
- 1mssql stuff 使用
- 2AGI:走向通用人工智能的【生命学&哲学&科学】第一篇——生命、意识、五行、易经、量子
- 3[力扣Hot 100------第2题--148.排序链表]_给定两个排序列表l1和l2,计算l1 l2的最快算法具有时间复杂性(nlogn)。
- 4Flask之强大的first_or_404_flask raise 404
- 52024年JAVA招聘行情如何?_2024 java 行情
- 6python爬虫爬取链家二手房信息_爬取链家北京二手房
- 7ElasticSearch教程入门到精通——第二部分(基于ELK技术栈elasticsearch 7.x+8.x新特性)
- 8LangChain(0.0.340)官方文档六:Output parsers_pydanticoutputparser
- 9Android 14 权限_android14 radio.te权限
- 10NLP step by step -- 了解Transformer
数据结构四:线性表之带头结点的单向循环链表的设计
赞
踩
前面两篇介绍了线性表的顺序和链式存储结构,其中链式存储结构为单向链表(即一个方向的有限长度、不循环的链表),对于单链表,由于每个节点只存储了向后的结点的地址,到了尾巴结点就停止了向后链的操作。也就是说只能向后走,如果走过了,就回不去了,还得重头开始遍历,所以就衍生出了循环链表。
目录
一、循环链表的产生原因
在之前学习单链表的时候,我们使用头结点来代表一个链表,可以用O(1)的时间复杂度便可以访问到第一个节点,但是在访问尾巴节点时,需要通过从头开始向后遍历,因此它的时间复杂度为O(n),而循环链表则不同,完全可以使用O(1)的时间来访问第一个节点和尾节点。
相比单链表,循环链表解决了一个很麻烦的问题。 即可以从任意一个结点出发,而不一定是要从头结点出发,就可访问到链表的全部结点,并且访问尾巴结点的时间复杂度也可以达到O(1)。
二、循环链表的基本概念和结构
循环单链表是首尾相连的一种单链表,即将最后一个结点的空指针改为指向头结点形成一个环型。判断单链表为空的条件是 plist->next == NULL,而判断循环单链表为空的条件是 plist->next==plist。
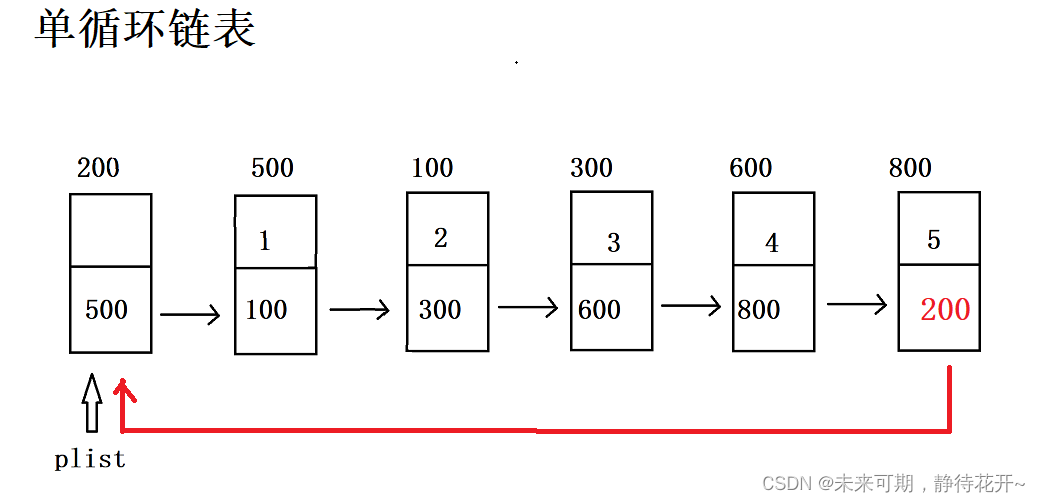
从上图可以看出,带头结点的循环链表与单链表的区别在于:最后一个有效结点的指针域指向头结点(保存头结点的地址), 通过这样的一种方式,使得链表构成一个闭环结构,在单链表中,从一已知结点出发,只能访问到该结点及其后续结点,无法找到该结点之前的其它结点。而在单循环链表中,从任一结点出发都可访问到表中所有结点,这是它的一大优点,遍历尾巴结点的时间复杂度也可以达到O(1)。
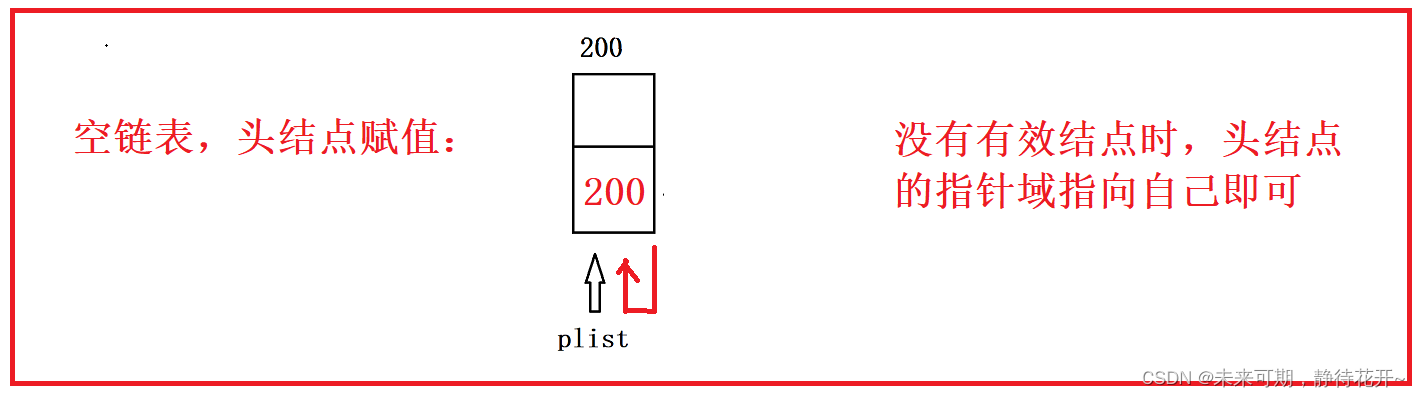
上图是带头结点的单向循环链表为空的情况下的结构,即它不存在有效结点,此时,为了保证它是一个循环结构,头结点的指针域指向它自己(即头结点的指针域保存头结点的地址) ,这也是判断带头结点的单向循环链表为空的一个依据即:plist->next==plist。
三、循环与非循环的对比
3.1 特点
- 若链表为空,则头结点的next结点还是指向其本身,即plist->next==plist;
- 尾节点的next指针指向plist结点,即头尾相连;
- 判断是否遍历了完,直接判断p->next==plist即可;
- 由单链表变化的循环也成为单向循环链表;
- 循环链表的特点是无须增加存储量,仅对表的链接方式稍作改变,即可使得表处理更加方便灵活;
3.2 优势
对单向链表中任一个节点的访问都需要从头结点开始;而对单向循环链表从任意节点出发都能遍历整个列表,极大的增强了其灵活性。其实循环链表和单链表的主要差异就在于循环的判断条件上,原本是判断 p->next 是否为空,现在则是 p-> next 不等于头结点,则循环未结束。
3.3 修改
判断是否为空:
单向链表:如果头结点指向空,那么为空链表(头结点的指针域为NULL)
单向循环链表:如果头结点指向自身,那么为空链表(头结点的指针域为自身)判断是否为尾结点
单向链表:指向空的节点为尾结点(尾结点的指针域为NULL)
单向循环链表:指向头结点的节点为尾结点(尾结点的指针域为头结点)
四、带头结点的单向循环链表的接口函数实现
单循环链表的基本操作也同样有:初始化,头插,尾插,按位置插,头删,尾删,按位置删,查找,按值删,获取有效值个数,判空,清空,销毁,打印。这里详细展示这些基本操作的实现思想和画图分析以及代码实现和算法效率分析,
注意:同样单循环链表与顺序表不同,由于它是按需索取,因此,不需要进行判满和扩容操作;
- //引入必要的头文件
- #include "SeqList.h"
- #include<assert.h>
- #include<stdlib.h>
-
-
- //初始化
- void Init_circlelist(struct CNode *cls);
-
- //头插
- void Insert_head(struct CNode* cls, ELEM_TYPE val);
-
- //尾插
- void Insert_tail(struct CNode* cls, ELEM_TYPE val);
-
- //按位置插
- void Insert_pos(struct CNode* cls, ELEM_TYPE val, int pos);
-
- //头删
- void Del_head(struct CNode* cls);
-
- //尾删
- void Del_tail(struct CNode *cls);
-
- //按位置删
- void Del_pos(struct CNode *cls, int pos);
-
- //按值删
- void Del_val(struct CNode *cls, ELEM_TYPE val);
-
- //查找val值出现的第一次位置
- struct CNode *Search(struct CNode *cls, ELEM_TYPE val);
-
- //获取有效长度
- int Get_length(struct CNode* cls);
-
- //销毁1
- void Destroy1(struct CNode *cls);
-
- //销毁2
- void Destroy2(struct CNode *cls);
-
- //判空
- bool IsEmpty(struct CNode *cls);
-
- //打印
- void Show(PCNode cls);

4.1 单链表结点设计(结构体)
单循环链表结构体设计非常简单,和单链表有效节点结构体设计一样,只需要一个数据域和指针域。
每个结点包括两个部分:存储数据的数据域和指针域(指向下一个结点/存储下一个结点地址的指针)构成。因此设计结点主要设计这两个成员变量。
强调结构体自身引用(自己嵌套自己必须使用struct,即使使用typedef关键字进行重命名)结构体内部不可以定义自身的结构体变量,但是可以定义自身结构体指针变量,因为指针与类型无关,占用内存空间就是4个字节!
- typedef int ELEM_TYPE;
-
- //带头结点的单循环链表
-
- //单循环链表结构体设计
- typedef struct CNode
- {
- ELEM_TYPE data; //数据域 保存节点有效值
- struct CNode *next;//指针域 保存下一个有效节点的地址
- }CNode, *PCNode;
-
-
- //typedef struct CNode CNode;
- //typedef struct CNode* PCNode;
4.2 单循环链表的初始化
单循环链表的初始化主要是对其指针域赋值,数据域不使用,不需要操作!并且此时头结点的指针域应该指向自身,而不是空!!!
- //初始化
- void Init_circlelist(struct CNode *cls)
- {
- //头结点的数据域不使用,不用赋值
- cls->next = cls; //初始化时,链表为空,头结点的指针域指向自身
- }
4.3 头插
循环和非循环单链表的头插法是一样的,不用修改代码。
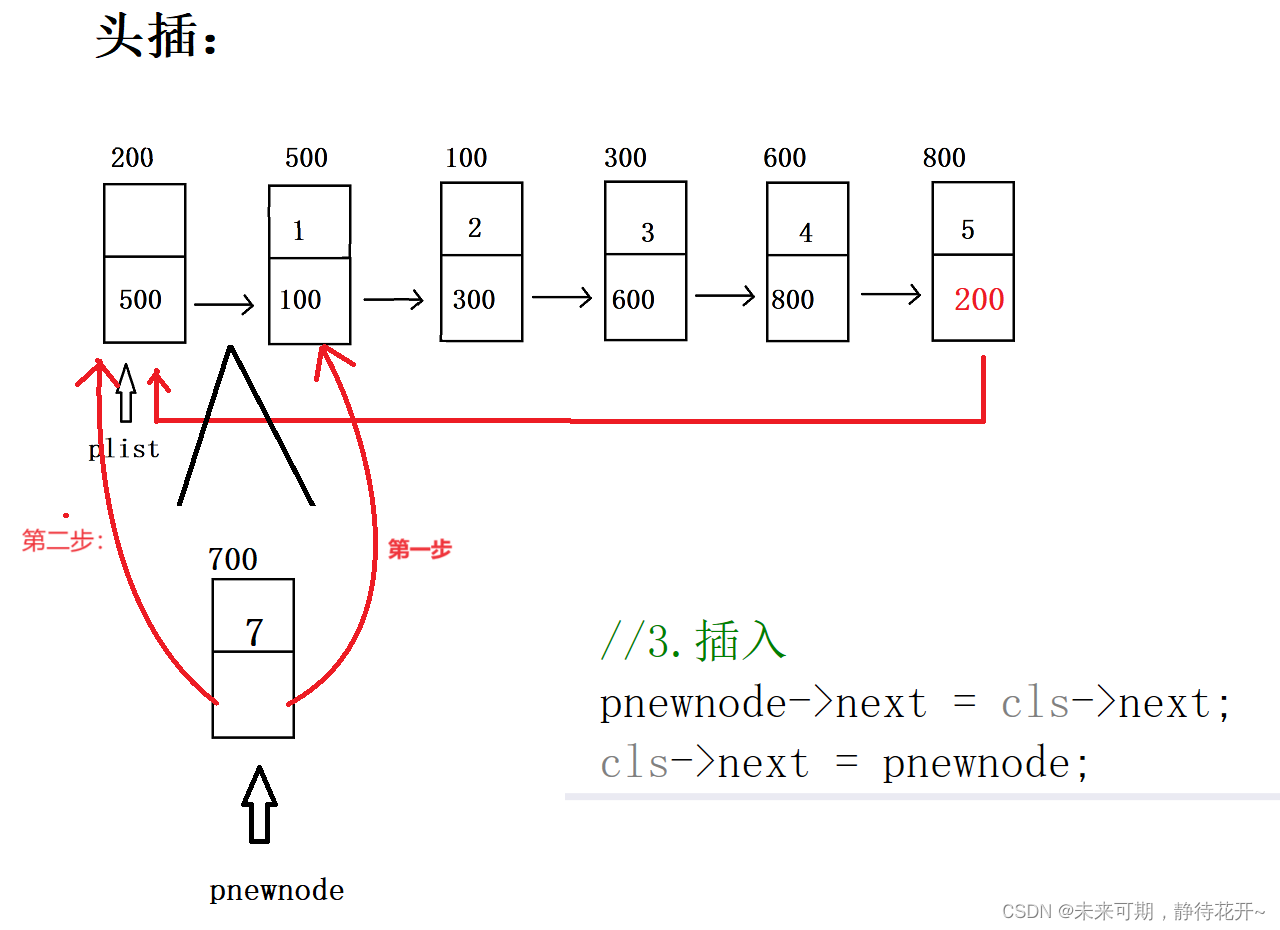
头插的基本思路如下:
第0步:assert对传入的指针检测;
第1步:购买新节点(购买好节点之后,记得将val值赋值进去);
第2步:找到合适的插入位置;
第3步:插入,注意核心代码,先牵右手,再牵左手!!!否则会发生内存泄漏。
- //头插
- void Insert_head(struct CNode* cls, ELEM_TYPE val)
- {
- //0:assert对传入的指针检测
- assert(cls != NULL);
- //1.购买新节点
- struct CNode* pnewnode = (struct CNode*)malloc(sizeof(struct CNode));
- pnewnode->data = val;
-
- //2.找到合适的插入位置(头插,不需要找)
- //因为是头插函数 所以不需要特意的去合适的位置 直接向cls后面插即可
-
-
- //3.插入
- 分两步:先让新购买的节点也指向第一个有效节点,这时,头结点的指针域就可以指向新购买的节点了
- pnewnode->next = cls->next;
- cls->next = pnewnode;
-
- }
4.4 尾插
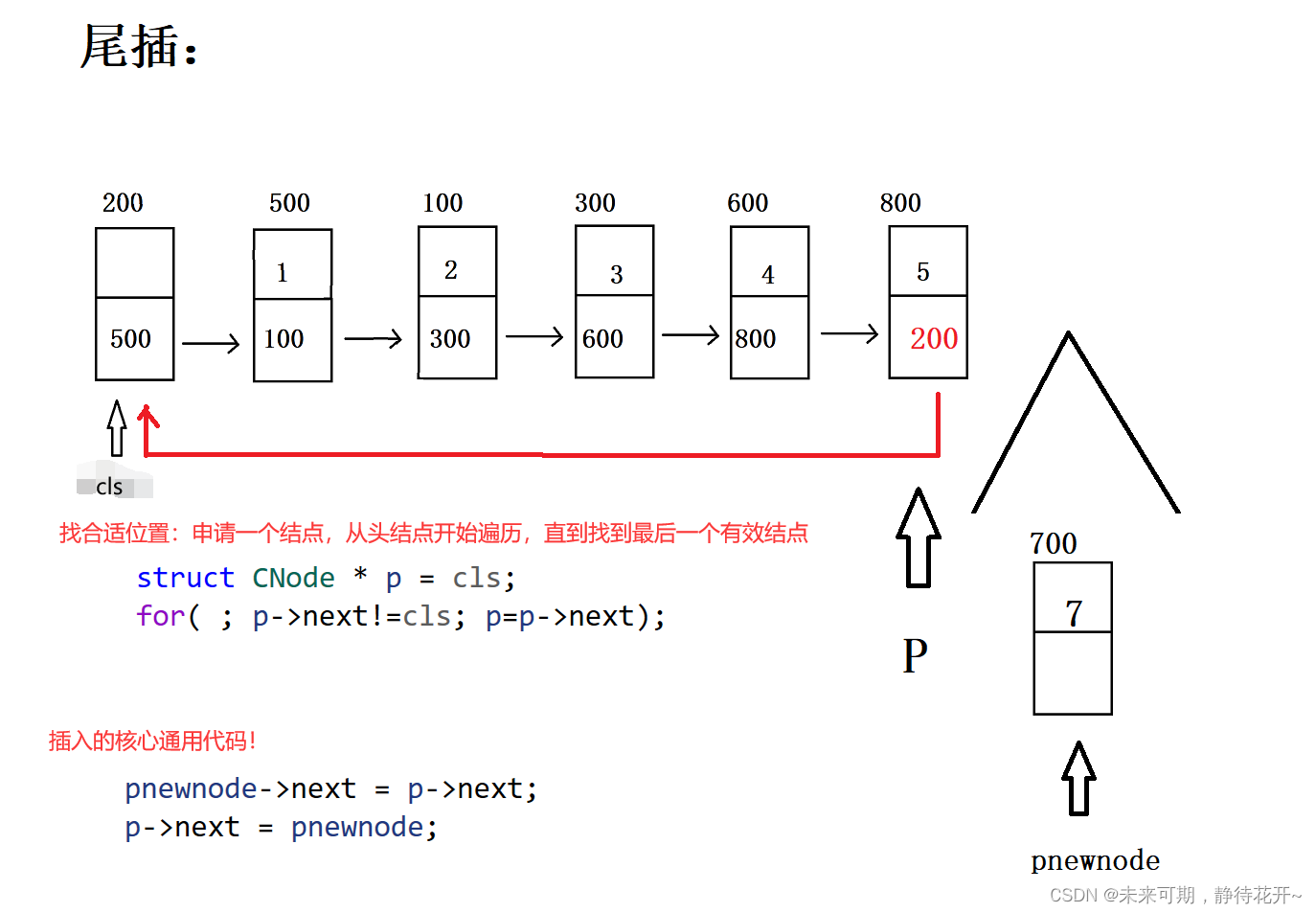
尾插的基本思路如下:
第0步:assert对传入的指针检测;
第1步:购买新节点(购买好节点之后,记得将val值赋值进去);
第2步:找到合适的插入位置,在这里就是找到最后一个有效结点,如何找?因为最后一个有效结点的指针域为头结点,只需要从头开始通过地址,遍历每一个结点,直到遇到最后一个节点,此时指针域指向头结点;与单链表相比,只是尾巴结点的判断条件发生变化。
第3步:利用插入的通用代码!
- //尾插
- void Insert_tail(struct CNode* cls, ELEM_TYPE val)
- {
- //0:assert对传入的指针检测
- assert(cls != NULL);
- //1.购买新节点
- struct CNode *pnewnode = (struct CNode*)malloc(sizeof(struct CNode));
- pnewnode->data = val;
-
- //2.找到合适的插入位置(用最后一个有效节点的next域和头结点的地址做判断)
- struct CNode * p = cls;
- for( ; p->next!=cls; p=p->next); //退出循环时,此时p便指向最后一个有效结点(尾巴结点)
-
- //3.插入
- pnewnode->next = p->next;
- p->next = pnewnode;
- }
4.5 按位置插入
按位置插入的基本思路如下:
第0步:assert对传入的指针和插入的位置检测;要插入的位置必须大于等于零且小于等于 链表总长度。
第1步:购买新节点(购买好节点之后,记得将val值赋值进去);
第2步:找到合适的插入位置,在这里就是找到插入位置的前一个结点,如何找?用指针p指向(例如pos=2,则让临时指针p,从头结点开始向后走pos步)
第3步:利用插入的通用代码!
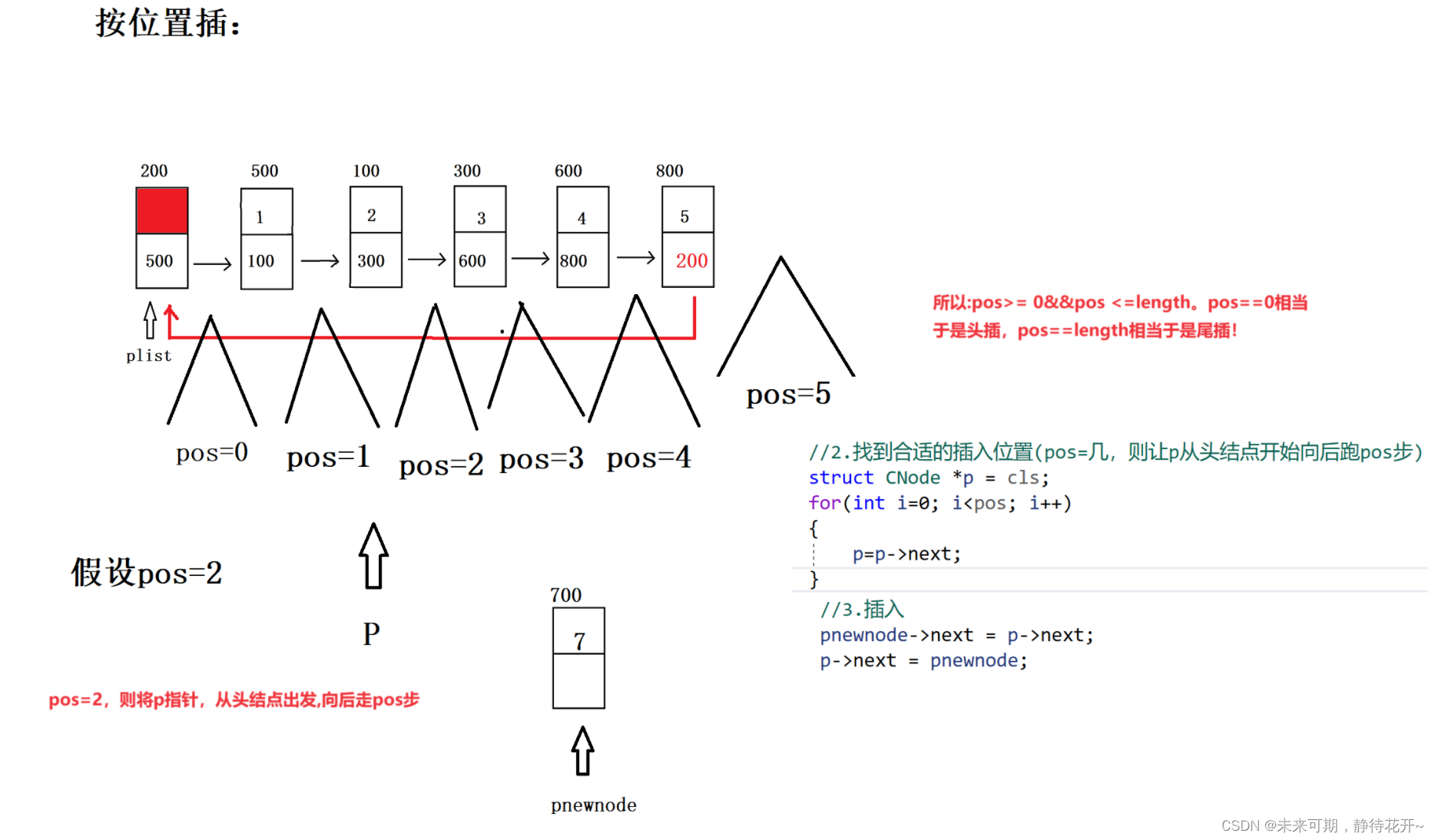
- //按位置插
- void Insert_pos(struct CNode* cls, ELEM_TYPE val, int pos)
- {
-
- //0:assert对传入的指针检测
- assert(cls != NULL);
- assert(pos>=0 && pos<=Get_length(cls));
-
- //1.购买新节点
- struct CNode *pnewnode = (struct CNode*)malloc(sizeof(struct CNode));
- pnewnode->data = val;
-
- //2.找到合适的插入位置(pos=几,则让p从头结点开始向后跑pos步)
- struct CNode *p = cls;
- for(int i=0; i<pos; i++)
- {
- p=p->next;
- }
-
- //3.插入
- pnewnode->next = p->next;
- p->next = pnewnode;
-
-
- }
4.6 头删
对于删除操作,则需要对链表进行判空操作!并且删除操作遵循基本同样的4个步骤,需要理解加记忆。删除操作的基本思路如下:
①:用指针q指向待删除节点;
②:用指针p指向待删除节点的前驱节点;(头删的话,这里p可以被plist代替)
③:跨越指向;
④:释放待删除节点。
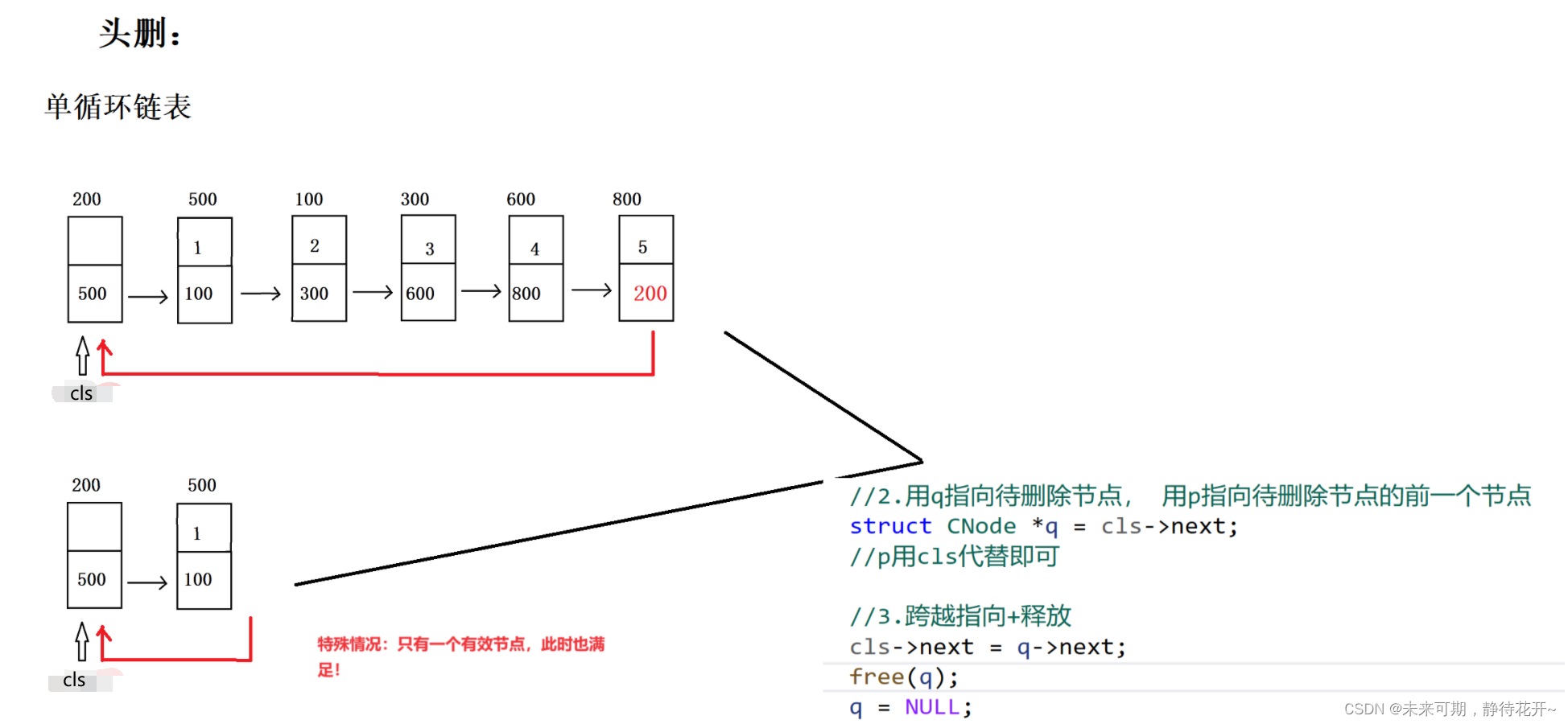
- //头删
- void Del_head(struct CNode* cls)
- {
- //0:assert对传入的指针检测
- assert(cls != NULL);
- //1.判空
- if(IsEmpty(cls))
- {
- return;
- }
-
- //2.用q指向待删除节点, 用p指向待删除节点的前一个节点
- struct CNode *q = cls->next;
- //p用cls代替即可
-
- //3.跨越指向+释放
- cls->next = q->next;
- free(q);
- q = NULL;
- }
4.7 尾删
尾删的基本思路还是那四个步骤,只是具体实现的方式不一样。与单链表相比,只是尾巴节点的判断条件发生变化。
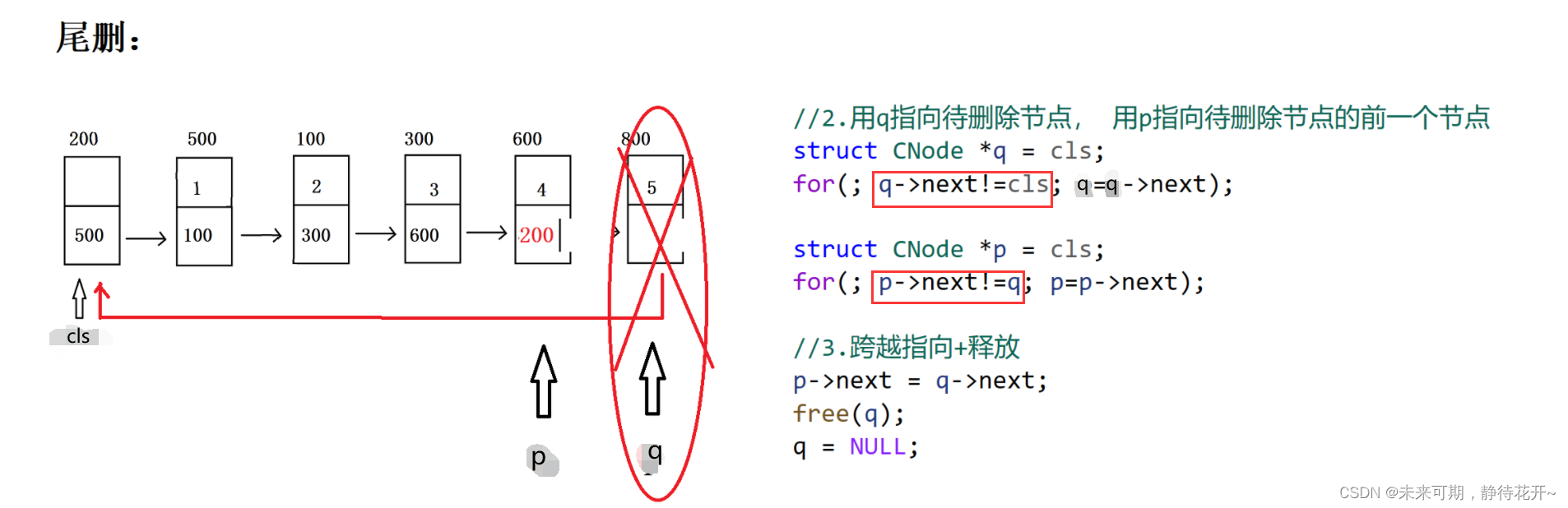
- //尾删
- void Del_tail(struct CNode *cls)
- {
- //0:assert对传入的指针检测
- assert(cls != NULL);
- //1.判空
- if(IsEmpty(cls))
- {
- return;
- }
-
- //2.用q指向待删除节点, 用p指向待删除节点的前一个节点
- struct CNode *q = cls;
- for(; q->next!=cls; p=p->next);
-
- struct CNode *p = cls;
- for(; p->next!=q; p=p->next);
-
- //3.跨越指向+释放
- p->next = q->next;
- free(q);
- q = NULL;
- }
4.8 按位置删除
根据位置删除结点,需要判断结点的合法性,这次的pos需要小于链表长度,基本思路还是那四个步骤,只是具体实现的方式不一样。
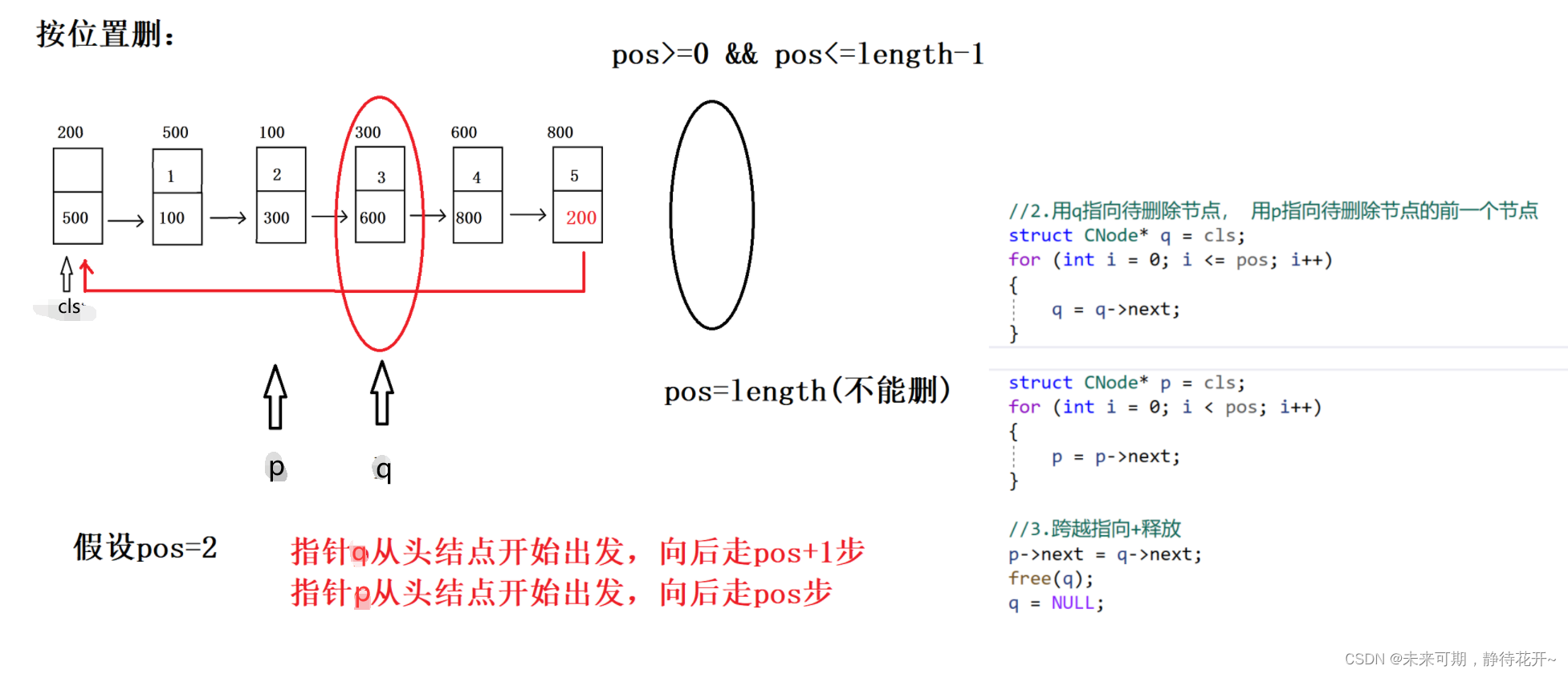
- //按位置删
- void Del_pos(struct CNode *cls, int pos)
- {
- //0:assert对传入的指针检测
- assert(cls != NULL);
- //0.5 pos做合法性判断
- assert(pos>=0 && pos<=Get_length(cls)-1);
-
- //1.判空
- if(IsEmpty(cls))
- {
- return;
- }
-
- //2.用q指向待删除节点, 用p指向待删除节点的前一个节点
- struct CNode *q = cls;
- for(int i=0; i<=pos; i++)
- {
- q = q->next;
- }
-
- struct CNode *p = cls;
- for(int i=0; i<pos; i++)
- {
- p = p->next;
- }
-
- //3.跨越指向+释放
- p->next = q->next;
- free(q);
- q = NULL;
-
- }
4.9 按值删
按值删需要先找到数据域是该值的结点,然后将其删除,基本思路还是那四个步骤,只是具体实现的方式不一样。
- //按值删
- void Del_val(struct CNode *cls, ELEM_TYPE val)
- {
- //0:assert对传入的指针检测
- assert(cls != NULL);
-
- //1.判空
- if(IsEmpty(cls))
- {
- return;
- }
-
- //调用函数找该值,返回对应的结点
- struct CNode* q = Search(cls, val);
-
- //进行判断是否存在该结点
- if(q == NULL)
- {
- return;
- }
-
- //2.找到合适位置,待删除结点的前一个结点
- struct CNode * p = cls;
- for(; p->next!=q; p=->next);
-
- //3.跨越指向+释放
- p->next = q->next;
- free(q);
- q = NULL;
- }
4.10 查找
按值查找,返回该值的结点,查找操作只需要定义一个临时结点类型指针变量,让它从第一个有效节点开始遍历,只要结点存在就往后遍历。这里的循环条件:p!=cls,意思是从第一个有效节点遍历到最后一个结点(只要结点存在,就往后走),与单链表相比,只是尾巴节点的判断条件发生变化。
- //查找val值出现的第一次位置
- struct CNode *Search(struct CNode *cls, ELEM_TYPE val)
- {
- //0:assert对传入的指针检测
- assert(cls != NULL);
-
- //1.从第一个有效节点开始向后遍历
- struct CNode *p = cls->next;
- for( ; p!=cls; p=p->next)
- {
- if(p->data == val)
- {
- return p;
- }
- }
- return NULL;
- }
4.11 获取有效值个数
只需要定义一个临时结点类型指针变量,让它从第一个有效节点开始遍历,只要没有到最后一个结点就往后遍历。 采用计数器思想,计数器加1,返回计数器变量即是有效结点个数。与单链表相比,只是尾巴节点的判断条件发生变化。
- //获取有效长度
- int Get_length(struct CNode* cls)
- {
- //0:assert对传入的指针检测
- assert(cls != NULL);
-
- //1.从第一个有效节点开始向后遍历
- struct CNode *p = cls->next;
- int count = 0;
-
- for( ; p!=cls; p=p->next)
- {
- count++;
- }
-
- return count;
- }
4.12 判空
在进行删除操作时,需要对链表进行判空操作,如果链表为空,则无法删除!!如何判断链表为空?在链表只有一个头结点时,代表链表为空,此时就是最初始的状态,只有一个头结点,并且头结点的指针域为它自己(指向它自己),因此,只需要判断头结点的指针域是否为自身,便可以知道链表是否为空。与单链表相比,只是空链表的判断条件发生变化。
-
- //判空
- bool IsEmpty(struct CNode *cls)
- {
- //0:assert对传入的指针检测
- assert(cls != NULL);
-
- return cls->next==cls;
- }
4.13 销毁
第一种:无限头删
只要链表不为空,一直调用头删函数,直到把所有结点删除完,此时,退出循环。
- //销毁1
- void Destroy1(struct CNode *cls)
- {
- //0:assert对传入的指针检测
- assert(cls != NULL);
-
- while(!IsEmpty(cls))
- {
- Del_head(cls);
- }
- }
第二种:不借助头结点,但是需要两个指针变量p和q(双指针思想)。与单链表相比,只是空链表的判断条件发生变化。
- //销毁2
- void Destroy2(struct CNode *cls)
- {
- struct CNode *p = cls->next;
- struct CNode *q = NULL;
-
- cls->next = cls;
-
- while(p != cls)
- {
- q = p->next;
- free(p);
- p = q;
- }
-
-
- }
4.14 打印
只需要定义一个临时结点类型指针变量,让它从第一个有效节点开始遍历,只要没有到最后一个结点就往后遍历,同时打印结构体的数据域成员。
- //打印
- void Show(PCNode cls)
- {
- //0:assert对传入的指针检测
- assert(cls != NULL);
-
- struct CNode *p = cls->next;
-
- for( ; p!=cls; p=p->next)
- {
- printf("%d ", p->data);
- }
-
- printf("\n");
- }
五、总结
单向循环链表的插入,删除算法与单链表基本一致,所不同的是若操作在链表的尾部进行,则判断条件发生变化不同,以让单链表继续保持循环的性质。因此,需要记住循环链表判空和判断是否为尾巴结点的条件!即循环链表中没有NULL指针。涉及遍历操作时,其终止条件就不再是像非循环链表那样判别p或p->next是否为空,而是判别它们是否等于某一指定指针,如头指针或尾指针等。
以上便是我为大家带来的带头结点的单向循环链表设计内容,若有不足,望各位大佬在评论区指出,谢谢大家!可以留下你们点赞、收藏和关注,这是对我极大的鼓励,我也会更加努力创作更优质的作品。再次感谢大家!

