
- 1《自然语言处理高阶研修》-nlp_adaptive label smoothing with self-knowledge in na
- 22022 年国产编程语言发展总结_国产编程语言发展历程
- 3Mysql 开启ssl连接_require_secure_transport
- 4数据结构四:线性表之带头结点的单向循环链表的设计
- 5渗透测试成长篇-点击劫持漏洞
- 6web前端开发技术 笔记 1_web前端开发技术第三版笔记
- 7Hadoop分布式高可用HA集群搭建笔记(含Hive之构建),java类加载过程面试题_dfs.namenode.http-address.hacluster
- 8Android笔记(二十):JetPack DataStore 之 Proto DataStore_android proto datastore
- 9【USB 3.2 Type-C】 端口实施挑战的集成解决方案 (补充一)
- 1004 Docker练习赛从0开始到 docker 镜像提交
Stable diffusion webui部署及简单使用_linux搭建stable-diffusion-webui
赞
踩
前言
Stable diffusion-webui部署及使用
一、Stable Diffusion WebUI部署
1.Stable diffusion
Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词指导下产生图生图的转变。其源代码和模型权重已分别公开发布在GitHub和Hugging Face,可以在大多数配备有适度GPU的电脑硬件上运行。而以前的专有文生图模型(如DALL-E和Midjourney)只能通过云计算服务访问。
Stable Diffusion是一种扩散模型(diffusion model)的变体,叫做“潜在扩散模型”(latent diffusion model; LDM)。扩散模型是在2015年推出的,其目的是消除对训练图像的连续应用高斯噪声,可以将其视为一系列去噪自编码器。Stable Diffusion由3个部分组成:变分自编码器(VAE)、U-Net和一个文本编码器。与其学习去噪图像数据(在“像素空间”中),而是训练VAE将图像转换为低维潜在空间。添加和去除高斯噪声的过程被应用于这个潜在表示,然后将最终的去噪输出解码到像素空间中。在前向扩散过程中,高斯噪声被迭代地应用于压缩的潜在表征。每个去噪步骤都由一个包含ResNet骨干的U-Net架构完成,通过从前向扩散往反方向去噪而获得潜在表征。最后,VAE解码器通过将表征转换回像素空间来生成输出图像。研究人员指出,降低训练和生成的计算要求是LDM的一个优势。去噪步骤可以以文本串、图像或一些其他数据为条件。调节数据的编码通过交叉注意机制(cross-attention mechanism)暴露给去噪U-Net的架构。为了对文本进行调节,一个预训练的固定CLIP ViT-L/14文本编码器被用来将提示词转化为嵌入空间。
2.Linux 上的自动安装步骤如下:
stable diffusion-webui部署参考:https://github.com/AUTOMATIC1111/stable-diffusion-webui
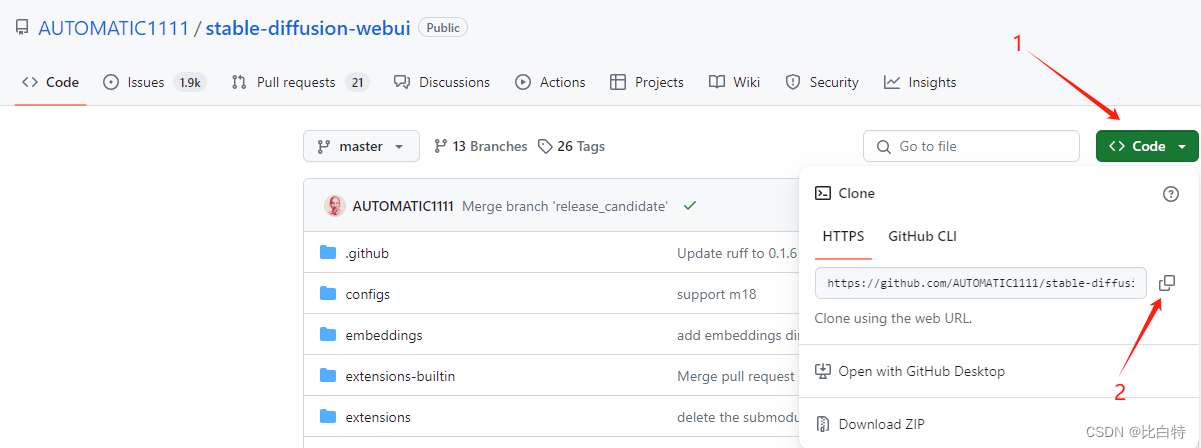
复制后在命令行运行以下代码。(前提是已安装Git工具,参考博文:https://blog.csdn.net/qq_43570821/article/details/136204928)
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
- 1
1.安装依赖项:
# Debian-based:
sudo apt install wget git python3 python3-venv libgl1 libglib2.0-0
# Red Hat-based:
sudo dnf install wget git python3 gperftools-libs libglvnd-glx
# openSUSE-based:
sudo zypper install wget git python3 libtcmalloc4 libglvnd
# Arch-based:
sudo pacman -S wget git python3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.切换到想要安装 WebUI 的目录并执行以下命令:
wget -q https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh
- 1
3.运行 webui.sh
二、使用步骤
1.下载已有模型
模型下载链接:https://huggingface.co/models
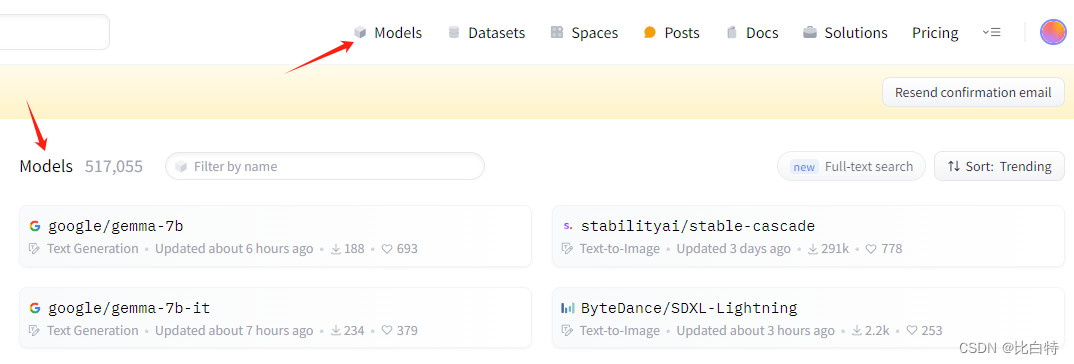
选择自己需要的模型下载
完整下载
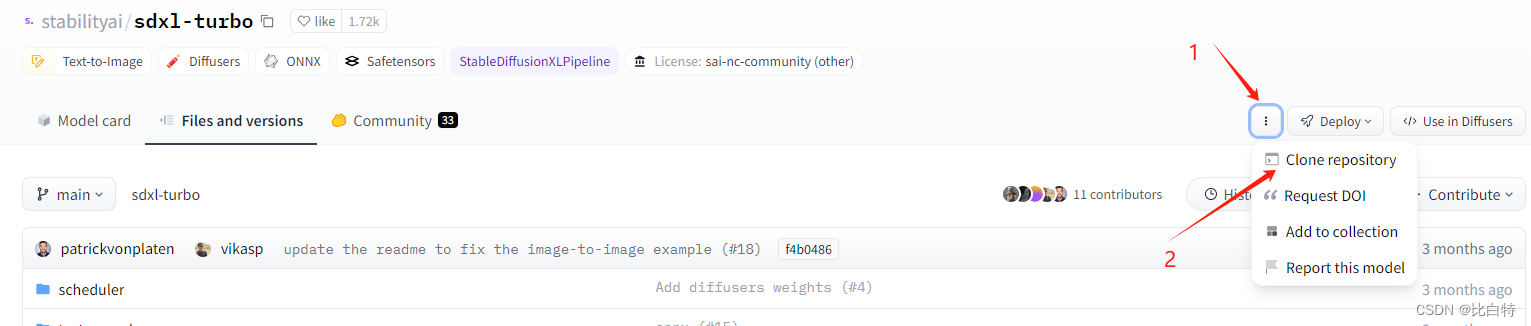
仅下载模型文件
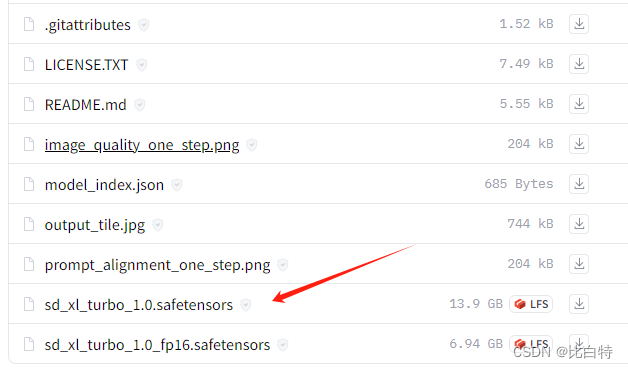
2.启动WebUI
切换到stable-diffusion-webui文件夹,运行以下命令激活venv环境
source venv/bin/activate
- 1
运行bash ./run.sh,在浏览器打开webui界面
3.界面介绍
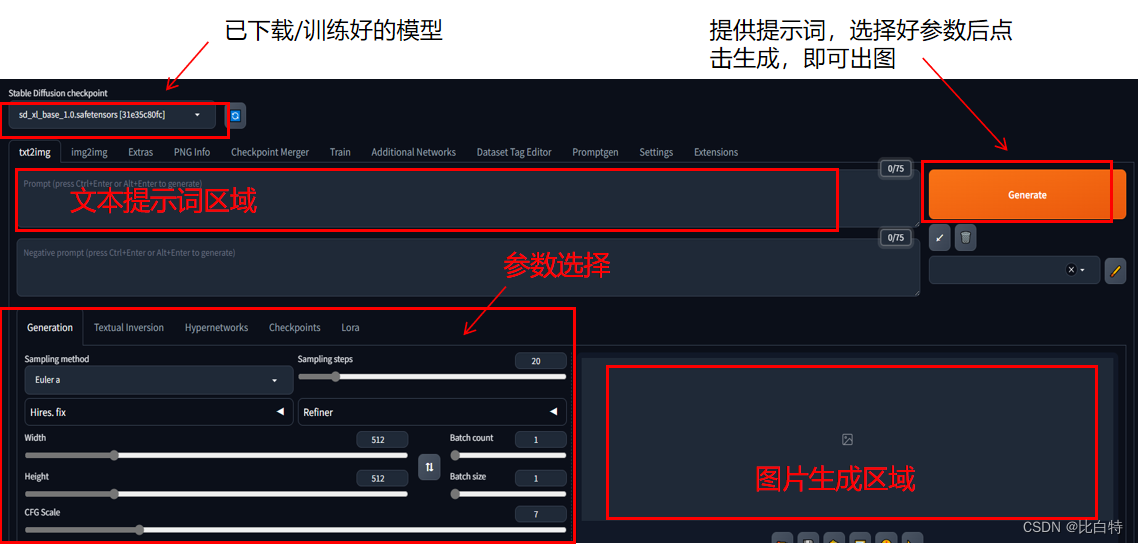

总结
以上就是今天要讲的内容,本文仅仅简单介绍了stable diffusion-webui的使用,后面会进行特定风格的lora模型训练。

