
- 1软件测试工程师的待遇怎么样_软件测试工程师怎么样
- 2微信 PC 端 v3.9.9.27 多开消息防撤回版_微信3.9.9.27
- 3Format格式_{0:d}.format(2.1234567)
- 4git clone --depth=1时的一些问题_http 504 curl 22 the requested url returned, depth
- 5Rotary Position Embedding (RoPE, 旋转式位置编码) | 原理讲解+torch代码实现_旋转位置编码
- 6git fetch - git merge - git pull 指令_git fetch merge
- 7使用多项式朴素贝叶斯对中文垃圾短信进行分类_中文垃圾短信数据集
- 8关于el-upload上传图片拿不到图片信息,无法删除问题_el upload handlesuccess拿不到res
- 9idea(version 2020.1) checkout发现不见了(个人笔记)_idea 不显示checkout tag or revisoion
- 10【Unity音游制作】你玩过节奏大师吗?(Koreographe插件导入游戏主体)【一】
自然语言处理——基础篇01_基于规则的自然语言生成
赞
踩
自然语言处理——基础篇01
一、什么是自然语言处理?
自然语言处理(Natural Language Processing,NLP): 是用计算机来理解和生成自然语言的各种理论和方法。
自然语言: 指的是人类语言,特指文本符号,而非语音信号。
自然语言处理的代表性应用: 机器翻译、智能助手、文本校对、舆情分析、智能教育、知识图谱。
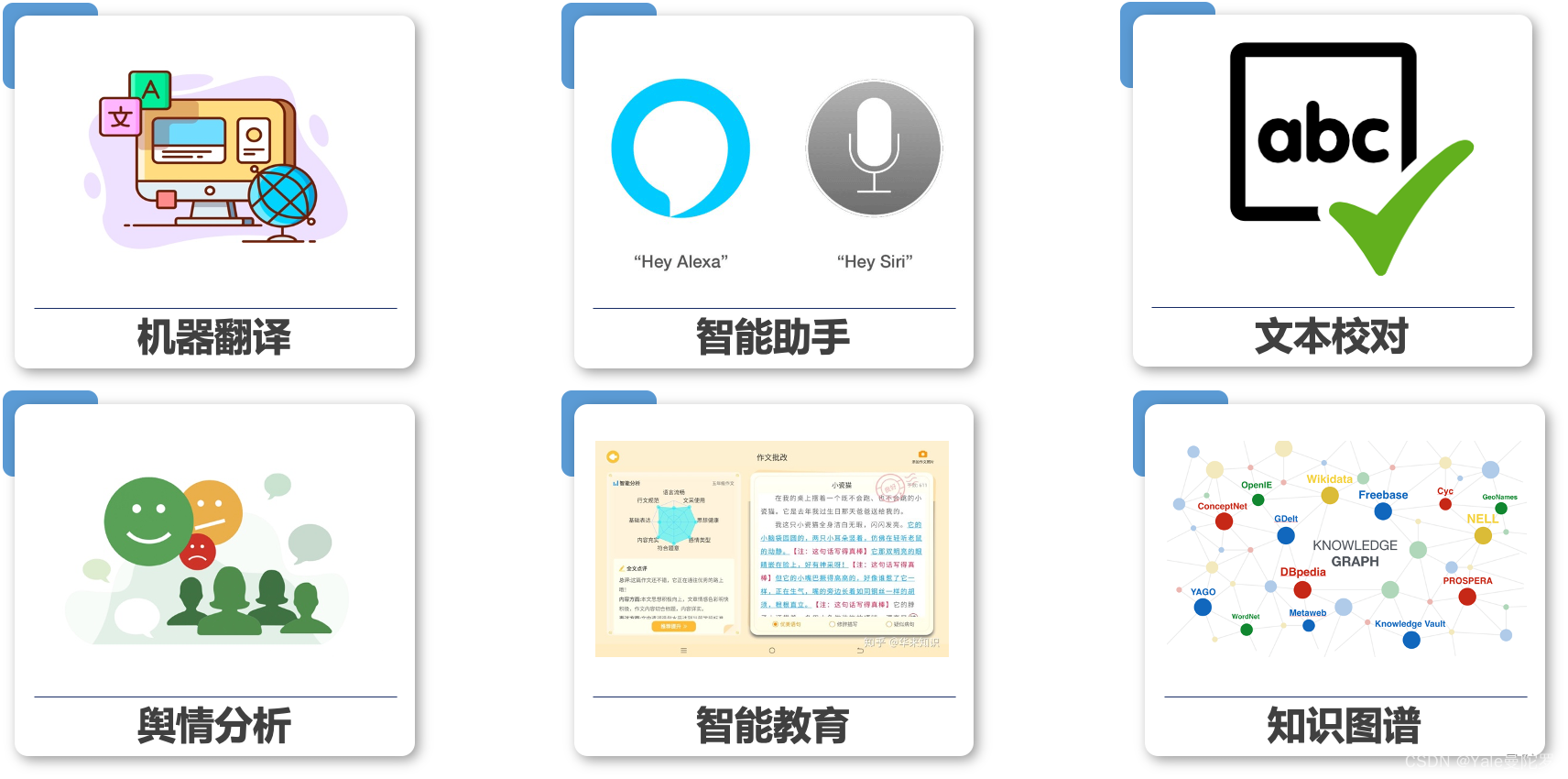
自然语言处理属于认知智能任务: 认知智能 是人类与动物的主要区别之一,它需要更强的抽象和推理能力。
二、自然语言处理的难点与特点?
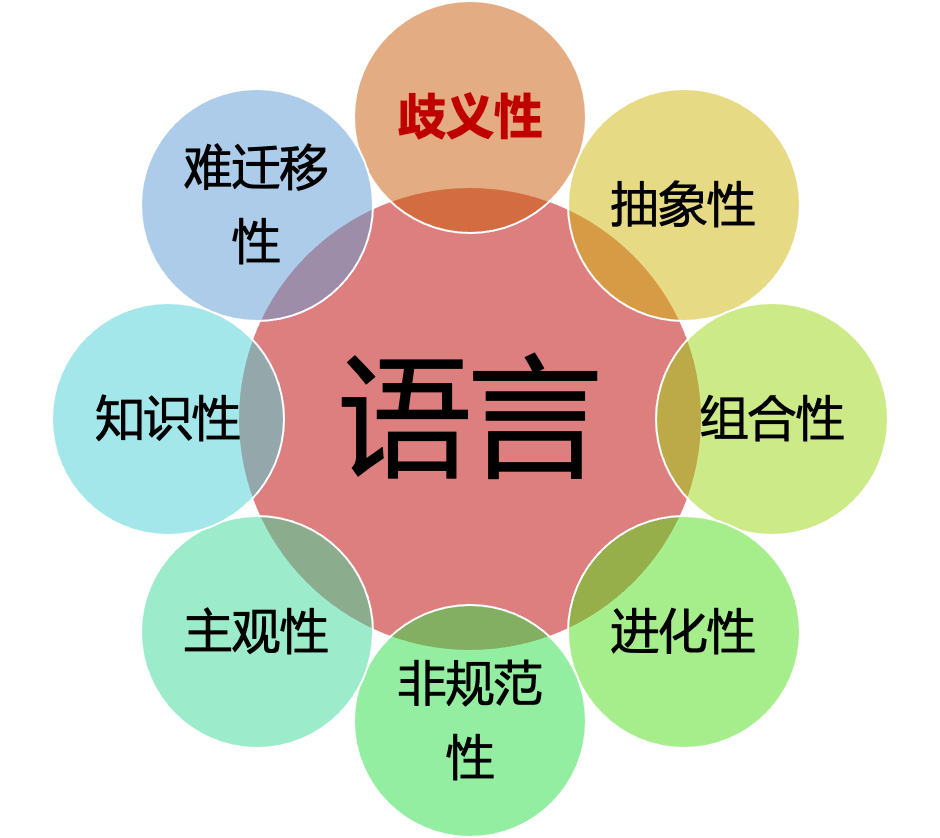
自然语言处理的复杂性,在于【语言】本身具有如下特点:歧义性、抽象性、组合性、进化性、非规范性、主观性、知识性,以及难迁移性。
基于上述原因,在下述同样一段对话中的【意思】两字,在不同情境下有不同含义。

自然语言处理成为制约人工智能取得更大突破和更广泛应用的瓶颈。
自然语言处理的任务层级: 至底向上,依次为:资源建设、基础任务、应用任务、应用系统,共四个层级。

自然语言处理可以归结为四个基本问题:
- 文本匹配问题;
- 文本分类问题;
- 序列到序列问题;
- 结构预测问题。
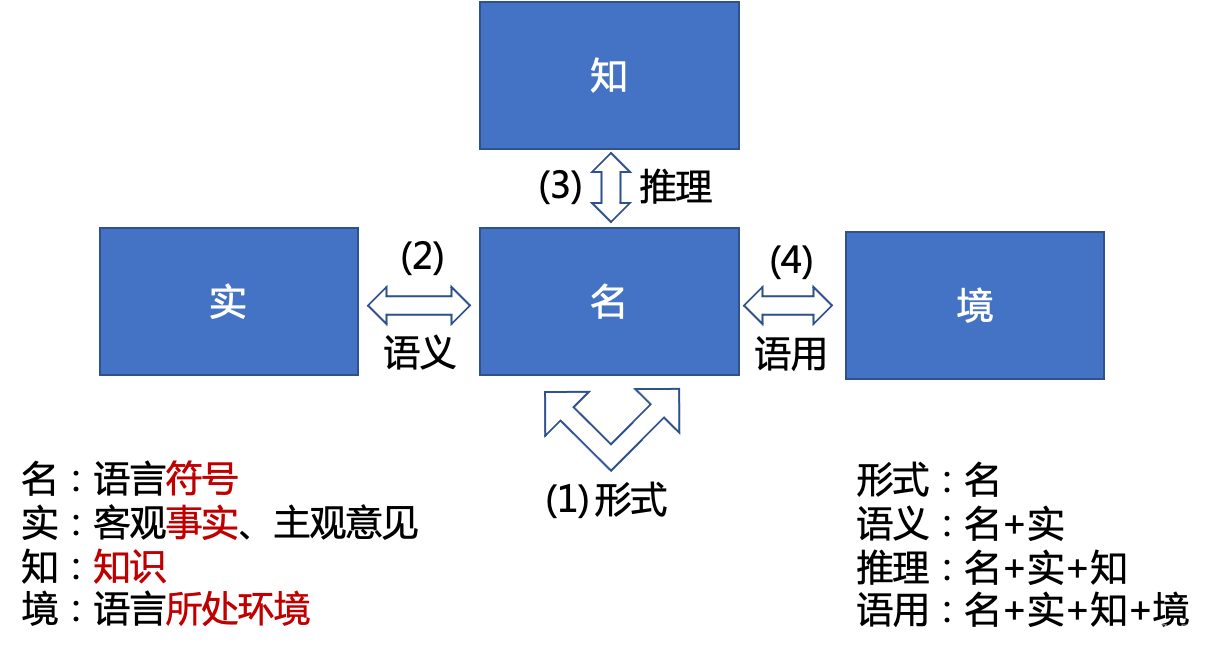
自然语言处理的研究对象与层级:
自然语言处理的研究对象包括:名、实、知、境,共四个。
- 形式方面:主要研究语言符号层面的处理,研究的是“名”与“名”之间的关系,如:
通过编辑距离等计算文本之间的相似度。 - 语义方面:主要研究语言符号和其背后所要表达的含义之间的关系,即“名”和“实”之间的关系,如“手机余额不足”和“电话欠费了”
两个句子的表达方式完全不同,但是背后阐述的事实是相同的。语义问题也是自然语言处理领域目前主要关注的问题。 - 推理方面:
推理是在语义研究的基础之上,进一步引入知识的运用,因此涉及“名”、“实”和“知”之间的关系,这一点正体现了自然语言的知识性。 - 语用方面:语用则最为复杂,由于
引入了语言所处的环境因素,通常表达的是“言外之意”和“弦外之音”,同时涉及了“名”、“实”、知”、“境”四个方面。例如:同样的一句话“你真讨厌”,从字面意义上明显是贬义,而如果是情侣之间的对话,则含义可能就不一样了。另外,语气、语调以及说话人的表情和动作也会影响其要表达的含义。
自然语言处理中【层级 × × ×任务】二维表:
| 分类 | 解析 | 匹配 | 生成 | |
|---|---|---|---|---|
| 形式 | 文本分类 | 词性标注、句法分析 | 搜索 | 机械式文摘 |
| 语义 | 情感分析 | 命名实体识别、语义角色标注 | 问答 | 机器翻译 |
| 推理 | 隐式情感分析 | 文本蕴含 | 写故事结尾 | |
| 语境 | 反语 | 聊天 |
三、语言模型
语言模型(Language Model,LM): 是描述一段自然语言的概率或者给定上文时下一个词出现的概率。以上两种定义是等价的,且均遵循【链式法则】。
P ( w 1 w 2 . . . w l ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 w 2 ) . . . P ( w l ∣ w 1 w 2 . . . w l − 1 ) = ∏ i = 1 l P ( w i ∣ w 1 : i − 1 ) P(w_1w_2...w_l)=P(w_1)P(w_2|w_1)P(w_3|w_1w_2)...P(w_l|w_1w_2...w_{l-1}) =\prod_{i=1}^l P(w_i|w_{1:{i-1}}) P(w1w2...wl)=P(w1)P(w2∣w1)P(w3∣w1w2)...P(wl∣w1w2...wl−1)=i=1∏lP(wi∣w1:i−1)
语言模型 广泛应用于多种自然语言处理任务:
- 机器翻译(词排序): P ( t h e c a t i s s m a l l ) > P ( s m a l l t h e i s c a t ) P(the \quad cat \quad is \quad small) > P(small \quad the \quad is \quad cat) P(thecatissmall)>P(smalltheiscat)
- 语音识别(词选择): P ( t h e r e a r e f o u r c a t s ) > P ( t h e r e a r e f o r c a t s ) P(there \quad are \quad four \quad cats) > P(there \quad are \quad for \quad cats) P(therearefourcats)>P(thereareforcats)
四、NLP的常见任务类型
1. 中文分词
词: 是最小的能够独立使用的音义结合体,包括:(1)以汉语为代表的【汉藏语系】;(2)以阿拉伯语为代表的【闪-含语系】中不包含明显的词之间的分隔符。
中文分词: 是将中文字序列切分成一个个单独的词。
中文分词的最大难点是【分词的歧义】: 示例如下:
原始:严守一把手机关了
分词:
1、严守一/把/手机/关/了
2、严守/一把手/机关/了
3、严守/一把/手机/关/了
4、严守一/把手/机关/了
- 1
- 2
- 3
- 4
- 5
- 6
2. 子词切分(Subword)
以英语为代表的【印欧语系语言】,由于词形变化复杂(如:computer、computers、computing等),仅用空格切分存在如下问题:
- 数据稀疏;
- 词表过大,降低处理速度;
因此,通常采用 子词切分 ,方法如下:
- 将一个单词切分为若干连续的
片段(子词); - 子词切分的方法众多,其基本原理相似,即:使用尽量长且频次高的子词对单词进行切分。
3. 句法分析
句法分析: 是分析句子的句法成分(如:主、谓、宾、定、状、补等),将词序列表示的句子转换成【树状结构】。


4. 语义分析
语义分析: 分为 词义消歧(Word Sense Disambiguation,WSD) 、 语义角色标注(Semantic Role Labeling,SRL) 和 语义依存图(Semantic Dependency Graph) 三部分。
备注:
\quad
- 语义角色标注(Semantic Role Labeling,SRL) 也称【谓词论元结构(Predicate-Argument Structure)】
- 语义依存图(Semantic Dependency Graph) 的示例如下:


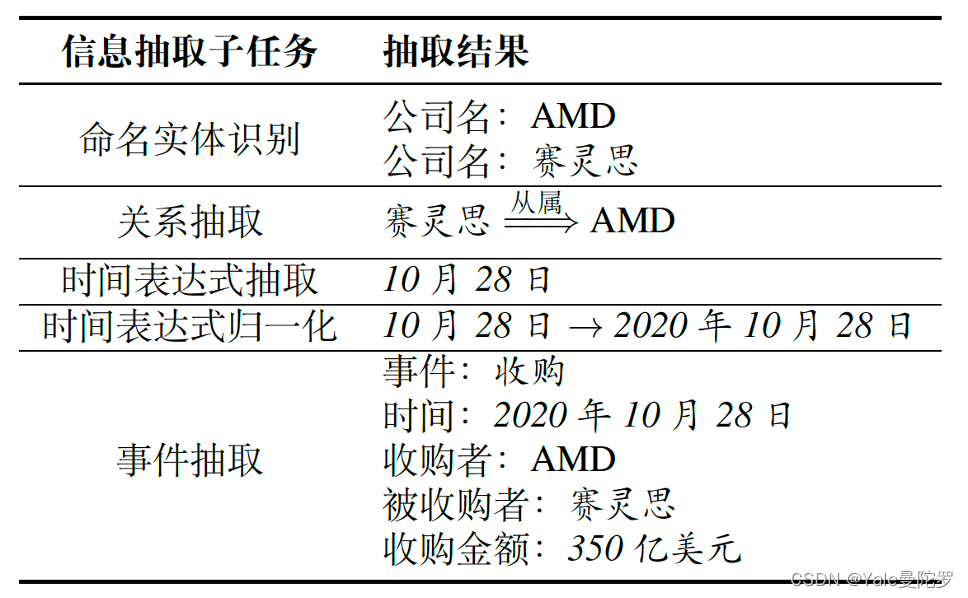
4. 信息抽取
信息抽取(Information Extraction,IE): 从非结构化的文本中自动抽取结构化信息。
输入:10月28日,AMD宣布斥资350亿美元收购FPGA芯片巨头赛灵思。这两家传了多年绯闻的芯片公司终于走到了一起。
- 1
5. 情感分析
情感分析(Sentiment Analysis,SA): 是指个体对外界事物的态度、观点或倾向性(如:正面、负面等),以及人自身的情绪(Emotion),如:喜、怒、哀、惧等。
输入:这款手机的屏幕很不错性能也还可以。
- 1

6. 问答系统
问答系统(Question Answering,QA): 用户以自然语言形式描述问题,从异构数据中获得答案。根据数据来源的不同,问答系统可以分为4种主要的类型:
- 检索式问答系统:答案来源于固定的文本语料或互联网,系统通过查找相关文档并抽取答案完后才能问答。
- 知识库问答系统:问答问题所需的知识以数据库等结构化形式存储,问答系统首先将问题解析为结构化的查询语句,通过查询相关知识点,并结合知识推理获取答案。
- 常见问题集回答系统:通过对历史积累的常见问题集合进行检索,回答用户提出的类似问题。
- 阅读理解式问答系统:通过抽取给定文档中的文本片段或生成一段答案来回答用户提出的问题。
7. 机器翻译
机器翻译(Machine Translation,MT):
8. 对话系统
对话系统(Dialogue System,DM):
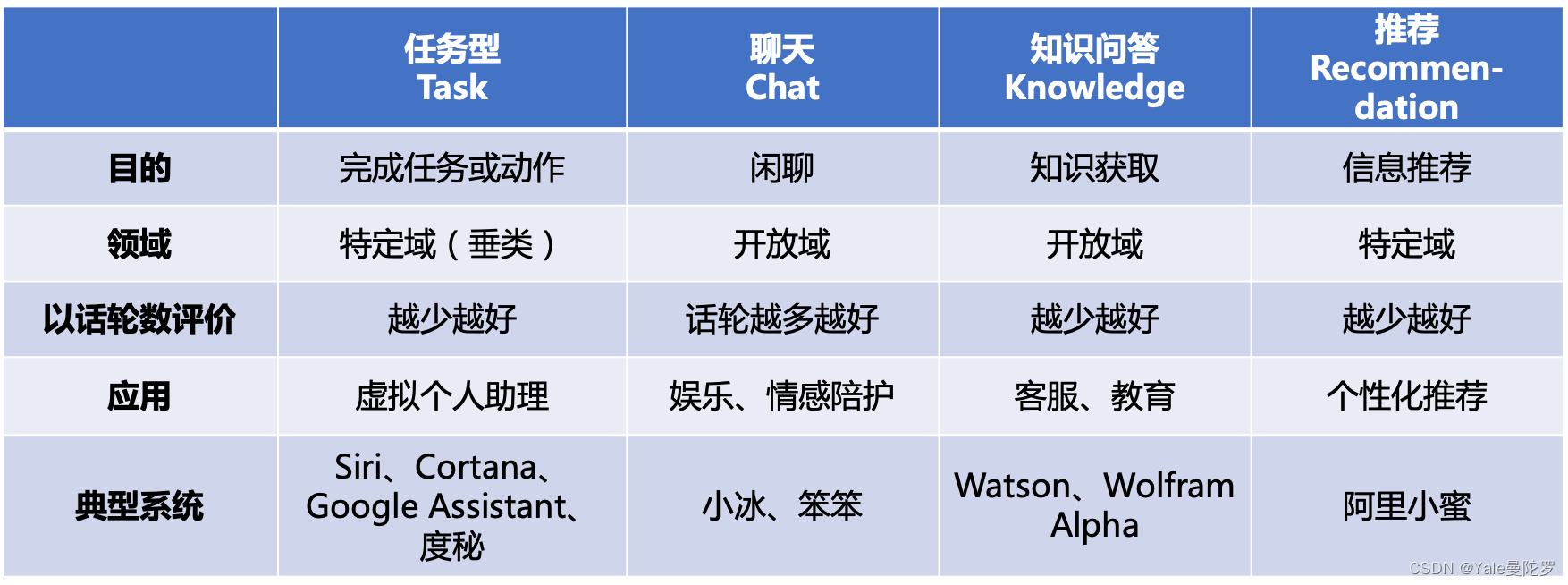
五、文本的表示
若要利用计算机对自然语言进行处理,首先需要解决语言(特指【文本】)在计算机内部的存储和计算问题。字符串(String)是文本最自然,也是最常用的机内存储形式。根据语义在计算及内部的表示方法不同,自然语言处理技术经历了四次范式变迁。依次为:

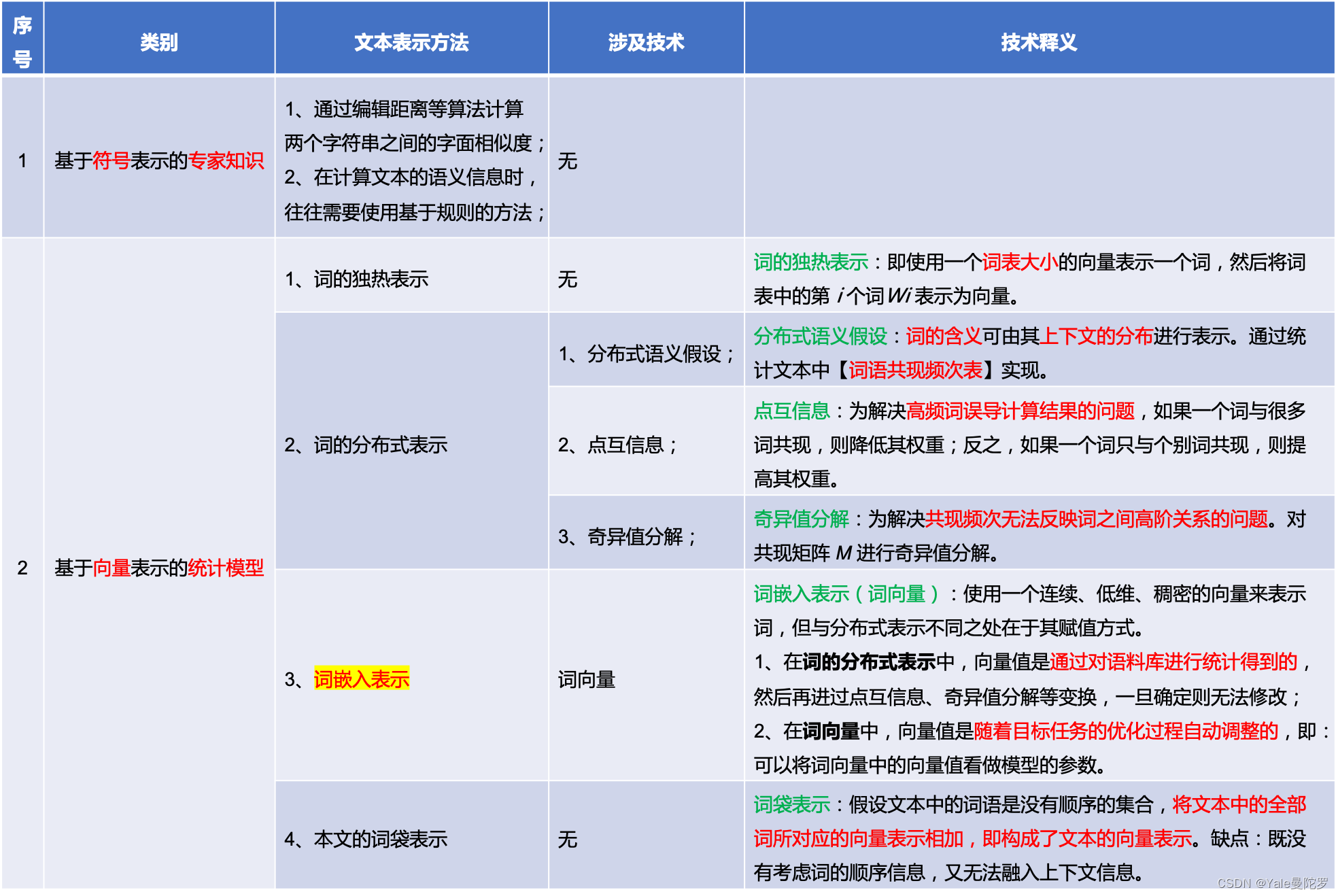
分布式(Distributed)词表示的发展历程:

1. 基于符号(字符串)表示的专家知识
在使用字符串表示计算文本的语义信息时,往往需要使用基于规则的方法。如果句子中出现“喜欢”、“漂亮”等词则为褒义;如果出现“讨厌”、“丑陋”等词则为贬义。
优点:
- 符合人类的直觉;
- 可解释性、可干预性好;
缺点:
- 知识完备性不足;
- 需要专家构建和维护;
- 不便于计算;
- 规则的表达能力有限;
- 随着规则的增多,规则之间可能存在矛盾和冲突的情况,导致最终无法做出决策。
为了解决基于规则的方法存在的以上诸多问题,基于机器学习的自然语言处理技术应运而生,其最本质的思想 是 将文本表示为向量,其中的每一维代表一个特征 。在进行决策的时候,只要对这些特征的相应值进行加权求和,就可以得到一个分数用于最终的判断。
2. 基于向量表示的统计模型
基于向量表示的统计模型:使用高维、离散、稀疏的向量表示词。
2.1 词的独热表示
在词的独热表示中,维度为词表大小,其中只有一位为1,其余为0。
缺点:
- 严重的数据稀疏问题;
- 无法处理“多词一义”的现象。
为解决上述缺点,**传统的解决方案**如下:
- 增加额外的特征。例如:(1)词性特征:名词、动词、形容词;(2)前后缀特征:re-、-tion、-er;
- 词义词典。例如:(1)WordNet、HowNet等;(2)用词的上位信息表示语义类别;(3)需要解决一词多义的问题;(4)收录的词不全且更新慢。
- 词聚类特征。例如:Brown Clustering(Brown etal,CL 1992)
2.2 词的分布式表示
词的独热表示容易导致数据稀疏问题,而通过引入特征的方法虽然可以缓解该问题,但是特征的设计费时费力。为实现自动提取特征并设置相应的特征值,引入了【词的分布式表示】。
分布式表示: 直接使用【低维、稠密、连续】的向量表示词;
备注:通过“自监督”的方法直接学习词向量。也称“词嵌入(Word Embedding)”
分布式表示的缺点:
- 训练速度慢,增加新语料库困难;
- 不易扩展到短语、句子表示;
| 方法 | 作用 | 涉及技术手段 |
|---|---|---|
| 分布表示的降维 | 避免稀疏性,反映高阶共现关系 | 奇异值分解(Singular Value Decompostion,SVD) |
| 分布表示的加权 | 降低高频词的权重 | 点互信息(Pointwise Mutual Information,PMI) |
2.2.1 分布式语义假设
分布式语义假设: 词的含义可由其上下文的分布进行表示。通过统计文本中【词语共现频次表】实现。
2.2.2 点互信息
点互信息: 为解决高频词误导计算结果的问题,如果一个词与很多词共现,则降低其权重;反之,如果一个词只与个别词共现,则提高其权重。
P
M
I
(
w
,
c
)
=
l
o
g
2
P
(
w
,
c
)
P
(
w
)
P
(
c
)
PMI(w,c)=log_{2}{\frac{P(w,c)}{P(w)P(c)}}
PMI(w,c)=log2P(w)P(c)P(w,c)
式中, P ( w , c ) 、 P ( w ) 、 P ( c ) P(w,c)、P(w)、P(c) P(w,c)、P(w)、P(c)分别是 w w w与 c c c的共现概率,以及 w w w和 c c c分别出现的概率。
可见,通过 P M I PMI PMI公式计算,
- 如果, w w w和 c c c的共现概率(与频次正相关)较高,但是 w w w或者 c c c出现的概率也较高(高频词),则最终的 P M I PMI PMI值会变小;
- 反之,即便 w w w和 c c c的共现概率(与频次正相关)不高,但是 w w w或者 c c c出现的概率也较低(低频词),则最终的 P M I PMI PMI值可能会比较大;
从而较好地解决了高频词误导计算结果的问题。
2.2.3 奇异值分解
奇异值分解: 为解决共现频次无法反映词之间高阶关系的问题。对共现矩阵
M
M
M 进行奇异值分解。
M
=
U
Σ
V
T
M = UΣV^{T}
M=UΣVT
式中,
U
U
U和
V
V
V均为正交矩阵,满足:
U
T
U
=
V
T
V
=
I
U^TU=V^TV=I
UTU=VTV=I;
Σ
Σ
Σ是由
r
r
r个奇异值(Singular Value)构成的对角矩阵。
截断奇异值分解: 若在 Σ Σ Σ中仅保留 d d d个 ( d < r ) (d<r) (d<r)最大的奇异值( U U U和 V V V也保留相应的维度),则被称为【截断奇异值分解(Truncated Singular Value Decomposition)】截断奇异值分解实际上是对
矩阵M的低秩近似。
\quad
通过截断奇异值分解所得到的的矩阵 U U U中的每一行,则为相应词的 d d d维向量表示,该向量一般具有连续、低维和稠密的性质。由于 U U U的各列相互正交,因此可以认为词表示的每一维表达了该词的一种独立的“潜在语义”,所以这种方法也被称为 潜在语义分析(Latent Semantic Analysis,LSA) 。相应地, Σ V T ΣV^{T} ΣVT的每一列也可以作为相应上下文的向量表示。
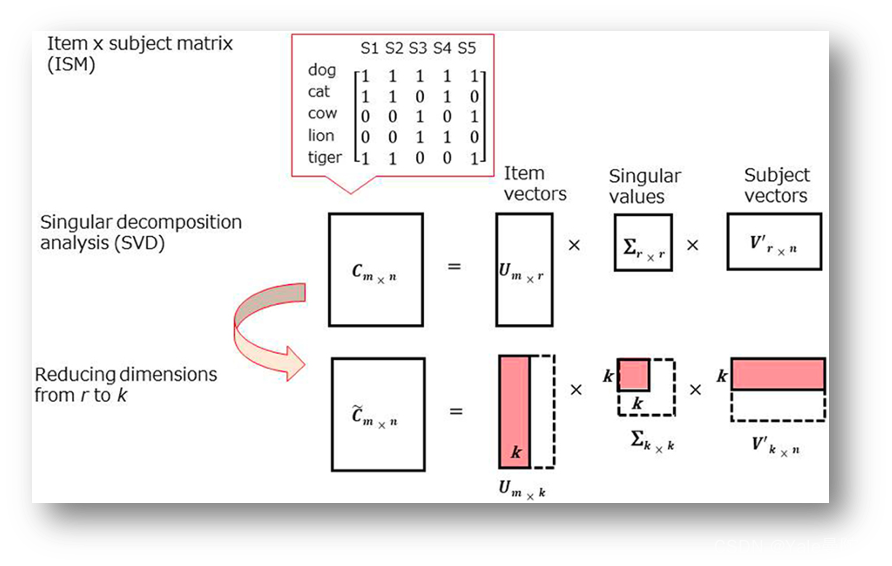
在Python的numpy.linalg库中内置了SVD函数,只需要输入共现矩阵,然后调用相应的函数即可。如:
U, s ,Vh = np.linalg.svd(M_pmi)
- 1
2.3 词嵌入表示
词嵌入表示(Word Embedding): 也是使用一个连续、低维、稠密的向量来表示词,但与分布式表示不同之处在于其赋值方式。
- 在词的分布式表示中,向量值是通过对语料库进行统计得到的,然后再进过点互信息、奇异值分解等变换,一旦确定则无法修改;
- 在词向量中,向量值是随着目标任务的优化过程自动调整的,即:可以将词向量中的向量值看做模型的参数。
参考我的另一篇博文:一、Word Embedding的学习、理解和思考——理论篇
2.4 文本的词袋表示
文本的词袋表示(Bag-Of-Words,BOW): 所谓词袋表示,就是假设文本中的词语是没有顺序的集合,将文本中的全部词所对应的向量表示(既可以是独热表示,也可以是分布式表示或词向量)相加,即构成了【文本的向量表示】。如:在使用独热表示时,文本向量表示的每一维恰好是相应的词在文本中出现的次数。
缺点:
1. 没有考虑词的顺序信息。 导致“张三打李四”和“李四打张三”,虽含义不同,但由于它们包含的词相同,即使词序不同,词袋表示的结果也是一样的。
2. 无法融入上下文信息。 比如:要表示“不 喜欢”,只能将两个词的向量相加,无法进行更细致的语义操作。当然,可以通过【增加词表】的方法加以解决,比如引入二元词(Bigram)词表,将“不 + 喜欢”等作为“词”,然后同时学习二元词的词向量表示。这种方法既能部分解决否定词的问题,也能解决局部词序的问题,但是随着词表的增大,会引入更严重的数据稀疏问题。
五、自然语言处理的评价



