- 1竞赛经验分享 && NUIST CEEE慕课计划【1】—— 全国大学生集成电路创新创业大赛_集创赛通过率怎么样
- 2vue初级快速入门_{"wd":"vue v-bin
- 3Windows系统下python版本Open3D-0.18.0 的快速安装与使用_python install open3d
- 4react中实现路由懒加载_react 定义路由需要createelement lazy
- 5AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍_huggingface 模型
- 62024年网络安全最全Web渗透—— Honeypot_honeypotv3漏洞(2),2024年最新面试必问
- 7java简单的事务处理_JAVA之JDBC简单事务处理
- 8Material Components之旅——MaterialButton
- 9初始化go项目和git_github 下载golang项目 初始化
- 10Python 生成 JWT(json web token) 及 解析方式_python 实现jsonwebkey.factory.newjwk
基于PSO粒子群优化算法的VRTPW路径规划问题matlab仿真_matlab vrptw
赞
踩
UP目录
一、理论基础
VRPTW是指一定数量的客户,各自有不同数量的货物需求,配送中心向客户提供货物,由一个车队负责分送货物,组织适当的行车路线,目标是使得客户的需求得到满足,并能在一定的约束下,达到诸如路程最短、成本最小等目的。VRPTW(Vehicle Routing Problem with Time Windows)是指在经典VRP的前提上,给每个客户增添时间窗约束以进行运输服务,时间窗是一个顾客与厂商根据双方需求协商好的特定时间段,包含最早可到达时间和最晚必须到达时间。带时间窗约束使得 VRP 更加复杂性,通常可把时间窗分为硬时间窗(必须满足)、软时间窗(可以不满足,但会受到惩罚)。
PSO求解VRPTW最关键的一步就是如何用一个粒子对VRPTW的解进行表示,本文采用一种常见的表达方式,假设顾客数目为L,车辆最大使用数目为M,则所构造的一个粒子位置为一个2行L列的矩阵,第1行为Xv,表示各个顾客对应的车辆编号,第2行为Xr,表示各个顾客在对应的车辆路径中的执行次序。
在PSO中,群中的每个粒子表示为向量。在投资组合优化的背景下,这是一个权重向量,表示每个资产的分配资本。矢量转换为多维搜索空间中的位置。每个粒子也会记住它最好的历史位置。对于PSO的每次迭代,找到全局最优位置。这是群体中最好的最优位置。一旦找到全局最优位置,每个粒子都会更接近其局部最优位置和全局最优位置。当在多次迭代中执行时,该过程产生一个解决该问题的良好解决方案,因为粒子会聚在近似最优解上。
Ray等人通过将PSO算法和Pareto排序机制想结合起来。采用Pareto排序法来选择一组精英解,全局最优粒子的选择则是采用轮盘赌方式从中选择。实际运行时,只有少量的个体选择概率大,种群多样性保持不好。Coello等在PSO算法中选择群体最佳位置则是通过引入Pareto竞争机制和微粒知识库。该知识库用于存储微粒在每次飞行循环后的飞行经验,知识库的更新是通过考虑一个基于地理学的系统,该系统是就每个微粒的目标函数值而言来定义的。这个知识库被微粒用来确定一个指导搜索的领导者。同时非劣解的确定是通过将候选个体与从种群中随机选出的比较集进行比较,因此比较集的参数对算法成功与否有着至关重要的影响。若参数过大,则容易发生早熟收敛的现象,而参数过小,则种群中选出的非劣解的数量可能过少。
PSO模拟的是鸟群的捕食行为。设想场景:一群鸟在随机搜索食物。在这个区域里只有一块食物。所有鸟都不知道食物在哪里。但是他们知道当前的位置距离食物还有多远。那么找到食物的最优策略是什么?最简单有效的就是搜寻目前离食物最近的鸟的周围区域。
鸟群在整个搜寻过程中,通过相互传递各自的信息,让其他鸟知道自己当前的位置,通过这样的协作来判断自己找到的是不是最优解,同时也将最优解的信息传递给整个鸟群,最终整个鸟群都能聚集在食物源的周围,即找到了最优解。
PSO中,每个优化问题的解都是搜索空间的一只鸟,我们称之为“粒子”。所有的粒子都有一个被优化的函数决定的适应值,每个粒子还有一个速度决定他们飞翔的方向和距离。然后粒子们就追随当前的最优粒子在解空间中搜索。
PSO初始化为一群随机粒子(随机解)。然后通过迭代找到最优解,在每一次迭代中,粒子通过跟踪两个“极值”来更新自己。第一个就是粒子本身所找到的最优解,这个解叫做个体极值。另一个极值是整个种群目前找到的最优解,这个极值是全局机制。另外也可以不用整个种群而只是用其中一部分作为粒子的邻居,那么在所有邻居中的极值就是局部极值。
PSO初始化为一群随机粒子(随机解)。然后通过迭代找到最优解。在每一次迭代中,粒子通过跟踪两个“极值(pbest和gbest)”来更新自己。在找到这两个最优值后,粒子通过下面的公式来更新自己的速度和位置。
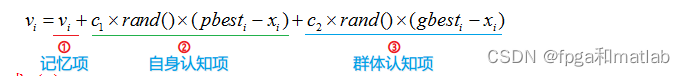

PSO初始化为一群随机粒子(随机解),然后通过迭代找到最优解。在每一次迭代中,粒子通过跟踪两个极值来更新自己;第一个就是粒子本身所找到的最优解,这个解称为个体极值;另一个极值是整个种群目前找到的最优解,这个极值是全局极值。

第一:首先对粒子群的随机位置和速度进行初始化,即在速度和位置的限定
范围内产生随机值;
第二:利用适应度函数计算每个粒子的适应值;
第三:比较每个粒子的适应值和自身所经历过最好位置Pi的适应值,若当前值更好,则将当前值作为自身最好位置;
第四:比较每个粒子的适应值和全局最好位置Pg的适应值,若当前值更好,则将当前值作为全局最好位置;
第五:更新粒子的速度和位置;
第六:如此时已满足结束条件,即达到最大的迭代次数或最小的错误要求,则进化终止,输出最优解,否则,转到步骤2。
二、核心程序
- .................................................
- c1=0.1;
- c2=5;
- w=0.96;
- load 'node.txt';
- xy=node(2:NUM+1,2:3);
-
- x0=ones(N,NUM);
- for i=1:N %随机给每个粒子分配路径
- x0(i,:)=randperm(NUM);
- end
-
- v0=zeros(N,NUM);
- for i=1:N %在VRP中粒子的速度代表交换序
- v0(i,:)=round(rand(1,NUM)*NUM);
- end
-
- distance_center=zeros(1,NUM);%每个粒子离配送中心的距离
- for i=1:NUM
- distance_center(i)=sqrt((node(i+1,2)-node(1,2))^2+(node(i+1,3)-node(1,3))^2);
- end
-
- distance_two=zeros(NUM,NUM); %每两个用户之间的距离
- for i=1:NUM-1
- for j=i+1:NUM
- dis=sqrt((xy(i,1)-xy(j,1))^2+(xy(i,2)-xy(j,2))^2);
- distance_two(i,j)=dis;
- distance_two(j,i)=dis;
- end
- end
-
-
- for i=1:N %每个粒子路径的总距离
- EachPathDis(i)=PathDistance(x0(i,:),distance_two,distance_center);
- end
-
- IBest=x0; %粒子个体的历史最优路径
- IBestFitness=EachPathDis;%粒子个体的历史最优适应值
- [GBestFitness,index]=min(EachPathDis); %粒子全局最优路径
- g1=GBestFitness; %粒子全局最优适应值
-
- figure;
- subplot(2,2,1);
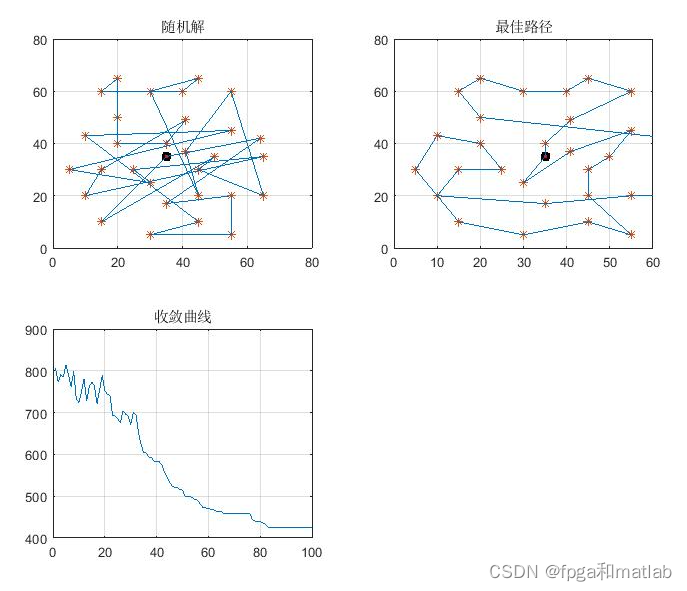
- PathPlot(node,NUM,index,IBest);
- title('随机解');
-
- while(IsStop==0)&&(Iteration<MI)
- Iteration=Iteration+1;
- %g2(Iteration)=GBestFitness;
- for i=1:N
- GBest(i,:)=x0(index,:); %全局最优路径
- end
-
- pi_x=GenerateChangeNums(x0,IBest); %(Pi-Xi)就是使xi向个体最优解靠近,而非远离,这也是一个交换用户序号的过程,得到交换的序
- pi_x=HoldByOdds(pi_x,c1); %这是c1*(Pi-Xi)的过程,以c1保留交换序
- pg_x=GenerateChangeNums(x0,GBest); %(Pg-Xi)就是使Xi向全局最优解靠近,得到路径中要交换的用户序号
- pg_x=HoldByOdds(pg_x,c2); %这是c2*(Pg-Xi)的过程,以c2保留交换序
-
- v0=HoldByOdds(v0,w); %这是w*Vi的过程,以概率w得到交换序
-
- x0=PathExchange(x0,v0); %通过交换序来改变每个粒子的路径,也就是优化的过程
- x0=PathExchange(x0,pi_x);
- x0=PathExchange(x0,pg_x);
- for i=1:N %计算每条路径的距离
- EachPathDis(i)=PathDistance(x0(i,:),distance_two,distance_center);
- end
-
- IsChange=EachPathDis<IBestFitness; %更新后的距离优于更新前的,记录序号
- IBest(find(IsChange),:)=x0(find(IsChange),:); %更新个体最佳路径
- IBestFitness=IBestFitness.*(~IsChange)+EachPathDis.*IsChange; %更新个体最佳路径距离
- [GBestFitness,index]=min(EachPathDis); %更新全局最佳路径,记录相应的序号
- if GBestFitness==OldpgFitness %比较更新前和更新后的适应度值;
- INUM=INUM+1;
- else
- OldpgFitness=GBestFitness; %不相等时更新适应度值,并记录清零
- INUM=0;
- end
- if INUM>=20
- IsStop=1;
- end
-
- BestFitness(Iteration)=GBestFitness;
- end
- UP58

三、测试结果