
热门标签
热门文章
- 1AIGC工具系列之——基于OpenAI的GPT大模型搭建自己的AIGC工具_自己搭建aigc大模型
- 2uniapp从入门到入土-日更_脚本之家 uni-app跨平台开发与应用,从入门到实践
- 3Pyinstaller进行文件打包_pyinstaller demo.py --onefile生成文件在哪个文件夹下
- 4Hadoop 3.0磁盘均衡器(diskbalancer)功能及使用介绍
- 5ELT 同步 MySQL 到 Doris
- 6【人脸表情识别】微表情识别系统【含GUI Matlab源码 1808期】_微表情分析系统
- 7万字长文:深度解读最新发布的《国家数据安全法》 by 傅一平
- 8iOS开发一路走来看到,好奇,好玩,学习的知识点记录_xingai69tangav
- 9前Airbnb工程师:如何零基础猥琐发育成区块链开发者?
- 10【软件设计师】——4.计算机网络
当前位置: article > 正文
hadoop伪分布式集群搭建_伪分布式集群搭建卸载本机jdk
作者:笔触狂放9 | 2024-05-31 07:27:16
赞
踩
伪分布式集群搭建卸载本机jdk
hadoop伪分布式集群搭建
一、关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
- 1
- 2
二、关闭selinux
查看selinux状态,如果为disabled说明已经关闭,
如果为enforcing,需要将enforcing设置为disabled
vim /etc/sysconfig/selinux
将SELINUX=enforcing 修改为SELINUX=disabled

设置完成之后,需要重启生效,重启后查看selinux状态,为disabled说明设置成功
[root@hadoop01 opt]# sestatus
SELinux status: disabled
[root@hadoop01 opt]#
- 1
- 2
- 3
三、安装jdk
1、卸载自带的openjdk
[root@hadoop01 ~]# java -version openjdk version "1.8.0_161" OpenJDK Runtime Environment (build 1.8.0_161-b14) OpenJDK 64-Bit Server VM (build 25.161-b14, mixed mode) [root@hadoop01 ~]# rpm -qa | grep java python-javapackages-3.4.1-11.el7.noarch java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.el7.x86_64 java-1.7.0-openjdk-1.7.0.171-2.6.13.2.el7.x86_64 java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64 java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64 tzdata-java-2018c-1.el7.noarch javapackages-tools-3.4.1-11.el7.noarch [root@hadoop01 ~]# [root@hadoop01 ~]# rpm -qa | grep jdk java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.el7.x86_64 java-1.7.0-openjdk-1.7.0.171-2.6.13.2.el7.x86_64 java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64 java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64 copy-jdk-configs-3.3-2.el7.noarch [root@hadoop01 ~]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.171-2.6.13.2.el7.x86_64 [root@hadoop01 ~]# rpm -e --nodeps java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64 [root@hadoop01 ~]# rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64 [root@hadoop01 ~]# rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.el7.x86_64 [root@hadoop01 ~]# java -version -bash: /bin/java: No such file or directory

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
2、上传jdk安装包,使用root用户安装
mkdir -p /usr/java
tar -zxvf jdk-8u192-linux-x64.tar.gz -C /usr/java
- 1
- 2
3、配置环境变量
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_192
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
- 1
- 2
- 3
- 4
4、查看是否安装成功
配置好环境变量之后,执行source /etc/profile ,使环境变量生效,查看java -version

四、修改主机名、hosts
vim /etc/hostname
hadoop01
- 1
- 2
vim /etc/hosts
192.168.110.1 hadoop01
- 1
- 2
五、hadoop安装及配置
1、将hadoop安装包上传到 /opt 目录下
mkdir /opt/module
chown hadoop:hadoop /opt/module
- 1
- 2
2、解压安装包
[hadoop@hadoop01 opt]$ tar -zxvf hadoop-2.7.3.tar.gz -C /opt/module/
- 1
 ## 3、配置core-site.xml
## 3、配置core-site.xml
vim core-site.xml
- 1
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.3/data/tmpdata</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4、配置hdfs-site.xml
vim hdfs-site.xml
- 1
<property> <name>dfs.namenode.name.dir</name> <value>/opt/module/hadoop-2.7.3/data/namenode</value> <description>为了保证元数据的安全一般配置多个不同目录</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/module/hadoop-2.7.3/data/datanode</value> <description>datanode 的数据存储目录</description> </property> <property> <name>dfs.replication</name> <value>1</value> <description>HDFS 的数据块的副本存储个数, 默认是3</description> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
5、配置mapred-site.xml
[hadoop@hadoop01 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@hadoop01 hadoop]$
[hadoop@hadoop01 hadoop]$ vim mapred-site.xml
- 1
- 2
- 3
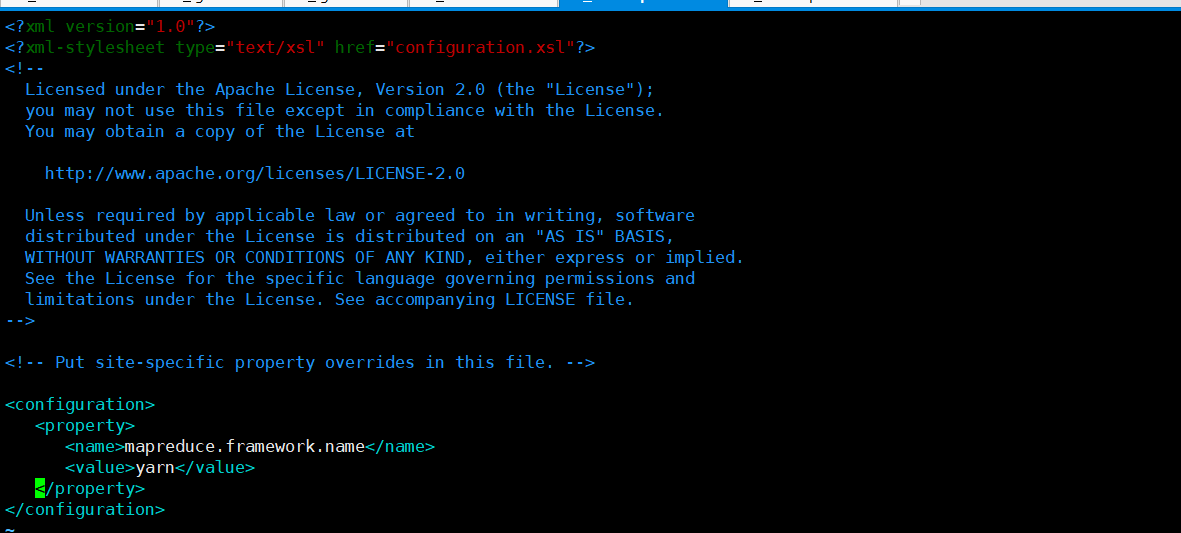
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 1
- 2
- 3
- 4
6、配置yarn-site.xml
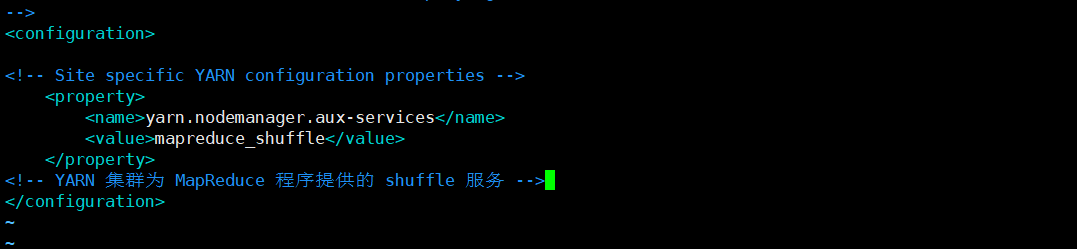
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- YARN 集群为 MapReduce 程序提供的 shuffle 服务 -->
- 1
- 2
- 3
- 4
- 5
- 6
7、配置slaves
vim slaves
hadoop01
- 1
- 2

因为是伪分布式,所以只填入hadoop01一台机器的主机名
8、配置Hadoop环境配置
8.1 由于是用hadoop用户登陆的,环境变量是~/.bashrc
vim ~/.bashrc
- 1
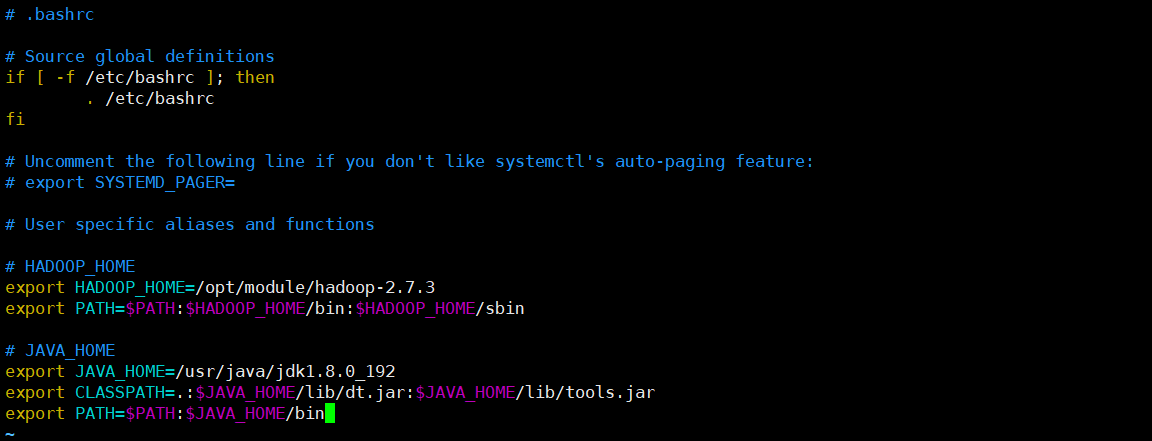
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_192
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
8.2 使配置生效
[hadoop@hadoop01 ~]$ source ~/.bashrc
- 1
8.3 查看hadoop版本:hadoop version
[hadoop@hadoop01 ~]$ hadoop version
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /opt/module/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar
- 1
- 2
- 3
- 4
- 5
- 6
- 7
9、创建core/hdfs-site.xml里配置的路径
[hadoop@hadoop01 ~]$ mkdir -p /opt/module/hadoop-2.7.3/data/namenode
[hadoop@hadoop01 ~]$ mkdir -p /opt/module/hadoop-2.7.3/data/datanode
[hadoop@hadoop01 ~]$
[hadoop@hadoop01 ~]$ mkdir -p /opt/module/hadoop-2.7.3/data/tmpdata
- 1
- 2
- 3
- 4
10、Hadoop的初始化
[hadoop@hadoop01 ~]$ hadoop namenode -format
- 1
如下图所示出现status 0即为初始化成功。

11、启动hadoop
[hadoop@hadoop01 ~]$ cd /opt/module/hadoop-2.7.3/
[hadoop@hadoop01 hadoop-2.7.3]$ sbin/start-dfs.sh
[hadoop@hadoop01 hadoop-2.7.3]$ sbin/start-yarn.sh
- 1
- 2
- 3

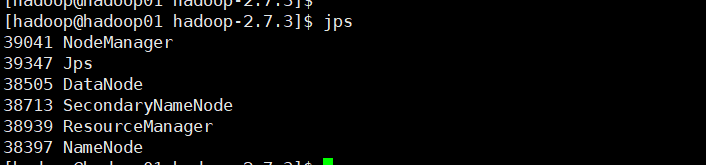
12、访问hadoop的webUI界面
- 浏览器输入:http://IP:50070

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/651100
推荐阅读

相关标签

