
- 1StarRocks的外部表_starrocks外部表
- 2Redis内存优化——内存淘汰及回收机制_redies内存回收机制是怎样的?
- 3分组统计绘图处理matplotlib
- 4RK3568-input输入子系统_rk3568 input子系统
- 5WebLangChain_ChatGLM:结合 WebLangChain 和 ChatGLM3 的中文 RAG 系统_tavily search
- 6深入理解强化学习——强化学习的例子_深度强化学习已经落地的案例
- 7echarts如何实现3D饼图(环形图)?_echarts环形图3d
- 8【2020年3月】计算机视觉/图像处理方向最新论文速递_forward-looking ground penetrating radar image rec
- 9【Oracle学习】Oracle之多表查询_oracle根据a表统计b表
- 10YOLOv5改进系列(29)——添加DilateFormer(MSDA)注意力机制(中科院一区顶刊|即插即用的多尺度全局注意力机制)
【Hadoop】谷歌的三篇论文(GFS、MapReduce分布式计算模型 、BigTable大表)_谷歌数据库三大论文介绍
赞
踩
谷歌的三篇论文(GFS、MapReduce分布式计算模型 、BigTable大表)
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/118628706(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
- 1
0 谷歌的基本思想:三驾马车
- (1)GFS:Google File System
- Google的分布式文件系统
- (2)MapReduce分布式计算模型
- Google的分布式计算模型:用于解决PageRank问题
- (3)BigTable大表
- 列式存储Hbse的理论基础
谷歌作为一个搜索引擎,每天要爬取巨量的数据,因此需要解决数据的存储问题,于是第一篇文章就是介绍分布式文件系统(这里GFS和之后要讲解的HDFS是有一定的区别的,谷歌的GFS是放在内存上的,而HDFS是放在硬盘上,内存是不安全的,如果内存发生变化,数据就会发生丢失)
然后对于海量数据的运算,谷歌提出了MapReduce分布式计算模型(Java程序),就是面对爬回来的海量数据如何呈现给用户,这里面有一个排序的问题,也就是PageRank问题
最后一篇论文就是BIgTable大表的思想,将数据全部都放在一个表中,不再符合范式,但是会提高数据库性能(需要牺牲空间)
1 第一篇论文:GFS
1.1 Google的GFS分布式文件系统的基本原理
需要弄懂: 为什么这个GFS可以解决海量数据的存储,它的核心原理是什么?(梳理如下图)
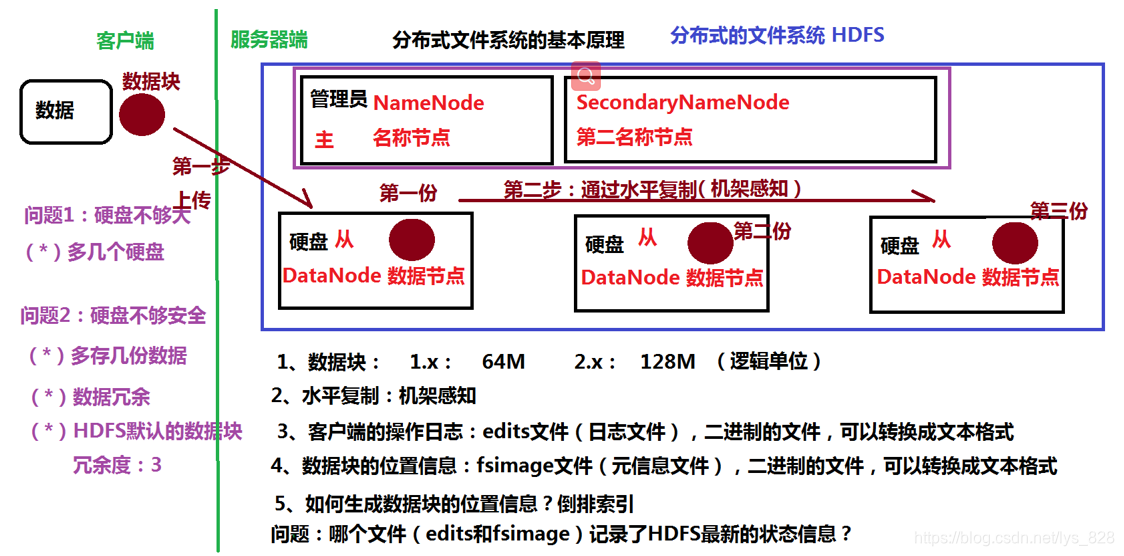 客户端:
客户端:
- 基本需求:需要把数据存放起来,可以是电影、日志、报告等
- (1)空间足够大,放得下我要存放的数据
- (2)保障数据的安全
服务器端:
- 基本功能:提供数据存储的服务
- (1)多个空间存放数据
- (2)设置冗余
第一个需求中,假设要存放的数据是20G,那么一个硬盘只能存放8G,那么我们就可以设置3个硬盘来存放数据,因此就使用了最简单的方式解决数据空间的问题;然后第二个需求,保障数据安全,可能在使用过程中硬盘会发生损坏,因此为了避免数据丢失,就需要进行数据冗余(多存放几份数据,即使其中某一块硬盘坏掉了在其它的硬盘中也有备份),Hadoop中的文件分布式系统HDFS中默认的 数据块 冗余度为3
1.2 HDFS
Hadoop中的文件分布式系统HDFS(Hadoop Distributed File System)就是基于Google的GFS分布式文件系统
1.2.1 节点介绍
在HDFS中除了要进行存储数据块的硬盘外,还应该需要管理员(通俗的理解为除了有干活的人,还有有人来监督干活的人,给他们发工资),其中管理员被称作NameNode(名称节点),并不负责数据的存储(不是真正干活的人),而是接受客户端的请求,监管各个硬盘的状态(是不是存满了,有没有损坏…),最终客户端的请求会以数据块的形式存放入硬盘,硬盘被称作为DataNode(数据节点)
需要提醒一下:理论上只要DataNode无限多,就能实现海量数据的存储,但是对于使用的Apache版本Hadoop,最多包含了4000个节点,这个数量在学习过程中是绝对足够了,如果是在生产运营过程中需要注意这个限制(阿里,华为替代真实的生产环境)
除了NameNode和DataNode外还有一个SecondaryNameNode(第二名称节点),需要特别注意,这个节点并不是NameNode的备份,也就是说当NameNode挂掉之后,SecondaryNameNode不能代替其进行继续工作,如果NameNode挂掉就会造成宕机,存在单点故障的问题(这个单点就是指主节点:NameNode),而NameNode和SecondaryNameNode必须在同一个系统中。具体SecondaryNameNode的作用会在下面的数据块位置信息处介绍
因此要搭建一个全分布的系统,至少需要三台虚拟机,一台是放置NameNode和SecondaryNameNode,本身具有一个DataNode,还有两台仅作为DataNode;如果要搭建一份伪分布系统,也就是需要包含最基础的功能,即含有NameNode、SecondaryNameNode和DataNode,只需要一台虚拟机就可以了
上机操作启动安装好的伪分布系统(下一个博客会系统介绍环境的搭建,这里就是启动查看一下相关节点),查看一下,代码指令:start-dfs.sh
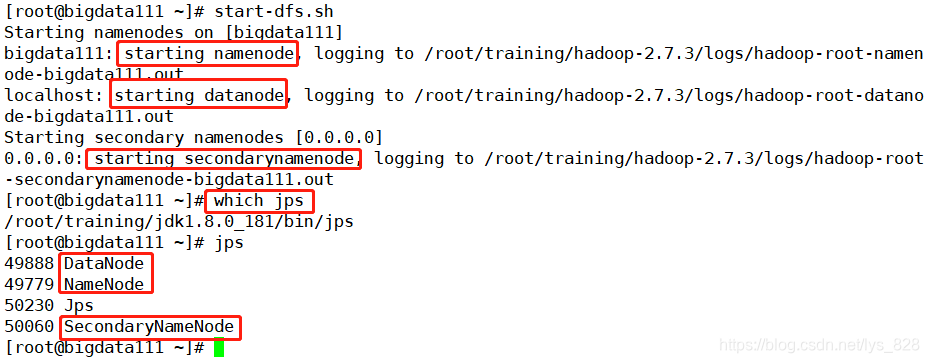
可以看出启动时会同时启动上面刚刚介绍的三个节点,而这三个都是Java进程,可以通过jps查看这三个进程,如果可以看到对应的进程,说明整个伪分布的系统就搭建完毕了。
1.2.2 数据块与机架感知
在Hadoop中提及的是数据块,而不是数据,这里面有什么区别?到底什么是数据块?(很重要,很重要,很重要);更进一步数据冗余又是如何实现呢?
- 数据块大小会随着版本不同。在Hadoop 1.x版本中默认是64m,在2.x和3.x版本中默认是128m。比如客户端请求的数据为200m,那么再进行存放时候就会被进行切分为128m和72m,重要的就是在这个72m如何存储?这时候就体现出数据块的概念了(DataNode是以数据块进行存储),如果数据没有达到一个数据块128m的要求,仍然是以128m进行储存(解释:物理空间占用是本身的大小,但逻辑空间存放是存放在HDFS中是以一个数据块的大小128m)
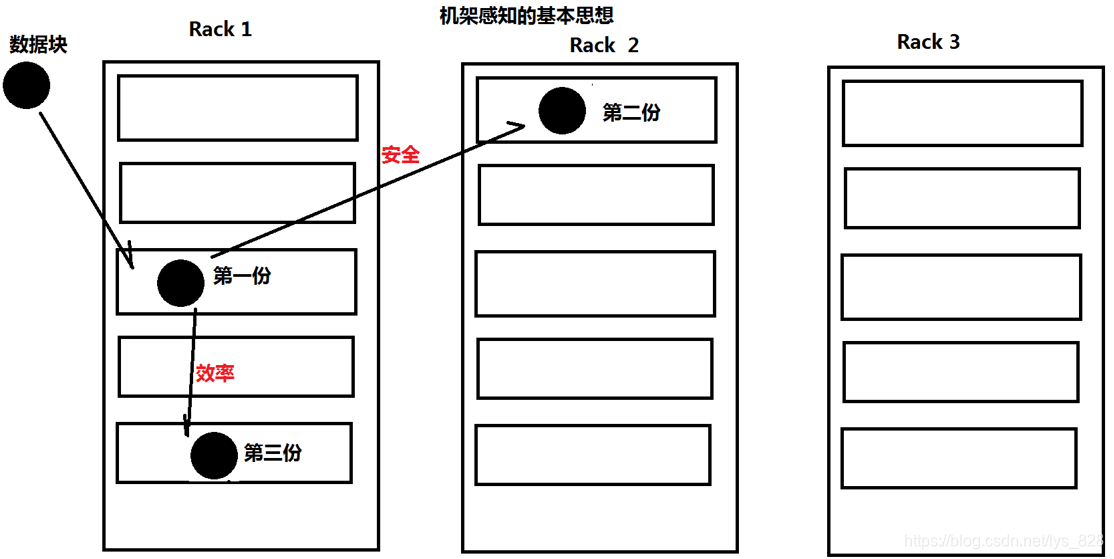
- 数据冗余是通过数据块的水平复制,将上传的数据块复制到多个节点上,从而达到冗余度的要求,具体实现的方式为:机架感知(Hadoop自动实现了这个算法)
机架感知的基本思想:第一份数据块会放置在一个机架中,然后第二份数据块会放在另一个机架,然后第三份会放置在第一份数据块同在的机架。首先为了安全的考虑如果一个机架出现故障,那么整个机架上的服务器全部完蛋,所以第二份优先放置在另一个机架,为了效率的考虑第三份自然要和第一个数据块在一个机架中(如果这个机架中第一份数据块坏掉了,直接可以替换本机架的另一个备份数据块,也就是第三个数据块,从而实现高效)
1.2.3 客户端日志
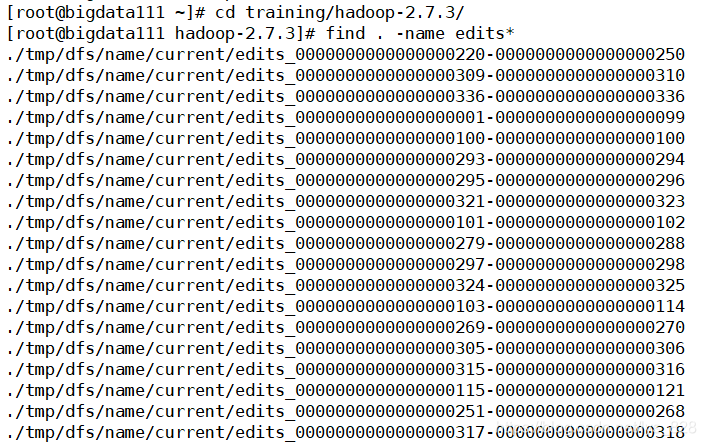
客户端无论是通过命令行还是Java程序,操作HDFS存储数据,必然会产生操作日志,维护操作日志也是一项很重要的工作,客户端日志被记录在edits文件中(被称作日志文件),文件的位置查找如下,cd trainging/hadoop-2.7.3 切换到目标文件目录下后 find . -name edits*查找所有的edits文件。需要注意这些文件都是二进制文件,无法直接查看,但是可以转化为文本格式
1.2.4 数据块位置信息
既然数据块存放在DataNode中,那么需要知道数据块到底存放在哪里的位置,HDFS中将这部分信息存放在fsimage文件中(称作元信息文件,也是二进制文件,同样可以转换为文本格式),该文件类信息也是和edits文件同位置中,因此直接进行查询语句就行了。find . -name fsimage*
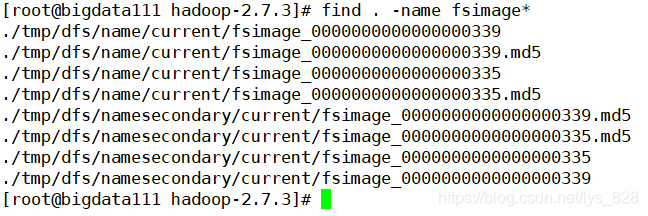
问题:哪个文件(edits和fsimage)记录了HDFS最新的状态信息?
答案就是edits文件,体现了HDFS最新的状态信息,那么就需要有种方式将edits文件中的最新状态写入到fsimage文件中,这个工作就是由SecondaryNameNode完成的,一旦将edits文件中的最新信息合并写入到fsimage文件中时,实际上edits文件就可以进行删除了,但是还是建议在生产环境中保留所有的操作日志,如果有一天fsimage文件发生损坏,都可以通过edits文件进行恢复。
1.2.5 倒排索引
前面介绍了可以通过fsimage文件知道数据块到底存放在哪里的位置,那么就有一个问题,数据块的位置信息是哪里来的呢?也就是如何生成数据块的位置信息?答案就是通过倒排索引
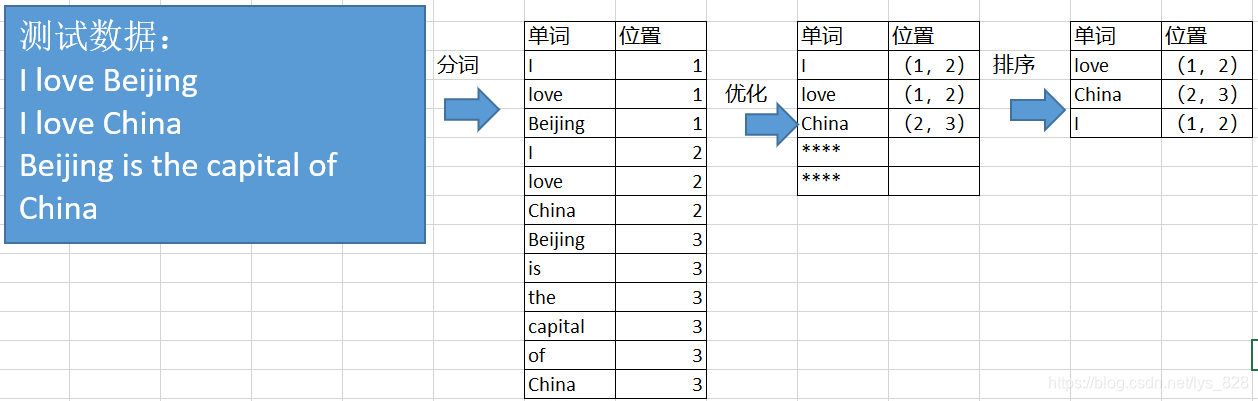
原理解释:首先是准备测试数据如下三句,需要知道单词出现的位置。首先第一步就是将数据进行分词操作,记录每个单词出现在哪个句子中;其次就是可以对第一步的内容进行优化合并,比如 love 这个单词出现在第一句和第二句中,就可以使用括号的方式将出现在所有的位置进行包含,最后就是进一步优化,对第二步获取的数据进行排序,方便索引查找。以上就是整个倒排索引的全过程。
2 第二篇论文:MapReduce分布式计算模型
2.1 MapReduce基本原理
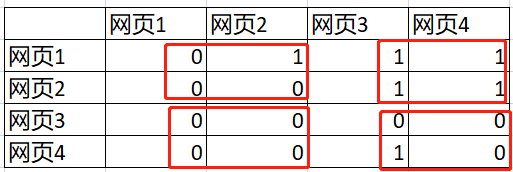
首先第二篇论文发表,主要是解决PageRank的问题,那么到底什么是PageRank,需要详细地了解一下。以四个网页的排序为例,进行讲解

上图中,网页1与剩下三个网页均有连接、网页2连接网页3和网页4,网页4仅连接网页3,网页3没有任何连接,那么如何判断这四个网页的重要程度呢?然后按照重要性程度最高的排在网页搜索结果的最前面。光人眼看这个四个网页可以发现网页3的重要性最高,因为剩下的网页均指向它,但是它没有指向任何网页(有点类似我们搜索一个方法,然后多个网页点进去后都以指向一个参考网页的链接,最后的这个链接才是最终答案所在,故这个网页的重要性最高)。解决的办法就是构建向量矩阵,通过对比每列的权重Rank,就可以判断重要性。
那么接下来问题又来了,虽然上面是通过向量矩阵可以解决这个排名的问题,但是仅仅是举例数据为4个网页,而搜索引擎每天爬取的数据达到亿级以上,那么向量矩阵达到亿 x 亿,这个数量级基本上任何计算机都没有办法完成(未来可能),那么既然是矩阵,通过我们之前大学学的矩阵知识,知道矩阵是可以分块进行运算的,所以这里的处理思想和之前一样,也是采用分块(把任务进行拆解,求出每一个字块的结果,然后在将结果合并成最后一个矩阵,最终求解出结果),比如上面的4 x 4矩阵可以划分成4块,依次计算每一块中的值,然后再计算总值
MapReduce的核心就是:先拆分,后合并
举一个更简单一点的例子,解析MapReduce模型编程,过程如下
为什么要实现Hadoop的序列化接口,其本质就是可以自定义数据类型
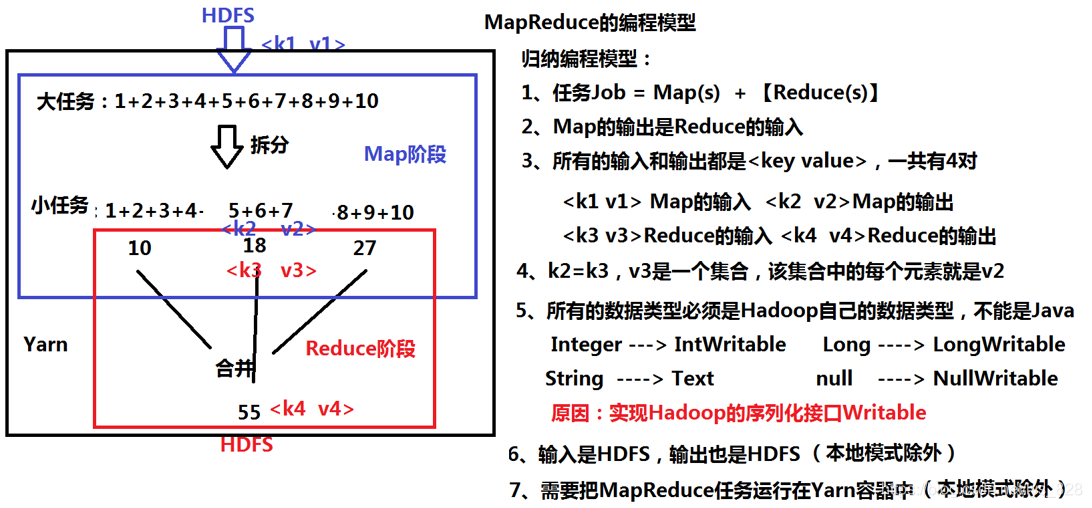
MapReduce分布式计算模型要放置在Yarn容器中,Yarn也是一个主从架构,之前的HDFS中主节点为:NameNode,从节点为:DataNode;在Yarn中,主节点为:ResourceManager,从节点为NodeManager。而DataNode节点和NodeManager这两个节点是在同一台服务器上运行(具体为什么,之后介绍Yarn时候会详细介绍)。
2.2 上机操作
执行代码顺序:
- 查看存在已经上传至HDFS上的data.txt文件:
hdfs dfs -ls /input/data.txt - 查看存在已经上传至HDFS上的data.txt文件:
hdfs dfs -cat /input/data.txt - 切换执行路径:
cd training/hadoop-2.7.3/share/hadoop/mapreduce/ - 查看当前路径:
pwd - 确定当前路径下是否有执行程序的jar包:
ls hadoop-mapreduce-examples-2.7.3.jar - 开启yarn服务:
start-yarn.sh - wordcount程序运行:
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/data.txt /output/0710 - 查看程序是否生成指定文件:
hdfs dfs -ls /output/0710 - 核实指定文件中的数据
hdfs dfs -cat /output/0710/part-r-00000
首先准备最初示例的三句话组成一个文件上传至HDFS(至于怎么上传会在之后的HDFS章节进行介绍),然后切换到可以计算单词计数的jar包所在的路径,找到想要的文件后启动yarn服务。
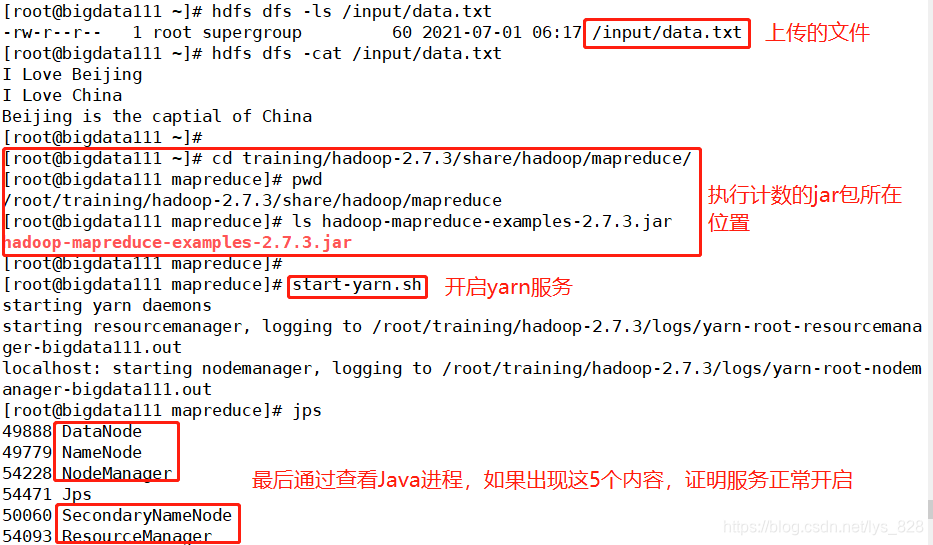
最后执行计数的jar包,这里可以留意一下系统的操作,首先会先去请求ResourceManager节点,然后进行任务的提交,接着提交完毕后,会输出一个一行语句,里面包含了web端的任务处理进度显示
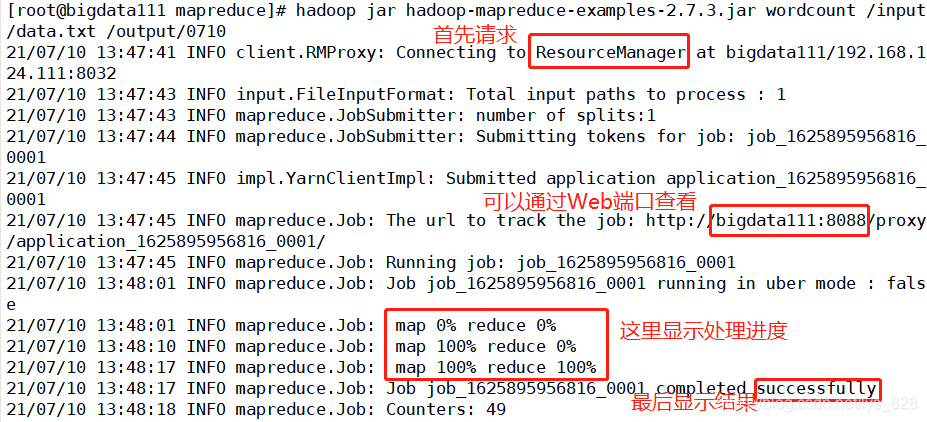
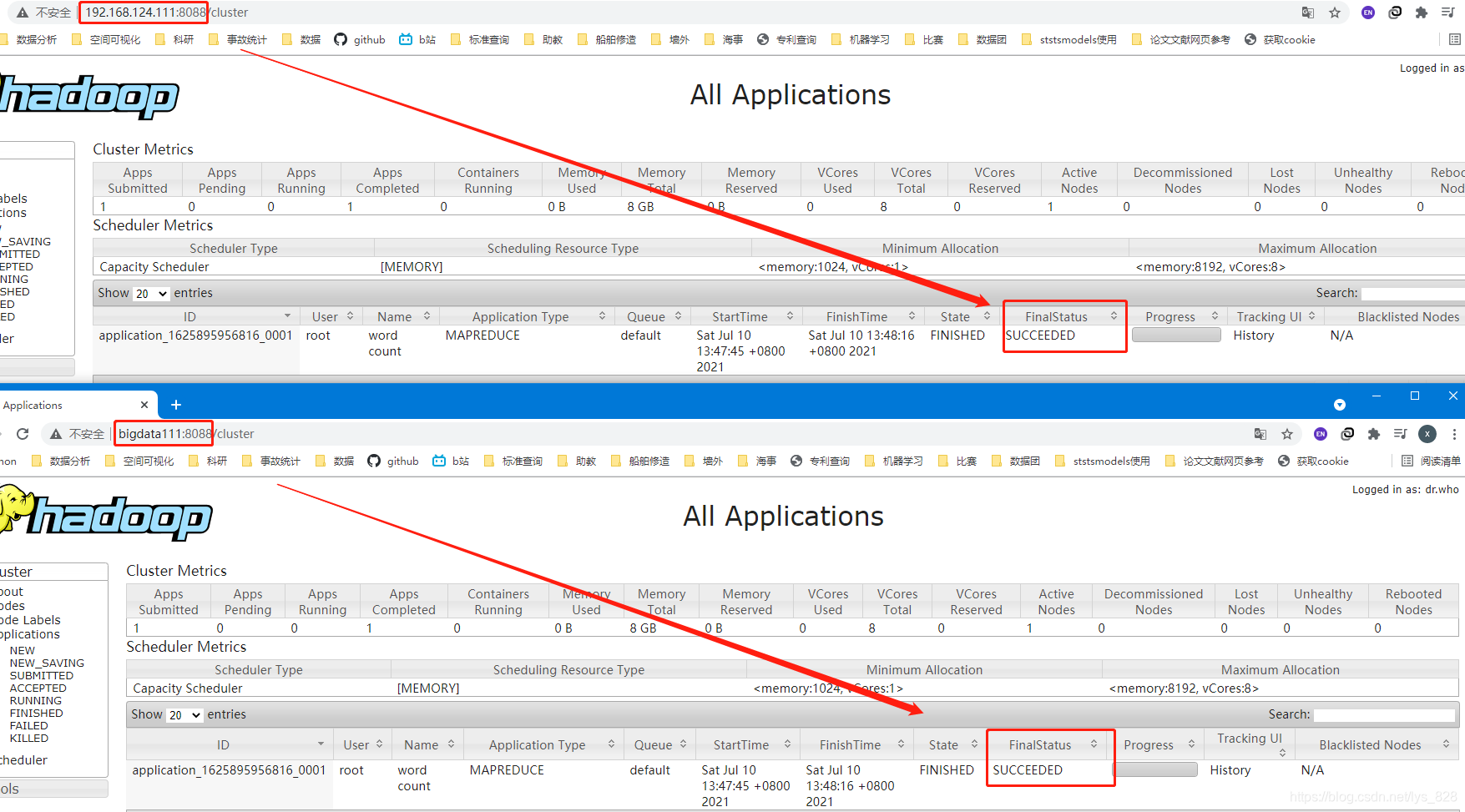
这个url可以直接使用bigdata111:8088也可以使用129.168.124.111:8088在浏览器地址栏进行输入后回车,就可以看到程序处理的进度和最终的结果
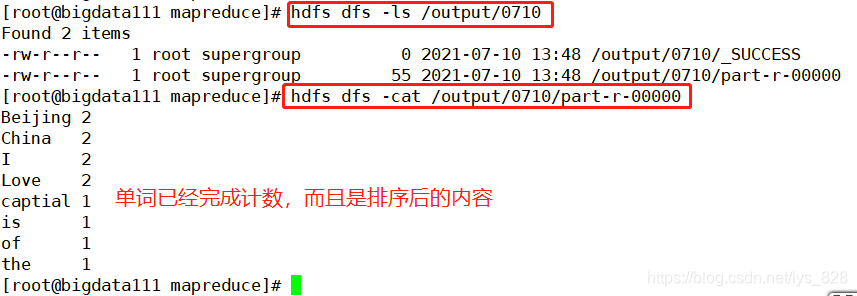
最终可以核实一下是否生成了指定文件和文件中的内容是否为预期结果
3 第三篇论文:BigTable大表
大表就对应着Hadoop中的Hbase
3.1 大表基础理念
大表思想的提出也就有了现在的NoSQL数据库。这里就需要回顾一下以往的SQL关系型数据库,其是基于关系模型提出的数据库。关系模型指的是最终可以使用一张二维表的方式存储数据,所以在关系型数据库中是以行和列的方式存储数据,且要遵循范式的要求。
为什么在关系型数据库中需要遵从范式的要求? 通俗的大白话来讲就是肯定有好处我采取遵守,那么这个优点就是减少数据冗余(多表查询),但是也有缺点,就是数据量大时,性能会受到限制。(通过牺牲性能提高储存的空间,主要是以前的储存介质比较昂贵,储存代价比较高)
为了处理大量数据的情况,就需要提高性能,打破范式,谷歌从而提出了大表的思想,将所有的数据都存放在一张表中。(通过牺牲存储的空间提高性能,现在的储存介质比较低廉)
3.2 大表与传统数据库表结构对比
这里以Orcle数据库为例,对比Oracle的表结构和HBase的表结构,如下
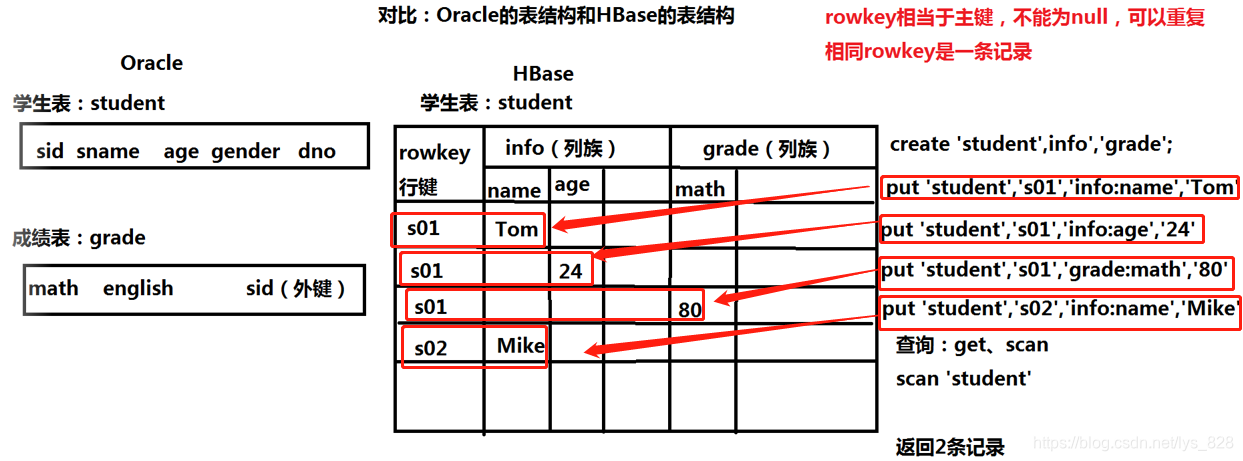
和传统数据库不一致的是,Hbase的表结构是有行键和列族组成,行键可以相同,表示一条记录,插入数据时,如果没有指定字段名称,此时就会自动创建该字段,然后进行数据的写入,最后查询时候由于相同的行键代表一条记录,上述代码查询的结果就为2条记录。
关系型数据库是行式数据库,适合insert update select;HBase是列式数据库,适合做select(大数据中是不谈事务,主要是查询)。

