
AIGC技术研究与应用 ---- 下一代人工智能:新范式!新生产力!(2.4 -大模型发展历程 之 多模态)_多模态大模型:新一代人工智能技术范式 pdf
赞
踩
什么是多模态
多模态生成, 指将一种模态转换成另一种模态, 同时保持模态间语义一致性 。主要集中在文字生成图片 、文字生成视频及图片生成文字。
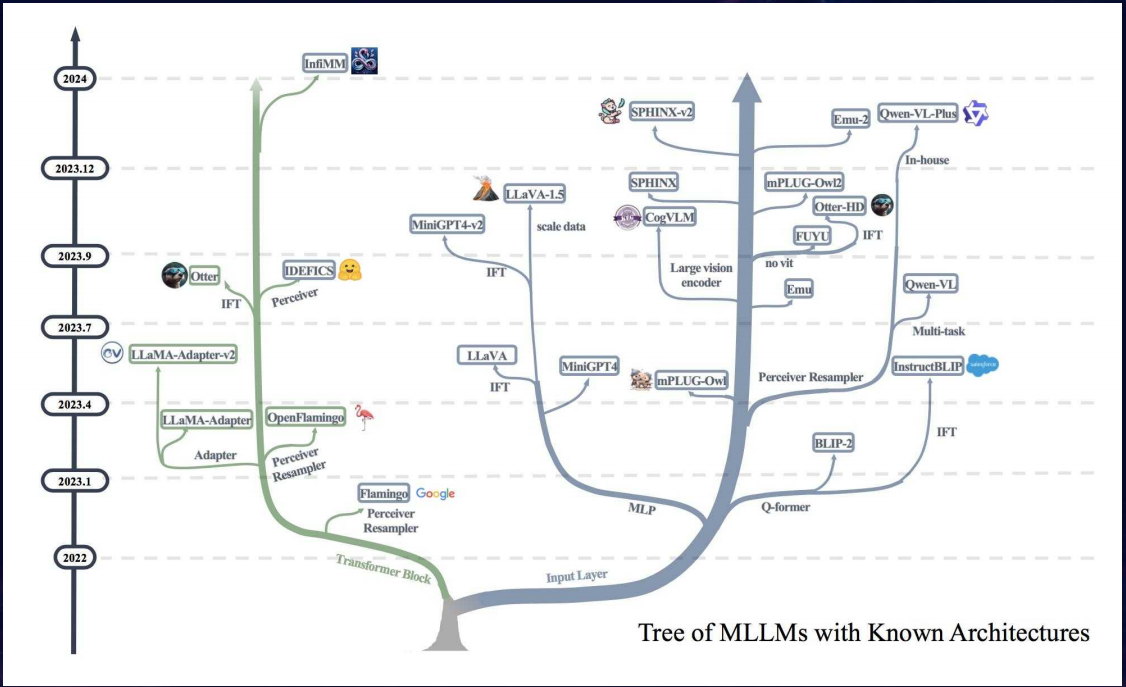
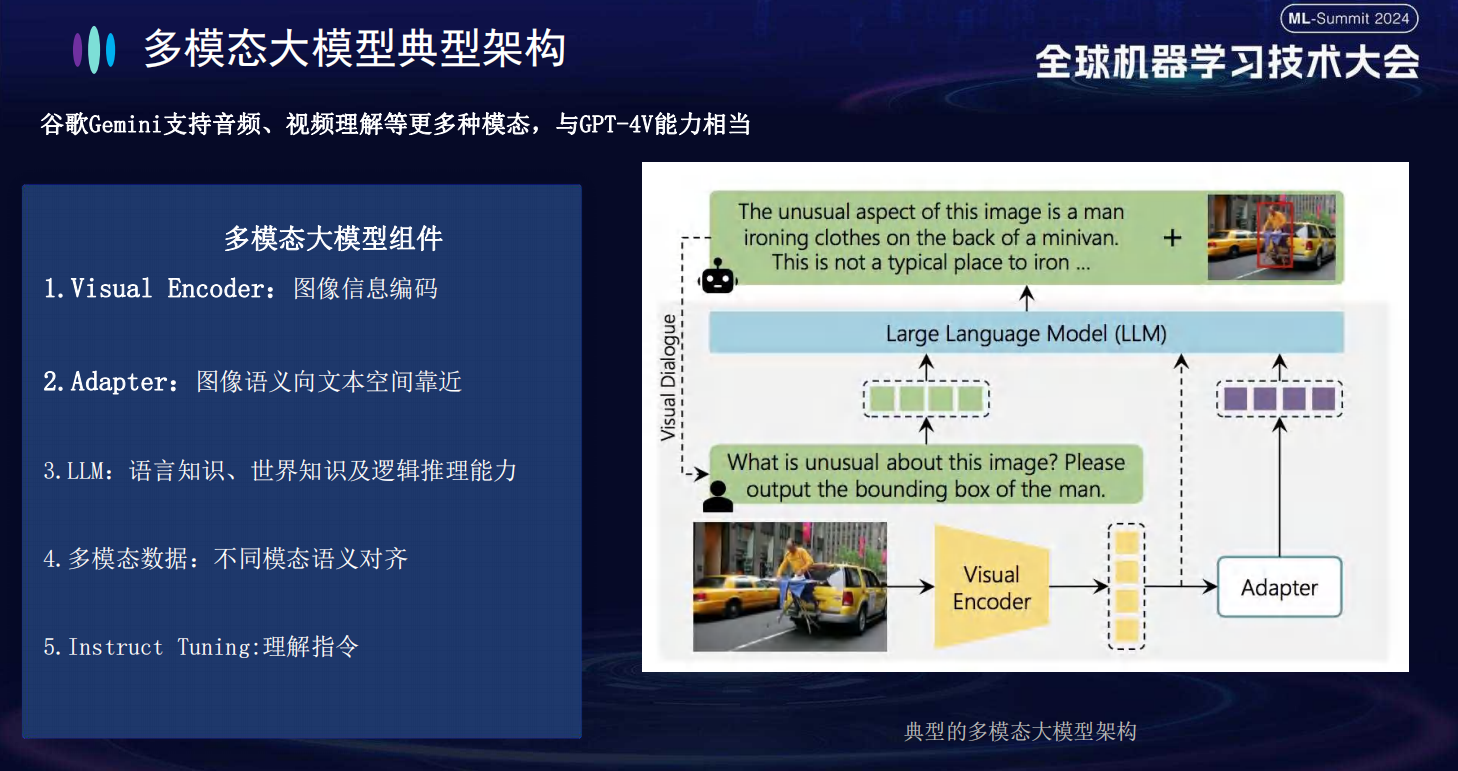
为什么 Transformer 也是多模态模型的基础架构
多模态数据的最大挑战之一就是要汇总多种模式(或视图)中的信息,以便在过滤掉模式的冗余部分的同时,又能将补充信息考虑进来。
第一个是任务方面,之前的多模态任务是怎么做的,为什么现在大家会转向Transformer做多模态任务?
在Transformer,特别是Vision Transformer出来打破CV和NLP的模型壁垒之前,CV的主要模型是CNN,NLP的主要模型是RNN,那个时代的多模态任务,主要就是通过CNN拿到图像的特征,RNN拿到文本的特征,然后做各种各样的Attention与concat过分类器,这个大家可以从我文章栏的一篇ACL论文解说《Writing by Memorizing: Hierarchical Retrieval-based Medical Report Generation》略窥一二,使用这种方式构造出来的多模态模型会大量依赖各种模型输出的特征进行多重操作,pipeline巨大并且复杂,很难形成一个end2end的方便好用的模型
第二个是模型原理层面,为什么Transformer可以做图像也可以做文本,为什么它适合做一个跨模态的任务?
说的直白一点,因为Transformer中的Self-Attetion机制很强大,使得Transformer是一个天然强力的一维长序列特征提取器,而所有模态的信息都可以合在一起变成一维长序列被Transformer处理
视觉 Transformer 和 Text Transformer 如何结合 - contrastive learning 对比学习
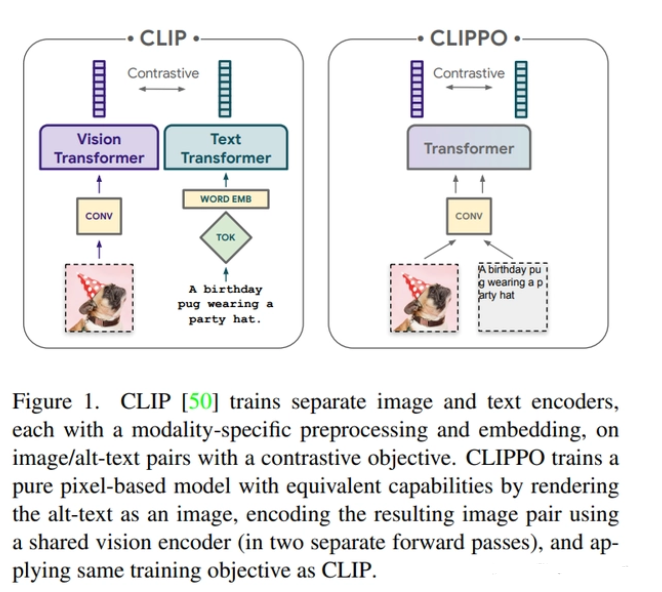
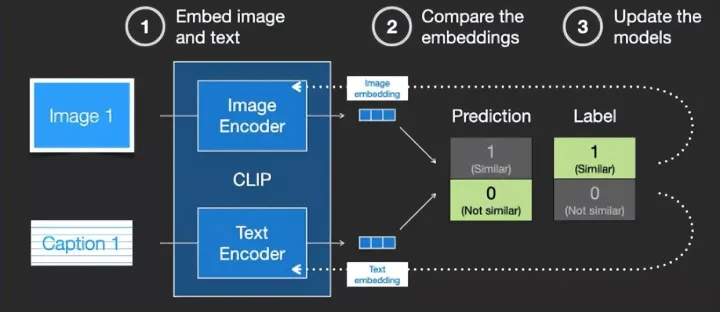
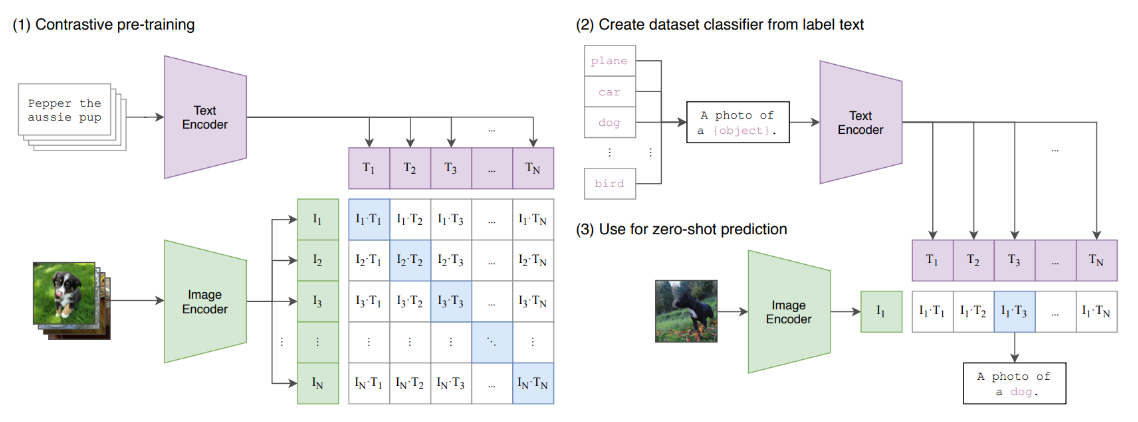
2021年, OpenAI发布了CLIP, 是一种经典的文图跨模态检索模型, 在大规模图文数据集上进行了对比学习预训练, 具有很强的文图跨模态表征学习能 力 。CLIP模型包含图像和文本的Encoder两部分, 用于对图像和文本分别进行特征抽取。
clip 的核心是使用INfoNCE Loss进行文本和图像两种模态间互信息最大化
对比学习首先学习未标记数据集上图像的通用表示形式,然后可以使用少量标记图像对其进行微调,以提升在给定任务(例如分类)的性能。简单地说,对比表示学习可以被认为是通过比较学习。相对来说,生成学习(generative learning)是学习某些(伪)标签的映射的判别模型然后重构输入样本。在对比学习中,通过在输入样本之间进行比较来学习表示。对比学习不是一次从单个数据样本中学习信号,而是通过在不同样本之间进行比较来学习。可以在“相似”输入的正对和“不同”输入的负对之间进行比较。

对比学习通过同时最大化同一图像的不同变换视图(例如剪裁,翻转,颜色变换等)之间的一致性,以及最小化不同图像的变换视图之间的一致性来学习的。 简单来说,就是对比学习要做到相同的图像经过各类变换之后,依然能识别出是同一张图像,所以要最大化各类变换后图像的相似度(因为都是同一个图像得到的)。相反,如果是不同的图像(即使经过各种变换可能看起来会很类似),就要最小化它们之间的相似度。通过这样的对比训练,编码器(encoder)能学习到图像的更高层次的通用特征 (image-level representations),而不是图像级别的生成模型(pixel-level generation)。
参考:https://towardsdatascience.com/a-framework-for-contrastive-self-supervised-learning-and-designing-a-new-approach-3caab5d29619
stable diffusion

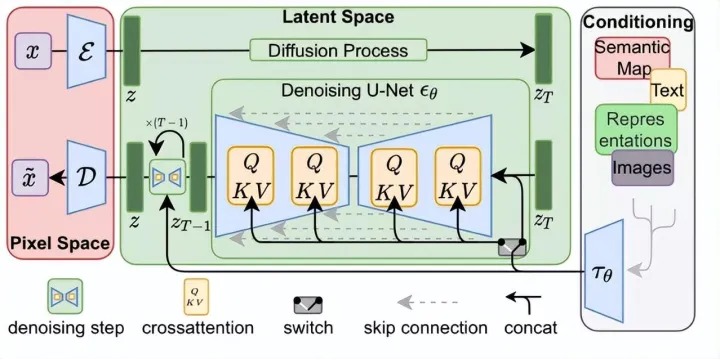

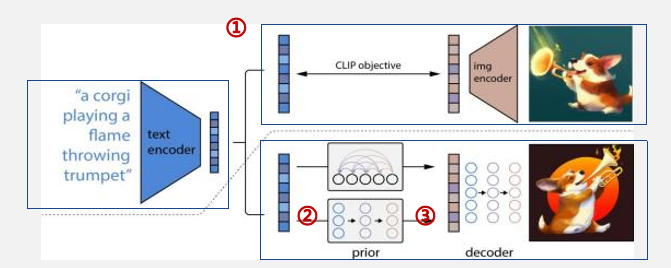
“ CLIP + 其他模型”成为通用的做法
多模态定义: 多模态生成, 指将一种模态转换成另一种模态, 同时保持模态间语义一致性 。主要集中在文字生成图片 、文字生成视频及图片生成文字。
◼ Transformer架构的跨界应用成为跨模态重要开端之一 。多模态训练普遍需要匹配视觉的区域特征和文本特征序列, 形成Transformer架构擅长处理的一 维长序列, 与Transformer的内部技术架构相符合 。此外Transformer架构还具有更高的计算效率和可扩展性, 为训练大型跨模态模型奠定了基础。
◼ CLIP ( Contrastive Language-Image Pre-training, 可对比语言-图像预训练算法) 成为图文跨模态重要节点。
✓ 2021年, OpenAI发布了CLIP, 是一种经典的文图跨模态检索模型, 在大规模图文数据集上进行了对比学习预训练, 具有很强的文图跨模态表征学习能 力 。CLIP模型包含图像和文本的Encoder两部分, 用于对图像和文本分别进行特征抽取。
✓ “CLIP+其他模型”在跨模态生成领域成为较通用的做法, 如Disco Diffusion, 其原理为CLIP模型持续计算Diffusion模型随机生成噪声与文本表征的 相似度, 持续迭代修改, 直至生成可达到要求的图像。
论文标题:Learning Transferable Visual Models From Natural Language Supervision
论文链接:https://arxiv.org/abs/2103.00020
github: https://github.com/OpenAI/CLIP
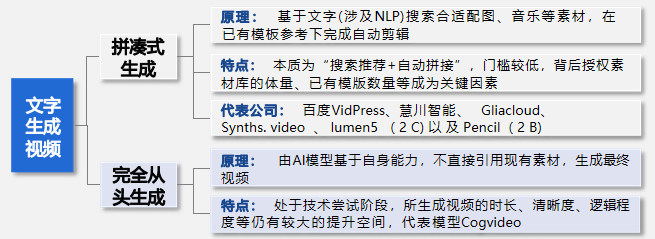
多模态模态生成:文字生成图像取得突破,其他领域仍有待提升
◼ 文字生成图像: 2021年, OpenAI推出了CLIP和DALL-E, 一年后推出了DALL-E2; 2022年5月, 谷歌推出了Imagen和新一代AI绘画大师Parti; 2022年 8月, Stability Al推出Stable diffusion并宣布开源 。国内主流的AI绘画平台有文心一格 、盗梦师 、意间AI 、Tiamat等。
◼ 文字生成视频: 以Token为中介, 关联文本和图像生成, 逐帧生成所需图片, 最后逐帧生成完整视频 。但由于视频生成会面临不同帧之间连续性的问题, 对 生成图像间的长序列建模问题要求更高, 以确保视频整体连贯流程 。按技术生成难度和生成内容, 可区分为拼凑式生成和完全从头生成。
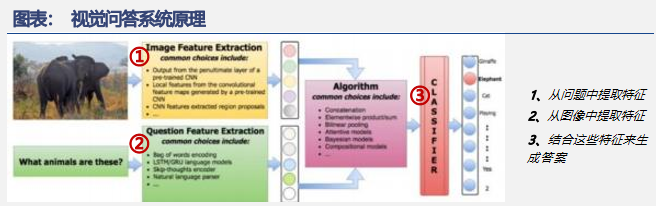
◼ 图像/视频生成文本: 具体应用有视觉问答系统 、配字幕 、标题生成等, 代表模型有METER 、ALIGN等。

参考文献与学习路径
车万翔等统稿
- ChatGPT 调研报告
模型部署简介
- https://github.com/open-mmlab/mmdeploy/blob/master/docs/zh_cn/tutorial/01_introduction_to_model_deployment.md
GPT 系列模型解析
ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT
- https://blog.csdn.net/v_JULY_v/article/details/128579457
数云融合|探究GPT家族的进化之路:GPT-3、GPT-3.5和GPT-4的比较分析
- https://zhuanlan.zhihu.com/p/616691512
前序文章
- 初探 GPT-2
- 生成式AI(Generative AI)将重新定义生产力
- AIGC 后下一个巨大的风口:AI生成检测
- 代表AIGC 巅峰的ChatGPT 有哪些低成本开源方案能够复现?
- 如何驯化生成式AI,从提示工程 Prompt Engineering 开始 !
模型进化
面向统一的AI神经网络架构和预训练方法
- https://www.sohu.com/a/673342257_121124371
券商研报
从ChatGPT到生成式AI:人工智能新范式重新定义生产力
- https://xueqiu.com/9005856403/240887888
- https://xueqiu.com/5159309685/241858304
浙商证券:《AIGC算力时代系列:ChatGPT研究框架》
国泰君安:ChatGPT研究框架(2023)
腾讯研究院:AIGC发展趋势报告2023
华东政法大学:人工智能通用大模型ChatGPT的进展风险与应对
- http://www.199it.com/archives/1568017.html
ChatGPT浪潮下,看中国大语言模型产业发展
- https://www.iresearch.com.cn/Detail/report?id=4166&isfree=0
AI服务器拆解,产业链核心受益梳理
- https://xueqiu.com/2524803655/247578353
国海证券,AIGC深度行业报告:新一轮内容生产力革命的起点
https://xueqiu.com/6695901611/243415262
陆奇演讲
飞书的赛比链接不能复制只能看。。。
陆奇演讲PPT官方版
https://miracleplus.feishu.cn/file/TGKRbW4yrosqmixCtprcUlAynzg
陆奇演讲视频官方版
https://miracleplus.feishu.cn/file/OrO7bivJeoT6FxxSjaJcXWlwncS
陆奇演讲文本官方版
https://miracleplus.feishu.cn/docx/Mir6ddgPgoVs3KxF6sncOUaknNS
微信公众号版本 ,能复制
- https://mp.weixin.qq.com/s/fzYxwaANqWpqxC__1zTNDA
多模态
为什么Transformer适合做多模态任务?
- https://www.zhihu.com/question/441073210/answer/2991137965
- https://www.zhihu.com/question/441073210
直观理解Stable Diffusion
- https://zhuanlan.zhihu.com/p/598999843

