
热门标签
热门文章
- 1八分钟就看懂 | 推荐系统 (协同过滤) 原来这么简单_协同过滤类推荐系统
- 2LibCurl HTTP部分详细介绍_libcurl设置 协议头
- 3每天看一个fortran文件(7)之寻找cesm边界层高度计算代码
- 4python实现强化学习_python中强化学习的概念
- 5头歌实践教学平台数据库原理与应用实训答案_头歌实践教学平台答案
- 6MySQL 自动根据年份动态创建范围分区_mysql 按年分区
- 7《自然语言处理的前沿探索:深度学习与大数据引领技术风潮》_采用最前沿的自然语言处理和大数据技术是什么
- 8使用Python的requests库,轻松实现网络爬虫和数据抓取_requests.models.response
- 9SQL语句,查询操作_sql 将最高工资的人和最低工资的人 查询出来
- 10Android 7.0中FileProvider
当前位置: article > 正文
FastGPT + OneAPI 构建知识库_fastgpt 通义千问
作者:笔触狂放9 | 2024-05-29 15:34:00
赞
踩
fastgpt 通义千问
云端text-embedding模型
这个在前面的文章FastGPT私有化部署+OneAPI配置大模型中其实已经说过,大概就是部署完成OneAPI后,分别新建令牌和渠道,并完成FastGPT的配置。
新建渠道
选择模型的类型并配置对应的词向量模型即可,这里我选择的是阿里通义千问。
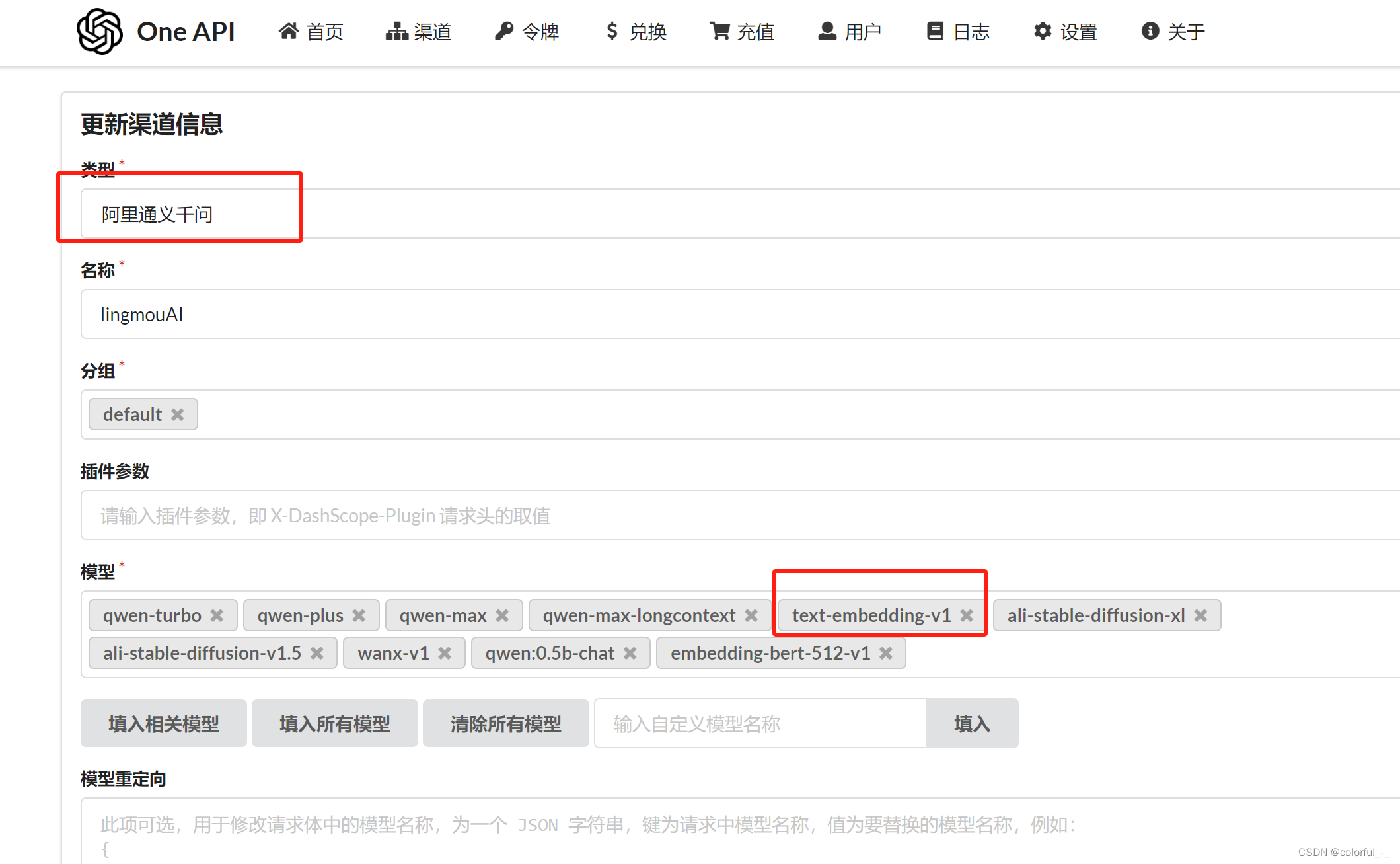
重启oneAPI
FastGPT配置
docker-compose.yml文件配置
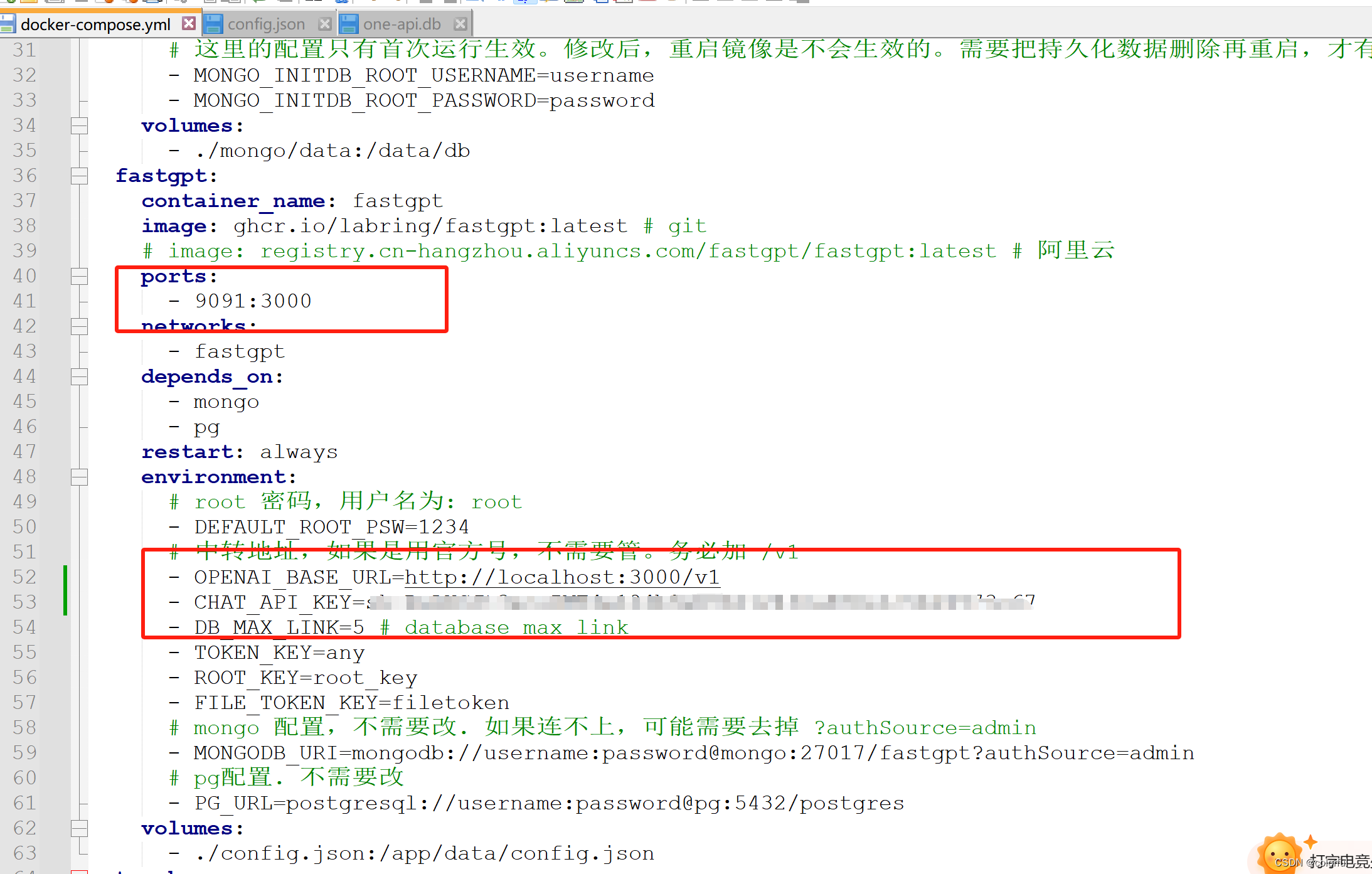
修改 FastGPT 配置文件config.json
"vectorModels": [ { "model": "text-embedding-v1", "name": "lingmouAI", "inputPrice": 0, "outputPrice": 0, "defaultToken": 700, "maxToken": 3000, "weight": 100 }, { "model": "text-embedding-ada-002", "name": "lingmouAI", "inputPrice": 0, "outputPrice": 0, "defaultToken": 700, "maxToken": 3000, "weight": 100 } ],

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
重启fastGPT
docker-compose up -d
- 1
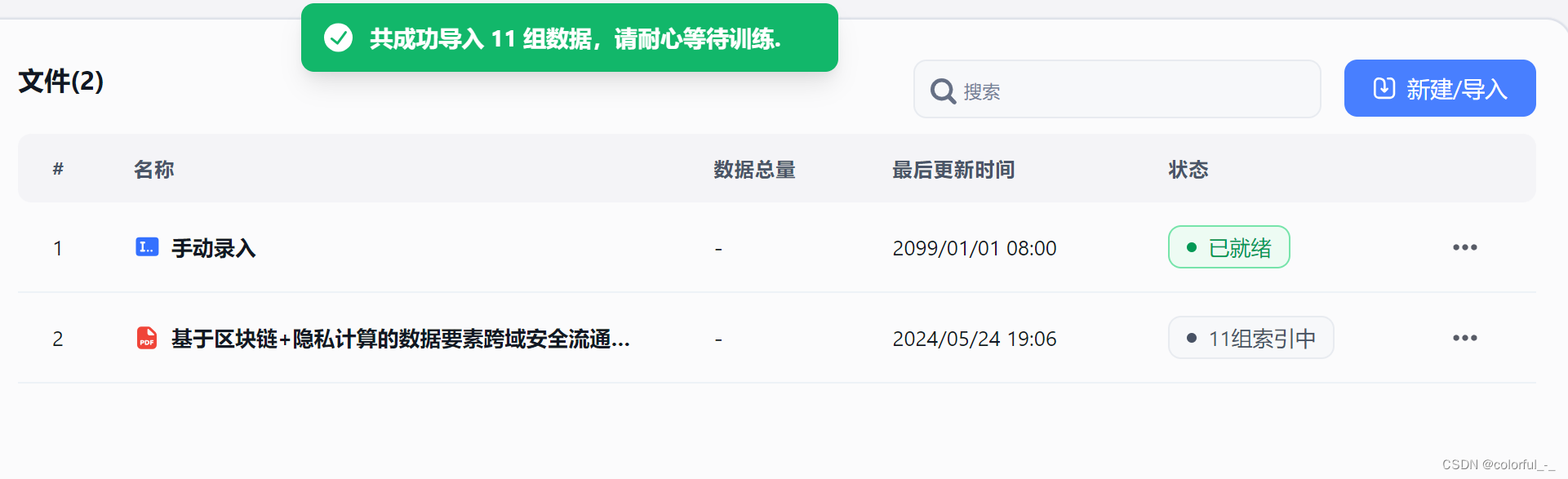
FastGPT测试知识库训练
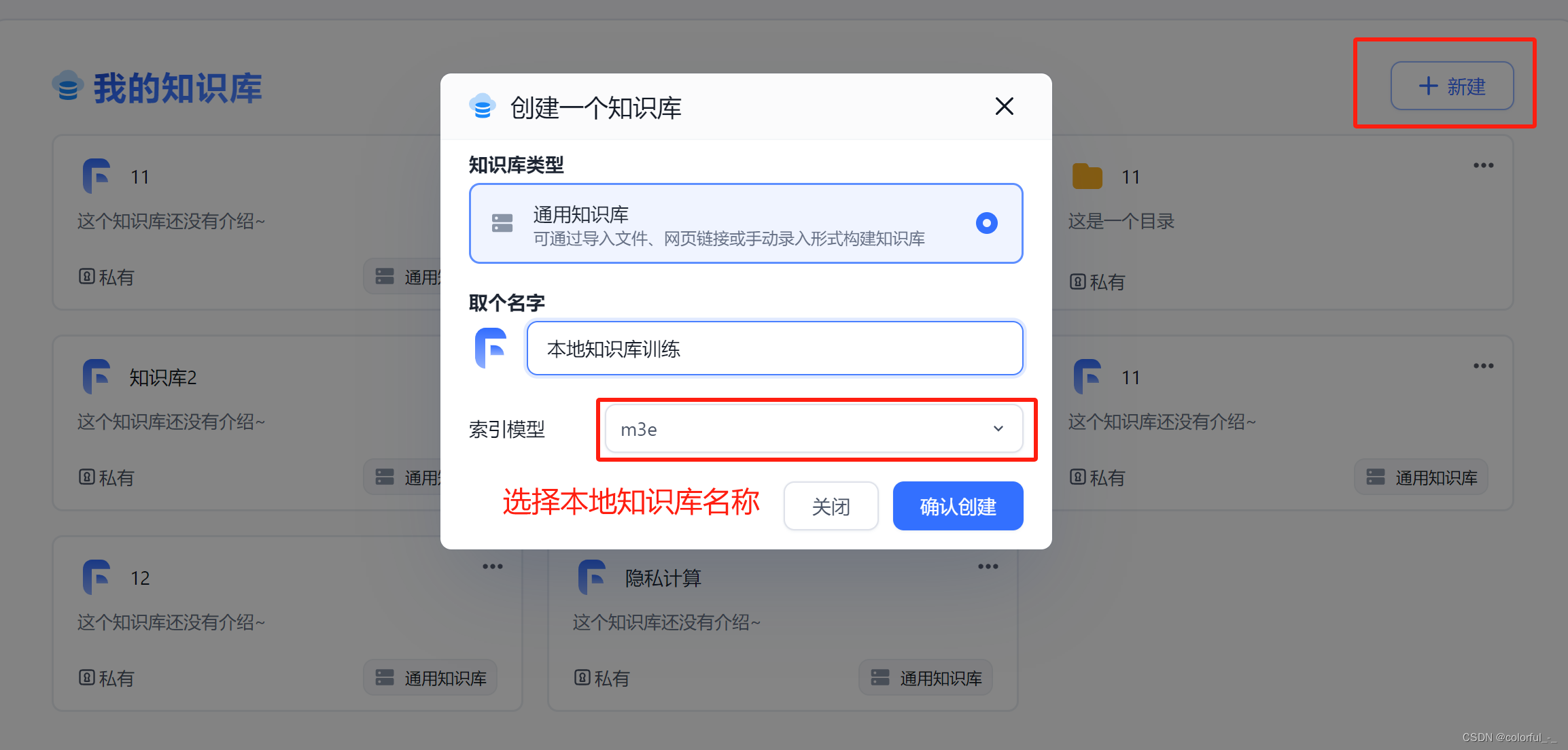
新建知识库
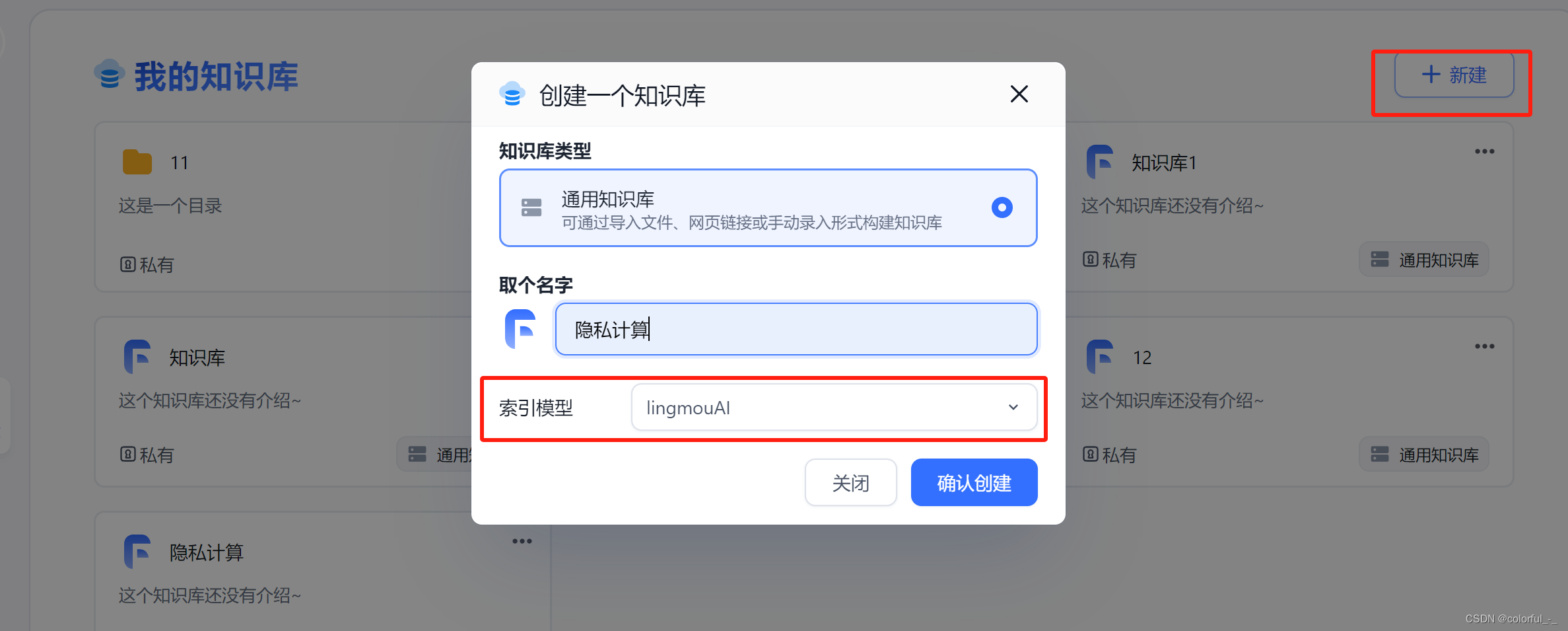
上传文件

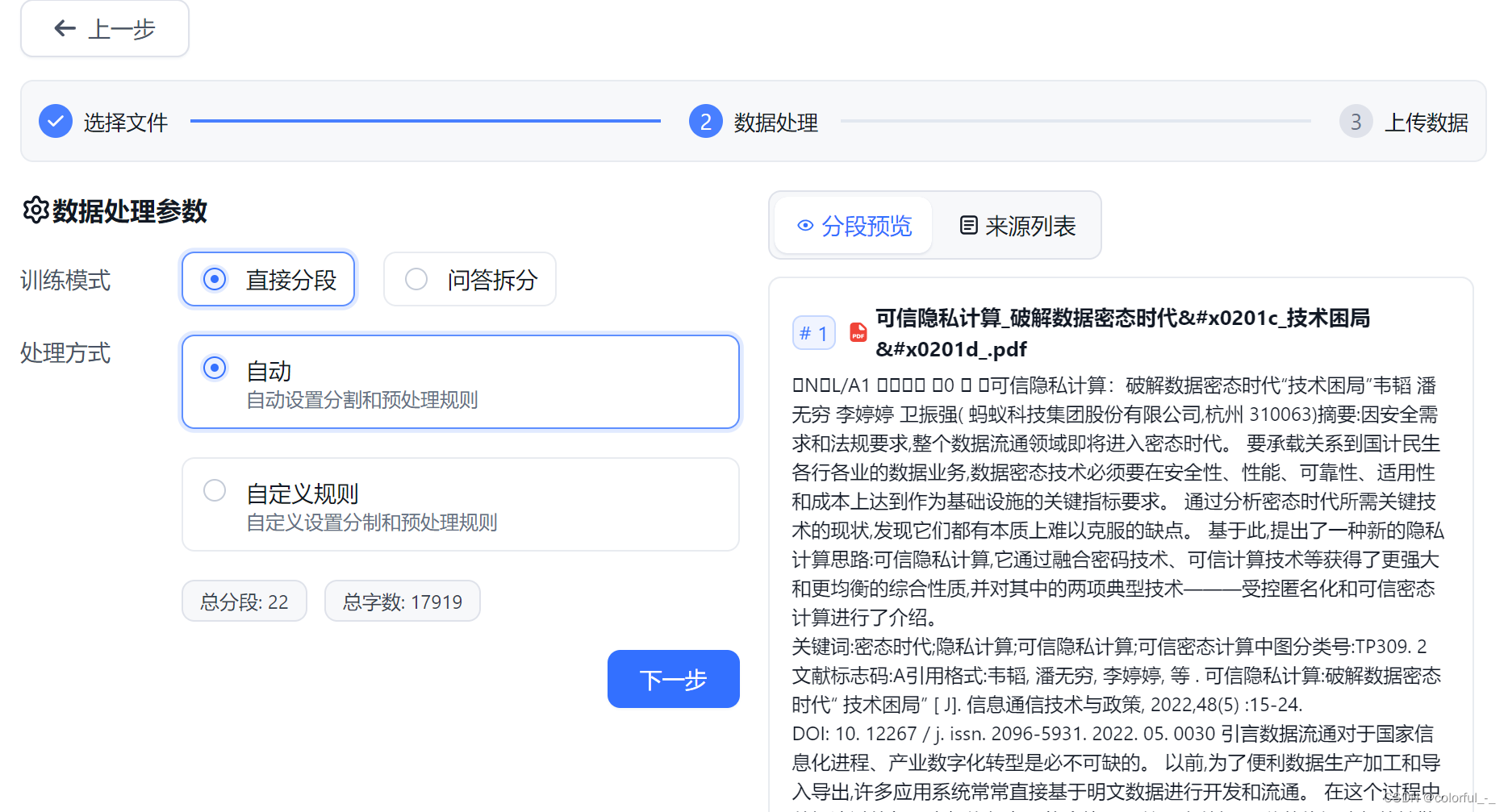
上传文件并设置训练方式和处理方式
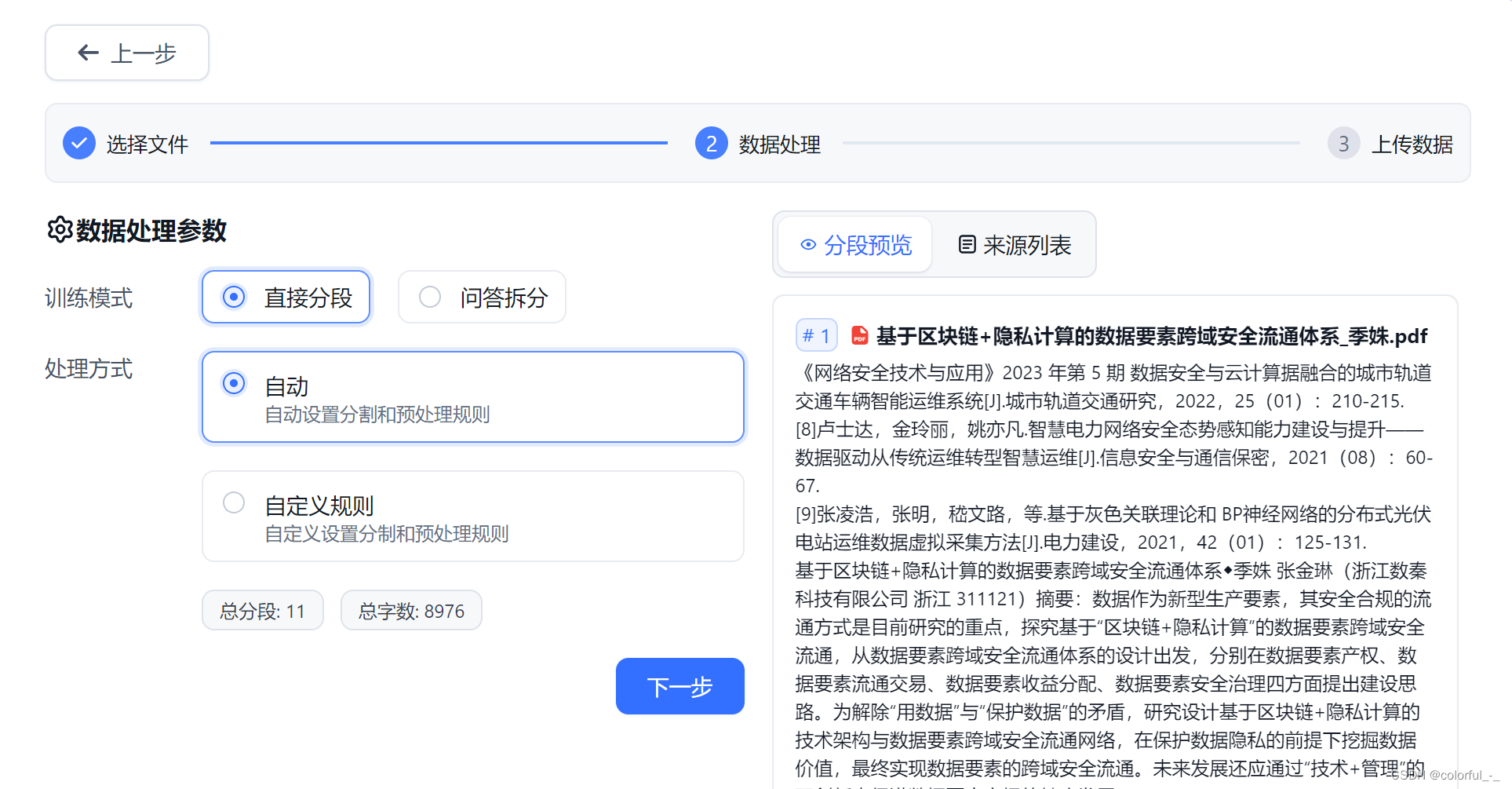
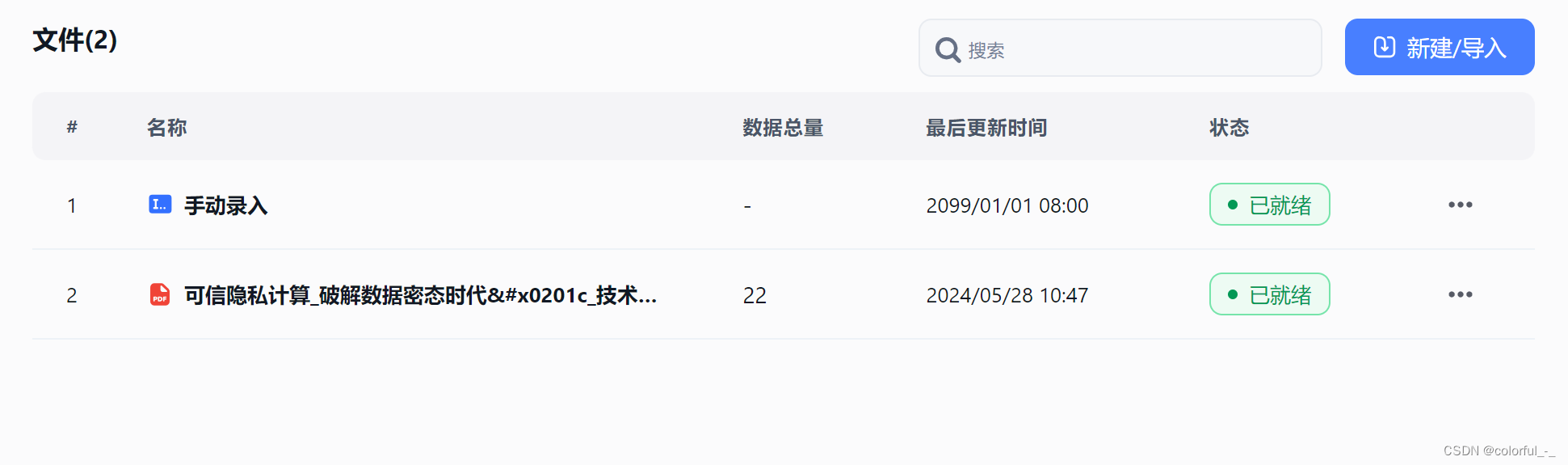
上传数据,并等待训练完成
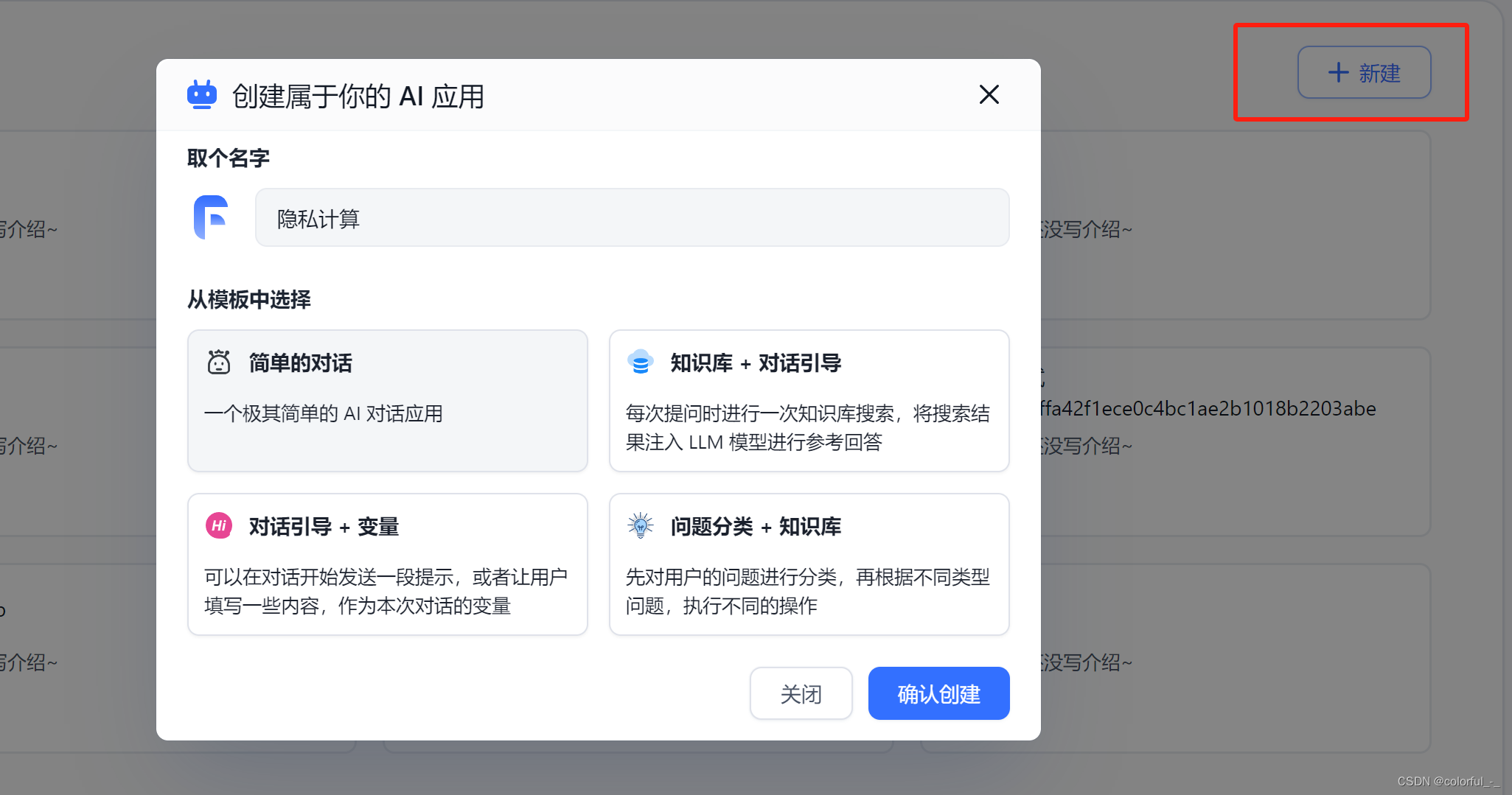
新建应用并测试
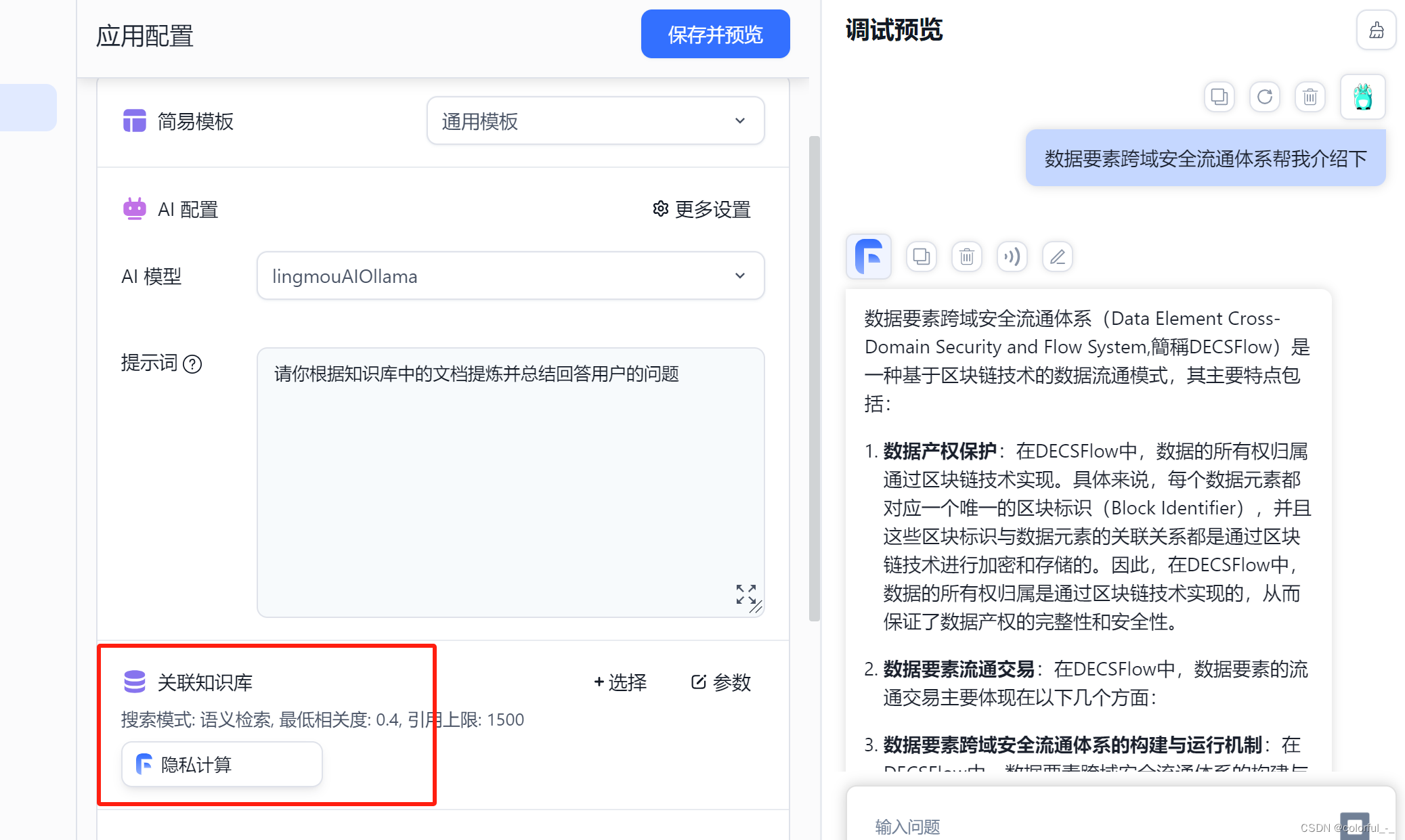
新建完成后,在应用内选择刚刚配置的知识库,就可以对话了
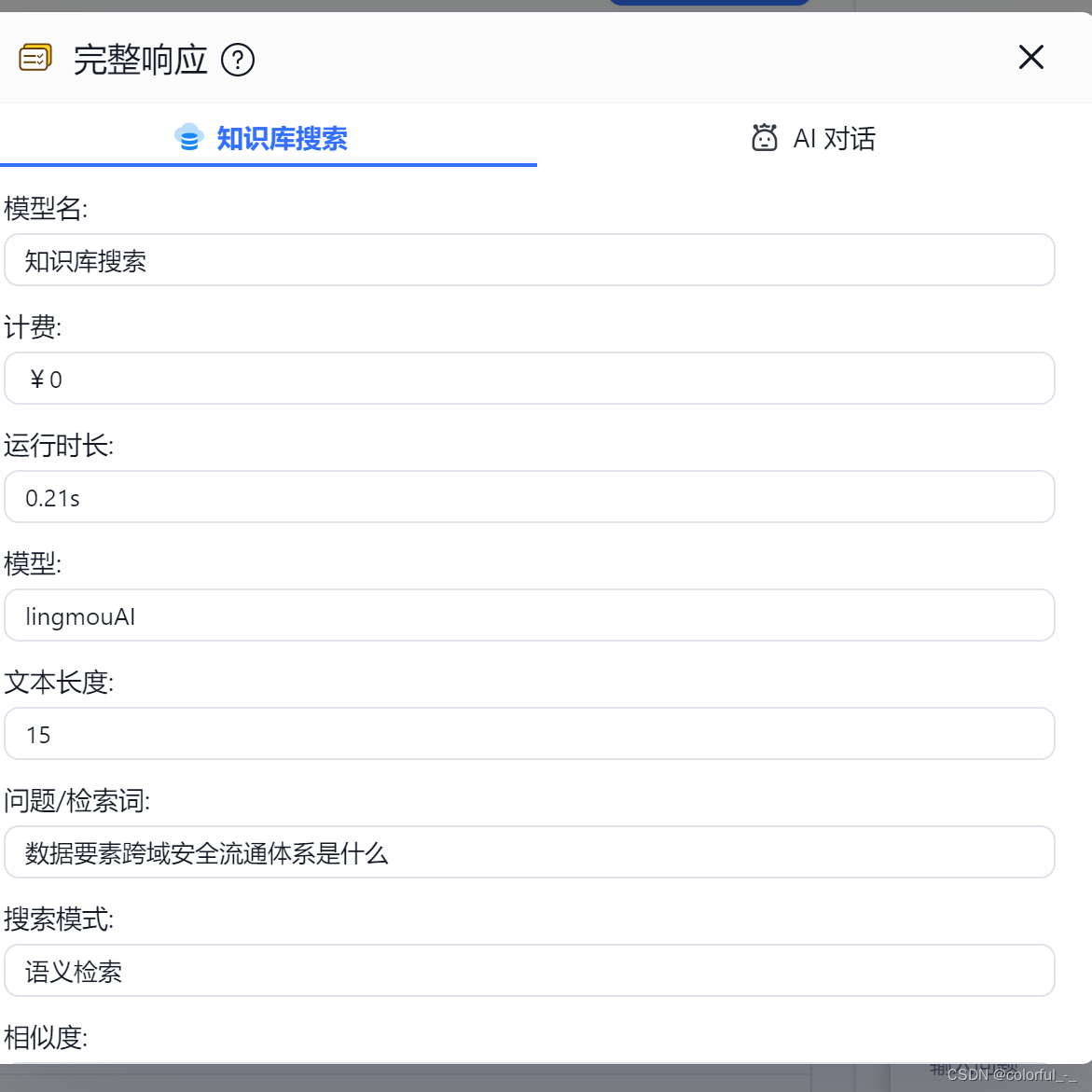
对text-embedding理解
问题记录
- 会出现多次请求大模型的情况,导致会有重复输出,重启后也没有解决。现在原因还没分析出来。
如下所示:

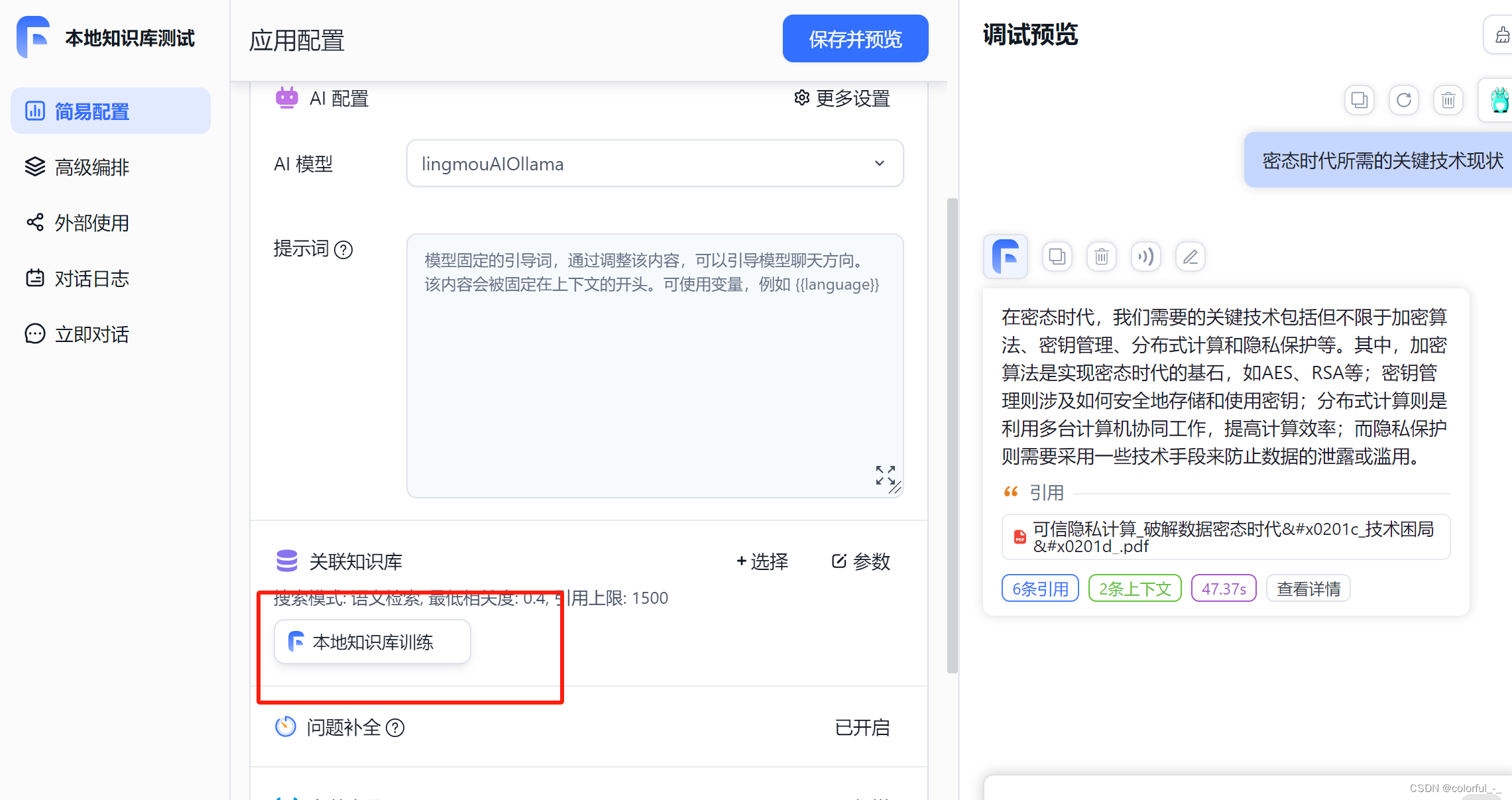
我是在本地cpu电脑上跑的qwen:b的模型,并在FastGPT中提问测试。由于我关联了知识库,会到知识库中找到相似的内容后发给本地大模型,但是我发现参数量比较小的模型不能很好处理较多的输入,所以导致时间很长才会有输出且内容不准确。相关截图如下:
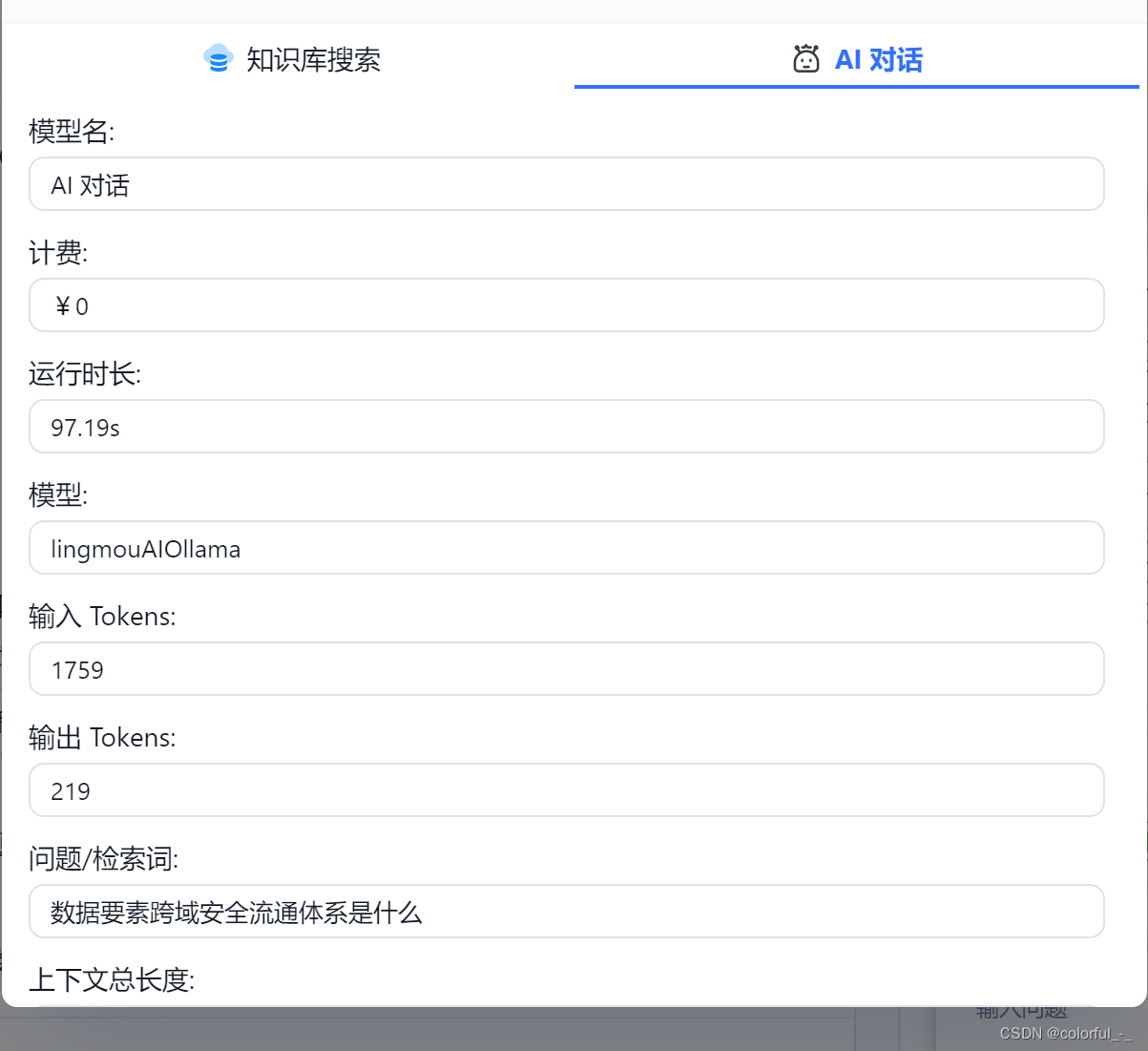
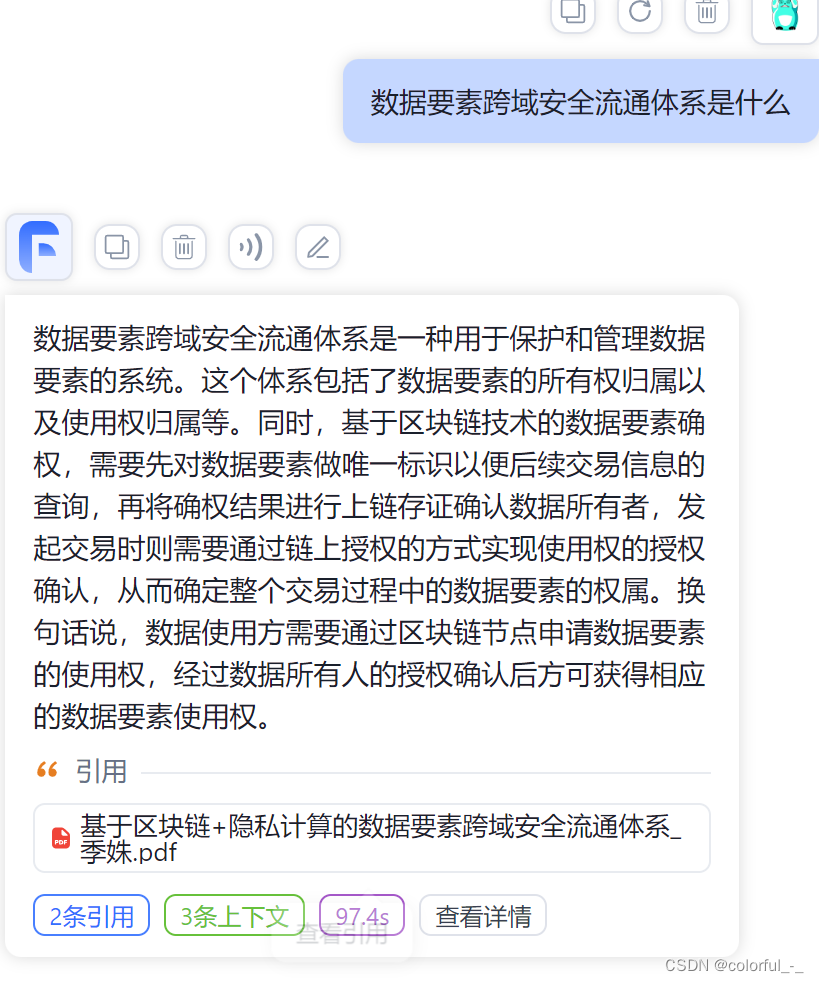
本地text-embedding模型
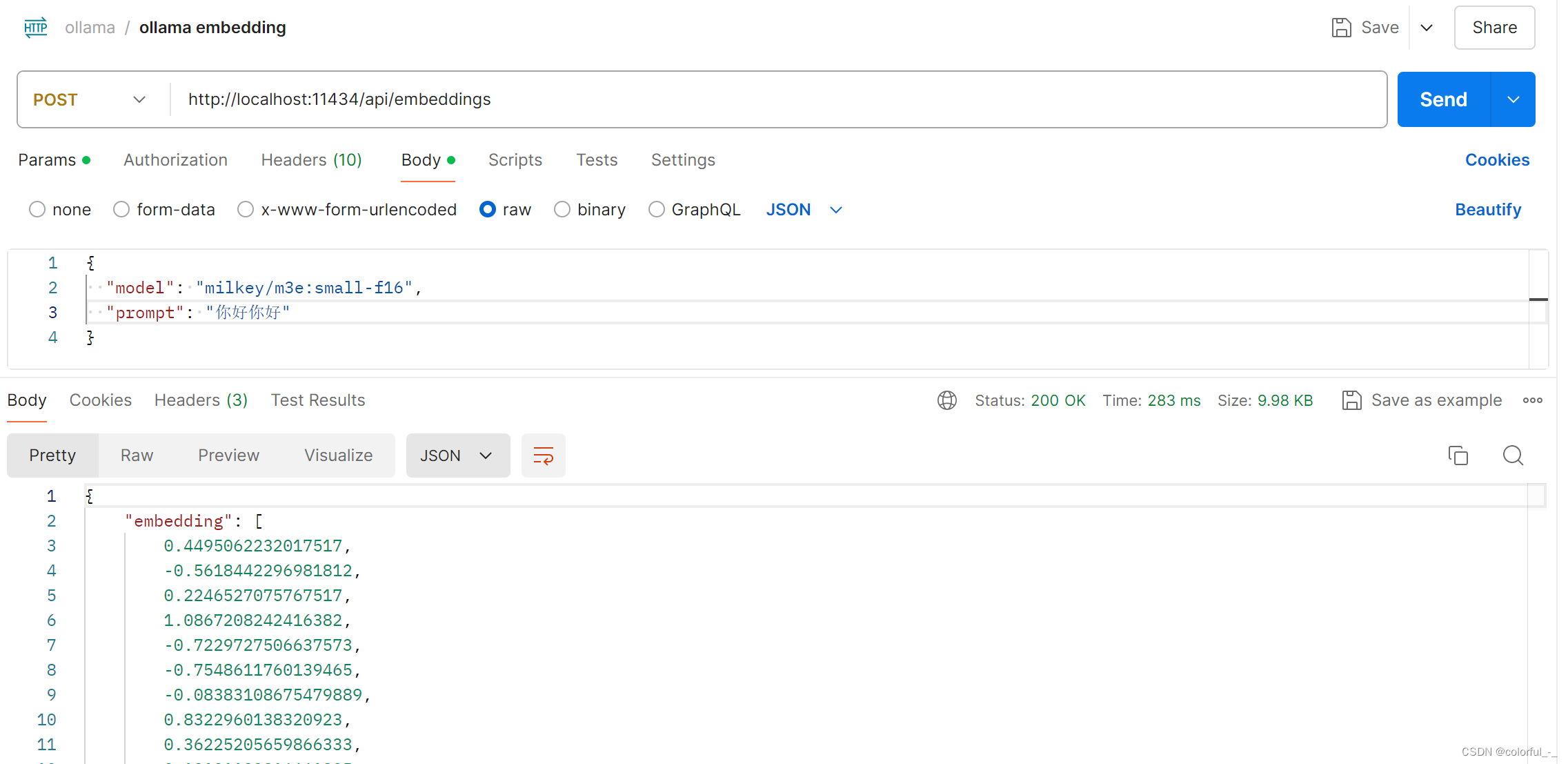
模型下载
使用ollama下载m3e模型,部署完成后可使用PostMan等工具调用
ollama pull milkey/m3e:small-f16
- 1
OneAPI一定要使用最新的版本,不然会出现报错

OneAPI配置渠道信息
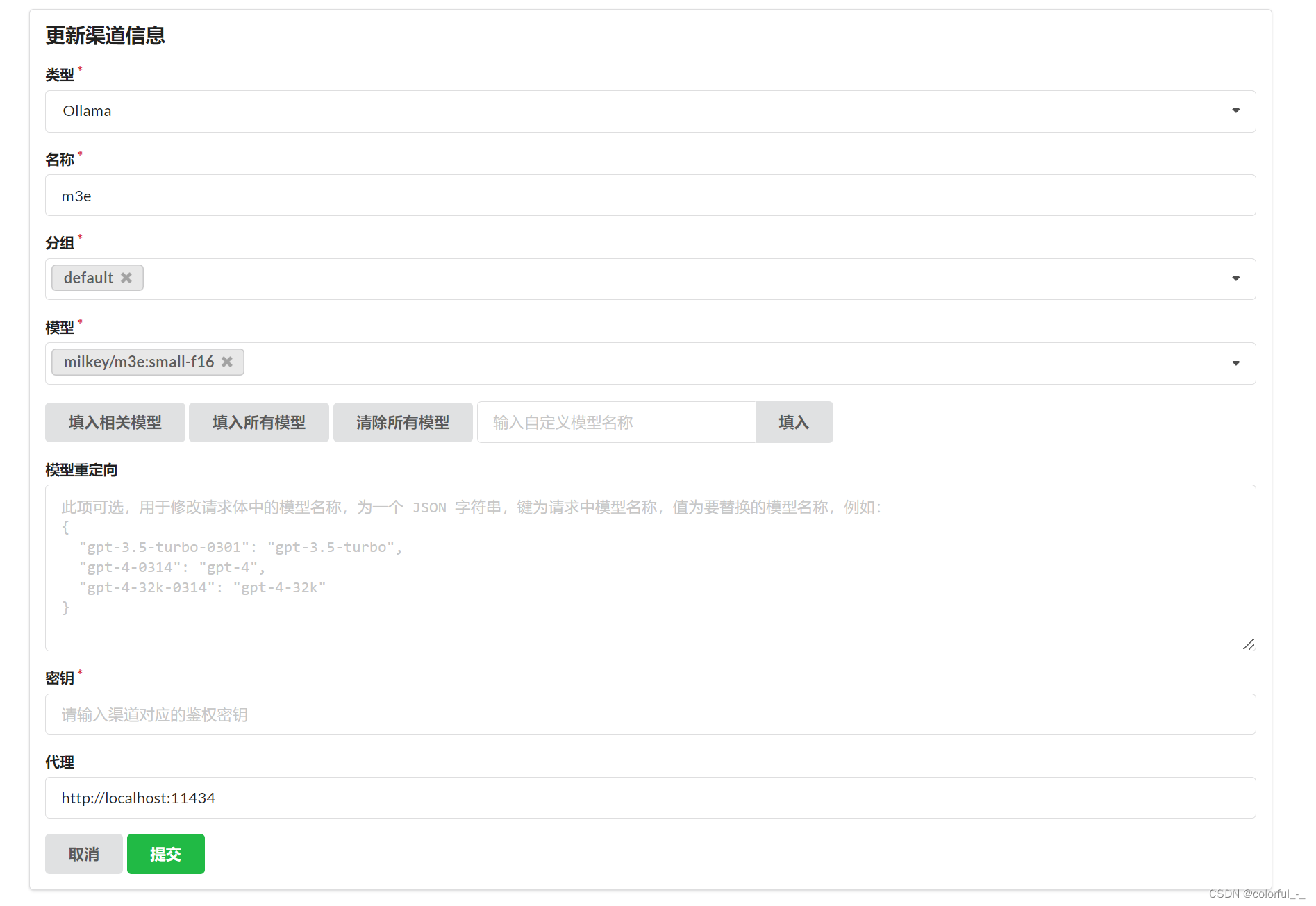
配置好后可使用postman调用
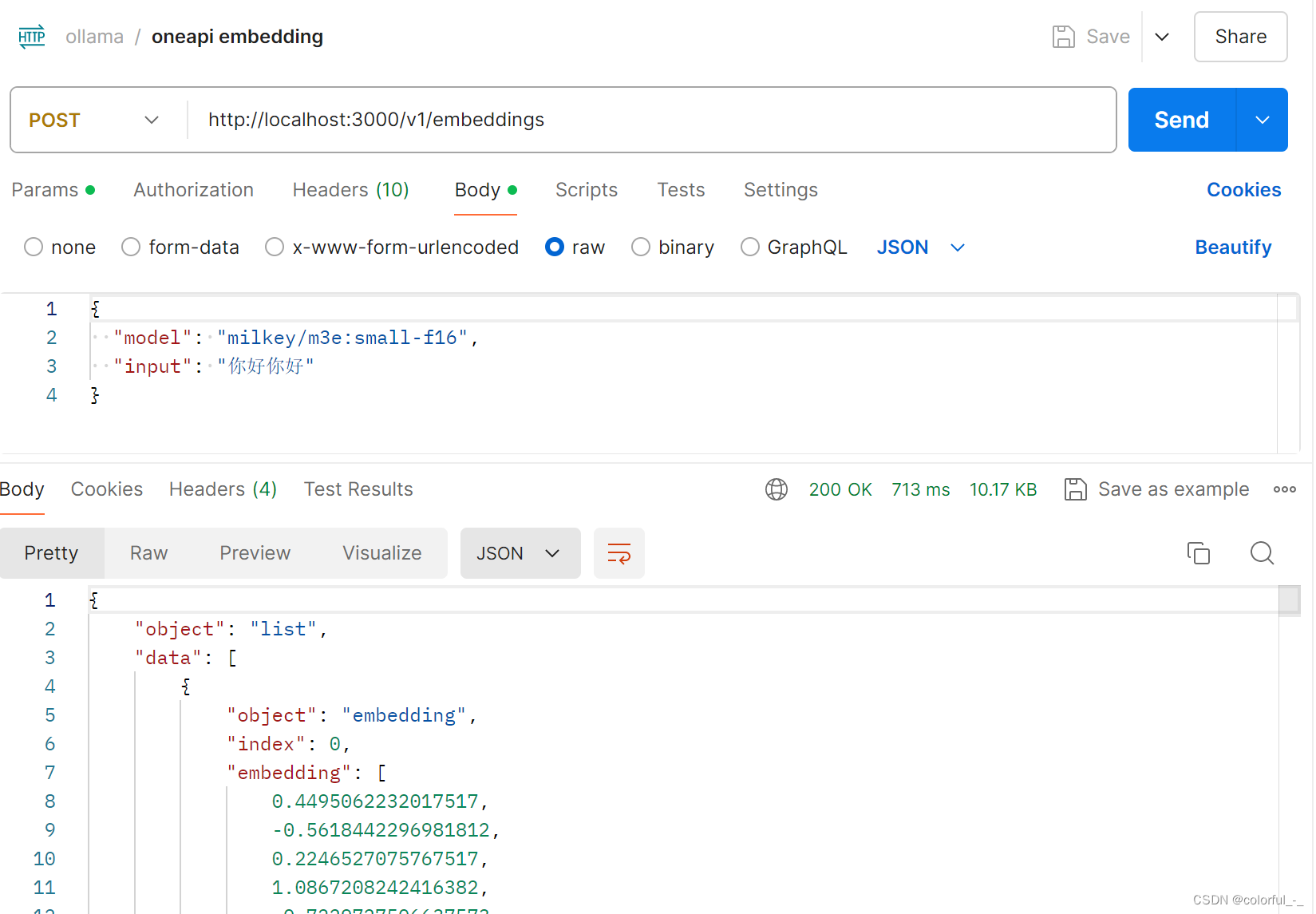
修改FastGPT的config.json文件

FastGPT上传知识库并训练
新建知识库选择本地知识库模型
上传知识库文件并训练
等待训练完成
FastGPT新建应用并测试
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/642933
推荐阅读
相关标签

