
- 1BLE蓝牙笔记----数据包解析_pdu type
- 2【❤️考研、期末考、计算机二级❤️】C语言程序设计——第三章最简单的C程序设计 顺序程序设计_c语言程序设计题是怎么做的
- 3LLM-Blender: 用成对排序和生成融合集成大型语言模型_llm-blender: ensembling large language models with
- 4python 字典与集合详解_python 字典是集合
- 5实战Leetcode(四)
- 6MySQL命令行导入数据库_mysql导入数据库命令
- 7浅谈“全栈工程师需要掌握哪些技能”_全栈工程师要学什么
- 8操作系统实验三 观察Linux进程/线程的异步并发执行_并发count值计算
- 9探索未来:MetaSpore - 高效能AI计算框架的革新者
- 10安全笔记:渗透|Metasploit的MSF终端——理论_msf终端功能
【数据结构】常见排序算法——常见排序介绍、插入排序、直接插入排序、希尔排序_数据加密技术的插入排序的概念
赞
踩
1.排序的概念和应用
1.1排序的概念
在计算机科学中,排序是将一组数据按照指定的顺序排列的过程。排序算法由于执行效率的不同可以分为多种不同的算法。
通常情况下,排序算法可以分为两类,即内部排序和外部排序。内部排序是指数据全部加载到内存中进行排序,适用于数据量较小的情况,而外部排序则是指针对数据量较大的情况,需要利用外部存储设备(如磁盘)进行排序。在不同场景下,我们需要选择不同的排序算法来达到最佳的排序效果。
(1)排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
(2)稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
(3)内部排序:数据元素全部放在内存中的排序。
(4)外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
1.2排序的运用
排序算法被广泛应用于计算机程序中,用于对数据进行排序,以便更快、更方便地处理和查询数据。这些应用包括数据库、搜索引擎、数据分析、加密、财务管理、视频处理和游戏开发等领域。
生活中很多地方都会有排序。
1.3常见的排序算法
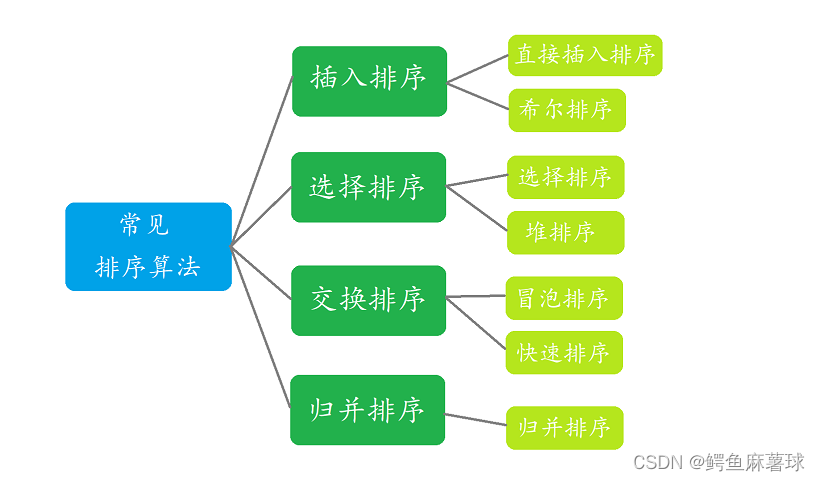
2.常见的排序算法
2.1插入排序
直接插入排序是一种简单的插入排序法,其基本思想是:
插入排序特点:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列。
我们在玩扑克时,就运用到了插入排序:

2.1.1直接插入排序
直接插入排序(Insertion Sort)是一种简单但有效的排序算法,其基本思想是将一个新元素插入到已排序好的元素序列中去。具体实现中,我们从第二个元素开始,将当前元素与前面已排序的元素进行比较,如果当前元素比前一个元素小,则将它插入前一个元素的前面,否则不做处理。如此以往,直到最后一个元素都被放入正确的位置为止。
插入排序属于原地排序,只需要常数级别的额外空间。在处理小规模数据集时比较高效,但在处理大型数据集时会有些效率问题。它的时间复杂度为O(n2)但由于其常数项比冒泡排序和选择排序小,因此实际运行时比这些算法更快。插入排序是一种稳定排序算法,因为在排序过程中不涉及跳跃式的交换,所以相等元素的相对位置不会改变。
直接插入排序实现思想:
当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移。
直接插入排序的实现:
具体来说,这个函数的作用是对传入的数组a进行排序,数组中有n个元素。首先在外层循环中,从数组的第二个元素(索引为1)开始遍历,将其作为当前待排序的元素tmp,同时记录一个end指针指向当前已排序的最后一个元素所在的位置。
在内层循环中,我们将tmp与end所指向的元素比较,如果tmp小于end所指向的元素,则将end所指向的元素后移一位,并向前移动end指针,继续在区间[0, end]中进行比较,直到找到tmp应该插入的位置。
最后,将tmp插入到正确的位置,该插入位置为end + 1。
这样,经过n-1次外层循环的排序操作后,数组a中的元素就按升序排列了。
void InsertSort(int* a, int n) { for (int i = 1; i < n; i++) { int end=i-1; int tmp=a[i]; //将tmp插入到[0,end]区间中,保持有序 while (end >= 0) { if (tmp < a[end]) { a[end + 1] = a[end]; end--; } else { break; } } a[end + 1] = tmp; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
直接插入排序的特性总结:
(1)元素集合越接近有序,直接插入排序算法的时间效率越高;
(2)时间复杂度:O(N^2);
(3)空间复杂度:O(1),它是一种稳定的排序算法;
(4)稳定性:稳定。
2.1.2希尔排序
希尔排序(Shell Sort)是插入排序的一种变体,是一种针对插入排序进行优化的算法,也被称为“缩小增量排序”。希尔排序的基本思想是对待排序的序列进行分组,对于每个子序列应用直接插入排序算法进行排序,逐渐扩大分组的范围,同时逐步缩小增量,直到分组大小为1,完成排序。
希尔排序通过先排序间隔较长的子序列,使得整个序列中的数据基本有序,这样在排序较短的子序列时就可以节省大量时间,从而提高整个排序的效率。希尔排序有许多种不同的递增序列选择方法,不同的算法实现之间可利用不同的增量序列。
希尔排序的时间复杂度与其所选用的增量序列有关,最差情况下为O(n2)平均情况下为O(n1.3)左右。希尔排序属于不稳定排序,因为在大间隔排序时元素的相对位置可能会发生变化。
希尔排序法实现思想:
先选定一个整数,把待排序文件中所有记录分成个组,所有距离为的记录分在同一组内,并对每一组内的记录进行排序。然后,取,重复上述分组和排序的工作。当到达=1时,所有记录在统一组内排好序。
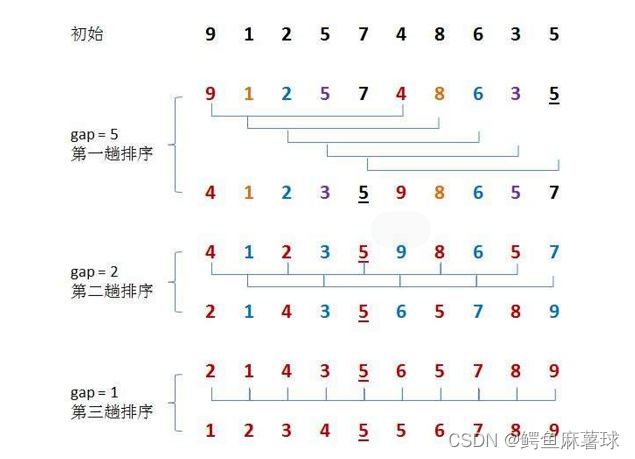
希尔排序的实现:
希尔排序的思想是先取一个间隔gap,将数组a分为若干个长度为gap的子序列,分别对这些子序列进行直接插入排序。然后逐渐缩小gap的值,重复以上操作,直至gap=1时,整个数组排序完成。
代码中使用的增量序列是gap = gap / 3 + 1,也可选择其他增量序列,每次都将gap值缩小,直至其为1时排序结束。对于每个子序列,通过直接插入排序进行排序,不同之处是直接插入排序是对相邻的元素进行插入操作,而希尔排序的插入操作是对相距gap的元素进行插入。
具体来看,对于每个间隔为gap的子序列,我们初始化end为i,记录待插入的元素tmp=a[i+gap],然后将tmp进行插入操作,找到合适的位置,使得end所在位置及之后的元素都向后移动gap个位置。插入排序的结束位置为0,整个操作过程和直接插入排序是类似的。
综上,希尔排序是通过先分组排序后逐步缩小元素间距,以达到提高排序效率的一种排序算法。
void ShellSort(int* a, int n) { int gap = n; while (gap > 1) { //gap = gap/2; gap = gap / 3 + 1; for (int i = 0; i < n - gap; i += gap) { int end = i; int tmp = a[i + gap]; while (end >= 0) { if (tmp < a[end]) { a[end + gap] = a[end]; end -= gap; } else { break; } } a[end + gap] = tmp; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
我们可以简化上面的代码,使其减少一个循环,但复杂度不变:
这段代码是标准的希尔排序的实现。它接受两个参数:一个整型数组a和数组的长度n。其中,数组a是待排序的对象,n表示数组a的元素个数。
标准的希尔排序是将待排序的序列分成若干个子序列,对每个子序列进行插入排序,随后逐渐缩小子序列的长度,直到整个序列排序完成。关键点在于使用不同的增量gap来划分子序列,不同的增量选择方式会影响算法的时间复杂度。
在该代码中,希尔排序的增量序列选择的策略是gap = n/2, n/4, n/8, … 直到gap=1。每次缩小增量gap之后,对每个子序列都进行一次插入排序。这样可以使得每个元素都能够尽可能快地移动到自己的正确位置上,以达到加速排序的目的。
具体来看,每次对一个增量gap的子序列进行直接插入排序,我们选取增量gap之后,通过循环将整个数组分成了gap组。对于每个子序列,通过直接插入排序算法进行排序,在一次希尔排序中,相同的元素可能在多个子序列进行比较和赋值操作。
通过多次迭代,不断缩小增量gap,在进行若干次间隔大的直接插入排序之后,我们最后得到的是一次增量为1的直接插入排序,此时整个序列的排序完成。
综上,标准的希尔排序算法是一种高效的排序算法,其时间复杂度和其所采用的增量序列有关,最优的情况下是O(n*log(n)),最差情况下是O(n^2)。
void ShellSort(int* a, int n) { // gap > 1 预排序 // gap == 1 直接插入排序 int gap = n; while (gap > 1) { //gap /= 2; gap = gap / 3 + 1; for (int i = 0; i < n - gap; i++) { int end = i; int tmp = a[i + gap]; while (end >= 0) { if (tmp < a[end]) { a[end + gap] = a[end]; end -= gap; } else { break; } } a[end + gap] = tmp; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
希尔排序的特性总结:
(1)希尔排序是对直接插入排序的优化。
(2)当gap > 1时都是预排序,目的是让数组更接近于有序。 当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
(3)希尔排序的时间复杂度不好计算, 因为gap的取值方法很多,导致很难去计算,因此在好些树中给出的希尔排序的时间复杂度都不固定。
(4)稳定性:不稳定。
《数据结构(C语言版)》— 严蔚敏

这些就是数据结构中有关直接插入排序和希尔排序的简单介绍了
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

