
热门标签
热门文章
- 110分钟了解Jmeter性能测试工具,懂事的已经点进来看了_性能测试工具jmeter
- 2《SpringBoot篇》01.Springboot超详细入门(基础篇)_spring boot
- 3如何解决无法远程连接云服务器Windows实例_indows无法自动登录,请检查服务器远程设置中是否勾选了妆夺许云待单网求别身恰翰
- 4树和二叉树(C语言)_树的tip
- 5张量的视角建模RIS信道(1)_ris信道模型
- 6OpenAI已全面开放自定义GPT以及文件上传等功能
- 751单片机应用篇-- --智能门锁_单片机项目智能门锁技术路线图
- 8如何使用宝塔面板搭建Tipask问答社区网站并发布公网远程访问
- 9计算机网络面试_哪一种交付方式不能保证数据包
- 10SpringAI项目之Ollama大模型工具【聊天机器人】_java调用ollama接口
当前位置: article > 正文
pytorch bert文本分类_中文文本分类 pytorch实现
作者:笔触狂放9 | 2024-06-05 19:27:02
赞
踩
结合bert和rnn的中文文本分类

来自 | 知乎 作者 | 胡文星
地址 | https://zhuanlan.zhihu.com/p/73176084
编辑 | 机器学习算法与自然语言处理公众号
本文仅作学术分享,若侵权,请联系后台删文处理
前言
使用pytorch实现了TextCNN,TextRNN,FastText,TextRCNN,BiLSTM_Attention,DPCNN,Transformer。 github:Chinese-Text-Classification-Pytorch,开箱即用。中文数据集:
我从THUCNews中抽取了20万条新闻标题,文本长度在20到30之间。一共10个类别,每类2万条。以字为单位输入模型,使用了预训练词向量:搜狗新闻 Word+Character 300d。类别:财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐。数据集、词表及对应的预训练词向量已上传至github,开箱即用。 模型效果: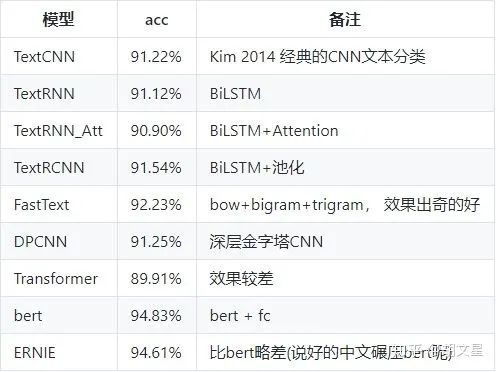
1.TextCNN
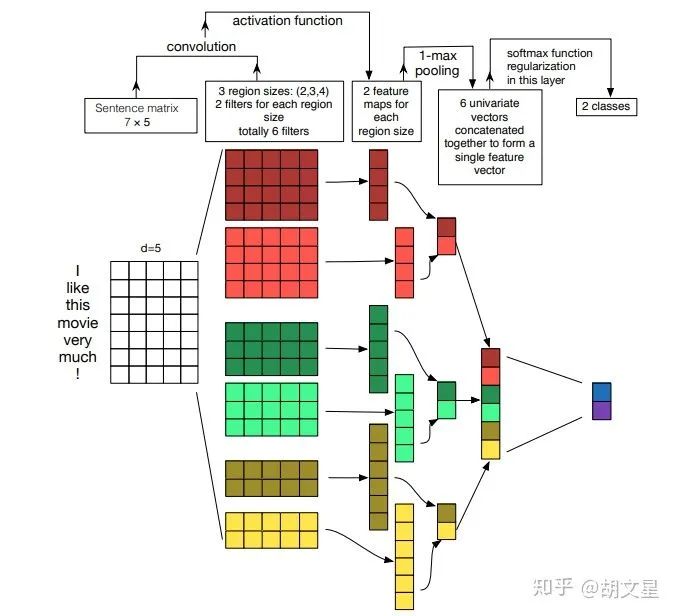 TextCNN整体结构
TextCNN整体结构
3个尺寸的卷积核:(2, 3, 4),每个尺寸的卷积核有100个。卷积后得到三个特征图: [batch_size, 100, seq_len-1] [batch_size, 100, seq_len-2] [batch_size, 100, seq_len-3]4.池化层:对三个特征图做最大池化 [batch_size, 100] [batch_size, 100] [batch_size, 100]5.拼接: [batch_size, 300]6.全连接:num_class是预测的类别数 [batch_size, num_class]7.预测:softmax归一化,将num_class个数中最大的数对应的类作为最终预测 [
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/677833
推荐阅读
相关标签

