
- 1AES加密的中文乱码与Java默认编码_aes解密乱码
- 2【爬虫实战】7基础Python网络爬虫——淘宝商品比价定向爬虫(MOOC学习笔记)_淘宝爬虫
- 3【微信小程序】事件分类以及阻止事件冒泡_微信小程序怎样阻止事件冒泡
- 4python实现植物大战僵尸_Python开发植物大战僵尸游戏
- 5RK3588 Android13自定义一个按键实现长按短按_rk3588 gpio-keys
- 6windows上oh-my-posh和posh-git安装,提升命令行美观和开发效率,附带vscode的适配
- 7Linux常见命令的缩写来源单词
- 8TLS/SSL 协议详解 (9) Client hello_ssl 44个字节随机数
- 9二叉树的应用——哈夫曼树_二叉树的实际生活应用及案例
- 10Task7 第八章 集成学习_按照集成学习的组合策略不同可以分为
基于python的豆瓣电影数据的可视化与分析_基于电影票房与观众评价的可视化数据集
赞
踩
1 项目背景意义介绍
电影是一种具有极高娱乐性和文化价值的艺术形式,自从电影产业诞生以来,已经成为了人们生活中的重要组成部分。电影产业在全球范围内都有着广泛的影响力,对经济、文化、社会等多个方面都起到了积极的作用。因此,对电影产业进行数据分析和可视化,可以帮助我们更好地了解电影市场的发展状况和趋势,有助于制定更加科学合理的电影投资、制作和营销策略。
对于给定的这份电影数据,其中包含了一些关键的信息,比如电影的年份、名称、预算、收入、类型和评分等,这些数据可以帮助我们分析电影市场的发展情况和趋势,以及各个类型电影的表现和受欢迎程度。通过对这些数据进行分析和可视化,可以看出各个类型的电影在市场中的占比、哪种类型的电影最受欢迎
预算和收入之间是否存在某种关系、高预算的电影是否总是表现更好、评分和收入之间是否有一定的相关性高评分的电影是否总是收入更高
通过对这些问题进行数据分析和可视化,可以帮助电影从业者更好地了解市场形势、洞察观众需求,从而制定更加科学合理的策略,提高电影制作、投资和营销的成功率。同时,对于观众来说,这些数据和分析结果也可以帮助他们更好地了解电影市场和各种类型电影的特点,从而做出更加明智的选择。
2 数据介绍
2.1数据字段介绍
这份电影数据集包含了一些重要的字段,下面是对每个字段的详细介绍:
年份:指电影的发行年份,它可以帮助我们追踪电影市场的发展历程,探究不同时期电影市场的特点和趋势。
电影名称:指电影的具体名称,它可以帮助我们识别不同的电影作品,并进行更加精细的分析。
预算(亿元):指电影制作过程中的预算成本,它可以反映出电影制作的规模和质量水平,以及各种成本因素对电影市场表现的影响。
收入(亿元):指电影在票房、DVD销售、版权收益等方面所获得的收益总额,它是衡量电影市场表现的重要指标之一。
类型:指电影的类别或类型,如动作片、恐怖片、喜剧片等,它可以帮助我们分析不同类型的电影在市场中的表现和受欢迎程度。
评分:指电影在影评网站或观众评价平台上的得分,它可以帮助我们评估电影的质量和口碑,并探究评分与收入之间的相关性。
通过对这些数据字段的分析和可视化,我们可以了解电影市场的发展情况和趋势,了解不同类型的电影在市场中的占比以及受欢迎程度,探究预算和收入之间的关系,评估电影的质量和口碑,并为制定更加科学合理的电影投资、制作和营销策略提供参考依据。
2.2 数据展示
如图所示是文件的数据,存在excel文件中,具体如下图所示:

3.数据处理
3.1查看数据类型
这行代码将会返回数据框中每个列的数据类型。通过这个操作,您可以了解每个字段的数据类型是什么,比如整数(int)、浮点数(float)、字符串(object)等。
# 查看数据类型
data_types = df.dtypes
print("数据类型:\n", data_types)
效果图如下所示:

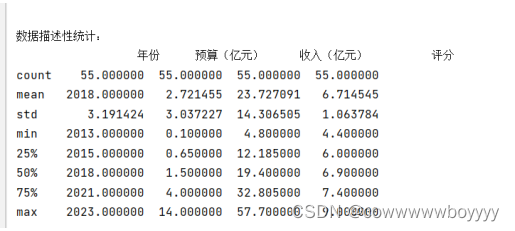
3.2 数据描述性统计
这行代码将会生成关于数据的描述性统计信息,包括计数(count)、均值(mean)、标准差(std)、最小值(min)、25%分位数(25%)、中位数(50%)、75%分位数(75%)和最大值(max)等。这些统计信息能够帮助您了解数据的分布情况和异常值等。
# 数据描述性统计
data_description = df.describe()
print("\n数据描述性统计:\n", data_description)
效果图如下所示:
3.4 数据清洗
数据分析和清洗在数据科学和业务决策中起着至关重要的作用,发现模式和趋势:通过数据分析和清洗,可以揭示数据中的模式和趋势,帮助我们理解数据背后的故事。这有助于发现隐藏的关联性和规律,提供对业务环境的深入洞察,并支持战略决策。
检测异常值和错误:数据中常常存在异常值、离群点和错误数据,这可能会对分析结果产生严重影响。通过数据清洗,可以识别和处理这些异常情况,提高数据的准确性和可靠性。
数据预处理:原始数据通常是杂乱无章的,可能包含缺失值、重复值、格式不一致等问题。数据清洗的过程可以对数据进行预处理,包括填补缺失值、去除重复值、统一数据格式等,为后续分析提供干净、一致的数据。
(1)重复值
由结果可知,没有重复值的情况

# 1. 查看重复值的情况,以及打印重复的数据
duplicate_rows = df[df.duplicated()]
print("重复值情况:")
print(duplicate_rows)
(2)缺失值
由结果可知,没有缺失值的情况
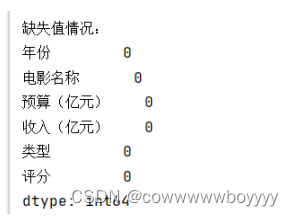
# 2. 查看缺失值的情况,以及打印缺失值的数据
missing_values = df.isnull().sum()
print("\n缺失值情况:")
print(missing_values)
(3)删除空行数据
#3. 删除空行
df.dropna(axis=0, how='any', inplace=True)
# 输出处理后的数据
print(df)
4.可视化展示
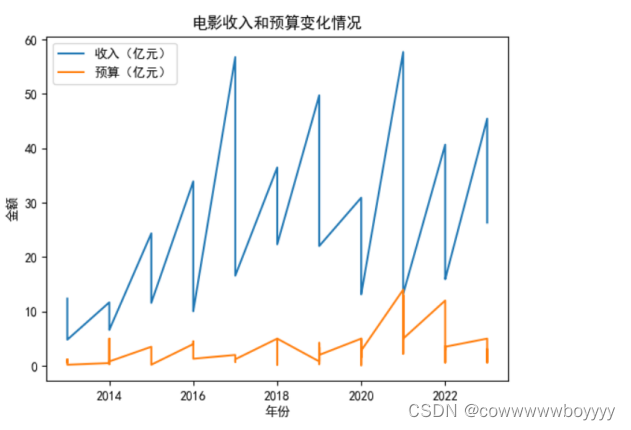
4.1 电影收入和预算变化情况
思路是首先从数据框中提取了年份、收入和预算三列的数据,然后使用matplotlib库绘制了折线图来展示电影收入和预算随着年份变化的情况。
通过提取数据框中的年份、收入和预算列,将它们分别存储在了year、revenue和budget这三个变量中。
接下来使用plot函数,分别以年份为横坐标,收入和预算为纵坐标,绘制了两条折线,分别代表收入和预算随着年份的变化情况。添加了标题('电影收入和预算变化情况')和坐标轴标签('年份'、'金额')。调用legend函数添加了图例,用来区分收入和预算两条曲线。最后调用show函数展示了绘制好的折线图。
通过这张折线图,可以直观地看到电影收入和预算随着年份的变化趋势,从而更好地了解电影市场的发展情况和财务状况。
4.2 不同类型电影的收入情况
(还有很多图省略..... 太多了不想复制了需要的可以评论区+三连哈)
4.3 评分 vs. 收入(亿元)
4.4 相同年份的电影数量统计
4.5 收入前6的电影
4.6 预算前6的电影
4.7 评分前6的电影
5.总结
根据以上的分析,我总结了以下几个点:
电影收入和预算变化情况:可以看出每年每个电影的收入都超出了实际的预算的价格。这可能是因为电影制作方在预算上保守估计,或者是电影在市场上获得了意外的成功,从而带来更高的收入。建议电影制作方在预算上加强估算,同时也要注意市场风险的影响,以避免因为资金问题导致电影制作的问题。
不同类型电影的收入情况:奇幻类型的是最多的,最少的是儿童的。这可能是因为奇幻类型的电影有着更广泛的受众群体,同时也具有更大的视觉效果和特效,吸引了更多的观众。而儿童类型的电影则需要更加注重教育性和亲和力,从而吸引到更多的儿童观众。建议电影制作方在选择电影类型时要综合考虑市场需求和观众喜好,同时也要注意电影内容的质量和特色。(省略.....)


