
- 1大数据方向毕业设计:热门选题合集及实践指南_大数据技术毕业设计选题方向
- 2Python OpenCV 入门 这篇就够了_opencv轻松入门 面向python
- 3Python魔法之旅-魔法方法(07)
- 4K8s(Kubernetes)常用命令
- 5AI大模型探索之路-基础篇5:GLM-4解锁国产大模型的全能智慧与创新应用_gml4模型
- 6喜报!多学科领域高分区SCI、EI期刊录用成功!
- 7智慧农田视频监控技术应用:智能监管引领农业新时代
- 8idea version control 找不到_idea2019jar包里面的controller路径搜不到
- 9Windows中 AppdData_window appdata locallow
- 10FPGA入门 关于Quartus 的安装教程_quartus prime 安装教程 csdn
路径规划算法
赞
踩
前言
随着机器人技术、智能控制技术、硬件传感器的发展,机器人在工业生产、军事国防以及日常生活等领域得到了广泛的应用。而作为机器人行业的重要研究领域之一,移动机器人行业近年来也到了迅速的发展。移动机器人中的路径规划便是重要的研究方向。移动机器人的路径规划方法主要分为传统的路径规划算法、基于采样的路径规划算法、智能仿生算法。传统的路径规划算法主要有A算法、Dijkstra算法、D算法、人工势场法,基于采样的路径规划算法有PRM算法、RRT算法,智能仿生路径规划算法有神经网络算法、蚁群算法、遗传算法等。
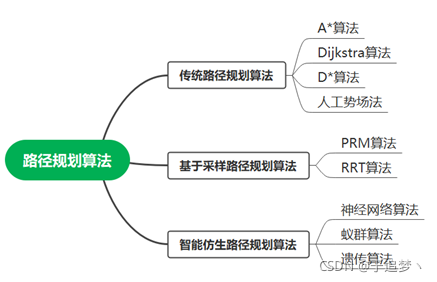
一、传统路径规划算法
1.Dijkstra算法
Dijkstra算法是Edsger Wybe Dijkstra在1956年提出的一种用来寻找图形中结点之间最短路径的算法。Dijkstra算法的基本思想是贪心思想,主要特点是以起始点为中心向外层层扩展,直到扩展到目标点为止。Dijkstra算法在扩展的过程中,都是取出未访问结点中距离该点距离最小的结点,然后利用该结点去更新其他结点的距离值。
Dijkstra算法流程:
1. 将初始点s放入到集合S中,初始时集合S中只有s;
2. 无自环的初始点s到自己的最短路径为0;
3. For(目标点ei不在集合S中):
4. 计算集合S中以外的所有结点到集合S中结点的最短距离,即从s出发,到达所有结点且只允许通过初始点s的最短路径。如果没有直达的通路,那么就设置为无穷,意味着暂时到达不了的结点。
5. While(集合V-S不是空集):
6. 选出第一次for循环之后在集合V-S中,且相对于集合S的最短路径中距离最短的目标点ej。
7. 将该目标点ej并入到集合S中。
8. 将目标点ej并入集合S之后会对V-S以外的顶点相对于集合S的最短路径长度产生影响。
9. For(更新S中的结点路径)
10. If(dist[s,ej]+wj,i < dist[s,ei])
11. dist[s,ei] = dist[s,ej]+wj,i
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
注:该算法不允许图中存在负权边。

优点:
1) 如果最优路径存在,那么一定能找到最优路径
缺点:
1) 有权图中可能是负边
2) 扩展的结点很多,效率低
2.A*算法
A算法发表于1968年,A算法是将Dijkstra算法与广度优先搜索算法(BFS)二者结合而成,通过借助启发式函数的作用,能够使该算法能够更快的找到最优路径。A算法是静态路网中求解最短路径最有效的直接搜索方法。
A算法的启发式函数:f(n)=g(n)+h(n)
f(n)表示结点的综合优先级,在选择结点时考虑该结点的综合优先级;
g(n)表示起始点到当前结点的代价值;
h(n)表示当前结点到目标点的代价估计值,启发式函数。
当h(n)趋近于0时,此时算法退化为Dijkstra算法,路径一定能找到,但速度比较慢;当g(n)趋近于0时,算法退化为BFS算法,不能保证一定找到路径,但速度特别快。我们可以通过调节h(n)的大小来调整算法的精度与速度。
在A*算法中,采用最多的是欧几里得距离,即dist = srqt((y2-y1)2+(x2-x1)2)。
A*算法流程:
1. 将起始点s加入到开启列表openlist中
2. 重复以下过程:
a) 遍历开启列表openlist,寻找F值最小的结点,并将其作为当前要处理的结点
b) 将要处理的结点移到关闭列表closelist
c) 对当前结点的8个相邻结点的每个结点:
i. 如果他是不可抵达的或者已经在关闭列表closelist中,忽略;
ii. 如果他不在开启列表openlist中,将其加入openlist,并把当前结点设置为其父节点,记录当前结点的F、G、H值;
iii. 如果他已经在开启列表openlist中,检查这条路径(即经由当前结点到达相邻结点)是否更好,用G值做参考,更小的G值表示这个更好的路径,如果是这样,将其父节点设置为当前结点,并重新计算他的G值和F值,如果开启列表openlist是按F值进行排序,改变后需要重新排序。
d) 停止,当
i. 终点加入到了开启列表openlist中,此时路径已经找到
ii. 查找重点失败,并且开启列表openlist中是空的,此时没有路径
3. 保存路径,从终点开始,每个结点沿着其父节点移动直到起点。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

优点:
1) 利用启发式函数,搜索范围小,提高了搜索效率
2) 如果最优路径存在,那么一定能找到最优路径
缺点:
1) A算法不适用于动态环境
2) A算法不太适合于高维空间,计算量大
3) 目标点不可达时会造成大量性能消耗
3.D*算法
D算法是卡耐基梅隆机器人中心的Stentz在1994年提出的主要用于机器人探路,并且美国火星探测器上就是应用的D路径规划算法。A算法适用于在静态路网中寻路,在环境变化后,往往需要replan,由于A不能有效利用上次计算的信息,故计算效率较低。D算法由于储存了空间中每个点到终点的最短路径信息,故在重规划时效率大大提升。A是正向搜索,而D特点是反向搜索,即从目标点开始搜索过程。在初次遍历时候,与Dijkstra算法一致,它将每个节点的信息都保存下来。
D*算法流程:
1. 先用Dijkstra算法从目标节点G向起始节点搜索。储存路网中目标点到各个节点的最短路和该位置到目标点的实际值h,k(k为所有变化h之中最小的值,当前为k=h)原OPEN和CLOSE中节点信息保存。 2. 机器人沿最短路开始移动,在移动的下一节点没有变化时,无需计算,利用上一步Dijkstra计算出的最短路信息从出发点向后追述即可,当在Y点探测到下一节点X状态发生改变,如堵塞。机器人首先调整自己在当前位置Y到目标点G的实际值h(Y),h(Y)=X到Y的新权值C(X,Y)+X的原实际值h(X)。X为下一节点(到目标点方向Y->X->G),Y是当前点。K值去h值变化前后的最小。 3. 用A*或其他算法计算,这里假设用A*算法,遍历Y的子节点,放入CLOSE,调整Y的子节点a的h值,h(a)=h(Y)+Y到子节点a的权重C(Y,a),比较a点是否存在于OPEN和CLOSE中,方法如下:用A*或者其他算法计算,这里假设用A*算法,遍历Y的子节点,放入CLOSE,调整Y的子节点a的h值,h(a)=h(Y)+Y到子节点a的权重C(Y,a),比较a点是否存在于OPEN和CLOSE中,方法如下: while() { 从OPEN表中取k值最小的节点Y; 遍历Y的子节点a,计算a的h值 h(a)=h(Y)+Y到子节点a的权重C(Y,a) { if(a in OPEN) 比较两个a的h值 if( a的h值小于OPEN表a的h值 ) { 更新OPEN表中a的h值;k值取最小的h值 有未受影响的最短路经存在 break; } if(a in CLOSE) 比较两个a的h值 //注意是同一个节点的两个不同路径的估价值 if( a的h值小于CLOSE表的h值 ) { 更新CLOSE表中a的h值; k值取最小的h值;将a节点放入OPEN表 有未受影响的最短路经存在 break; } if(a not in both) 将a插入OPEN表中; //还没有排序 } 放Y到CLOSE表; OPEN表比较k值大小进行排序; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
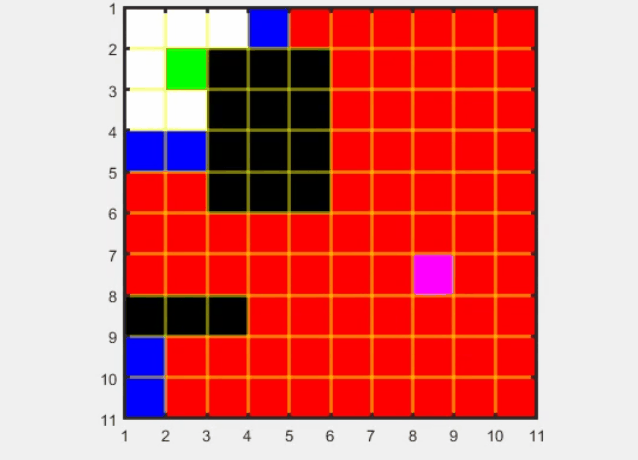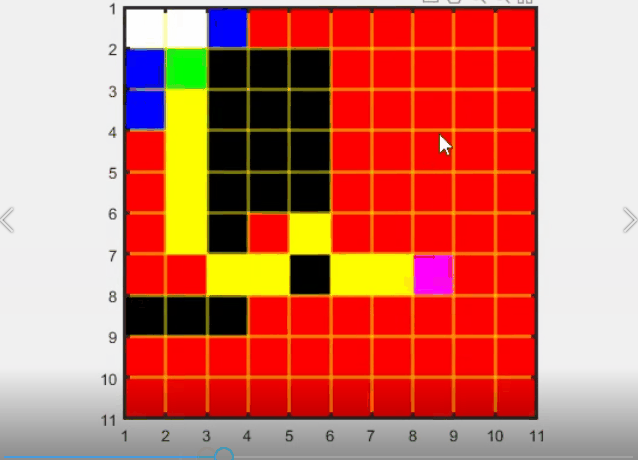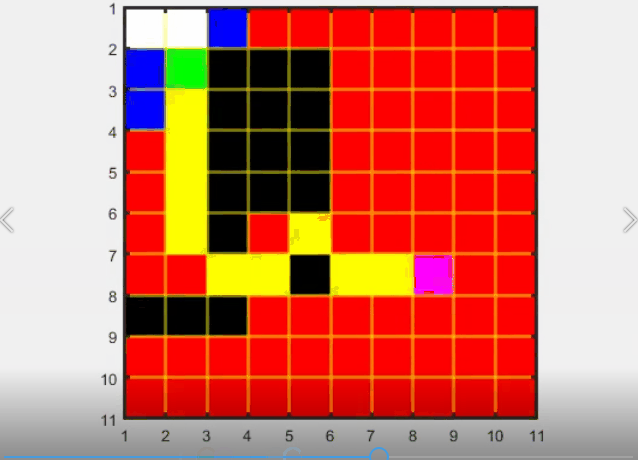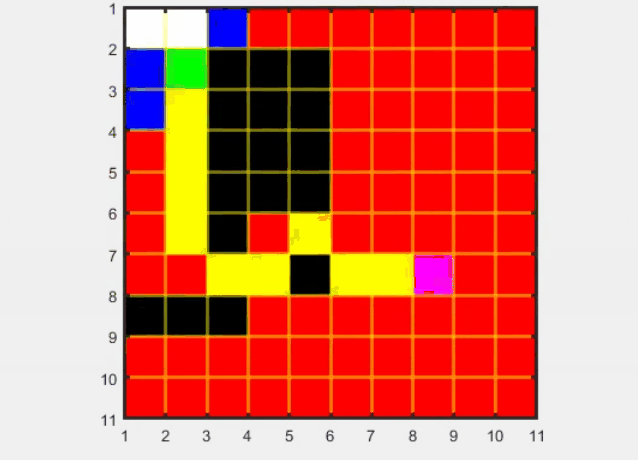
优点:
1)适用于动态环境的路径规划,搜索效率高
缺点:
1) 不适用于高维空间,计算量大
2) 不太适用于在距离较远的最短路径上发生变化的场景
4.人工势场法
人工势场法是由Khatib在1985年提出的一种基于虚拟力场的局部路径规划算法,该算法的基本思想是当机器人在周围环境中运动时,将环境设计成一种抽象的人造引力场,目标点对移动机器人产生“引力”,障碍物对移动机器人产生“斥力”,最后通过二者的合力来控制移动机器人的运动。应用人工势场法规划出来的路径一般是比较平滑并且安全的,但是存在着局部最优的问题。
利用势场函数U来建立人工势场,势场函数是一种可微函数,空间中某点处势场函数值的大小,代表了该点的势场强度。我们采用引力势场函数与斥力势场函数,用U(q)表示二者之和。
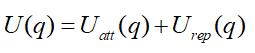
引力势场函数:
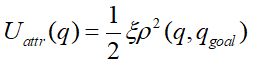
e表示引力增益,p(q,qgoal)表示当前点到目标点的距离;
斥力势场函数:
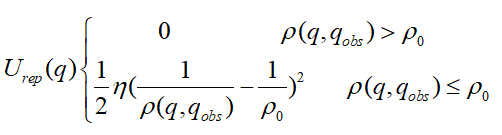
n表示斥力增益,p(q,qgoal)表示当前点到障碍物的距离,p0表示障碍物作用距离阈值。

优点:
1) 规划出的路径一般是比较平滑且安全
2) 人工势场法是一种反馈控制策略,具有一定的鲁棒性
缺点:
1) 容易陷入局部最优的问题
2) 距离目标点较远时,引力特别大,斥力相对较小,可能会发生碰撞
3) 当目标点附近有障碍物时,斥力非常大,引力较小,很难到达目标点
二、基于采样路径规划算法
1.PRM算法
随机路线图(PRM)算法是一种基于图搜索的算法,可以将连续状态空间转换成离散状态空间,在利用A*等搜索算法在路线图上寻找路径,提高搜索效率。PRM算法是概率完备且不是最优的算法。
PRM算法流程:
1. 初始化,设G(V,E)为一个无向图,其中顶点集V代表无碰撞的状态点,连线集E代表无碰撞的路径。初始状态为空。
2. 状态点采样,在状态空间中采样无碰撞的状态点加入到无碰撞的状态点V中。
3. 邻域计算,定义距离p,对于已经存在于无碰撞的状态点V中的点,如果他与无碰撞的点的距离小于p,则将其称作无碰撞状态点的邻域点。
4. 边线连接,将无碰撞的状态点与其邻域相连,生成连线。
5. 碰撞检测,检测连线是否与障碍物发生碰撞,如果无碰撞,则将其加入到连线集E中。
6. 结束条件,当所有采样点均已完成上述步骤后结束,否则重复2~5。
7. 最后使用A*算法在路线图上寻找最优路径。
- 1
- 2
- 3
- 4
- 5
- 6
- 7

优点:
1) 适用于高维空间和复杂约束的路径规划问题
2) 搜索效率高,搜索速度快
缺点:
1)概率完备但不是最优
2.RRT算法
RRT算法是适用于高维空间,通过对状态空间中的采样点进行碰撞检测,避免了对空间的建模,较好的处理带有非完整约束的路径规划问题,有效的解决了高维空间和复杂约束的路径规划问题。该算法是概率完备但不是最优的算法。
RRT算法以初始点qinit作为根节点,通过随机采样增加叶子节点的方式,生成一个随机扩展树,当目标点位于随机扩展树上时,能够找到一天初始点到目标点的路径。首先,需要从状态空间中随机选择一个采样点qrand,然后从随机树中选择一个距离qrand最近的结点qnearest,从qnearest向qrand扩展一个步长的距离,得到一个新的结点qnew,如果qnew与障碍物发生碰撞,则返回空;否则,将qnew加入到随机树中,重复上述步骤直到qnearest和qgoal距离小于一个阈值。
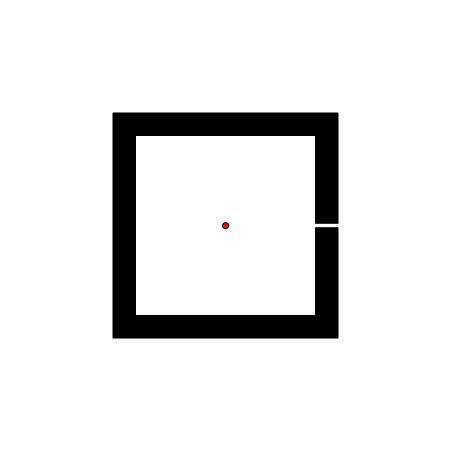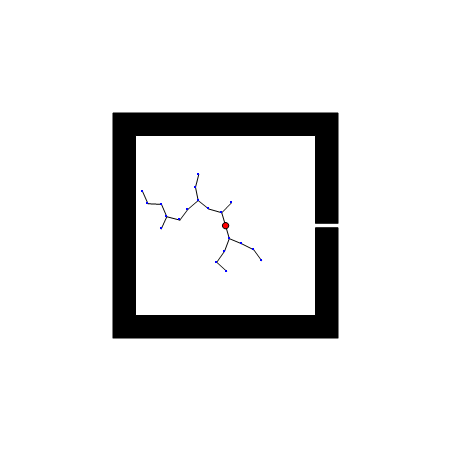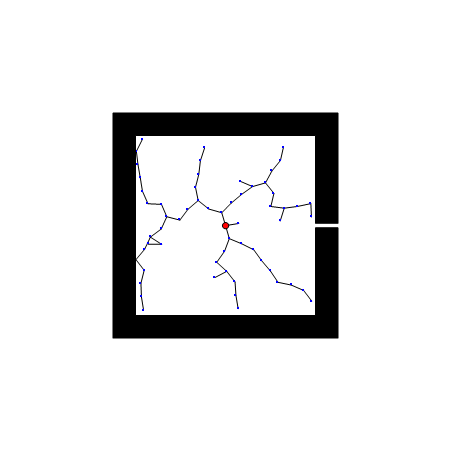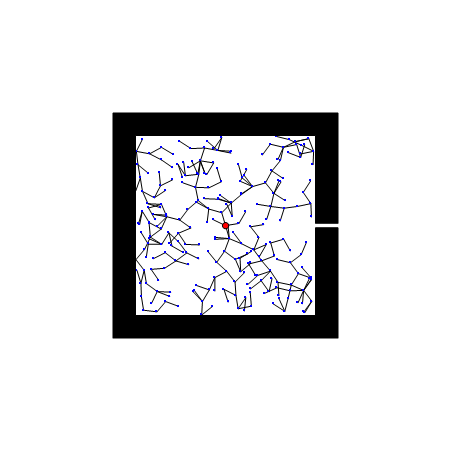
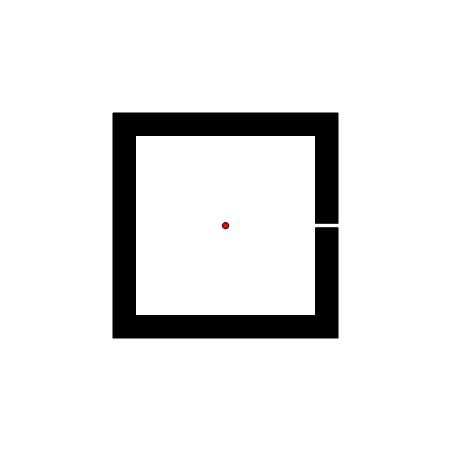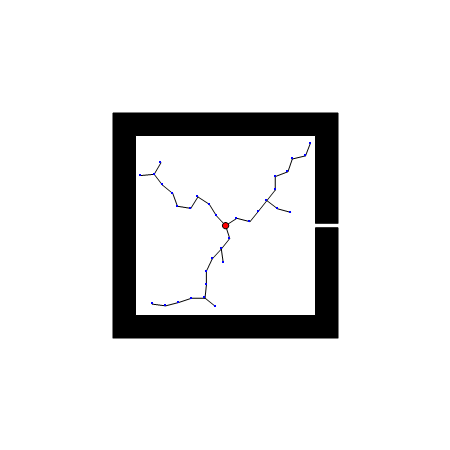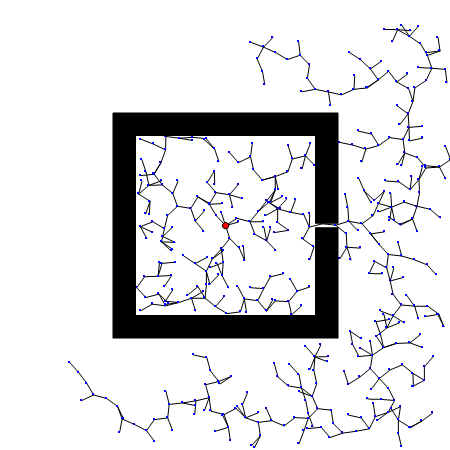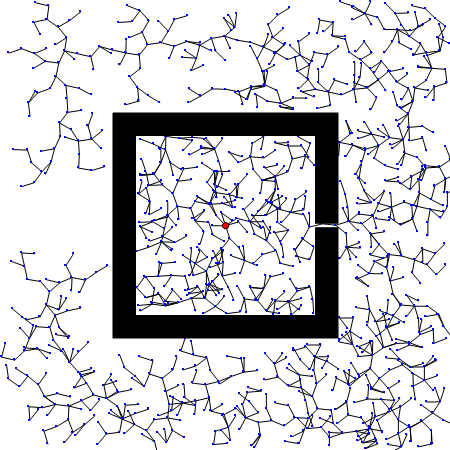
优点:
1) 搜索效率比较高,搜索速度比较快
2) 适用于高维空间,不会产生维度灾难的问题
3) 只需对状态空间采样点进行碰撞检测,避免了对空间的建模
缺点:
1) 规划出的路径质量一般,可能存在棱角、不够光滑
2) RRT算法不太适用于存在狭长空间的环境
3) 规划出的路径可能不是最优路径
4) 不适用于动态环境的路径规划
三、智能仿生算法
1.神经网络算法
随着机器人自主性的不断提高,使其具有环境感知以及环境学习的能力,许多学者提出了深度强化学习算法来解决移动机器人处于动态复杂环境中路径规划的问题。深度强化学习算法充分利用了深度学习的感知能力与强化学习的决策能力,通过机器人与环境的交互过程不断试错,通过环境评价性的反馈,实现系统更加智能的决策控制,帮助移动机器人在某些复杂未知的环境中实现一定程度的自主化与智能化。
路径规划就是一个标准的MDP问题,强化学习可以通过值迭代等方法建立一个表格,用以存储状态s到动作a的映射。但是在复杂环境中会产生维度灾难的问题,因此神经网络可以解决维度灾难的问题。以DQN算法为例,来讲解神经网络算法在路径规划中的应用。DQN算法是Q-Learning算法与卷积神经网络(CNN)二者进行结合。DQN算法是由两个网络结构、初始参数相同的结构组成,一个是估计网络,用来输出估计值函数;另一个是目标网络,用来输出目标值函数。通过强化学习使机器人与环境进行交互得到样本(s,a,r,s’),将所有的样本集放入到经验回放池中。神经网络进行训练时,随机的从经验回放池中抽取batchsz数量的样本,将样本输入进神经网络,利用神经网络的非线性拟合能力,拟合出非线性函数来表达我们的Q值,利用e-greedy策略来进行选择智能体的动作。智能体执行完相应的动作之后,环境会反馈一个状态和奖励值,最后经过神经网络模型的训练和优化得到网络的训练参数,得到相对准确的动作输出。
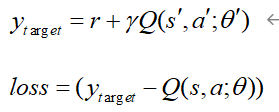
其中w表示估计网络的参数, w-表示目标网络的参数。
优点:
1) 适合于动态复杂环境
2) 适用于高维空间,避免维度灾难的问题
缺点:
1) 对硬件的要求比较高
2) 参数调节比较困难
2.蚁群算法
蚁群算法(Ant Colony Optimization,ACO)是Dorigo在1992年提出的一种用来寻找优化路径的概率型算法,是由一群无智能或有轻微智能的个体通过相互写作而表现出智能行为,为求解复杂问题提供了一个新的可能性。该算法的主要思想是蚂蚁在寻找食物过程中发现路径的行为。该算法具有分布计算、信息正反馈和启发式搜索的特征,本质上是进化算法中的一种启发式全局优化算法。
蚁群算法的基本原理是利用蚂蚁在觅食过程中会释放信息素。
1. 初始时刻,路径没有任何信息素,蚂蚁会以一定的随机性选择任意方向
2. 更新信息素矩阵,当有信息素时,蚂蚁会优先选择信息素浓度高的路径
3. 那么在相同时间内,信息素的浓度与路径长度成反比,越短的路径会有更多的信息素,那么后续的蚂蚁会选择信息素浓度高的路径,最优路径上的信息素浓度会越来越高
4. 随着时间的推移,信息素会自行挥发
5. 最终,能选择出一条最优路径即信息素浓度高的路径
- 1
- 2
- 3
- 4
- 5
影响蚁群算法的因素:
1) 信息素如何撒播
2) 信息素如何挥发
3) 以何种方式让蚂蚁选择运动方向,减少盲目性和不必要性
4) 给予蚂蚁和环境一定的记忆能力能够帮助减少搜索空间
个体分布越均匀,种群多样性就越好,得到全局最优解的概率就越大,但是寻优时间就越长;个体分布越集中,种群多样性就越差,不利于发挥算法的探索能力。正反馈加快了蚁群算法的收敛速度,却使算法较早地集中于部分候选解,因此正反馈降低了种群的多样性,也不利于提高算法的全局寻优能力。
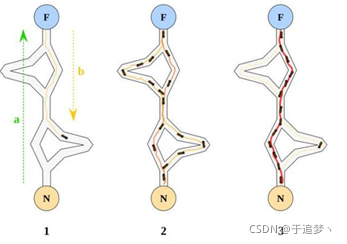
优点:
1) 蚁群算法的鲁棒性强
2) 采用正反馈机制,能够逼近最优解
3) 易与其他算法进行结合
缺点:
1) 盲目的随机搜索,搜索时间较长,搜索速度慢
2) 蚁群算法容易陷入局部最优
3) 蚁群算法参数的选择依赖于经验或试错
3.遗传算法
遗传算法(Genetic Algorithm,GA)是由John Holland于20世纪70年代提出,该算法是根据大自然中生物体进化规律而设计提出的,来模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。其本质是一种高效、并行、全局搜索的方法,能在搜索过程中自动获取和积累有关搜索空间的知识,并自适应地控制搜索过程以求得最佳解。
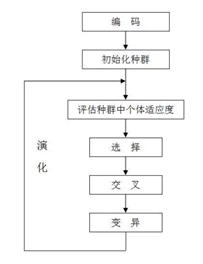
遗传算法的流程:
1.评估每条染色体所对应个体的适应度
While(未找到满意的解):
2.遵照适应度越高,选择概率越大的原则,从种群中选择两个个体作为父方和母方
3.抽取父母双方的染色体,进行交叉,产生子代
4.对子代的染色体进行变异
- 1
- 2
- 3
- 4
- 5
优点:
1) 遗传算法具有广泛的应用领域
2) 遗传算法具有群体搜索的特性
3) 遗传算法基于概率规则,搜索更为灵活
4) 遗传算法直接以目标函数作为搜索信息,不涉及目标函数值求微分的过程
缺点:
1) 遗传算法效率比较低
2) 遗传算法容易过早收敛
3) 遗传算法在编码时容易出现不规范不准确的问题
更多内容请关注微信公众号:深度学习与路径规划


