
- 1基于javaweb的学生管理系统_通过javaweb实现学生管理系统
- 2vue使用hiprint打印前端查询到的数据的详细过程_hiprint教程
- 3Linux之进程_linux进程
- 4【数据结构】八大排序(一)
- 5微信大数据挑战赛 记录_微信大数据挑战赛2021 数据集
- 6只要5分钟!小白向的MAC端VSCode C++环境配置【超简洁的图文教程,TLDR版本】_vscode c++ 配置setting
- 7使用fifo时,如何选择dram、bram及uram资源配置_fifo dram
- 8Linux/Windows下部署OpenCV环境(Java/SpringBoot/IDEA)_springboot opencv idea
- 9SpringBoot整合Rabbitmq(消息队列和rabbitmq的使用)_springboot集成mq监听队列消息
- 10封装一个elementui的table组件_封装element ui的table组件
2.7 汽车之家口碑爬虫_汽车之家网站允许爬取在线评论吗
赞
踩
2.7 汽车之家口碑爬虫
1.需求分析
因项目需求,要爬取汽车之家的口碑数据进行下一步分析。
但是普通的爬虫软件(如八爪鱼、火车头、神箭手)无法爬取评论(该公司采取了反爬虫措施)。
经分析,发现该公司的的反爬虫措施主要是用前端js去替换显示的字体,为一些标签。并且封住鼠标右键导致不好观察源代码。
本文以解决各个问题为顺序。
2.前端js反爬虫措施分析
声明:爬取汽车之家的主要难点在于第一步:破解前端js替换。破解方法的来源是博客园上大神Mr.Dolphin的文章反爬虫破解系列-汽车之家利用css样式替换文字破解方法:https://www.cnblogs.com/dyfblog/p/6753251.html 这一部分的问题大家可以移步前去获取更精确的答案。
2.1问题描述
以任意车型(奥迪A4L)为例:http://k.autohome.com.cn/692/
我们可以看到,表面上各个评论都由文字组成,但是打开F12开发者模式。我们就发现:一些形容词被替换成了span标签,如图:
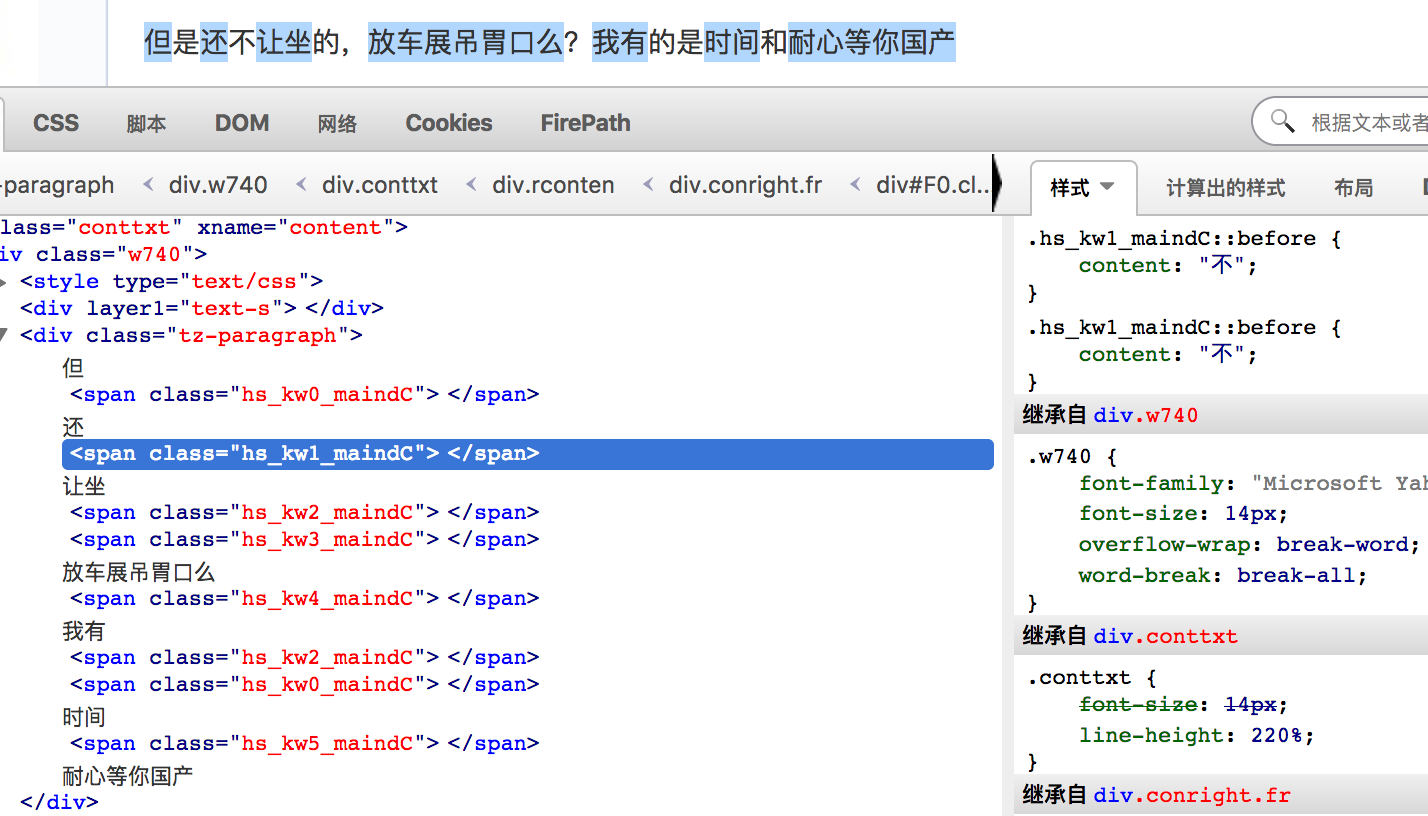
他们的具体做法是:
发布的口碑正文中随机抽取某几个字使用span标签代替,标签内容位空,但css样式显示为所代替的文。
这样不会影响正常用户的阅读,只是在用鼠标选择的时候是选不到被替换的文字的,对爬虫则会造成采集内容不全的影响。
这些是用JS实现的,这是一段js代码:
(function(hZ_) {
functionEW_() { = DV_()[decodeURIComponent]('%E3%80%81%E3%80%82%E4%B8%80%E4%B8%8A%E4%B8%8B%E4%B8%8D%E4%BA%86%E4%BA%94%E5%92%8C%E5%9C%B0%E5%A4%9A%E5%A4%A7%E5%A5%BD%E5%B0%8F%E5%BE%88%E5%BE%97%E6%98%AF%E7%9A%84%E7%9D%80%E8%BF%9C%E9%95%BF%E9%AB%98%EF%BC%81%EF%BC%8C%EF%BC%9F'Ÿ yc_());
= la_((yc_() 23; 3; 19; 17; 9; 1; 8; 12; 18; 13; 2; 4; 16; 5; 6; 21; 15; 11; 22; 14; 24; 0; 10; 7; 20), lf_(;));
= la_((10 _7, 6 _0; 2 _33, 14 _18; 8 _45, 8 _36; 0 _71, 16 _54; 13 _76, 3 _72; 0 _107, 16 _90; 15 _110, 1 _108; 4 _139, 12 _126; 9 _152, 7 _144; 10 _169, 6 _162; 4 _193, 12 _180; 11 _204, 5 _198; 3 _230, 13 _216; 1 _250, 15 _234; 13 _256, 3 _252; 6 _281, 10 _270; 9 _296, 7 _288; 13 _310, 3 _306; 6 _335, 10 _324; 7 _352, 9 _342; 6 _371, 10 _360; 5 _390, 11 _378; 5 _408, 11 _396; 7 _424, 9 _414; 6 _443, 10 _432lf_(;)), yc_(;));
Uj_();
return;;
}
function mS_() {
for (Gx_ = 0; Gx_ < nf_.length; Gx_++) {
var su_ = Pn_(nf_[Gx_], ',');
var KN_ = '';
for (Bk_ = 0; Bk_ < su_.length; Bk_++) {
KN_ += ui_(su_[Bk_]) + '';
}
Kx_(Gx_, KN_);
}
}
function NH_(Gx_) {
return '.hs_kw' + Gx_ + '_maindC';
}
function Ln_() {
return '::before { content:'
}
})(document);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
他的逻辑是,预先定义好哪几个字要被替换,上面代码中的那个很多%的字符串就是被替换的文字串,然后定义好每个文字的序号,最后按照文字的序号对文字串进行重新排序并生成css样式,注意,最一开始的span标签的class属性中是有个序号的,这个序号就是用来定位应该对应哪个文字。
接下来要做的就是无非就是从js代码中找到这个文字串,找到文字串的顺序,然后进行重排,然后根据span标签序号对原文
进行反向替换,从而得到完整的内容。

