
- 1如何批量查询自己的CSDN博客质量分_csdn 怎么查看哪里改进
- 29_帖子详情_帖子详情页面
- 3字节跳动测开面经,听他讲完,紧张得汗流了一背!_字节财经 测开
- 4git基本概念和核心命令使用_git的基本概念
- 5网络攻防演练.网络安全.学习_攻防实战演练csdn
- 6HOW - Canvas 入门系列之基于vue-konva的多维表格(四)
- 7vue+element-ui 表格中图片缩略图悬浮显示_vue el-table 加上传缩略图的功能
- 8通过adb查看当前连接的设备的CPU_windows adb如何查找cpu型号
- 9Docker部署MySQL监控工具Lepus_lepus docker
- 10.NET 8 Host 的一些更新
阿里云ClickHouse海量数据分析_clickhouse单表存储多少数据量
赞
踩
导读:2020年clickhouse就是一批黑马,成功脱颖而出,在各大互联网都受到青睐,头条、腾讯、快手、阿里都在使用clickhouse,下面我们一起来学习一下阿里巴巴在clickhouse中的经验分享。
目录
-
业务背景
-
技术选型
-
经验分享
-
未来规划
业务背景
我们是OLAP监控诊断团队的,我们这边收集了海量的SQL审计数据,我们的用户经常提出这样的需求:
-
某段时间内SQL执行耗时
-
SQL分布统计:DB分布、耗时分布、类型等
-
慢SQL有哪些?SQL Pattern是什么?
-
SQL诊断:资源使用、异常信息、执行计划、数据扫描等
-
实时用户画像
我们的数据规模:
-
单个ClickHouse集群存储的数据量压缩后约60TB
-
日志保留30天
-
写入速度30万/s,峰值40-50万/s,每天400亿一条
-
单表数据量80亿+
技术选型
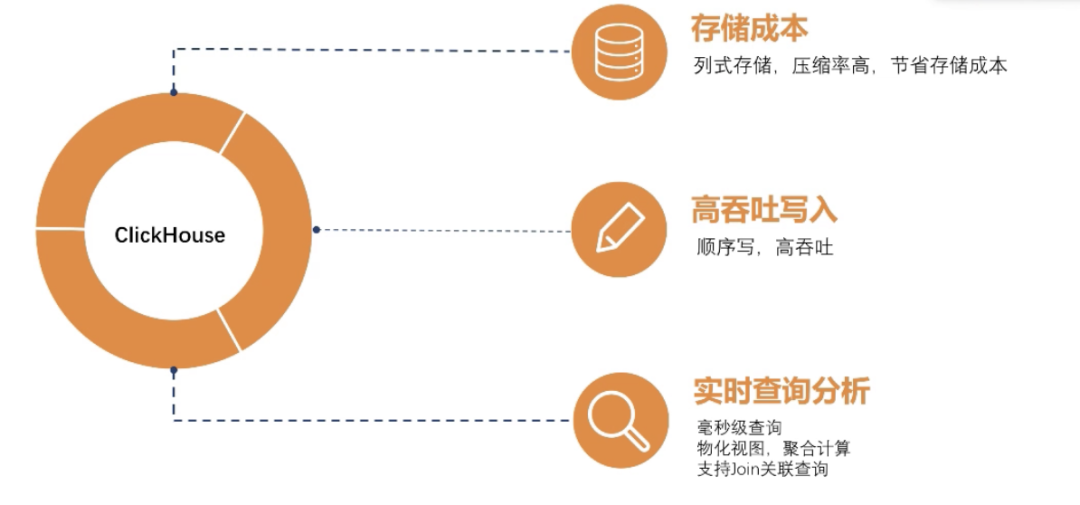
为什么会选择ClickHouse,主要从这几点出发吧:
-
存储成本:大家都知道ClickHouse的存储成本是非常低的,他是列式存储,整个压缩率都是比较高的,他们每列存储的值好多都是相同的,我们统计过我们的ClickHouse压缩比能达到10左右,
-
高吞吐写入:因为我们每天的实时数据量级比较大,我们对写入的要求还是比较高的,我们知到ClickHouse是MergTree这种架构,他跟LSMTree差不错,他们都是顺序写吞吐量比较高。
-
实时查询分析:我们需要的是实时查询分析,ClickHouse做为一个MPP架构,在大宽表的查询性能都是比较好的,查询性能可以达到毫秒级返回。ClickHouse支持物化视图,我们可以做一些预先聚合统计保存起来,下次查询可以直接命中之前预聚合的物化试图结果,这样可以提高查询性能。ClickHouse还支持Join的查询,这个也是我们需要的,因为我们需要做OLAP分析,简单的Join在ClickHouse还是可以支持的,复杂的Join还是无法满足。
经验分享
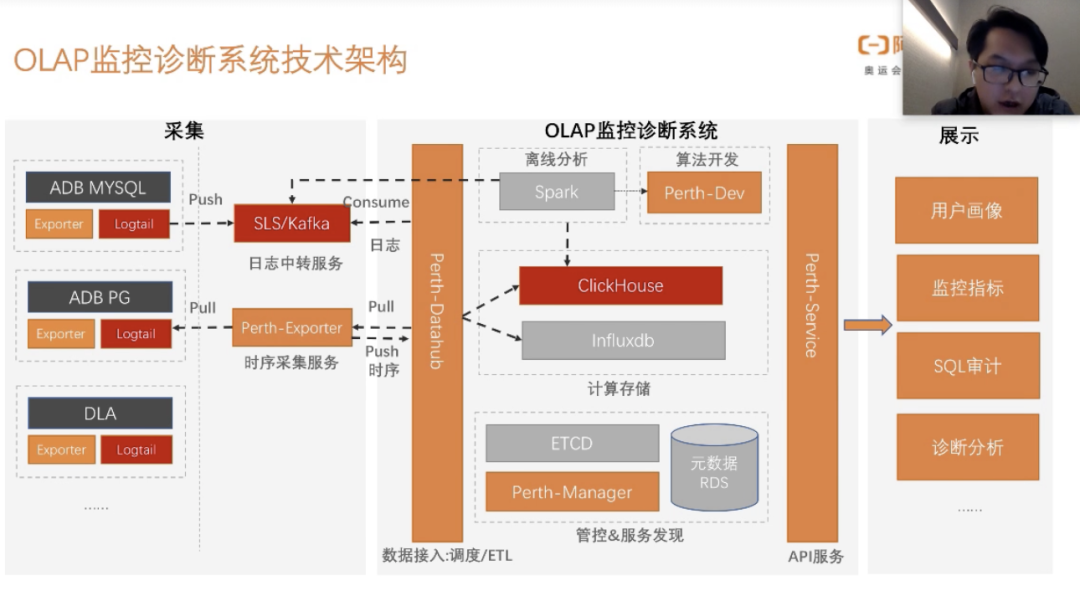
在进行经验分享之前,先简单介绍一下我们整个的OLAP监控诊断系统架构,这样可以让大家知道ClickHouse在我们整个系统架构中扮演者什么样的角色和作用,我们整个架构分为两个链路。
-
第一条链路:时序采集服务,时序的我们会存储在Influxdb,在日志上我们存储在ClickHouse中,为什么选择ClickHouse我们上面也讲了。
-
第二条链路:我们采集其他数据库中的日志,然后push到日志中专服务,通过我们的DataHub数据接入层,去不断的消费kafka中的日志,做一层简单的清晰,然后落到到ClickHouse中
后面我们会提供一个服务层,然后到用户那里去,其中主要包括:用户画像、监控指标、SQL审计、诊断分析等。细心的同学可能会看到,我们这个架构上有一块属于离线的分析,那为什么我们会用离线的分析呢?上面我们也说了,ClickHouse做简单的Join还是可以的,如果我们做复杂的任务计算的话,ClickHouse可能会把我们的系统资源打满,会影响整个ClickHouse的稳定性。一开始的我们会把大的任务放到凌晨1-2点开始执行,后来发现这种方式不太可行,因为随着业务的接入,任务也越来越多,所以我们后来加入了离线分析这块。
这个就是ClickHouse在我们这个整个监控诊断系统架构扮演的角色。

在进入经验分享之前我还想让大家先了解一下ClickHouse的整个架构,尽管好多同学都已经非常了解整个ClickHouse的架构了,我还想多说一下,因为后边讲的优化点,都是需要先了解ClickHouse架构,才知道如何去优化,尤其是ClickHouse的存储结构。
-
首先是前面是分布式表,会有一些shard打我们的本地表
-
本地表里面会有一些分区,每个分区里面会有多个MergerDataPart
-
每个Part会有几类文件:数据文件、mark文件、索引文件
-
左边是我们的ClickHouse建表DDL,我们是义logic_ins_id做为shard,在本地表是以日期做为分区,我们的排序会有以logic_ins_id+时间进行一个排序,这里大家会发现,为什么我们这里会乘以-1,ClickHouse默认的排序是正序的,如果你要倒序的存储,就需要乘以-1,这个目的是让我们的查询更快,不用再做一次倒序的计算。

ClickHouse经验分享,我们今天主要分享两个部分:
-
写入:主要是围绕MergeDataPart这个环节去讲
-
查询:我们都知道,一个大查询任务,主要消耗的时间就会花在数据加载和计算这两个环节,其他数据库产品也是这样子,他们都会利用一些数据本地性、数据缓存、网络协议、算法的优化等去做一些优化。
对于ClickHouse我们这块的优化主要有三点:
-
查询条件带上shard、分区、索引等条件,主要是让他尽可能少的加载数据
-
业务需求会经常有一些聚合条件,可以通过物化试图提前预聚合好,保存在物化试图内,从而加快查询速度,当然可能会消耗一些内存。
-
我们的需求会经常查询历史30天以内的sql,展示需要倒着排序,如果我们正序排的话,我们查询出来还得做一次排序计算。
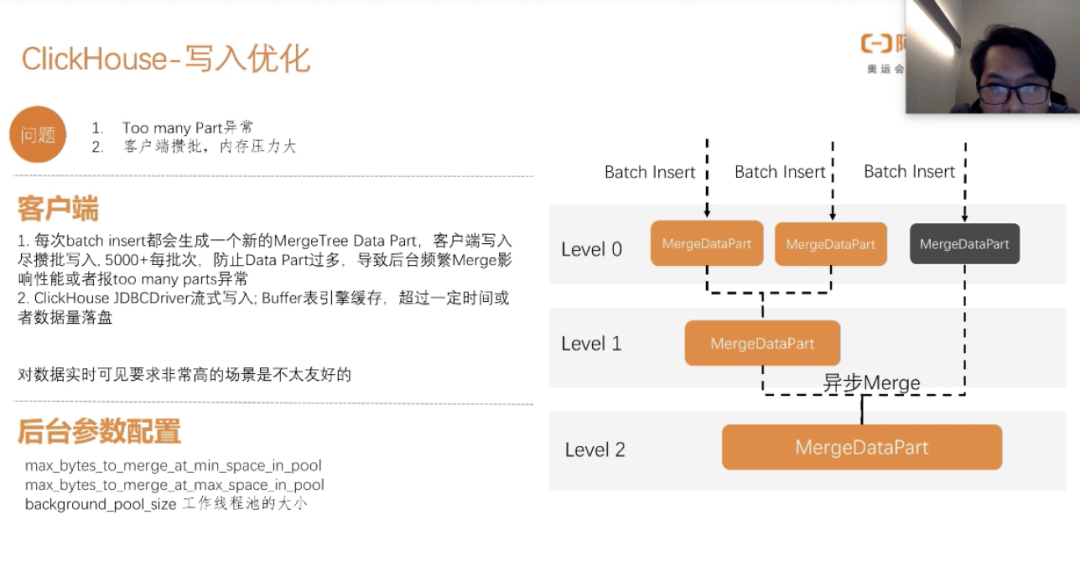
下面我们再来讲一下写入的优化,我们每次batch insert之后都会产生一个MergeDataPart,然后MergeDataPart再去异步合并成一个总的MergeDataPart,这会出现一个问题,当我们写入特别快,Merge又来不及Merge,那就会产生too many parts异常,这也是我们一开始使用clickhoue不太清楚底层写入的机制,导致不断的有这种异常出现,所以我在分享之前,先去给大家回顾一下ClickHouse的存储结构还有他的存储机制。我们客户端写入尽量进行批次写入,防止MergeDataPart过多,导致后台频繁merge影响性能或者报too many parts异常。
ClickHouse JDBCDriver流式写入,通过buffer表索引缓存,超过一定时间或者数据量落盘,这样会减少客户端的内存压力。
当然我们每次都是大量的数据积累批次写入,带来的影响就是数据的时效性差,对实时可见的场景不太友好,这个需要根据你的业务写入量和场景去平衡一下,到底是要积累更多的批数据写入,还是更实时的可见。
在merge的时候,我们为了提高merge的性能可以在后台配置一下:
-
max_byte_to_merge_at_min_space_in_pool;max_byte_to_merge_at_max_space_in_pool
-
background_poolsize工作线程的大小
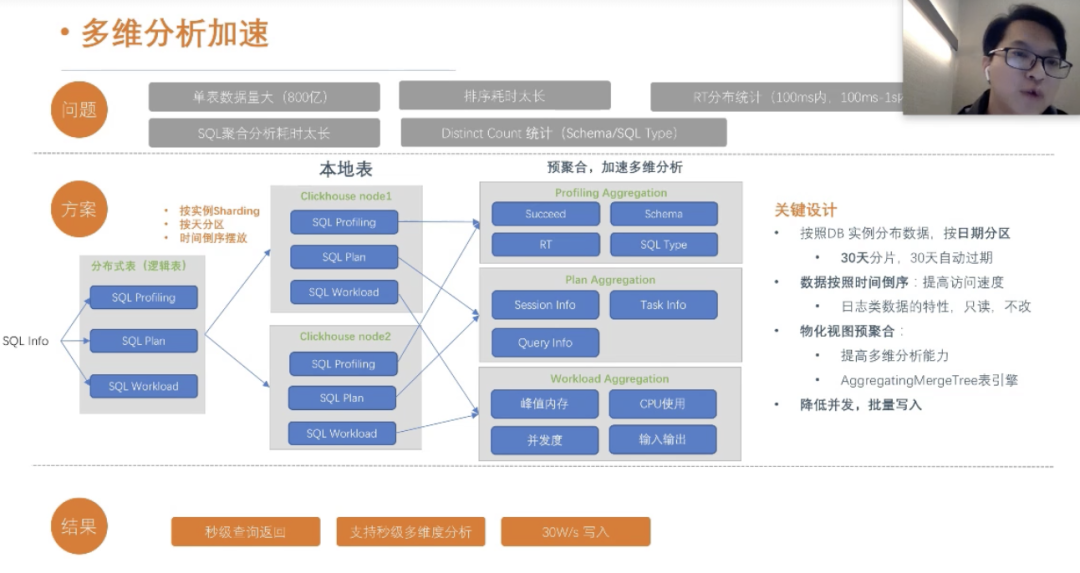
整体的思路:
-
物化视图预聚合,达到秒级或者毫秒级返回。
-
根据业务场景,倒排设计,提高查询速度
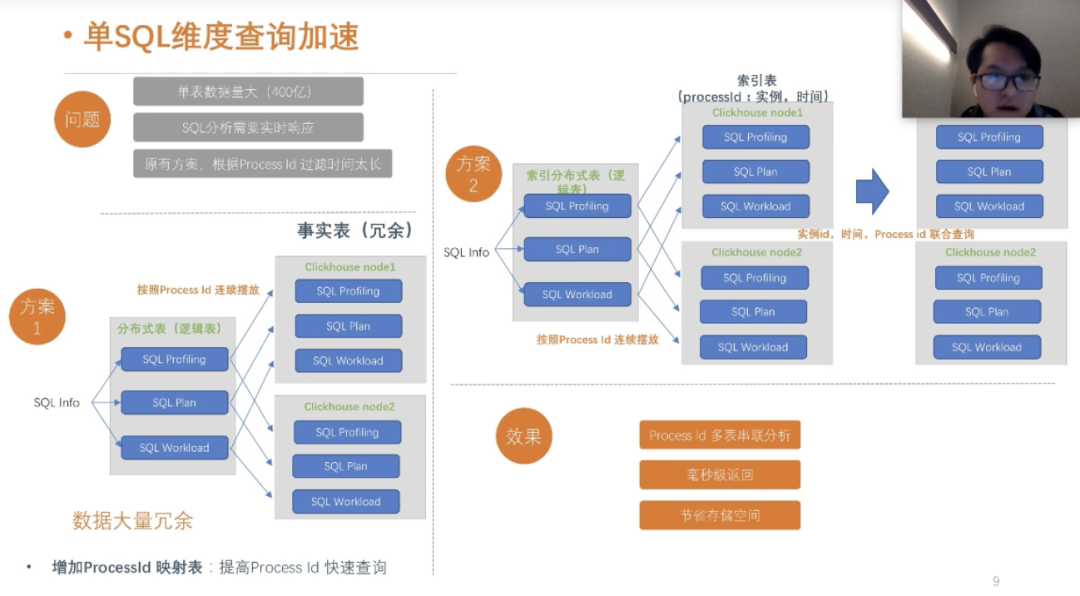
方案1:如果我们按照logic_ins_id做分区,我们会按照logic_ins_id做主键索引,如果 我们的查询sql没有包含logic_ins_id,我们传入的是processid,这会出现命中不了主键索引,从而扫码全部本地索引数据,这对查询性能带来很大的影响。
方案2:我们需要做一个映射表,记录pricessid和logic_ins_id的映射关系,这样我们在查询的时候,先通过pricessid查询出来logic_ins_id,然后再通过logic_ins_id命中主键索引,从而避免全表扫码,提高查询效率,我们这整个优化下来,查询时间降低到秒级和毫秒级以内,大家看完这个方案,可能会联想到二级索引,是的,我们有一个映射表,来充当二级索引的作用。

这个是我们业务场景的效果,整个页面的查询都是毫秒级返回。
用户画像的查询,如果放在ClickHouse做比较复杂,查询时间会在30分钟左右,我们通过把用户画像的SQL放在了Spark内计算,计算完结果写入ClickHouse中,也可以加速ClickHouse查询的速度。
未来规划
-
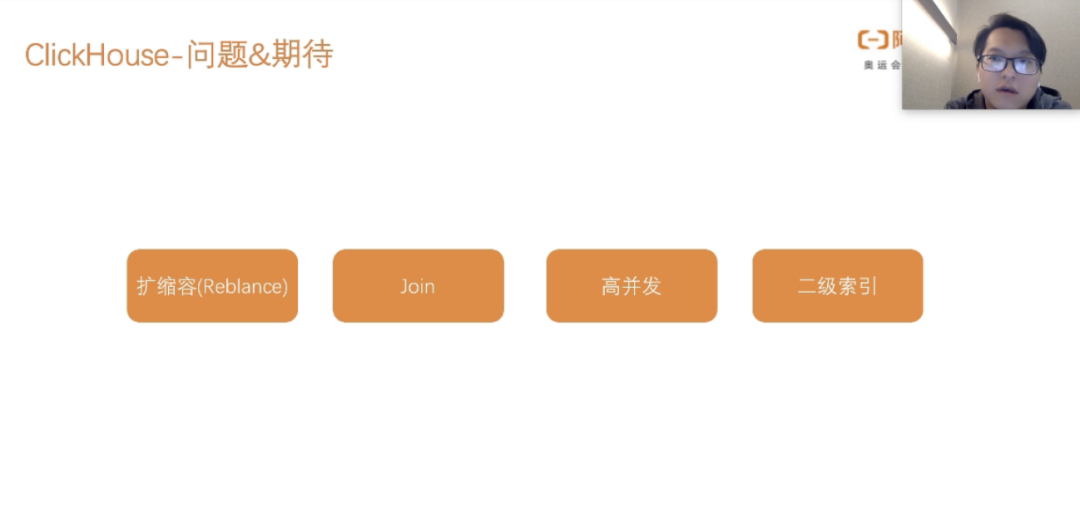
ClickHouse虽然很快,但是他占用资源,扩容也不可以自动扩容
-
Join关联查询不是很好,简单的Join可以,复杂的Join性能不好,复杂的Join建议用离线机选
-
高并发这块,频繁的Merge也是不够优化
-
二级索引ClickHouse团队正在做了,这个也是比较期待的

