
- 1详解MySQL事务原理_mysql acdi原理
- 2httprunner测试框架3--har2case录制脚本
- 3leetcode 27. 移除元素_leetcode 27 java
- 4SourceTree 教程文档(安装并设置SourceTree)
- 5C++(QT)调用snap7库连接西门子plc_c++ 对接plc 西门子s7-400
- 6python:pycharm虚拟解释器报错环境位置目录为空
- 7Ubuntu16.04 使用Python获取本机IP_ubuntu python 自动读取本地ip
- 8Install Python 3.7.*_conda install python==3.7.2 -n
- 9Oracle:左连接、右连接、全外连接、(+)号详解_左外连接和右外连接详解
- 10近义句子转换软件 - 同义词转换器软件
KafKa——生产者发送消息流程_kafka生产者发送消息
赞
踩
一、kafka Producer生产者结构
二、生产者发送消息流程
2.1 消息发送模式
Kafka发送消息主要有三种模式:发后即忘(fire-and-forget),同步(sync)及异步(Async)
2.1.1 发后即忘
忽略send方法的返回值,不做任何处理。大多数情况下,消息会正常到达,而且生产者会自动重试,但有时会丢失消息。
- package com.msb.producer;
-
- import org.apache.kafka.clients.producer.KafkaProducer;
- import org.apache.kafka.clients.producer.ProducerRecord;
- import org.apache.kafka.common.serialization.StringDeserializer;
- import org.apache.kafka.common.serialization.StringSerializer;
-
- import java.util.Properties;
-
- /**
- * 类说明:kafak生产者
- */
- public class HelloKafkaProducer {
-
- public static void main(String[] args) {
- // 设置属性
- Properties properties = new Properties();
- // 指定连接的kafka服务器的地址
- properties.put("bootstrap.servers","127.0.0.1:9092");
- // 设置String的序列化
- properties.put("key.serializer", StringSerializer.class);
- properties.put("value.serializer", StringSerializer.class);
-
- // 构建kafka生产者对象
- KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
- try {
- ProducerRecord<String,String> record;
- try {
- // 构建消息
- record = new ProducerRecord<String,String>("msb", "teacher","lijin");
- // 发送消息
- producer.send(record);
- System.out.println("message is sent.");
- } catch (Exception e) {
- e.printStackTrace();
- }
- } finally {
- // 释放连接
- producer.close();
- }
- }
-
-
- }

2.1.3 同步发送
获得send方法返回的Future对象,在合适的时候调用Future的get方法。参见代码。
- package com.msb.producer;
-
- import org.apache.kafka.clients.producer.Callback;
- import org.apache.kafka.clients.producer.KafkaProducer;
- import org.apache.kafka.clients.producer.ProducerRecord;
- import org.apache.kafka.clients.producer.RecordMetadata;
- import org.apache.kafka.common.serialization.StringSerializer;
-
- import java.util.Properties;
- import java.util.concurrent.Future;
-
- /**
- * 类说明:发送消息--同步模式
- */
- public class SynProducer {
-
- public static void main(String[] args) {
- // 设置属性
- Properties properties = new Properties();
- // 指定连接的kafka服务器的地址
- properties.put("bootstrap.servers","127.0.0.1:9092");
- // 设置String的序列化
- properties.put("key.serializer", StringSerializer.class);
- properties.put("value.serializer", StringSerializer.class);
-
- // 构建kafka生产者对象
- KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
- try {
- ProducerRecord<String,String> record;
- try {
- // 构建消息
- record = new ProducerRecord<String,String>("msb", "teacher2333","lijin");
- // 发送消息
- Future<RecordMetadata> future =producer.send(record);
- RecordMetadata recordMetadata = future.get();
- if(null!=recordMetadata){
- System.out.println("offset:"+recordMetadata.offset()+","
- +"partition:"+recordMetadata.partition());
- }
- } catch (Exception e) {
- e.printStackTrace();
- }
- } finally {
- // 释放连接
- producer.close();
- }
- }
-
-
-
-
- }
2.1.3 异步发送
实现接口org.apache.kafka.clients.producer.Callback,然后将实现类的实例作为参数传递给send方法。
- package com.msb.producer;
-
- import org.apache.kafka.clients.producer.Callback;
- import org.apache.kafka.clients.producer.KafkaProducer;
- import org.apache.kafka.clients.producer.ProducerRecord;
- import org.apache.kafka.clients.producer.RecordMetadata;
- import org.apache.kafka.common.serialization.StringSerializer;
-
- import java.util.Properties;
- import java.util.concurrent.Future;
-
- /**
- * 类说明:发送消息--异步模式
- */
- public class AsynProducer {
-
- public static void main(String[] args) {
- // 设置属性
- Properties properties = new Properties();
- // 指定连接的kafka服务器的地址
- properties.put("bootstrap.servers","127.0.0.1:9092");
- // 设置String的序列化
- properties.put("key.serializer", StringSerializer.class);
- properties.put("value.serializer", StringSerializer.class);
-
- // 构建kafka生产者对象
- KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
-
- try {
- ProducerRecord<String,String> record;
- try {
- // 构建消息
- record = new ProducerRecord<String,String>("msb", "teacher","lijin");
- // 发送消息
- producer.send(record, new Callback() {
- @Override
- public void onCompletion(RecordMetadata recordMetadata, Exception e) {
- if (e == null){
- // 没有异常,输出信息到控制台
- System.out.println("offset:"+recordMetadata.offset()+"," +"partition:"+recordMetadata.partition());
- } else {
- // 出现异常打印
- e.printStackTrace();
- }
- }
- });
- } catch (Exception e) {
- e.printStackTrace();
- }
- } finally {
- // 释放连接
- producer.close();
- }
- }
-
-
-
-
- }
2.1.4 异常处理
KafkaProducer中一般会有两种类型的异常:可重试异常和不可重试的异常。
常见的可重试异常:NetworkException、LeaderNotAvailableException、UnknownTopicOrPartitionException、NotEnoughReplicasException、NotCoordinatorException 等。比如NetworkException 表示网络异常,这个有可能是由于网络瞬时故障而导致的异常,可以通过重试解决;又比如LeaderNotAvailableException表示分区的leader副本不可用,这个异常通常发生在leader副本下线而新的 leader 副本选举完成之前,重试之后可以重新恢复
不可重试异常:RecordTooLargeException异常,暗示了所发送的消息太大,KafkaProducer对此不会进行任何重试,直接抛出异常。
对于可重试的异常,如果配置了 retries 参数,那么只要在规定的重试次数内自行恢复了,就不会抛出异常。retries参数的默认值为0,配置方式参考如下:
props.put("ProducerConfig.RETRIES_CONFIG",10);2.2 消息发送过程分析
2.2.1 拦截器
生产者生成某个消息后,首先会经历一个或者多个拦截器组成的拦截器链(当某个拦截器报错时,下一个拦截器会接着上一个执行成功的拦截器执行)
2.2.2 序列化器
当消息经过了所有的拦截器之后会来到序列化器进行序列化,会根据key和value的序列化配置进行序列化消息内容,生产者和消费者必须使用相同的key-value序列方式
- // 消息key序列化
- properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
- // 消息value序列化
- properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
2.2.3 分区器
经过序列化后,会根据自定义的分区器或者默认的分区器进行获取消息的所属分区,自定义分区器可以参考下面。
当消息的key存在时,首先获取当前topic下的所有分区器,然后对key进行求hash值,根据hash值和分区总数进行取余,获取所属的分区。
如果key不存在时,会根据topic获取一个递增的数值,然后通过和分区数进行取余获取所属的分区
默认分区器源码:
- public class DefaultPartitioner implements Partitioner {
-
- private final ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap<>();
-
- public void configure(Map<String, ?> configs) {}
-
- public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
- List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
- int numPartitions = partitions.size();
- if (keyBytes == null) {
- int nextValue = nextValue(topic);
- List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
- if (availablePartitions.size() > 0) {
- int part = Utils.toPositive(nextValue) % availablePartitions.size();
- return availablePartitions.get(part).partition();
- } else {
- // no partitions are available, give a non-available partition
- return Utils.toPositive(nextValue) % numPartitions;
- }
- } else {
- // hash the keyBytes to choose a partition
- return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
- }
- }
-
- private int nextValue(String topic) {
- AtomicInteger counter = topicCounterMap.get(topic);
- if (null == counter) {
- counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
- AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
- if (currentCounter != null) {
- counter = currentCounter;
- }
- }
- return counter.getAndIncrement();
- }
-
- public void close() {}
-
- }
自定义分区器:
- public class CustomerPartitions implements Partitioner{
- @Override
- public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
- int partition = 0;
- if(key == null) {
- } else {
- String keyStr = key.toString();
- if(keyStr.contains("Test")) {
- partition = 1;
- } else {
- partition = 2;
- }
- }
- return partition;
- }
-
- @Override
- public void close() {
-
- }
-
- @Override
- public void configure(Map<String, ?> configs) {
-
- }
- }
2.2.4 生产者线程
https://blog.csdn.net/dreamcatcher1314/category_12064664.html
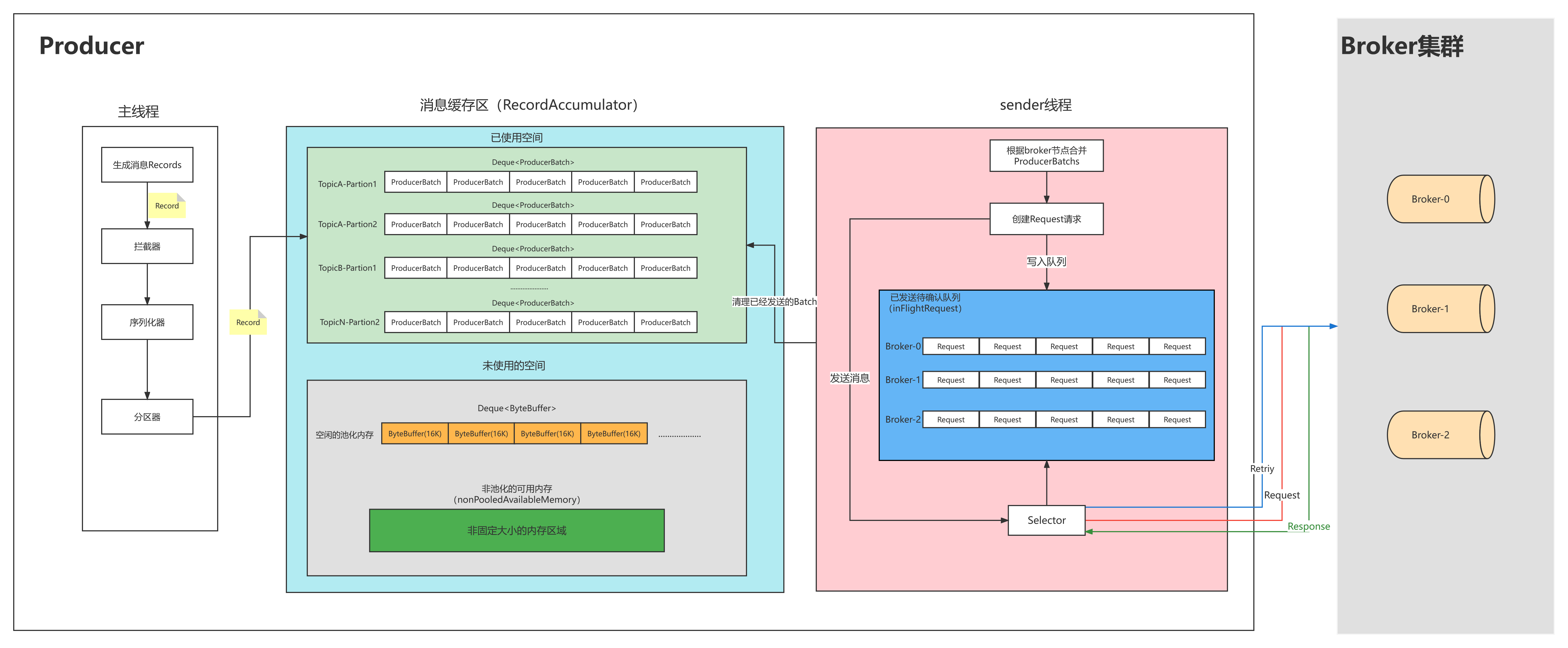
整个生产者客户端由两个线程协调进行,这两个线程分别是主线程和Sender线程(发送线程)。在主线程中由kafkaProducer创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中,Sender线程负责从RecordAccumulator中获取消息并将其发送到Kafka中。
主线程发送过来的消息都会被追加到RecordAccumulator的某个双端队列(Deque<ProducerBatch>)中(根据topic和分区可以去l顶一个双端队列,队列中的内容为<ProducerBatch>),新的消息会被放到队列的最后一个节点上。Sender读取消息的时候,从双端队列的头部读取。
当生产者发送消息的速度超过发送到服务器的速度,会导致生产者空间不足,这时候kafkaProducer的send()方法调用要么被阻塞,要么抛出异常,这个取决于参数max.block.ms的配置,此参数的默认值为60S
前置知识:
1、RecordAccumulator:每一个生产者都会维护一个固定大小的内存空间,主要适用于合并单条消息,进行批量发送,提高吞吐量,减少带宽消耗。
2、RecordAccumulator的大小是可配置的,可以配置buffer.memory来修改缓冲区的大小,默认值为:32M
3、RecordAccumulator的内存结构分为两部分。
第一部分为已经使用的内存,这一部分存放了很多队列。每一个主题的每一个分区都会创建一个队列,来存放当前分区下等待发送的消息集合。
第二部分为未使用的内存,这一部分分为已经池化后的内存和未池化的整个剩余内存(nonPooledAvailableMemory)。池化内存的会根据bitch.size(默认值16K)的配置进行多个ByteBuffer,放入一个队列中。所有的剩余空间会形成一个未池化的剩余空间
当一条消息(ProducerRecord)流入RecordAccumulator时:
场景一:消息大小小于16K
会寻找消息分区对应的双端队列(没有则创建),再从这个双端队列尾部获取一个ProducerBatch(没有则新建)。
1.1 当最后的ProducerBatch+当前消息<= 16K时,会把当前消息放入的ProducerBatch中
1.2 当最后的ProducerBatch +当前消息 > 16K,此时消息不会放入到这个ProducerBatch中,而是会向池化的队列中获取一个ByteBuffer,把这个ByteBuffer放入到队列尾部,然后把消息放入到这个新增的ProducerBatch中
1.3 当最后的ProducerBatch +当前消息 > 16K,并且池化的队列中没有可用的ByteBuff时,内存此消息不会放入到这个ProducerBatch中,而是会向剩余队列未使用的内存空间(nonPooledAvailableMemory)申请一个大小为16K的内存空间,添加到池化队列尾部。然后把这个新增的的ProducerBatch添加到分区下的队列尾部,存储新的信息。
场景二:消息大小大于16K
1、当消息超过16K时,任何一个ProducerBatch都无法存储这个消息。此时会直接向剩余的空间(nonPooledAvailableMemory)的进行分配和当前的消息大小一样的内存空间,加到队列的尾部,然后存储消息,等待发送。此内存空间无法复用
2、当剩余的空间(nonPooledAvailableMemory) < 消息大小时,nonPooledAvailableMemory会向池化队列获取空间,每次获取一个ByteBuffer(16K),直到nonPooledAvailableMemory的空间大于或等于消息大小时。获取的ByteBuffer会经过jvm的GC垃圾回收。过程比较慢。当nonPooledAvailableMemory空间大于获取等于消息大小时,会把分配消息大小的空间放入分区队列的尾部,把消息存入这个ProducerBatch内。
2.2.5 Sender线程
1、sender获取请求
生产者中会有一个sender线程不断的获取消息和发送消息。Sender线程会不断的扫描RecordAccumulator中所有的ProducerBatch,如果ProducerBatch达到batch.size(默认16K)大小,或者最早的一个消息已经等待超过linger.ms(默认为0)时,这个ProducerBatch会被Sender线程收集到。由于不同的topic和分区会分到不同的broker节点上,sender线程会把发送到相同Broker节点的ProducerBatch合并在一个Request请求中,一个Request请求不超过max.request.size(默认= 1M)
2、sender发送请求
请求在从sender线程发往kafka之前还会保存到InFlightRequest<缓冲区>中,里面为每一个Broker分配了一个队列,InFlightRequest保存对象的具体形式为Map<NodeId,Deque<Request>>,它的主要作用是缓存已经发送出去但还没收到响应的请求(NodeId是一个String类型,表示节点编号)。新的请求会放在队列尾部,每个队列最多能容纳max.in.fligt.request.per.connection(默认值5)个Request,队列满了不会产生新的Request。
3、selector获取到的Request会发往对应的Broker节点。Broker节点收到Request会进行ACK确认这个Request
4、当收到Broker对某个Request的ACK后,会删除inFlightRequest队列中这个Request。然后调用clear方法清楚对应的ProducerBatch。
RecordAccumulator Clear清理的场景:
针对场景一的 ProducerBatch都会标记为删除,然后放入池化队列,不会进行GC,并且从nonPooledAvailableMemory获取的内存也不会归还给nonPooledAvailableMemory。任然放在池化队列中
针对场景二的超过16K的消息内存空间会被GC回收,然后作为nonPooledAvailableMemory的一部分。
三、Producer网络通信模型
3.1、网络模型图

从图中可以看出,KafkaProducer相当于客户端,与Sender调用层交互,Sender调用NetWorkClient
而Selector底层封装了JavaNIO的接口,心中有了Producer的网络模型大致轮廓后,我们接下来分析Producer的模型。
3.2 Sender源码分析
3.2.1 sender线程定义和创建:
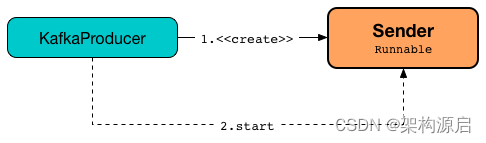
3.2.2 Sender线程定义
Sender继承了Runnable接口,而Sender线程是在KafkaProducer 的构造器中进行实例化和线程启动。当KafkaProducer被创建时,也会在构造器中实例化以 “kafka-producer-network-thread |[clientId]”命名的线程,而这个线程作为守护线程,伴随着KafkaProducer整个生命周期。
从下面的源码可以看出,Sender线程的run()方法中,核心发送入口方法为runOnce()。每一次执行runOnce()方法,Sender 将从RecordAccumulator记录累加器中获取1~max.request.size 个 ProducerBatch的消息数据,并最终将 ProduceRequests 发送到对应活动的 Kafka broker服务器中。
- public class Sender implements Runnable {
- /**
- * The main run loop for the sender thread
- */
- @Override
- public void run() {
- log.debug("Starting Kafka producer I/O thread.");
-
- // main loop, runs until close is called
- while (running) {
- try {
- runOnce();
- } catch (Exception e) {
- log.error("Uncaught error in kafka producer I/O thread: ", e);
- }
- }
-
- log.debug("Beginning shutdown of Kafka producer I/O thread, sending remaining records.");
-
- ....省略....
- }
- }
3.2.3 KafkaProducer中实例化Sender线程
- public class KafkaProducer<K, V> implements Producer<K, V> {
- ...省略
-
- // KafkaProducer构造器中,对Sender线程进行创建和线程启动
- KafkaProducer(ProducerConfig config,
- Serializer<K> keySerializer,
- Serializer<V> valueSerializer,
- ProducerMetadata metadata,
- KafkaClient kafkaClient,
- ProducerInterceptors<K, V> interceptors,
- Time time) {
- ...省略
- // Sender线程的创建和启动
- this.sender = newSender(logContext, kafkaClient, this.metadata);
- String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
- this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
- // Sender线程启动
- this.ioThread.start();
- ...省略
- }
-
- // Sender线程的创建
- Sender newSender(LogContext logContext, KafkaClient kafkaClient, ProducerMetadata metadata) {
- // 最大InFlightConnection请求链接数
- int maxInflightRequests = producerConfig.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION);
- // 请求超时时间
- int requestTimeoutMs = producerConfig.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);
- // 创建ChannelBuilder,提供服务Channel
- ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(producerConfig, time, logContext);
- ProducerMetrics metricsRegistry = new ProducerMetrics(this.metrics);
- // kafka数据传感器
- Sensor throttleTimeSensor = Sender.throttleTimeSensor(metricsRegistry.senderMetrics);
- // 创建KafkaClient客户端,默认为NetworkClient
- KafkaClient client = kafkaClient != null ? kafkaClient : new NetworkClient(
- new Selector(producerConfig.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),
- this.metrics, time, "producer", channelBuilder, logContext),
- metadata,
- clientId,
- maxInflightRequests,
- producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
- producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
- producerConfig.getInt(ProducerConfig.SEND_BUFFER_CONFIG),
- producerConfig.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),
- requestTimeoutMs,
- producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),
- producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),
- time,
- true,
- apiVersions,
- throttleTimeSensor,
- logContext);
-
- short acks = Short.parseShort(producerConfig.getString(ProducerConfig.ACKS_CONFIG));
- // 创建Sender线程
- return new Sender(logContext,
- client,
- metadata,
- this.accumulator,
- maxInflightRequests == 1,
- producerConfig.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
- acks,
- producerConfig.getInt(ProducerConfig.RETRIES_CONFIG),
- metricsRegistry.senderMetrics,
- time,
- requestTimeoutMs,
- producerConfig.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),
- this.transactionManager,
- apiVersions);
- }
-
- }
3.2.4 Sender的实例化参数
参数和实现功能说明
InFlightRequest: 飞行途中的请求,Sender线程发送到Kafka之前会保存数据到InFlightRequest中,主要作用是缓存已经发送但未接收到响应的请求,保存的数据模型为Map<NodeId,Deque<Request>>。
KafkaProducer 在创建Sender时会设置如下属性:
1、max.in.flight.requests.per.connection(maxInflightRequests): 设置每一个InFlightRequest链接最多缓存多少个未收到响应的请求,默认值为5。如果缓存的数据到达了最大值,则消息发送处于阻塞状态。如果需要保证消息顺序发送,可以将配置设置为1,但会影响到消息发送的执行效率,降低消息发送的吞吐量
2、request.timeout.ms(requestTimeoutMs):
KafkaProducer 等待请求响应的最长时间,默认值为 30000 ms。 请求超时之后可以选择进行重试。 注意这个参数需要比 broker 端参数 replica.lag.time.max.ms 的值要大,这样可以减少因客户端重试而引起的消息重复的概率。
3、max.request.size
这个参数用来限制生产者客户端能够发送的消息的最大值,默认值为 1048576 B,即 1 MB。 一般情况下,这个默认值就可以满足大多数的应用场景了。 不建议盲目地增大这个参数的配置值,尤其是在对 Kafka 整体脉络没有足够把控的时候。 因为这个参数还涉及一些其他参数的联动,比如 broker 端的 message.max.bytes 参数,如果配置错误可能会引起一些不必要的一场。 比如讲 broker 端端 message.max.bytes 参数配置为 10, 而 max.request.size 参数配置为 20,那么当我们发送一条消息大小为 15 的消息时,生产者客户端就会报出异常: org.apache.kafka.common.errors.RecordTooLargeException: The reqeust included a message larger than the max message size the server will accept.
4、retries 和 retry.backoff.ms retries 参数用来配置生产者重试的次数,默认值为 0,即发生异常的时候不进行任何的重试动作。 消息在从生产者发出道成功写入服务器之前可能发生一些临时性的异常,比如网络抖动、Leader 副本的选举等,这种异常往往是可以自行恢复的,生产者可以通过配置 retries 大于 0 的值,以此通过内部重试来恢复而不是一味的将异常抛给生产者的应用程序。 如果重试达到设定的次数,那么生产者就会放弃重试并返回异常。 不过并不是所有的异常都是可以通过重试来解决的,比如消息太大,超过 max.request.size 参数配置的值时,这种方式就不行了。 重试还和另一个参数 retry.backoff.ms 有关,这个参数的默认值为 100,它用来设定两次重试之间的时间间隔,避免无效的频繁重试。 在配置 retries 和 retry.backoff.ms 之前,最好先估算一下可能的异常恢复时间,这样可以设定总的重试时间大于这个异常恢复时间,以此来避免生产者过早地放弃重试。 Kafka 可以保证同一个分区中的消息时有序的。 如果生产者按照一定的顺序发送消息,那么这些消息也会顺序的写入分区,进而消费者也可以按照同样的顺序消费它们。
5、acks : 消息应答机制,默认值即为 1
ack =1 —— 生产者发送消息后,只要分区的leader副本写入消息成功,则生产者客户端就会收到服务器的成功响应,视为消息发送成功。
ack 为1 的时候,保证客消息发送的吞吐量,但是在消息可靠性上不能完全保证。会出现如下的情况:
a、如果消息无法写入leader副本,则生产者会收到错误响应,无法写入的情况通常情况为:leader副本崩溃、leader副本的重新选举期间。所以为了避免消息发送丢失的情况,生产者可以进行消息发送的失败重试。
b、在极端情况下可能会出现,消息写入成功写入leader副本,并且生产者客户端收到了服务器的成功响应。而此时leader副本崩溃,但是其他follower副本未及时更新到leader副本的数据,在新选举出的leader副本中则服务查询到这一条数据的记录,也就出现了消息丢失的情况。
acks = 0—— 生成者发送消息后,不用等待任何服务端的成功与否的响应。如果消息写入到Kafak服务端出现异常,从而可能导致消息丢失的情况。设置为0 可以达到消息发送的最大吞吐量,但是也可能出现消息丢失的情况。
acks = -1 或 acks = all ——生产者发送后,需要等待 leader副本将消息同步到所有follower副本,则返回消息成功,从而保证消息的可靠性。
3.2.5 Sender的线程唤起执行wakeup
首先,我们需要知道Sender线程的执行是在哪里阻塞的。Kafka客户端的底层网络通信是通过NIO实现,Kafka 的Selecotor类中,我们可以看到java.nio.channels.Selector nioSelector,对Kafak服务器的通信核心是通过nioSelector 来实现。
当调用nioSelector.select()方法时,调用者线程会进入阻塞状态,直到有就绪的Channel才会返回。而java.nio.channels.Selector 也提供了从阻塞状态唤起的方式,则是可以通过其他的线程调用nioSelector.wakeup进行阻塞线程的唤醒,则select()方法也会立即返回。
- public class Selector implements Selectable, AutoCloseable {
-
- private final java.nio.channels.Selector nioSelector;
-
- /**
- * Interrupt the nioSelector if it is blocked waiting to do I/O.
- */
- @Override
- public void wakeup() {
- this.nioSelector.wakeup();
- }
-
- }
wake()被调用的地方:
KafkaProducer 的doSend(),initTransactions(), sendOffsetsToTransaction(), commitTransaction(), abortTransaction(), waitOnMetadata()和 flush()方法
Sender类的 initiateClose()方法
3.3 Sender线程核心流程源码分析
Sender线程的状态通过两个变量控制,分别是running和forceClose
running: Sender线程是否正在运行中
forceClose: 是否强制关闭正在发送和待发送的消息,
强制关闭状态,忽略未发送和正在发送中的消息
分三种情况
1、状态一 running状态:
sender线程处于running状态,则一直循环执行runOnce()
2、状态二 非强制关闭状态:
a、停止接受新的请求,如果事务管理器、累加器或等待确认的过程中可能仍有请求,请等到这些完成。
b、如果任何提交或中止未通过事务管理器的队列,则中止事务
3、强制关闭状态
a、将所有未完成的事务请求和batchs置为失败,并唤醒正在等待的线程
b、我们需要使所有不完整的事务请求和批处理失败,并唤醒等待未来的线程。
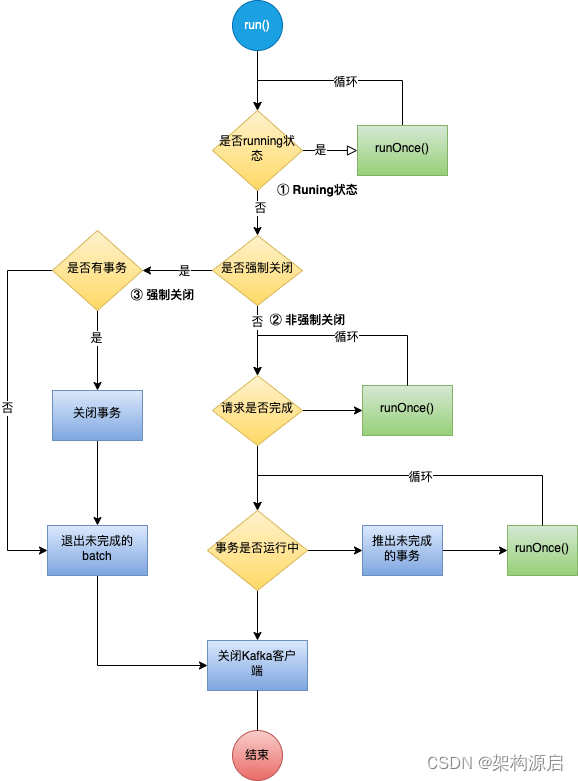
3.3.1 Sender.run方法分析
- // sender线程运行状态
- private volatile boolean running;
-
- // 强制关闭状态,忽略未发送和正在发送中的消息
- private volatile boolean forceClose;
-
- @Override
- public void run() {
- log.debug("Starting Kafka producer I/O thread.");
-
- // 状态一 running状态: sender线程处于running状态,则一直循环执行runOnce()
- while (running) {
- try {
- runOnce();
- } catch (Exception e) {
- log.error("Uncaught error in kafka producer I/O thread: ", e);
- }
- }
-
- log.debug("Beginning shutdown of Kafka producer I/O thread, sending remaining records.");
-
- // 状态二 非强制关闭状态
- //停止接受新的请求,如果事务管理器、累加器或等待确认的过程中可能仍有请求,请等到这些完成。
- while (!forceClose && ((this.accumulator.hasUndrained() || this.client.inFlightRequestCount() > 0) || hasPendingTransactionalRequests())) {
- try {
- runOnce();
- } catch (Exception e) {
- log.error("Uncaught error in kafka producer I/O thread: ", e);
- }
- }
-
-
- //如果任何提交或中止未通过事务管理器的队列,则中止事务
- while (!forceClose && transactionManager != null && transactionManager.hasOngoingTransaction()) {
- if (!transactionManager.isCompleting()) {
- log.info("Aborting incomplete transaction due to shutdown");
- transactionManager.beginAbort();
- }
- try {
- runOnce();
- } catch (Exception e) {
- log.error("Uncaught error in kafka producer I/O thread: ", e);
- }
- }
-
- // 状态三 强制关闭状态
- if (forceClose) {
- // 将所有未完成的事务请求和batchs置为失败,并唤醒正在等待的线程
- //我们需要使所有不完整的事务请求和批处理失败,并唤醒等待未来的线程。
- if (transactionManager != null) {
- log.debug("Aborting incomplete transactional requests due to forced shutdown");
- transactionManager.close();
- }
- log.debug("Aborting incomplete batches due to forced shutdown");
- this.accumulator.abortIncompleteBatches();
- }
- try {
- // KafkaClient Kafka客户端关闭
- this.client.close();
- } catch (Exception e) {
- log.error("Failed to close network client", e);
- }
-
- log.debug("Shutdown of Kafka producer I/O thread has completed.");
- }
3.2.2 Sender.runOnce()方法逻辑
从run()方法的逻辑可以看出,runOnce()方法是消息发送的入口
a、当事务存在的时候,进行事务处理逻辑,详细的事务处理,将在后续技术文章中进行讲解
b、 调用sendProducerData()方法,则是Kafka消息发送的核心处理逻辑
- void runOnce() {
- if (transactionManager != null) {
- try {
- transactionManager.maybeResolveSequences();
-
- // do not continue sending if the transaction manager is in a failed state
- //如果事务管理器处于失败状态,则不要继续发送
- if (transactionManager.hasFatalError()) {
- RuntimeException lastError = transactionManager.lastError();
- if (lastError != null)
- maybeAbortBatches(lastError);
- client.poll(retryBackoffMs, time.milliseconds());
- return;
- }
-
- // Check whether we need a new producerId. If so, we will enqueue an InitProducerId
- //检查我们是否需要一个新的 producerId。如果是这样,我们将入队一个 InitProducerId
- // request which will be sent below
- transactionManager.bumpIdempotentEpochAndResetIdIfNeeded();
-
- if (maybeSendAndPollTransactionalRequest()) {
- return;
- }
- } catch (AuthenticationException e) {
- // This is already logged as error, but propagated here to perform any clean ups.
- log.trace("Authentication exception while processing transactional request", e);
- transactionManager.authenticationFailed(e);
- }
- }
-
- long currentTimeMs = time.milliseconds();
- //Sender线程每次循环执行的地方
- long pollTimeout = sendProducerData(currentTimeMs);
- // 关于Socket的读写操作
- client.poll(pollTimeout, currentTimeMs);
- }
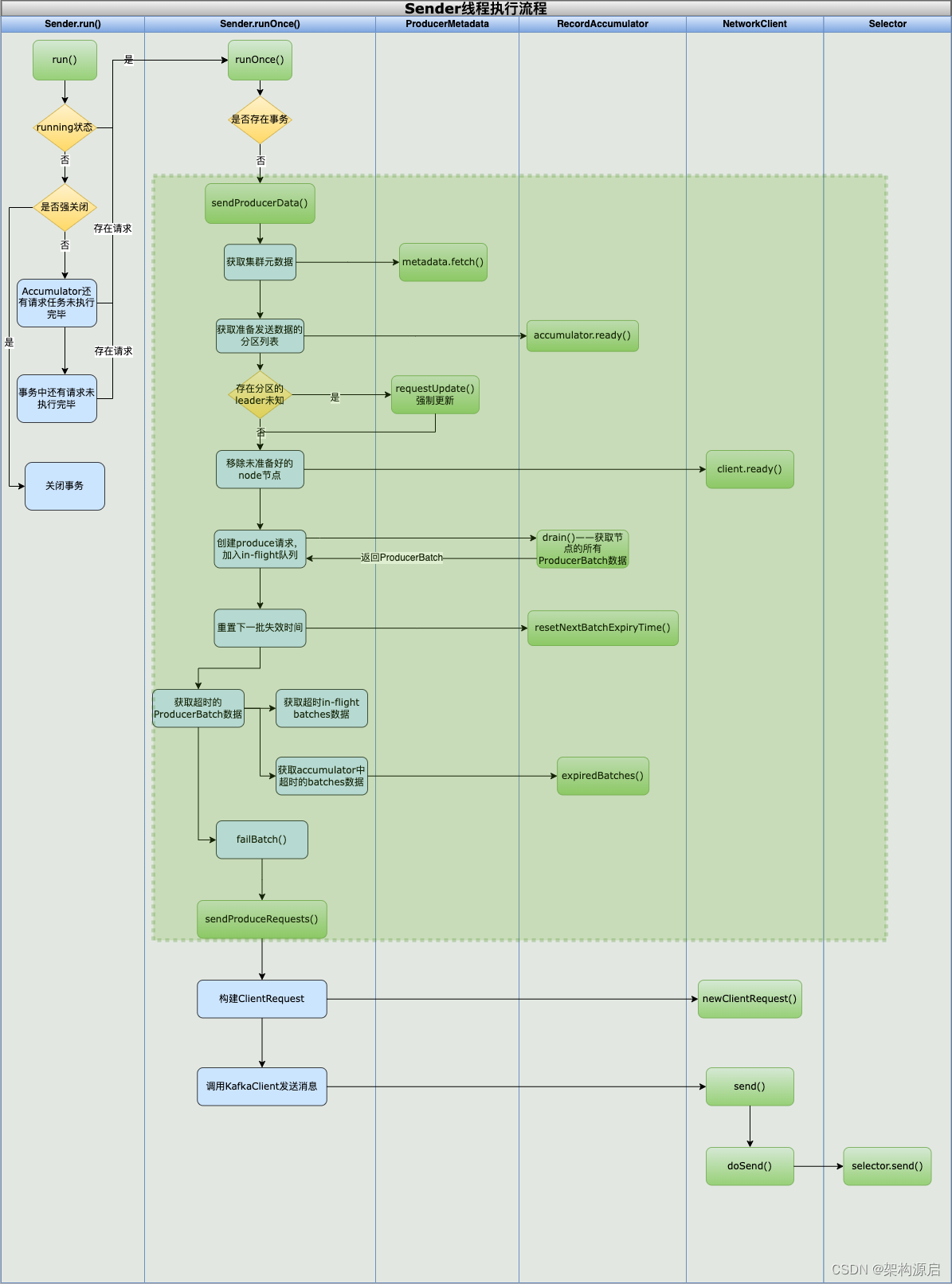
3.2.3 Sender线程sendProducerData()的核心逻辑梳理
虚线框内的逻辑,正式sendProducerData()的实现逻辑
- private long sendProducerData(long now) {
- // 获取当前运行并且未阻塞的Kafka集群元数据信息
- Cluster cluster = metadata.fetch();
- // get the list of partitions with data ready to send
- // 获取准备发送数据的分区(node节点)集合
- RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
-
- // if there are any partitions whose leaders are not known yet, force metadata update
- // 如果存在分区的leader未知,则强制更新元数据
- if (!result.unknownLeaderTopics.isEmpty()) {
- //未知leader的主题集包含leader选举待定的topic以及可能已过期的topic。
- // 再次将topic添加到ProducerMetadata元数据中,以确保包含该topic并请求元数据更新,因为这些消息要需要发送到对应主题。
- for (String topic : result.unknownLeaderTopics)
- this.metadata.add(topic, now);
-
- log.debug("Requesting metadata update due to unknown leader topics from the batched records: {}",
- result.unknownLeaderTopics);
- this.metadata.requestUpdate();
- }
-
- // 移除还没有准备好的node节点
- Iterator<Node> iter = result.readyNodes.iterator();
- long notReadyTimeout = Long.MAX_VALUE;
- while (iter.hasNext()) {
- Node node = iter.next();
- if (!this.client.ready(node, now)) {
- //仅更新延迟统计的readyTimeMs,以便每次批处理就绪时都向前移动(那么readyTimeM和drainTimeMs之间的差异将表示数据等待节点的时间)。
- this.accumulator.updateNodeLatencyStats(node.id(), now, false);
- iter.remove();
- notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
- } else {
-
- //更新readyTimeMs和drainTimeMs,这将“重置”节点延迟。
- this.accumulator.updateNodeLatencyStats(node.id(), now, true);
- }
- }
-
-
- // 创建produce请求,加入到Map<TopicPartition, List<ProducerBatch>> inFlightBatches中
- Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
- addToInflightBatches(batches);
-
- if (guaranteeMessageOrder) {
- // Mute all the partitions drained
- // 将所有排水分区静音
- for (List<ProducerBatch> batchList : batches.values()) {
- for (ProducerBatch batch : batchList)
- this.accumulator.mutePartition(batch.topicPartition);
- }
- }
-
- // 重置消息累加器中下一批次的过期时间
- accumulator.resetNextBatchExpiryTime();
- // 获取已达到超时待发送的in-flight batches 数据
- List<ProducerBatch> expiredInflightBatches = getExpiredInflightBatches(now);
- // 获取累积器中放置时间过长且需要过期的批次列表。
- List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(now);
- expiredBatches.addAll(expiredInflightBatches);
-
-
- //如果之前已将过期批次发送给代理,请重置生产者id。同时更新过期批次的指标。请参阅@TransactionState.resetIdempotentProducerId的文档,以了解为什么需要在此处重置生产者id。
- if (!expiredBatches.isEmpty())
- log.trace("Expired {} batches in accumulator", expiredBatches.size());
- for (ProducerBatch expiredBatch : expiredBatches) {
- String errorMessage = "Expiring " + expiredBatch.recordCount + " record(s) for " + expiredBatch.topicPartition
- + ":" + (now - expiredBatch.createdMs) + " ms has passed since batch creation";
- failBatch(expiredBatch, new TimeoutException(errorMessage), false);
- if (transactionManager != null && expiredBatch.inRetry()) {
- // This ensures that no new batches are drained until the current in flight batches are fully resolved.
- //这可确保在当前in-flight batches 完全解决之前,不会排出新批次。
- transactionManager.markSequenceUnresolved(expiredBatch);
- }
- }
- sensors.updateProduceRequestMetrics(batches);
-
-
- //如果我们有任何节点准备发送+具有可发送数据,则轮询0超时,这样可以立即循环并尝试发送更多数据。
- // 否则,超时将是下一批到期时间与检查数据可用性的延迟时间之间的较小值。
- // 请注意,由于延迟、后退等原因,节点可能有尚未发送的数据。这特别不包括具有尚未准备好发送的可发送数据的节点,因为它们会导致繁忙的循环。
- long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
- pollTimeout = Math.min(pollTimeout, this.accumulator.nextExpiryTimeMs() - now);
- pollTimeout = Math.max(pollTimeout, 0);
- if (!result.readyNodes.isEmpty()) {
- log.trace("Nodes with data ready to send: {}", result.readyNodes);
-
- //如果某些分区已经准备好发送,则选择时间将为0;
- // 否则,如果某个分区已经积累了一些数据,但还没有准备好,则选择时间将是现在与其延迟到期时间之间的时间差;
- // 否则,选择时间将是现在与元数据到期时间之间的时间差;
-
- pollTimeout = 0;
- }
- // 消息请求发送
- sendProduceRequests(batches, now);
- return pollTimeout;
- }
获取当前运行的元数据
Cluster cluster = metadata.fetch();从RecordAccumulator 消息累加器中,获取到准备发送数据的分区集合
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);移除未准备好的node节点
检查当前kafkaProducer是否与目标建立了网络连接,如果没有建立连接,则尝试初始化网络连接,如果初始化失败,则直接返回false,表示此时不适合向该Node发送请求。
其次就是检查当前已发送但是未响应的请求是否已经达到上线,要是有很多种这种请求存在,可能是broker处理能力不足,此时也不适合继续发送请求
除了进行网络方面的检查之外,还会检查kafka元数据是否需要更新,如果需要更新的话,也不能发送请求。毕竟使用过期的或是错误的元数据来发送数据,请求也不会发送成功
不适合发送请求的 Node 节点会从 readyNodes 集合中删除。
- // RecordAccumulator.ReadyCheckResult 获取到所有待发送的节点
- Iterator<Node> iter = result.readyNodes.iterator();
- long notReadyTimeout = Long.MAX_VALUE;
- while (iter.hasNext()) {
- Node node = iter.next();
- // 通过KafkaClient进行检查,node节点是否已经准备好
- if (!this.client.ready(node, now)) {
-
- //仅更新延迟统计的readyTimeMs,以便每次批处理就绪时都向前移动(那么readyTimeM和drainTimeMs之间的差异将表示数据等待节点的时间)。
- this.accumulator.updateNodeLatencyStats(node.id(), now, false);
- iter.remove();
- notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
- } else {
- // Update both readyTimeMs and drainTimeMs, this would "reset" the node
- // latency.
- //更新readyTimeMs和drainTimeMs,这将“重置”节点延迟。
- this.accumulator.updateNodeLatencyStats(node.id(), now, true);
- }
- }
3.2.4 创建produce请求,将ProducerBatch加入到InFlightBatches中
调用记录累加器RecordAccumlator.drain(),获取当前可以集群下的所有数据,并将他们整理成一个批次列表。
将消息放入到Map<TopicPartition, List<ProducerBatch>> inFlightBatches 的队列中,记录正在发送这一批数据。
如果需要进行顺序消息发送,则将通过数据ProducerBatch的主题信息记录到RecordAccumlator的Set<TopicPartition> muted中。
-
- //获当前可以集群下的所有数据,并将它们整理成一个批次列表
- Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
- // 加入到InFlightBatch队列中
- addToInflightBatches(batches);
-
- if (guaranteeMessageOrder) {
- // 保证消息顺序发送
- // 将所有批次的主题加入到Set<TopicPartition> muted中
- for (List<ProducerBatch> batchList : batches.values()) {
- for (ProducerBatch batch : batchList)
- this.accumulator.mutePartition(batch.topicPartition);
- }
- }
3.2.5 获取已经超时待发送的消息数据
重置消息累加器下一批次的过期时间
获取已经达到超时待发送的in-flight-batches批次数据
获取累加器中放置时间过长且需要过期批次的数据
将超时待发送批次数据进行汇总
- // 重置消息累加器中下一批次的过期时间
- accumulator.resetNextBatchExpiryTime();
- // 获取已达到超时待发送的in-flight batches 数据
- List<ProducerBatch> expiredInflightBatches = getExpiredInflightBatches(now);
- // 获取累积器中放置时间过长且需要过期的批次列表。
- List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(now);
- expiredBatches.addAll(expiredInflightBatches);
3.3.6 处理已超时的消息批次,通知该批消息发送失败
- //如果之前已将过期批次发送给代理,请重置生产者id。同时更新过期批次的指标。请参阅@TransactionState.resetIdempotentProducerId的文档,以了解为什么需要在此处重置生产者id。
- if (!expiredBatches.isEmpty())
- log.trace("Expired {} batches in accumulator", expiredBatches.size());
- for (ProducerBatch expiredBatch : expiredBatches) {
- String errorMessage = "Expiring " + expiredBatch.recordCount + " record(s) for " + expiredBatch.topicPartition
- + ":" + (now - expiredBatch.createdMs) + " ms has passed since batch creation";
- failBatch(expiredBatch, new TimeoutException(errorMessage), false);
- if (transactionManager != null && expiredBatch.inRetry()) {
- // This ensures that no new batches are drained until the current in flight batches are fully resolved.
- //这可确保在当前in-flight batches 完全解决之前,不会排出新批次。
- transactionManager.markSequenceUnresolved(expiredBatch);
- }
- }
- // 收集统计指标
- sensors.updateProduceRequestMetrics(batches);
3.3.7 构建请求,发送数据
- //如果我们有任何节点准备发送+具有可发送数据,则轮询0超时,这样可以立即循环并尝试发送更多数据。
- // 否则,超时将是下一批到期时间与检查数据可用性的延迟时间之间的较小值。
- // 请注意,由于延迟、后退等原因,节点可能有尚未发送的数据。这特别不包括具有尚未准备好发送的可发送数据的节点,因为它们会导致繁忙的循环。
- // 设置下一次的发送延时
- long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
- pollTimeout = Math.min(pollTimeout, this.accumulator.nextExpiryTimeMs() - now);
- pollTimeout = Math.max(pollTimeout, 0);
- if (!result.readyNodes.isEmpty()) {
- log.trace("Nodes with data ready to send: {}", result.readyNodes);
-
- //如果某些分区已经准备好发送,则选择时间将为0;
- // 否则,如果某个分区已经积累了一些数据,但还没有准备好,则选择时间将是现在与其延迟到期时间之间的时间差;
- // 否则,选择时间将是现在与元数据到期时间之间的时间差;
-
- pollTimeout = 0;
- }
-
- sendProduceRequests(batches, now);
3.4 Sender线程sendProduceRequest()的核心逻辑梳理
- /**
- * 从给定的记录批次创建生产请求
- */
- private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) {
- if (batches.isEmpty())
- return;
-
- final Map<TopicPartition, ProducerBatch> recordsByPartition = new HashMap<>(batches.size());
-
- // 找到创建记录集时使用的最小魔法版本
- byte minUsedMagic = apiVersions.maxUsableProduceMagic();
- for (ProducerBatch batch : batches) {
- if (batch.magic() < minUsedMagic)
- minUsedMagic = batch.magic();
- }
- // ProduceRequestData
- ProduceRequestData.TopicProduceDataCollection tpd = new ProduceRequestData.TopicProduceDataCollection();
-
- for (ProducerBatch batch : batches) {
- TopicPartition tp = batch.topicPartition;
- MemoryRecords records = batch.records();
-
- //如有必要,向下转换到使用的最小魔法的消息格式。
- // 通常情况下生产者开始构建批次以及我们发送请求的时间选择了基于过时元数据的消息格式。
- // 在最坏的情况下,如果选择使用新的消息格式,但发现代理不支持它,所系需要在客户端发送之前进行消息格式的向下转换。
- // 这旨在处理围绕集群升级的边缘情况,其中代理可能并非所有消息都支持相同的消息格式版本。
- // 例如,如果分区从代理迁移它支持新的魔法版本,但不支持,就需要转换。
- if (!records.hasMatchingMagic(minUsedMagic))
- records = batch.records().downConvert(minUsedMagic, 0, time).records();
- ProduceRequestData.TopicProduceData tpData = tpd.find(tp.topic());
- if (tpData == null) {
- tpData = new ProduceRequestData.TopicProduceData().setName(tp.topic());
- tpd.add(tpData);
- }
- tpData.partitionData().add(new ProduceRequestData.PartitionProduceData()
- .setIndex(tp.partition())
- .setRecords(records));
- recordsByPartition.put(tp, batch);
- }
-
- String transactionalId = null;
- if (transactionManager != null && transactionManager.isTransactional()) {
- transactionalId = transactionManager.transactionalId();
- }
-
- ProduceRequest.Builder requestBuilder = ProduceRequest.forMagic(minUsedMagic,
- new ProduceRequestData()
- .setAcks(acks)
- .setTimeoutMs(timeout)
- .setTransactionalId(transactionalId)
- .setTopicData(tpd));
- RequestCompletionHandler callback = response -> handleProduceResponse(response, recordsByPartition, time.milliseconds());
-
- // 创建clientRequest请求
- String nodeId = Integer.toString(destination);
- ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,
- requestTimeoutMs, callback);
- // 通过KafkaClient的实现类NetworkClient 调用发送
- client.send(clientRequest, now);
- log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
- }
转载:https://blog.csdn.net/qq_43719634/article/details/125964229
https://blog.csdn.net/dreamcatcher1314/article/details/127709763


