
热门标签
热门文章
- 1复杂任务也不怕!上海AI Lab提出增强型LLM框架—ControlLLM,大模型可操控多模态工具
- 2Advanced RAG 05:探讨基于文本内在语义信息的数据分块方法_semanticchunker
- 3Nginx限制上传(下载)大小限制_nginx文件上传下载大小限制配置
- 4模型训练中,不调用gpu比调用gpu更快的情况_使用gpu和cpu进行训练神经网络时间对比
- 5ShowMeBug x 红杉 | 创业公司怎么做好技术招聘?
- 6WEB/UI自动化实战--从入门到实战,保姆级教程Step1--环境部署_webui自动化环境搭建
- 7Android TextView加中划线/下划线_textview中划线
- 8springcloud-config.git: Auth fail_springcloud 使用github 作为配置中心,报错 auth fail
- 9【Rust】——使用消息在线程之间传递数据
- 10Effective Java 78条军规_a value class is simply a class that represents a
当前位置: article > 正文
【AIGC】Mac Intel 本地 LLM 部署经验汇总(CPU Only)_llm部署 cpu加载
作者:你好赵伟 | 2024-05-31 22:55:34
赞
踩
llm部署 cpu加载
书接上文,在《【AIGC】本地部署 ollama(gguf) 与项目整合》章节的最后,我在 ollama 中部署 qwen1_5-14b-chat-q4_k_m.gguf 预量化模型,在非 Stream 模式下需要 89 秒才完成一轮问答,响应速度实在是太慢,后续需要想办法进行优化…
PS:本人使用的是 2020 年 Intel 版本的 Macbook Pro(以下简称“MBP”)。如下图:
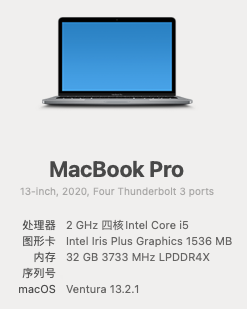
1. Ollama 模型性能对比
为了解决这个问题,找很多 ollama 的资料,基本上可以确定 3 点信息:
- ollama 会自动适配可用英伟达(NVIDIA)显卡。若显卡资源没有被用上应该是显卡型号不支持导致的。如下图:
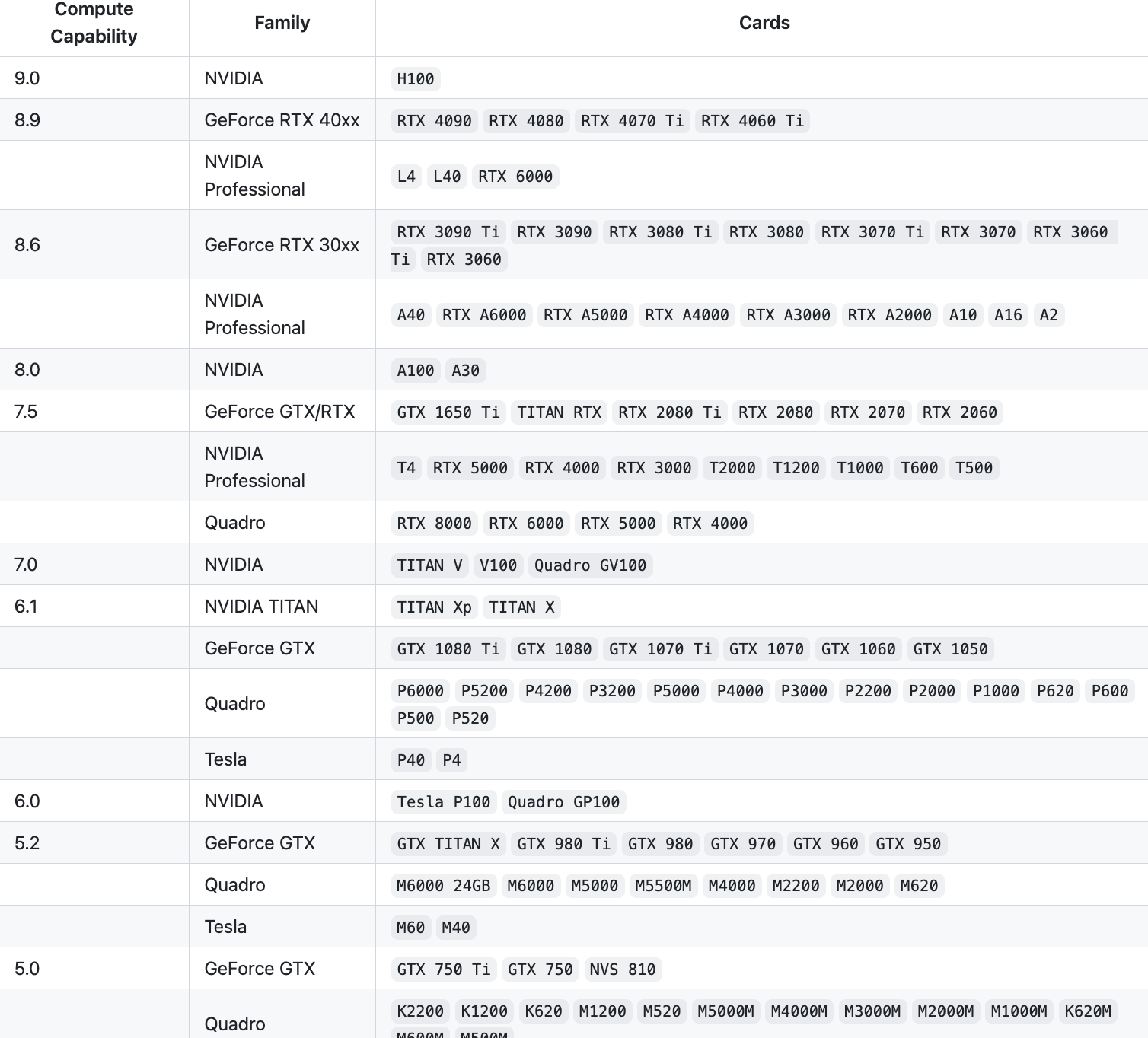
- ollama 支持 AMD 显卡的使用,如下图:

- 至于 Apple 用户 ollama 也开始支持 Metal GPUs 方案

欸…看到这里好像又有点希望了,我的 MBP 估计也支持 Metal 方案吧
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/654777
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

