
在进行大型网站的web开发时,分布式这个词经常出现在我们面前。如:
- memcache、redis服务器等缓存服务器的负载均衡(分布式cache),
- MySQL的分布式集群(分布式DB),
- 大量session的共享存储(分布式文件,或session服务器等),
这些都会用到分布式的思想,究其根源,都要理解分布式算法。原谅我扯这么一堆才扯出本文的主题,一致性哈希算法。接下来以缓存服务器的负载均衡来谈一下一致性哈希算法。
传统算法缺陷
对于服务器分布,我们要考虑的东西有如下三点:数据平均分布,查找定位准确,降低宕机影响。
传统算法一般是将数据的键用算法映射出数字,对其用服务器数量取模,并根据结果选择要存储的服务器。其能达到数据平均分布和查找定位准确的要求,并且优点是算法简单,存取时的计算量都比较小(在数据非常大时才会明显)。
但其有一个致命缺点,即一个服务器宕机后的影响很大,我们可以推算一下一台服务器宕机后的影响:
- 原有数据大部分丢失:服务器数量减少一台,取模数减1导致取模值错乱,如果以前有N台服务器,那么宕机后数据只有1/(n*(n-1))的数据能够被准确查找到。
- 负载无法均衡导致集体宕机:如果没有及时处理宕机的服务器,那么他的存储任务将会被顺序积累给它的下一个服务器,那么下一个服务器也会很快被压致宕机,如此一来,服务器组很快会集体宕机。
算法思想
一致性哈希算法是使用一定的哈希算法,将大量的数据平均映射到不同的存储目标上,在保证其查找准确性的同时,还要考虑其中一个存储目标失效时,其他存储目标对其责任存储内容的负载均衡。
一致性哈希算法的实现思想不难理解,如图:
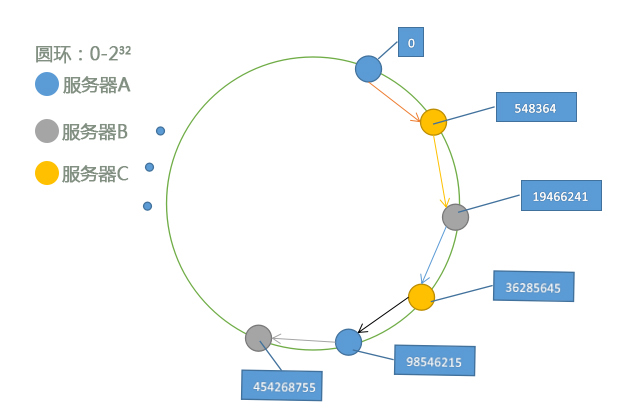
- 用一定的哈希算法(哈希函数等)将一组服务器的多个(数目自己设定)节点随机映射分散到0-232之间,由于其随机分布,保证了其数据平均分布的特点;
- 用同一算法计算要存储数据的键,根据服务器节点确定其存储的服务器结点,由于每次用同一算法计算,所以得出的结果是相同的,使其查找定位准确;
- 查找数据时,再次用同一算法计算键,并查找服务器的数据结点;
- 如果有一个服务器宕机,消除其服务器结点,并将数据放在下一个结点上,由于随机节点位置的随机性,所以数据被其他服务器平均负载,也就降低了宕机影响。
需要注意的是,这个环形空间只是一个虚拟空间,只是表示了服务器存储的范围和数据的落点,在进行存储时,我们还要通过查找到的落点,将数据放入对应的服务器进行查改。
算法实现
编程语言我们使用PHP来实现一致性哈希算法:
我们主要用到以下函数:
int crc32 ( string $str )
生成 str 的 32 位循环冗余校验码多项式。这通常用于检查传输的数据是否完整。string sprintf ( string $format [, mixed $args [, mixed $... ]] )
通过传入的格式产生字符串的特定格式形态。
实现如下:
- class Consistance
- {
- protected $num=24; //设定每一个服务器的节点数,数量越多,宕机时服务器负载就会分布得越平均,但也增大数据查找消耗。
- protected $nodes=array(); //当前服务器组的结点列表。
-
- //计算一个数据的哈希值,用以确定位置
- public function make_hash($data)
- {
- return sprintf('%u',crc32($data));
- }
-
- //遍历当前服务器组的节点列表,确定需要存储/查找的服务器
- public function set_loc($data)
- {
- $loc=self::make_hash($data);
- foreach ($this->nodes as $key => $val)
- {
- if($loc<=$key)
- {
- return $val;
- }
- }
- }
-
- //添加一个服务器,将其结点添加到服务器组的节点列表内。
- public function add_host($host)
- {
- for($i=0;$i<$this->num;$i++)
- {
- $key=sprintf('%u',crc32($host.'_'.$i));
- $this->nodes[$key]=$host;
- }
- ksort($this->nodes); //对结点排序,这样便于查找。
- }
-
- //删除一个服务器,并将其对应节点从服务器组的节点列表内移除。
- public function remove_host($host)
- {
- for($i=0;$i<$this->num;$i++)
- {
- $key=sprintf('%u',crc32($host.'_'.$i));
- unset($this->nodes[$key]);
- }
- }
- }
我们用以下代码进行测试:
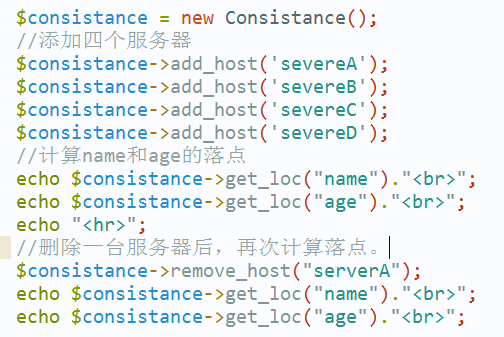
结果如下:

小结
算法的实现到此,我们还可以对算法进行优化,如在服务器数量和每个服务器节点数都很多的情况下,对查找结点的过程进行优化,因为排序好的,可以用二分法进行查找,加快查询效率,这些,仁智各见吧。
另外,虽然nginx服务器有一致性算法的插件,memcache和redis也都有相应的插件,MySQL的中间件有相应的集成,但是了解一致性哈希算法也很有意义。而且,我们也可以对其灵活使用,如对文件等进行分布式管理等等。
如果您觉得本博文对您有帮助,您可以推荐或关注我,如果您有什么问题,可以在下方留言讨论,谢谢。

