
- 1RK3399linux交叉编辑器下载,ubuntu下交叉编译X264和FFMPEG到RK3399平台(编译器:aarch64-linux-gcc)...
- 2人工智能为什么可以准确回答问题而不依赖数据库呢?_机器人对答是数据库
- 3有哪些好用不火的软件?_实验楼怎么样csdn
- 4PolarDB 卷来卷去 云原生低延迟强一致性读 1 (SCC READ 译 )
- 5FLASH问题答疑
- 6基于GPT-3.5的AI机器人:源码与脚本详解大数据任务提交和执行_ai3.5在线机器人
- 7无人机摄影测量数据处理、三维建模及在土方量计算中的应用_像空点
- 8【gitlab部署】centos8安装gitlab(搭建属于自己的代码服务器)
- 9【MySQL精通之路】全文搜索-布尔型全文搜索
- 10物联网主干组网之全IP光网络_光传输组网原理
大模型在线推理优化:GPU资源和推理框架如何选择?
赞
踩
▼最近直播超级多,预约保你有收获

—1—
大模型在线推理 GPU 资源如何选择?
大模型在线推理需要多少 GPU 资源,取决于大模型本身的参数,计算公式为:部署显存(单位 GB )= 参数量(单位 B)* A。(A 为参数精度,参数精度 FP32时 A=4,参数精度 FP16时 A=2)。
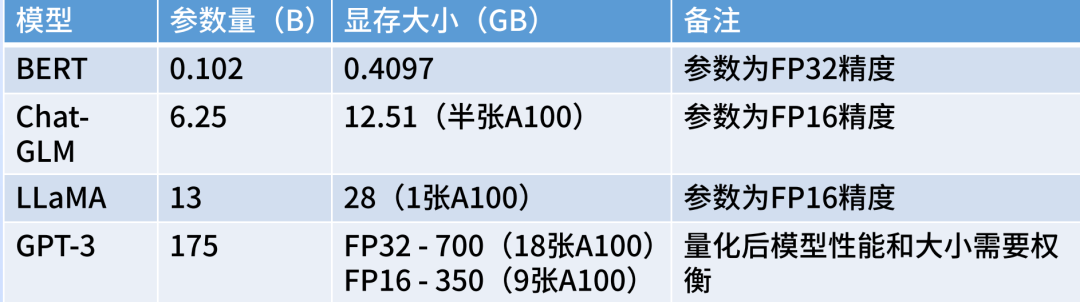
在 ChatGLM-6B 大模型上实测,显存推算基本符合上述计算公式。
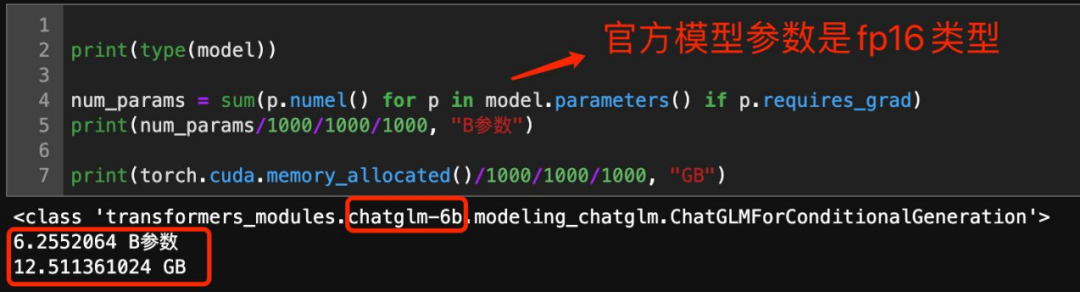
目前市场上常见的大模型参数规模有7B、13B、34B、72B、130B、176B、260B等(1B=10亿)。
那么市场上可以批量供给的 GPU 卡包括:英伟达 H20、L20、A10,国产 AI 芯片华为昇腾 910、昆仑芯 XPU 2代等。当然还有存量的英伟达 A800、H800、A30 等 GPU 卡可用于大模型在线推理服务。
在业务场景中大模型的在线推理服务大都是 OLTP 场景,需要实时响应,才能够满足业务的时延需求(比如:搜索、推荐等场景)。大模型的推理首 token 时延(time to first token)要求1秒以内,甚至毫秒级。这样的实时在线场景都是显存I/O速度受限(Memory-Bound)的。也就是说需要首先优化大模型的响应速度,而大模型的在线推理吞吐量(throught,tokens per second)不是首要目标(当然业务每秒上万并发或者10万并发除外)。除了首 token 时延,大模型在线推理服务也需要关注尾 token 时延(即完成一次会话响应的时延),站在业务的使用角度,大模型在线推理的 Response 响应越快越好。
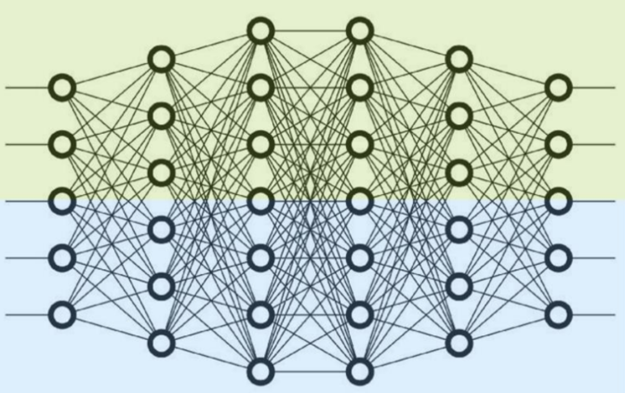
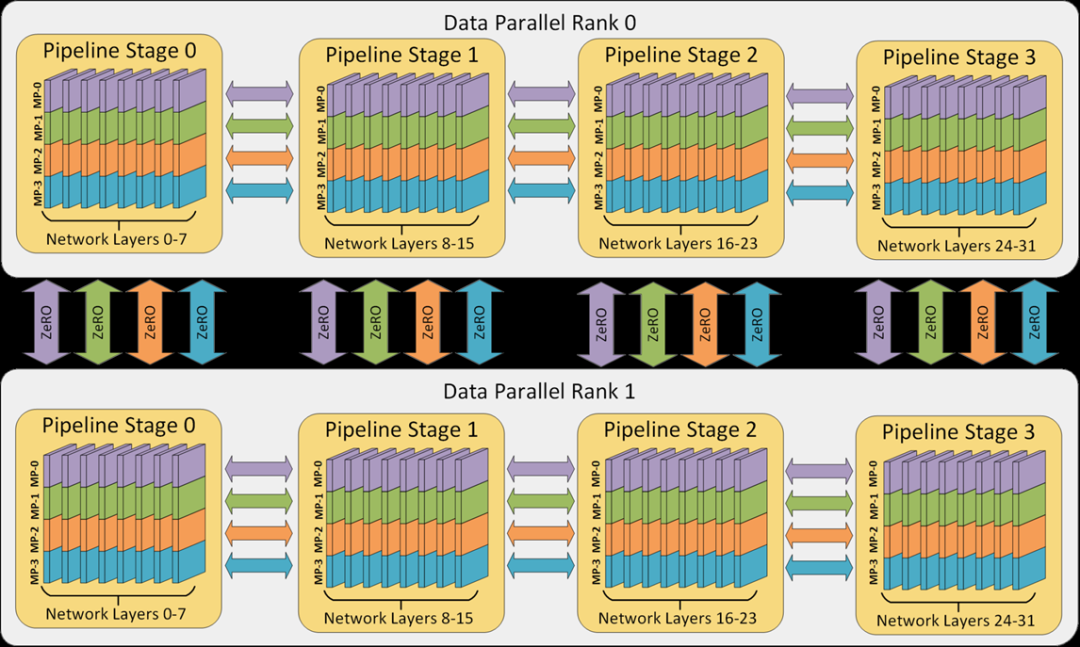
在 Memory-Bound 场景里,为了提升 GPU 利用率,往往采取张量并行(intra-layer)的加速方式,将大模型参数进行切分,减少从显存中读取大模型参数的耗时,从而提升参数计算的速度。如下图所示:
大模型参数层内划分,切分一个独立的层划分到不同的 GPU 上
0 号卡和 1 号卡分别计算某个层的不同部分
比如:对于 6B的模型,如果使用 FP16 精度进行大模型推理,那么大模型参数所占的显存空间约为 :6B * 2 = 12 GB。如果是使用单张 A10 卡进行推理,那么从显存中读取大模型参数的耗时约为:0.02秒(12/600 = 0.02,600 为 A10 的显存带宽(600GB/s))。如果是使用两张 A10 卡进行推理,并选择张量并行度=2,那么从显存中读取模型参数的耗时约为 0.01 秒(12/(600*2)= 0.01)。
当然使用多卡进行大模型在线推理,并不是越多越好,因为张量并行策略会带领额外通信开销,所以需要根据大模型参数规模来选择折中方案,并通过实际测试来看哪个方案时延最优。进一步来讲,当单机8个 GPU 卡总的显存都放不下大模型参数时,就需要使用流水线并行技术(Pipeline Parallelism),以便将大模型参数切分到不同的显存服务器上。比如下图的 3D 并行,一共32个 workers 节点,由4路张量并行、4路流水线并行、2路数据并行构成。
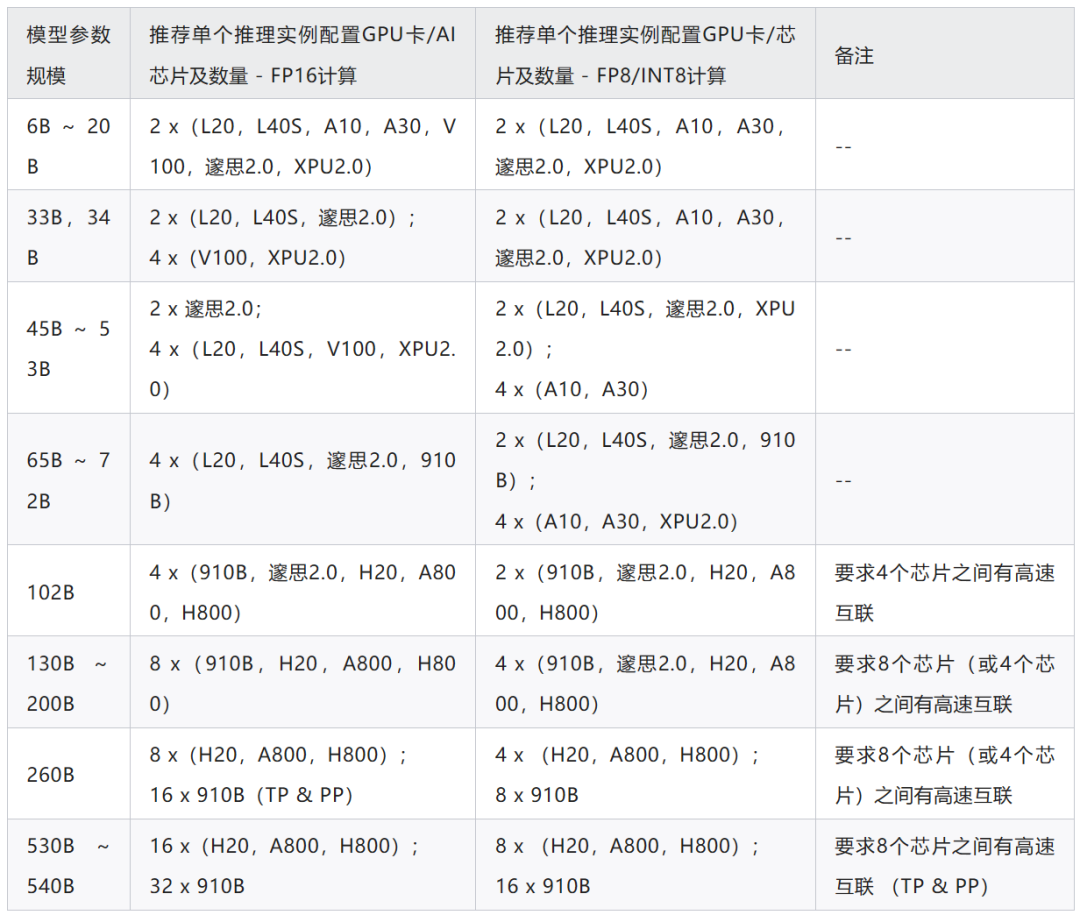
针对不同参数规模的大模型,其推理所使用的 GPU 资源选择也不一样,主要考虑的因素就是大模型参数所占的显存空间以及推理服务的性价比。使用 FP8 精度或 INT8 精度进行大模型推理,可以显著降低显存空间开销,也可以有效降低计算开销。一般情况下,使用FP8 精度推理比使用 INT8 精度推理可以获得更好的模型效果(或者说,相对于 FP16 计算,FP8 计算带来的大模型效果损失更小)。
基于实践经验优化大模型在线推理服务时延(比如:batch size = 1),我们推荐以下大模型推理资源配置。
—2—
大模型在线推理框架如何选择?
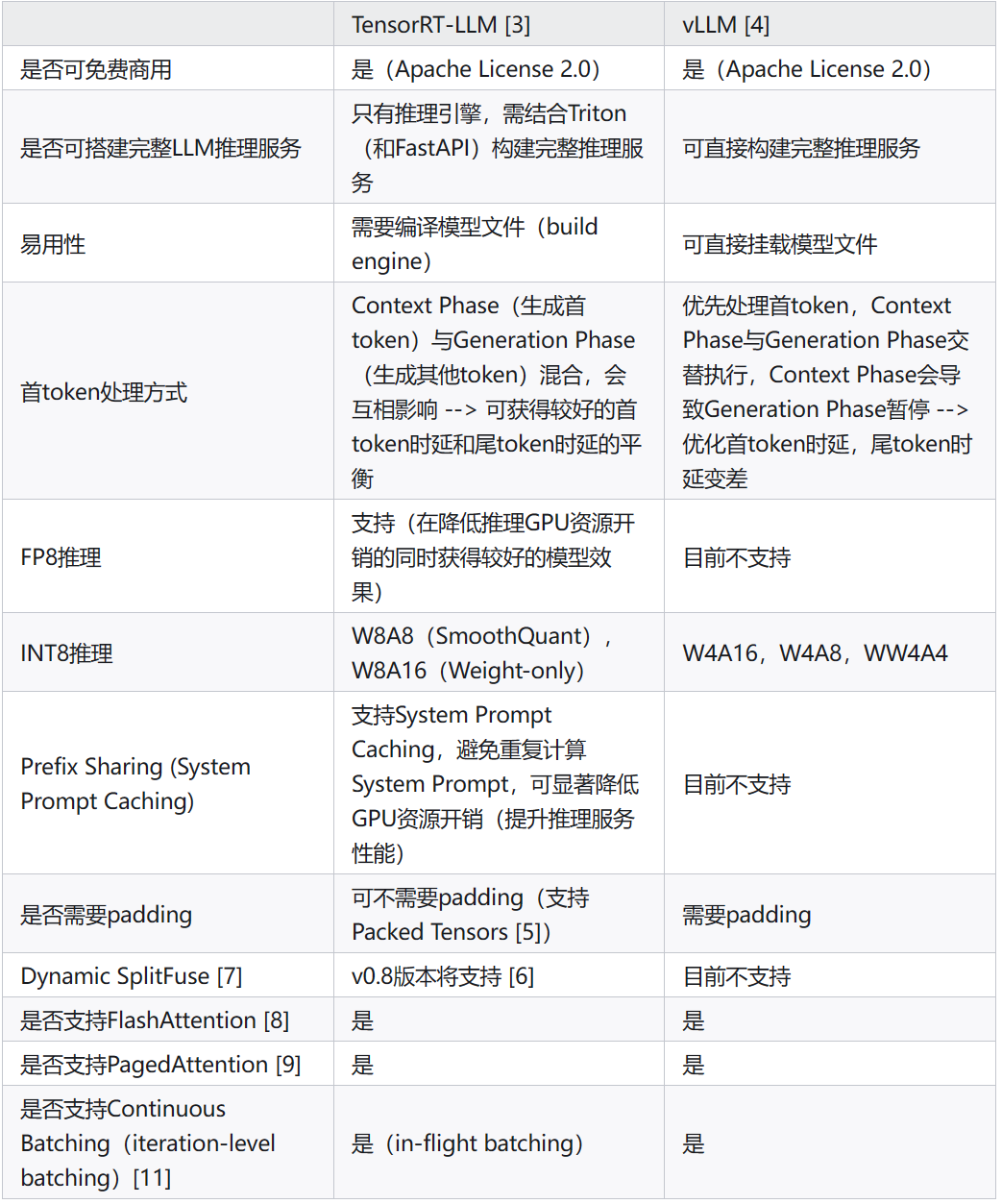
英伟达的 TensorRT-LLM 和伯克利的 vLLM 是目前主流的开源并且可免费商业商用的大模型在线推理框架。
TensorRT-LLM 是英伟达开源的大模型在线推理引擎,由开源项目FastTransformer演进而来,TensorRT-LLM需要结合Triton Inference Server 才能构建完整的大模型在线推理服务。如果需要支持基于 RESTFul API的流式输出(比如:类似 OpenAI 的大模型推理 API 接口),还需要进一步配合 FastAPI 网关才能支持流式输出,这是因为目前 Triton 不支持基于 RESTFul API 的流式输出,总体来讲,使用门槛相对较高。
vLLM 是由 UC Berkeley 主动开源的大模型在线推理框架,基于 vLLM 可以搭建完整的大模型在线推理服务,且默认可以支持 OpenAI API 协议。vLLM 的关键优势之一是支持 PagedAttention,将每个序列的 KV Cache 划分为块,允许在非连续的显存空间中存储 KV Cache ,可以高效管理 KV Cache 在显存的存储并减少 I/O 时间。
基于我们自己的实践经验,推荐大家使用 vLLM 来加速。以下是两个推理框架的对比。
为了帮助同学们彻底掌握大模型的应用开发、部署、生产化,今晚20点我会开一场直播和同学们深度剖析,请同学们点击以下预约按钮免费预约。
—3—
送!AI大模型开发直播课程
大模型的技术体系非常复杂,即使有了知识图谱和学习路线后,快速掌握并不容易,我们打造了大模型应用技术的系列直播课程,包括:通用大模型技术架构原理、大模型 Agent 应用开发、企业私有大模型开发、向量数据库、大模型应用治理、大模型应用行业落地案例等6项核心技能,帮助同学们快速掌握 AI 大模型的技能。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

