强方式可以提高模型的准确率,结果测试这两种方式还是有效的。
数据处理完了,那么下面就是我们可爱的CNN网络模型了

cnn一把梭,嗯,就是干。
1# bn + prelu
2def bn_prelu(x):
3 x=BatchNormalization()(x)
4 x=PReLU()(x)
5 return x
6# build baseline model
7def build_model(out_dims, input_shape=(128, 128, 1)):
8 inputs_dim=Input(input_shape)
9 x=Conv2D(32, (3, 3), strides=(2, 2), padding='valid')(inputs_dim)
10 x=bn_prelu(x)
11 x=Conv2D(32, (3, 3), strides=(1, 1), padding='valid')(x)
12 x=bn_prelu(x)
13 x=MaxPool2D(pool_size=(2, 2))(x)
14 x=Conv2D(64, (3, 3), strides=(1, 1), padding='valid')(x)
15 x=bn_prelu(x)
16 x=Conv2D(64, (3, 3), strides=(1, 1), padding='valid')(x)
17 x=bn_prelu(x)
18 x=MaxPool2D(pool_size=(2, 2))(x)
19 x=Conv2D(128, (3, 3), strides=(1, 1), padding='valid')(x)
20 x=bn_prelu(x)
21 x=MaxPool2D(pool_size=(2, 2))(x)
22 x=Conv2D(128, (3, 3), strides=(1, 1), padding='valid')(x)
23 x=bn_prelu(x)
24 x=AveragePooling2D(pool_size=(2, 2))(x)
25 x_flat=Flatten()(x)
26 fc1=Dense(512)(x_flat)
27 fc1=bn_prelu(fc1)
28 dp_1=Dropout(0.3)(fc1)
29 fc2=Dense(out_dims)(dp_1)
30 fc2=Activation('softmax')(fc2)
31 model=Model(inputs=inputs_dim, outputs=fc2)
32 return model
这里用了6个简单的卷积层,和PRelu+BN层。
下面是一个比较大的模型ResNet50,Merge模型是已经Merge在了Keras的Applications中,可以直接用。不过需要调整分类层。
1def resnet50_100(feat_dims, out_dims):
2 # resnett50 only have a input_shape=(128, 128, 3), if use resnet we must change
3 # shape at least shape=(197, 197, 1)
4 resnet_base_model=ResNet50(include_top=False, weights=None, input_shape=(128, 128, 1))
5 # get output of original resnet50
6 x=resnet_base_model.get_layer('avg_pool').output
7 x=Flatten()(x)
8 fc=Dense(feat_dims)(x)
9 x=bn_prelu(fc)
10 x=Dropout(0.5)(x)
11 x=Dense(out_dims)(x)
12 x=Activation("softmax")(x)
13 # buid myself model
14 input_shape=resnet_base_model.input
15 output_shape=x
16 resnet50_100_model=Model(inputs=input_shape, outputs=output_shape)
17 return resnet50_100_model
好了,炼丹炉有了接下来就是你懂的。
训练模型和调参真的是一个技术活,这里我跑了共40个Epoch。思路只有一个那就是先把Train的数据跑到loss下降并且先过拟合再说。只要过拟合了后面的一切都好调整了,如果训练数据都不能到过拟合或者99以上那么要仔细想想数据量够不够和模型的选择了。

loss
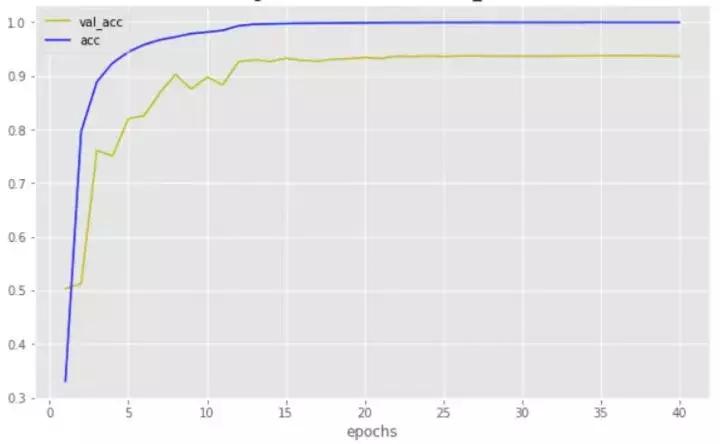
acc
可以很清楚的看出来,训练数据集已经过拟合了。我用的优化器是SGD,学习率设置的是lr=0.01。val_acc可以跑到了0.94左右,这是一个比较正常的训练水平。还可以进一步的提高。
数据增强:采取其他的数据增强方法进一步扩大训练数据,这里可以采用GAN来生成近似于真实图片的数据。衰减学习率:当到达一定Epoch的时候,loss不再下降了这个时候可以通过减小学习率的方法进一步训练。模型融合:模型融合的方法在大部分数据集上都会有所提高,这个是最常用的一种竞赛方式。
以上就是我自己做的流程和思路,提交结果和评测的代码写在我的GitHub上面了,有兴趣参加比赛练手的同学可以参考一下。
Github地址:github/FlyEgle/chinese_font_recognition/
好多小伙伴是从开发或者是其他工程上转到AI的,所以下面我给有需要的同学列举出一些必要的基础知识点:
数学:线性代数和概率论是必须要会的,而且基本的概念和计算都要懂。可以把高数,线性代数和概率论看一遍,这里推荐李航的统计学习方法。图像处理:如果是做图像方面的小伙伴,那么需要把冈萨雷斯的图像处理那本巨作看一遍,需要懂基本的图像概念和基本方法。
还有机器学习深度学习经典书、如果能把这几本书完全吃透那也很厉害了,当然学习知识点的途径还有很多。
学习社区;Google;TinyMind。
如果想深入学习的话,我推荐还是报名实训营,让更有经验的大咖导师为你指路,效率和效果都会翻倍!
在这里推荐CSDN学院出品的《人工智能工程师直通车》实训营,目的是:通过120天的实战,将学员培养达到具备一年项目经验的人工智能工程师水平。CSDN百天计划课程共分为3个阶段,4个月完成。

联系CSDN学院职场规划师,
获取一对一专属服务(WeChat ID:csdn26)
(包括:IT职场规划服务/专属折扣)
很多学员都曾苦恼,工作中缺乏“好师傅”,很多Bug,也都得绞尽脑汁自己解决。在全栈特训营,这些问题都将不存在。
我们采取讲师+课程助教的服务模式。
授课的两位老师分别是:中国科学院大学计算机与控制学院副教授卿来云老师、和计算机视觉领域处理大牛智亮老师。两位老师一个偏重理论知识、算法推倒;一个偏重实际操作,实战经验,可以全方面的为学员提供知识的讲解。
课程助教将会带领你一起攻克项目,Review你的代码并给出意见。最后,课程助教会带你们一起进行项目最后上线路演,并接受导师的点评。

