
- 1AIGC内容分享(六十一):AIGC 算法揭秘及产业落地应用分享_祝天刚 京东
- 2【Python编程实战】基于Python语言实现学生信息管理系统
- 3简历空白怎么办?计算机专业应届生和在校生怎么写简历?_计算机简历非科班怎么写学历
- 410种排序算法的复杂度,比较,与实现_排序算法复杂度对比
- 5隐马尔科夫模型 HMM 与 语音识别 speech recognition (1):名词解释_hmm speech
- 6【C进阶】文件操作(下)(详解--适合初学者入门)
- 7gitee开源项目基于SSM实现的图书借阅管理系统_ssm图书管理系统开源
- 8CDH集群hue继承hdfs遇到问题_hdfs权限继承无效
- 9NLP 算法实战项目:使用 BERT 进行文本多分类_bert多文本分类
- 10django基于python的图书馆管理系统--python-计算机毕业设计_图书馆管理系统设计pythondjango报告csdn
AIGC综述_a comprehensive survey of ai-generated content (ai
赞
踩
A Comprehensive Survey of AI-Generated Content (AIGC):A History of Generative AI from GAN to ChatGPT
一、AIGC简介
1、什么是AIGC
AIGC:生成式人工智能,AI-Generated Content。
AIGC的目标是使内容创建过程更加高效和易于访问,从而能够以更快的速度制作高质量的内容。
AIGC是通过从人类提供的指令中提取和理解意图信息,并根据其知识和意图信息生成内容来实现的。
AIGC的发展依赖于数据的增长、AI算法的发展以及GPU的发展
2、AI发展历程
1956,人工智能达特茅斯学院人工智能夏季研讨会上正式使用了人工智能(artificial
intelligence,AI)这一术语。这是人类历史上第一次人工智能研讨,标志着人工智能学科的诞生。
1957年-Frank Rosenblatt-感知机(Perceptron)的神经网络模型
1958年,David Cox提出了logistic regression线性判别器
1967年,Thomas等人提出K最近邻算法
1968年,爱德华·费根鲍姆(Edward Feigenbaum)提出首个专家系统DENDRAL(知识库、推理机)
1974年,哈佛大学沃伯斯(Paul Werbos)博士论文里,首次提出了通过误差的反向传播(BP)来训练人工神经网络,但在该时期未引起重视。
1980年,在美国的卡内基梅隆大学(CMU)召开了第一届机器学习国际研讨会,标志着机器学习研究已在全世界兴起。
1989年,LeCun (CNN之父) 结合反向传播算法与权值共享的卷积神经层发明了卷积神经网络(Convolutional Neural Network,CNN),并首次将卷积神经网络成功应用到美国邮局的手写字符识别系统中。
1995年,Cortes和Vapnik提出联结主义经典的支持向量机(Support Vector Machine),它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
1997年,Sepp Hochreiter 和 Jürgen Schmidhuber提出了长短期记忆神经网络(LSTM)。
2011年,IBM Watson问答机器人参与Jeopardy回答测验比赛最终赢得了冠军。Waston是一个集自然语言处理、知识表示、自动推理及机器学习等技术实现的电脑问答(Q&A)系统。
2012年,Hinton和他的学生Alex Krizhevsky设计的AlexNet神经网络模型在ImageNet竞赛大获全胜,这是史上第一次有模型在 ImageNet 数据集表现如此出色,并引爆了神经网络的研究热情。 AlexNet是一个经典的CNN模型,在数据、算法及算力层面均有较大改进,创新地应用了Data Augmentation、ReLU、Dropout和LRN等方法,并使用GPU加速网络训练。
2012年,谷歌正式发布谷歌知识图谱Google Knowledge Graph),它是Google的一个从多种信息来源汇集的知识库,通过Knowledge Graph来在普通的字串搜索上叠一层相互之间的关系,协助使用者更快找到所需的资料的同时,也可以知识为基础的搜索更近一步,以提高Google搜索的质量。
2013年,Google的Tomas Mikolov 在《Efficient Estimation of Word Representation in Vector Space》提出经典的 Word2Vec模型用来学习单词分布式表示,因其简单高效引起了工业界和学术界极大的关注。
2014年,聊天程序“尤金·古斯特曼”(Eugene Goostman)在英国皇家学会举行的“2014图灵测试”大会上,首次“通过”了图灵测试。
2014年,Goodfellow及Bengio等人提出生成对抗网络(Generative Adversarial Network,GAN),被誉为近年来最酷炫的神经网络。
2015年,Microsoft Research的Kaiming He等人提出的残差网络(ResNet)在ImageNet大规模视觉识别竞赛中获得了图像分类和物体识别的优胜。
2015年,谷歌开源TensorFlow框架。它是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。
2015年,马斯克等人共同创建OpenAI。它是一个非营利的研究组织,使命是确保通用人工智能 (即一种高度自主且在大多数具有经济价值的工作上超越人类的系统)将为全人类带来福祉。其发布热门产品的如:OpenAI Gym,GPT等。
2016年,AlphaGo与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜。
2017年,中国香港的汉森机器人技术公司(Hanson Robotics)开发的类人机器人索菲亚,是历史上首个获得公民身份的一台机器人。索菲亚看起来就像人类女性,拥有橡胶皮肤,能够表现出超过62种自然的面部表情。其“大脑”中的算法能够理解语言、识别面部,并与人进行互动。
2018年,Google提出论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》并发布Bert(Bidirectional Encoder Representation from Transformers)模型,成功在 11 项 NLP 任务中取得 state of the art 的结果。
2020年,OpenAI开发的文字生成 (text generation) 人工智能GPT-3,它具有1,750亿个参数的自然语言深度学习模型,比以前的版本GPT-2高100倍,该模型经过了将近0.5万亿个单词的预训练,可以在多个NLP任务(答题、翻译、写文章)基准上达到最先进的性能。
2021年,OpenAI提出两个连接文本与图像的神经网络:DALL·E 和 CLIP。DALL·E 可以基于文本直接生成图像,CLIP 则能够完成图像与文本类别的匹配。
2022年11月30日,OpenAI推出ChatGPT,使用了Transformer神经网络架构,也是GPT-3.5架构,2023年一月末,ChatGPT的月活用户已突破1亿,成为史上增长最快的消费者应用。
3、AIGC发展历程
从ChatGPT的前世今生,到如今AI领域的竞争格局(截止至2023.03)
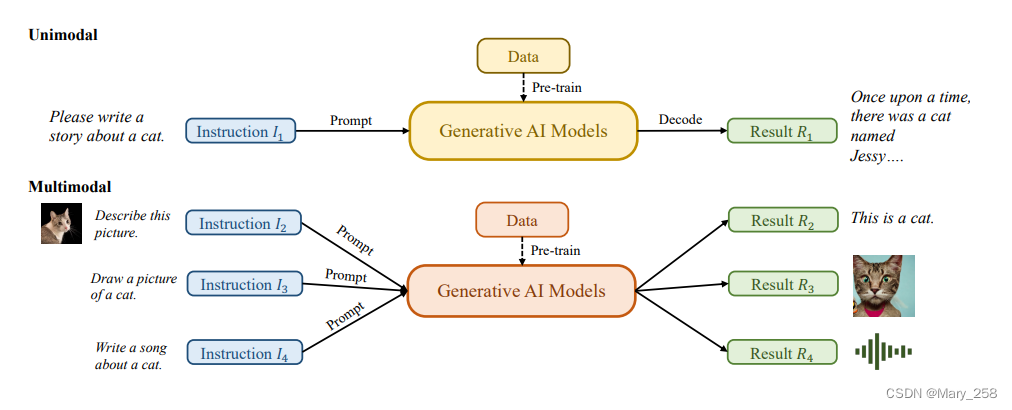
生成式AI模型(GAI)分为单模态模型和多模态模型:
单模态模型从与生成的内容模态相同的模态接收指令
多模态模型接受跨模态指令并产生不同模态的结果
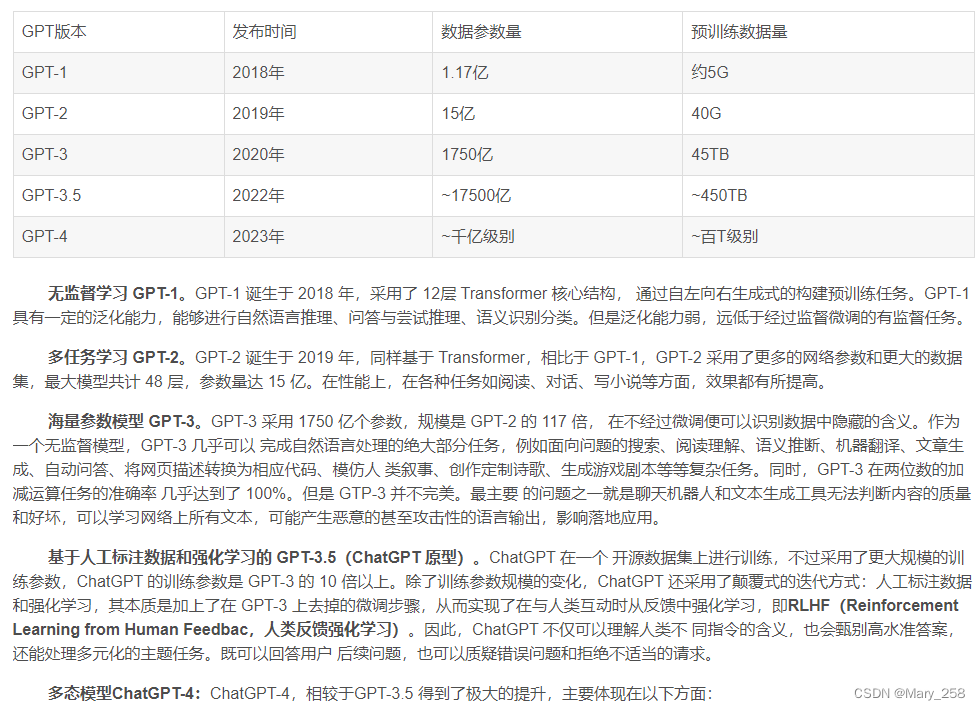
GPT-3的框架与GPT-2保持相同,但预训练数据大小从Web Text(38GB)到CommonCrawl【训练数据集](过滤后为570GB),以及基础模型大小从1.5亿增长到175亿。因此,GPT-3在各种方面都比GPT-2具有更好的泛化能力任务,例如人类意图提取。
ChatGPT利用来自人类反馈的强化学习(RLHF)[10-12]来确定对给定指令做出最恰当的响应,从而提高模型的可靠性和准确性随着时间的推移。这种方法使ChatGPT能够更好地理解长对话中的人类偏好。
同时,在计算机视觉中,稳定性提出了稳定扩散[13]stable diffusion, 2022年的人工智能在图像生成方面也取得了巨大成功。与现有方法不同,生成扩散模型可以通过控制探索和开发之间的权衡来帮助生成高分辨率图像,从而实现生成图像的多样性和与训练数据的相似性的和谐结合。
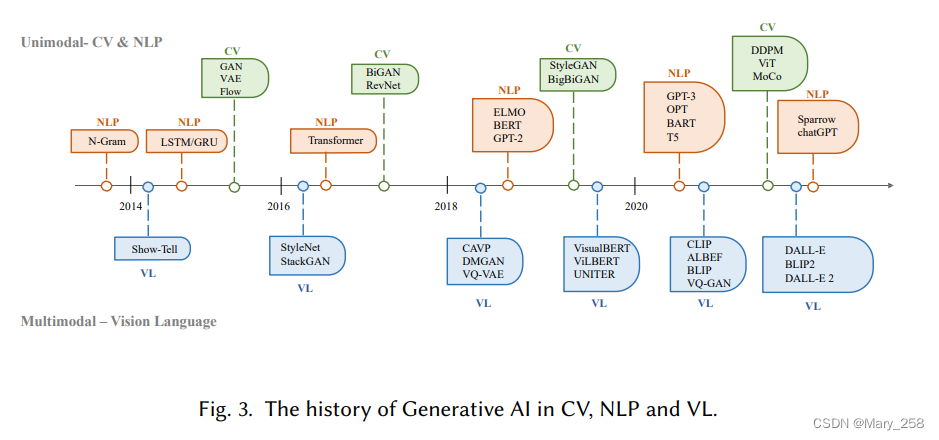
二、AI发展历史
20世纪50年代,隐马尔科夫模型HMM和高斯混合模型GMM生成了语言和时间序列之类的顺序数据。
NLP中,生成句子的传统方式是N-gram模型进行单词分别,然后搜索最佳序列。随着LSTM、GRU门控递归网络在训练过程中建模相对较长的依赖关系。
CV中,传统算法纹理合成和纹理映射到2014年生成对抗网络GANs的提出,再到变分自动编码器VAE和stable-diffusion的提出,图像生成过程也有了更细粒度的控制和高质量图像生成的能力。
Transformer的出现,使得NLP/CV出现了交叉点。NLP中,bert、GPT采用transformer作为其主要构建块,与LSTM和GRU相比更具优势。CV中,发展为ViT和swin transformer,多模态代表:CLIP
基于transformer模型的出现彻底改变了人工智能的生成,并带来了大规模训练的可能性。
ChatGPT、DALL-E-2、Codex
bert/transformer/强化学习
三、GAI模型训练中广泛使用的基本组件
3.1、AIGC的组件模型-Foundation Model
transformer
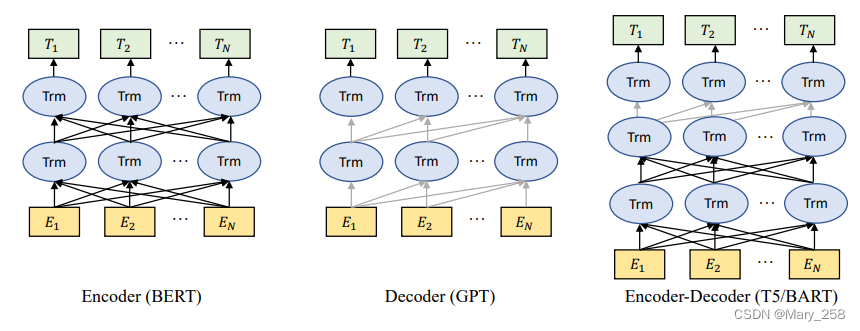
它最初是为了解决传统模型(如RNN)在处理可变长度序列和上下文感知方面的局限性而提出的。Transformer体系结构主要基于自关注机制,该机制允许模型关注输入序列中的不同部分。Transformer由一个编码器和一个解码器组成。编码器接收输入序列并生成隐藏表示,而解码器接收隐藏表示并生成输出序列。每一层编码器和解码器由多头注意力和前馈神经网络组成。多头注意力是Transformer的核心组成部分,它学习根据标记的相关性为其分配不同的权重。这种信息路由方法使模型能够更好地处理长期依赖关系,从而提高了在各种NLP任务中的性能。
transformer的另一个优点是其架构使其具有高度的并行性,并允许数据胜过电感偏差[40]。这种特性使transformer非常适合大规模的预训练,使基于transformer的模型能够适应不同的下游任务。
预训练语言模型-Pre-trained Language Models
自从引入Transformer体系结构以来,由于其并行性和学习能力,它已成为自然语言处理中的主导选择。通常,这些基于转换器的预训练语言模型根据其训练任务通常可分为两类:自回归语言建模autoregressive language modeling和掩蔽语言建模masked language modeling [41]。给定一个由几个标记组成的句子,masked language modeling 的目标,例如BERT[42]和RoBERTa[43],是指在给定上下文信息的情况下预测masked标记的概率。masked language modeling 最显著的例子是BERT[42],它包括masked language modeling 和下一句预测任务。RoBERTa[43]使用与BERT相同的架构,通过增加预训练数据量和纳入更具挑战性的预训练目标来提高其性能。XL Net[44]也基于BERT,它结合了置换运算来改变每次训练迭代的预测顺序,使模型能够跨tokens学习更多信息。而autoregressive language modeling,例如GPT-3[9]和OPT[45],是在给定先前token的情况下对下一个token的概率进行建模,因此是从左到右的语言建模。与masked language modeling不同,autoregressive language modeling自回归模型更适合于生成任务。
3.2、强化学习-Reinforcement Learning from Human Feedback
强化学习(RLHF)已被应用于各种应用程序中的微调模型,如Sparrow、InstructGPT和ChatGPT[10,46]。
通常,RLHF的整个流程包括以下三个步骤:预训练、奖励学习和强化学习的微调。
3.3、算力computing
硬件hardware
分布式训练 Distributed training.
云计算 Cloud computing
四、生成AI的发展历程-GENERATIVE AI
4.1、单模态模型
在本节中,我们将介绍最先进的单峰生成模型。这些模型被设计为接受特定的原始数据模态作为输入,例如文本或图像,然后以与输入相同的模态生成预测。我们将讨论这些模型中使用的一些最有前途的方法和技术,包括生成语言模型,例如GPT3[9]、BART[34]、T5[56],以及生成视觉模型,例如GAN[29]、VAE[30]和归一化流[57]。
4.1.1 语言生成模型Generative Language Models GLM
GLM:对话系统、翻译、问答系统
预训练语言模型分为:masked language models(encoders), auto-regressive language model(decoders)和encoder-decoder language models
Decoder models 使用用于文本生成
encoder models主要用于分类任务
encoder-decoder language models可以利用上下文信息和自回归特性来提高各种任务的性能。
依据 Decoder models 的模型
One of the most prominent examples of autoregressive decoder-based language models is GPT, which is a transformer-based model that utilizes self-attention mechanisms to process all words in a sequence simultaneously.
- GPT:基于Transformer,利用自注意机制处理序列中的单词。GPT是在前一个单词的基础上进行下一个单词预测任务的训练,使其能够生成连贯的文本。
Subsequently, GPT-2 [62] and GPT-3 [9] maintains the autoregressive left-to-right training method, while scaling up model parameters and leveraging diverse datasets beyond basic web text, achieving state-of-the-art results on numerous datasets.
- GPT-2[62]和GPT-3[9]放大模型参数,并利用web text进行训练,并在众多数据集上表现较好。
- Gopher[39]使用类似GPT的结构,但将LayerNorm[63]替换为RSNorm,其中将residual connection(RS,剩余连接)添加到原始层结构以维护信息。除了增强归一化功能外,其他几项研究都集中在优化注意力机制上。
- BLOOM[64]与GPT-3共享相同的结构,但BLOOM使用全注意力网络,而不是使用稀疏注意力,这更适合于对长依赖关系进行建模。
- [65]提出了Megatron,它扩展了GPT-3、BERT和T5等常用架构,并以分布式训练为目标来处理大量数据。这种方法后来也被MT-NLG[66]和OPT[45]所采用。
除了在模型架构和预训练任务方面的进步外,在改进语言模型的微调过程方面也做出了重大努力。
- InstructGPT[10]利用预先训练的GPT-3,并使用RLHF进行微调,允许模型根据人类标记的排名反馈来学习偏好。
依据 Encoder-Decoder models 的模型
One of the main encoder-decoder methods is Text-to-Text Transfer Transformer (T5)
- T5能将输入和输出数据转换为标准化的文本格式。可用于机器翻译、问答系统、摘要生成等
- Switch Transformer[67]utilizes“switch/切换”(指简化的MoE路由算法)在T5上进行并行训练。与基本模型相比,该模型在相同的计算资源下成功地获得了更大的规模和更好的性能。
- ExT5[68],谷歌2021年提出,扩展T5模型的规模。ExT5继续在C4和ExMix上进行预训练,which is跨不同领域的107个监督NLP任务的组合。
- BART[34],混合了BERT的双向编码器和GPT的自回归解码器,使其能够利用编码器的双向建模能力,同时保留生成任务的自回归特性。
- HTLM[69]利用BART去噪目标对超文本语言进行建模,超文本语言包含有关文档级结构的宝贵信息。该模型在各种生成任务的零样本学习中也实现了最先进的性能。
- DQ-BART[70]将BART压缩为较小的模型,从而在各种下游任务上实现BART的原始性能。
T5演化出Switch Transformer、ExT5;
bert和GPT→bart
BART演化出HTLM、DQ-BART

InstructGPT[10]的体系结构。首先,使用人类贴标机收集演示数据并且用于微调GPT-3。然后从语言中抽取提示和相应的答案模型和人类标签将从最好到最差对答案进行排名。这些数据用于训练奖励模型。最后,通过训练的奖励模型,可以根据偏好对语言模型进行优化人类贴标机。
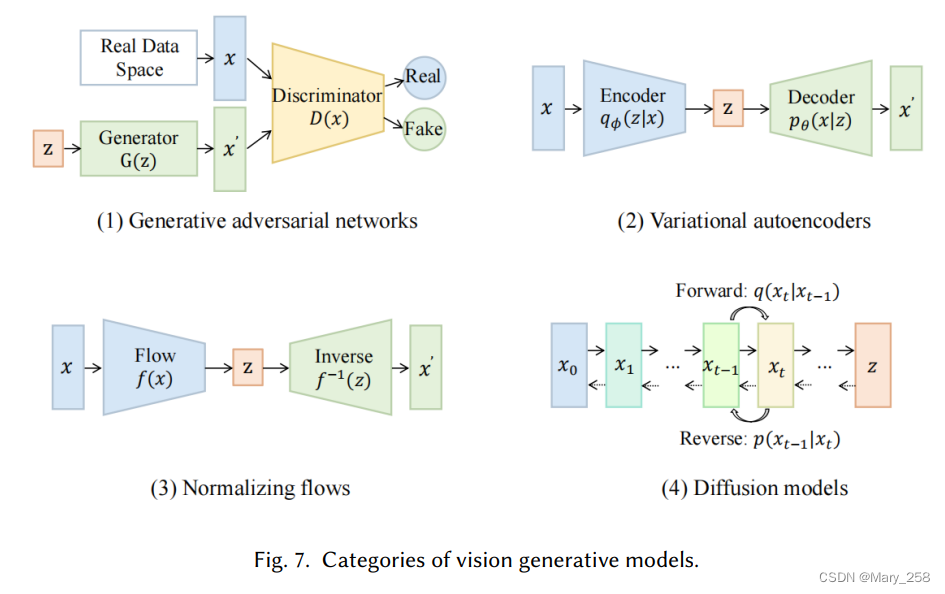
4.1.2 图像生成模型-Vision Generative Models
GAN
GANs consist of two parts, a generator生成器 and a discriminator鉴别器.生成器用于生成数据,鉴别器用于判别数据是否为真实数据。生成器和鉴别器的结构对GAN的训练稳定性和性能有很大影响。
Structure结构
LAPGAN[71]使用拉普拉斯金字塔框架[72]内的卷积网络级联,以从粗到细的方式生成高质量图像。
A.Radford等人[73]提出了DCGANs结构,这是一类具有架构约束的CNN,作为无监督学习的强大解决方案。
渐进式GAN[74]逐步扩展生成器和鉴别器,从低分辨率开始,添加层来建模更精细的细节,从而实现更快、更稳定的训练并生成高质量的图像。
由于传统的卷积GANs仅基于低分辨率特征图中的空间局部点来生成高分辨率细节,SAGAN[75]引入了注意力驱动、长程依赖性建模和频谱归一化,以改进训练动力学。
为了解决从复杂的数据集生成高分辨率和多样化的样本,BigGAN[76]被提出作为GANs的大规模TPU实现。
StyleGAN[77]通过分离高级属性和变体来改进GANs,从而在质量度量、插值和解纠缠方面实现直观的控制和更好的性能。[78,79]专注于反向映射——将数据投影回潜在空间,从而为辅助判别任务提供有用的特征表示。
为了解决模式崩溃问题并改进生成模型,D2GAN[80]和GMAN[81]方法都通过组合额外的鉴别器来扩展传统的GAN。
MGAN[82]和MAD-GAN[83]通过结合多个生成器和一个鉴别器来解决模式崩溃问题。CoGAN[84]由一对具有权重共享约束的GAN组成,允许从单独的边缘分布学习联合分布,而不需要训练集中的相应图像。
代表性变体
作为潜在矢量
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

