
- 1面试-数据库-锁模块
- 2SVN—清理以下路径失败_svn报错清理以下路径失败
- 3Pixelbook 2017 安装Ubuntu,Windows10 设备一切正常。_pixelbook2017刷win10
- 4抖去推短视频矩阵系统源代码开发部署----市场分析_抖去推ai源码
- 5集成学习与Voting模型(员工离职率预测)_python voting集成算法怎么调优
- 6企业微信集成策略:打破壁垒,驱动企业数字化转型
- 7EtherCAT超高速实时运动控制卡XPCIE1032H上位机C#开发(三):EtherCAT总线CSP,CSV,CST模式切换_ethercat运动控制卡
- 8OneNET视频能力体验------使用树莓派摄像头推流_树莓派 novif
- 9Python可以开发软件吗?Python入门学习!_python软件开发_可以用python做软件吗
- 10深度学总结:skip-gram pytorch实现_pytorch skip-gram
李宏毅机器学习(八)ELMo、BERT、GPT、XLNet、MASS、BART、UniLM、ELECTRA、others_bert和机器学习的区别
赞
踩
怎么得到这个pre-train好的模型呢?
Pre-training by Translation(翻译)
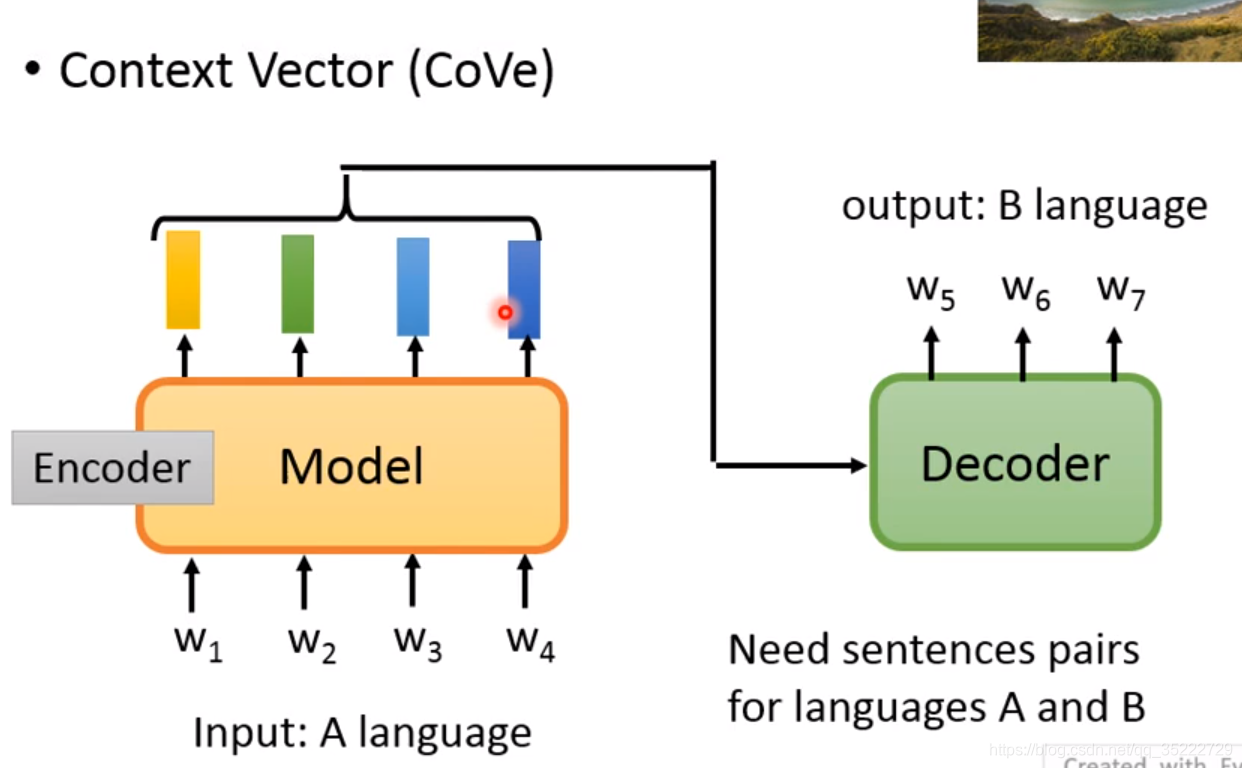
Context Vector(CoVe):
Embedding的words必须要考虑上下文! 有一个方法是用基于Translation的Model! 就是用Translation这个任务间接的训练model! 为什么不用Summary等任务作为工具呢,因为summary是提取某些word的重要性,那么不能做到对所有的word一视同仁! 同时该任务的缺点也在于需要大量的成对的数据,我们不可能有很多的数据!
Self-supervised Learning
就是我们不再用无监督作为名字了,而是使用自监督学习! 自监督就是用输入的一部分来预测自己的另一部分! 是没有标记的哦!
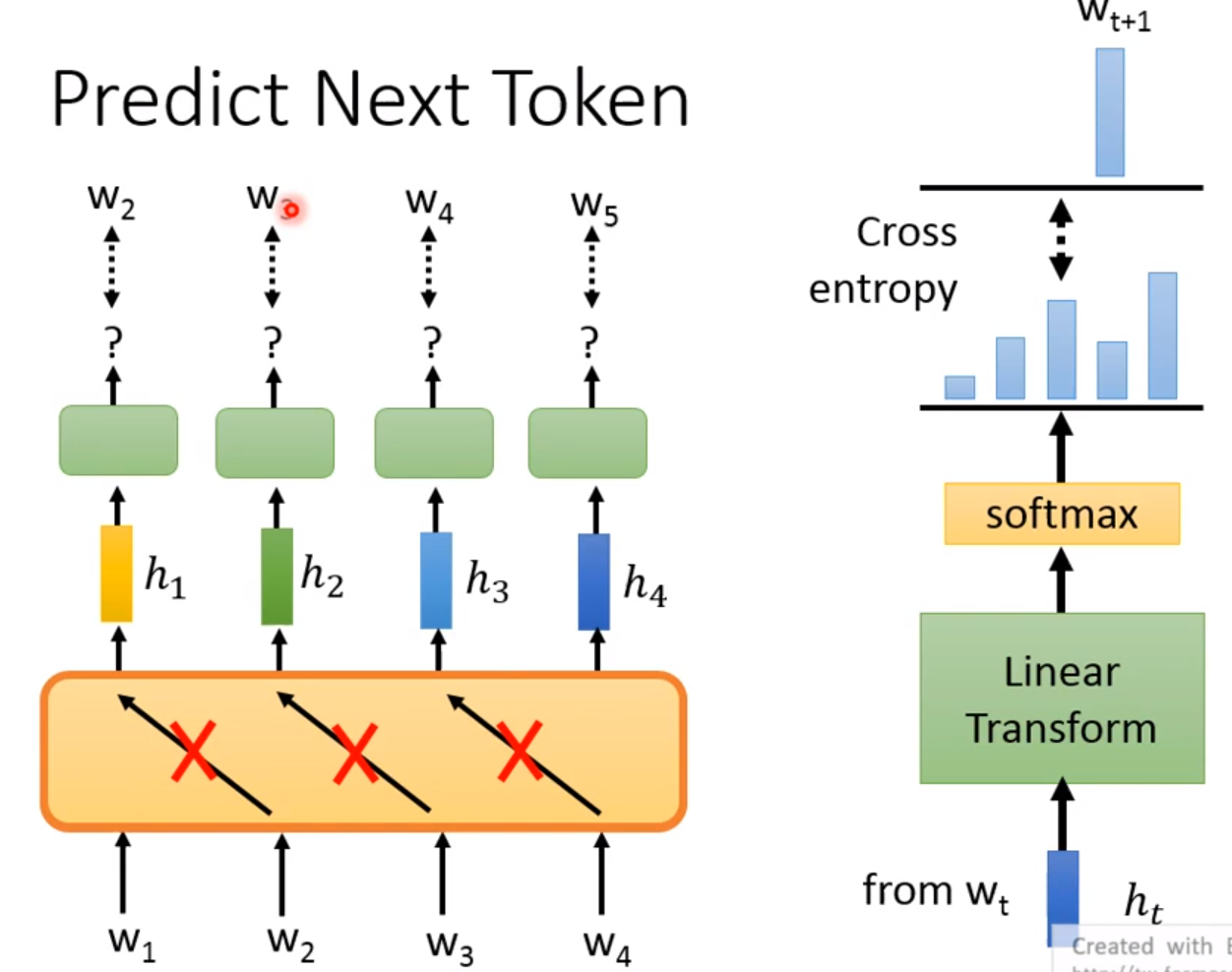
Predict Next Token
我们不能让 W 2 W_2 W2学习到不应该学习的知识,如果将 W 2 W_2 W2放入到 h 1 h_1 h1,那么就可以预测出 W 2 W_2 W2。而且右边就是整个的预测过程!
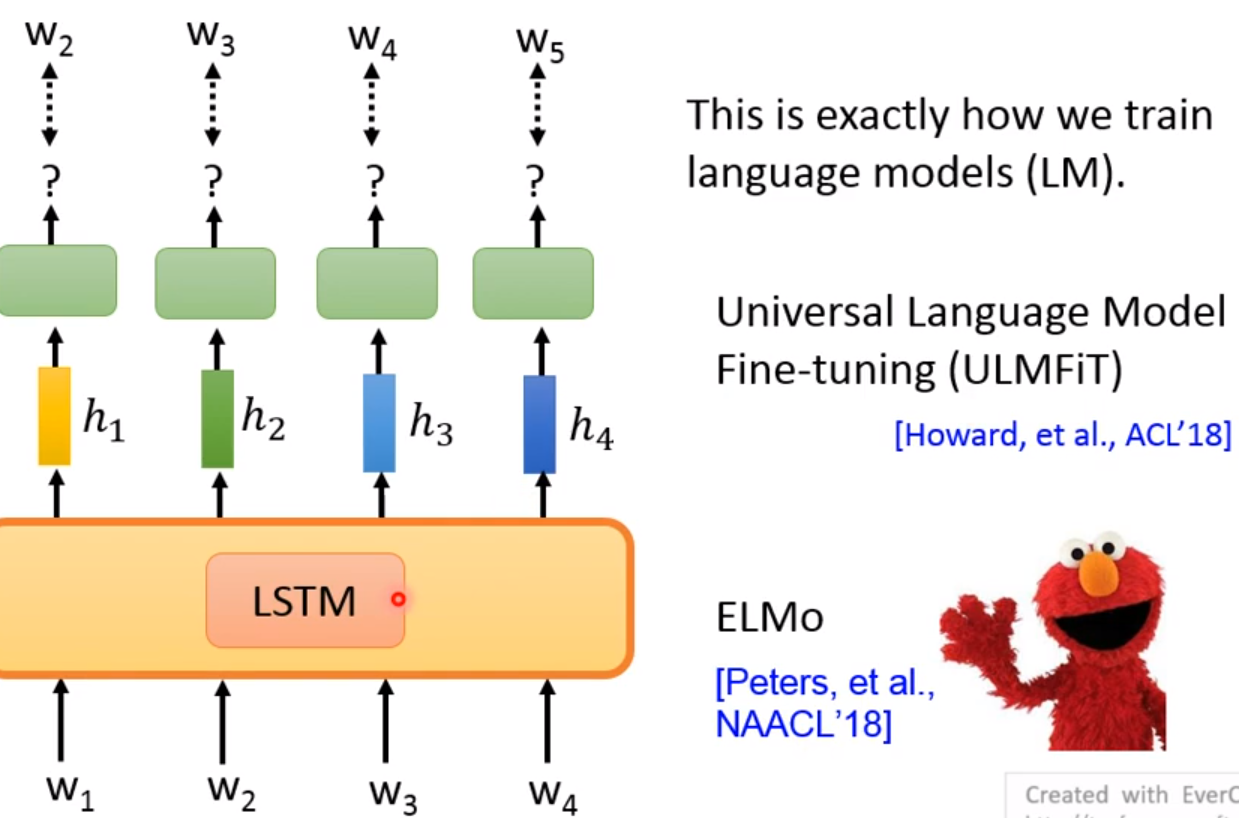
LM、ULMFiT、ELMo
都是使用的是LSTM!
GPT、GPT-2、Megatron、Turing NLG
使用的是自监督! 其中要留心attention的范围! 有限制的!
比如我们不能让模型看到后面的答案! 所以取attention的时候只能是前面所有!而不是整个句子!
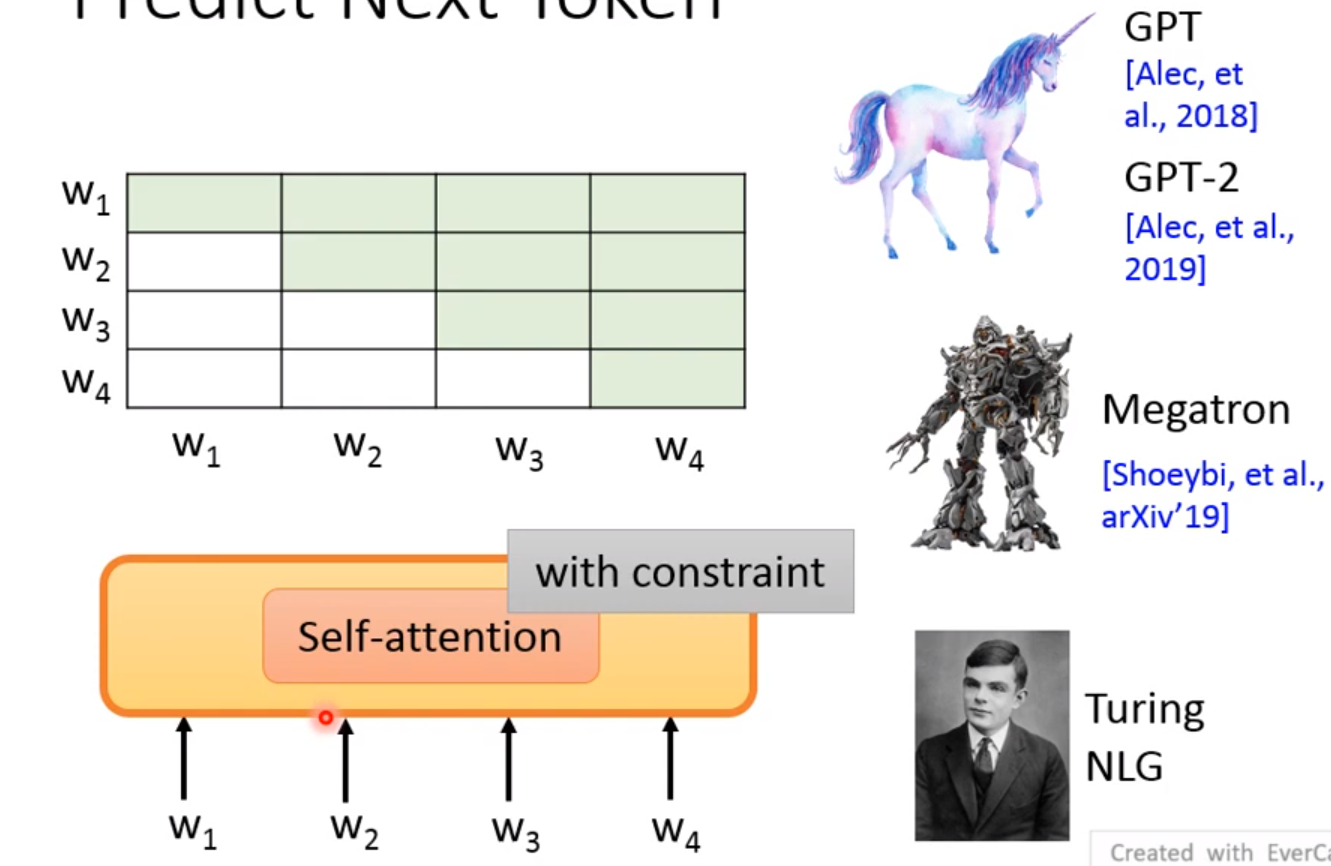
这有什么应用呢?
就是自己编一个文章! 比如独角兽新闻! GPT-2!
我们需要考虑左边的上下文,但是有右边的上下文呢!
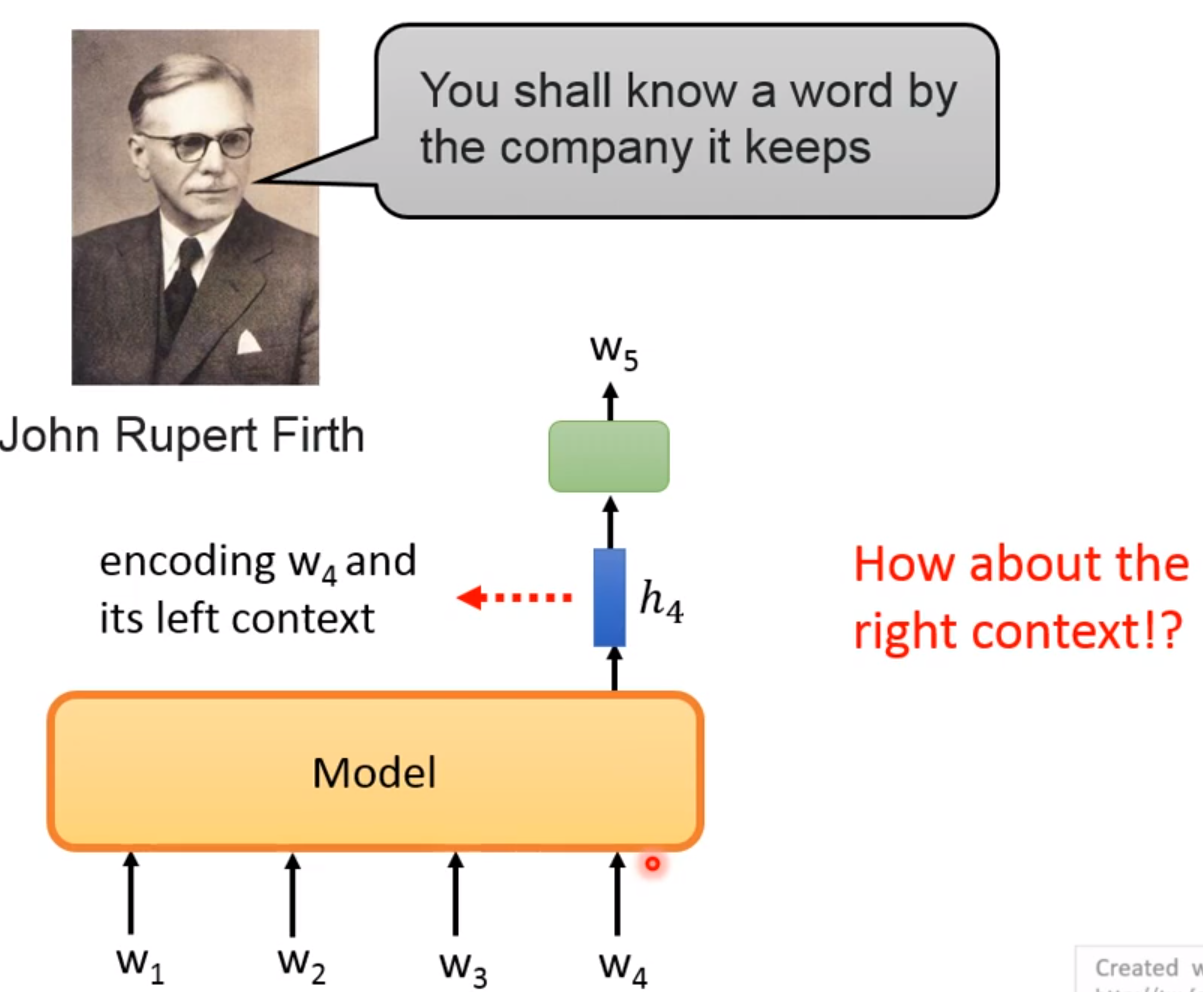
Predict Next Token-Bidirectional
ELMO! 双向考虑! 但是也有问题,你这样两个LSTM是单独处理的,你只是考虑了单边,而不是整个句子! 两个LSTM也是单独训练的!
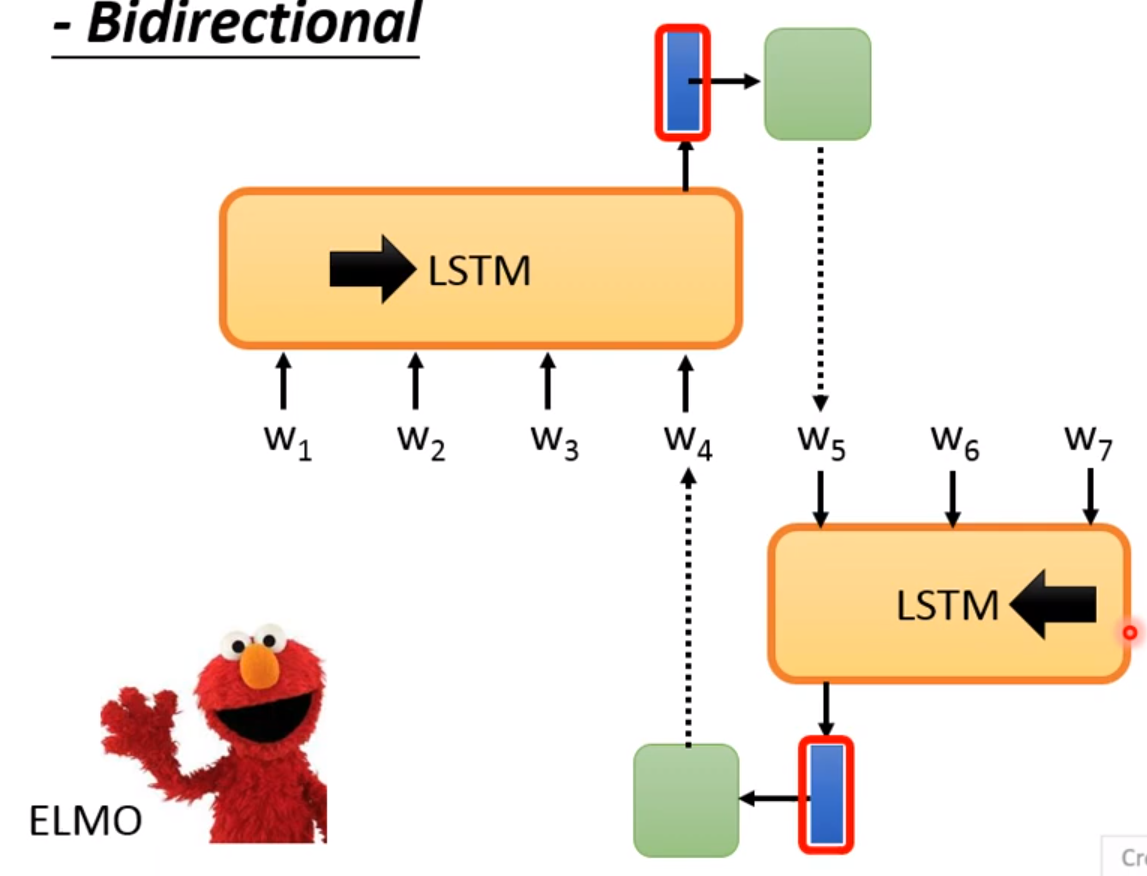
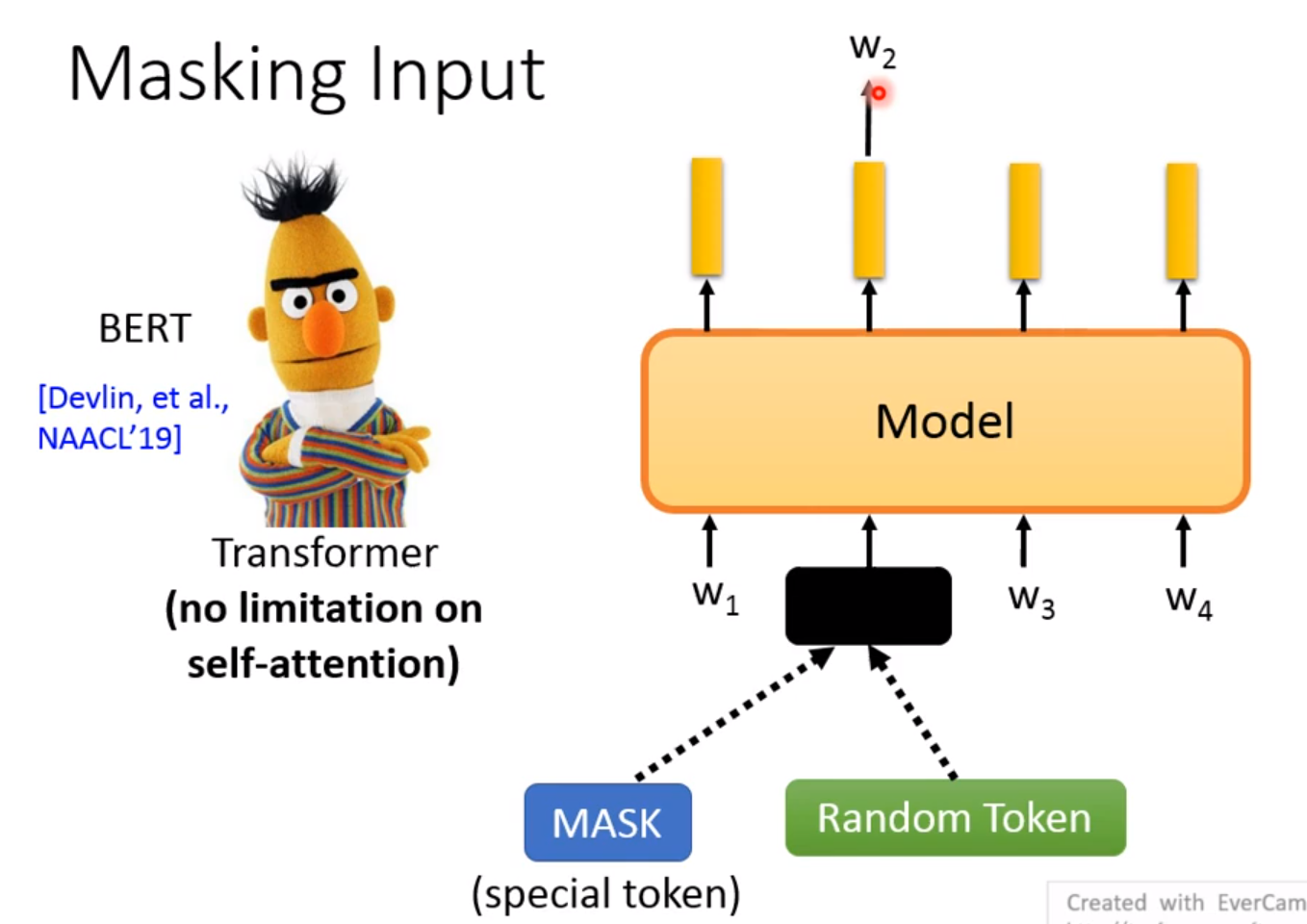
Masking Input
将某个Token进行Mask或者Random Token! 我们在学习 W 1 W_1 W1的时候要考虑 W 3 W_3 W3和 W 4 W_4 W4,相反 W 3 W_3 W3的时候也是这样! 由于 W 2 W_2 W2是被盖住了,所以不用担心学习到 W 2 W_2 W2的信息! 最终的目的就是学习到 W 2 W_2 W2!
CBOW:
和BERT不同: 左右看的范围是有一个Window,而BERT是有多少就计算多少! 第二个不同: BERT在Encoder之后输出Vector后可以连接头不同的向量,但是在CBOW中是直接相加的!
总结一下就是CBOW和BERT的训练方式基本都是一样的,只是模型的复杂度没有那么高!
Is random masking good enough?:
怎么覆盖呢? 比如黑龙江中,我们盖住“龙”字!还是整个黑龙江
两种不同的mask:
- Whole Word Masking(WWW)
WWW: 也就是把整个单词遮盖住! 而不是单个字!
而phrase-level是短语,多个单词;
Entity-level呢,则是更特定,就是特定的地名、组织名等! 也就是我们ERNIE!

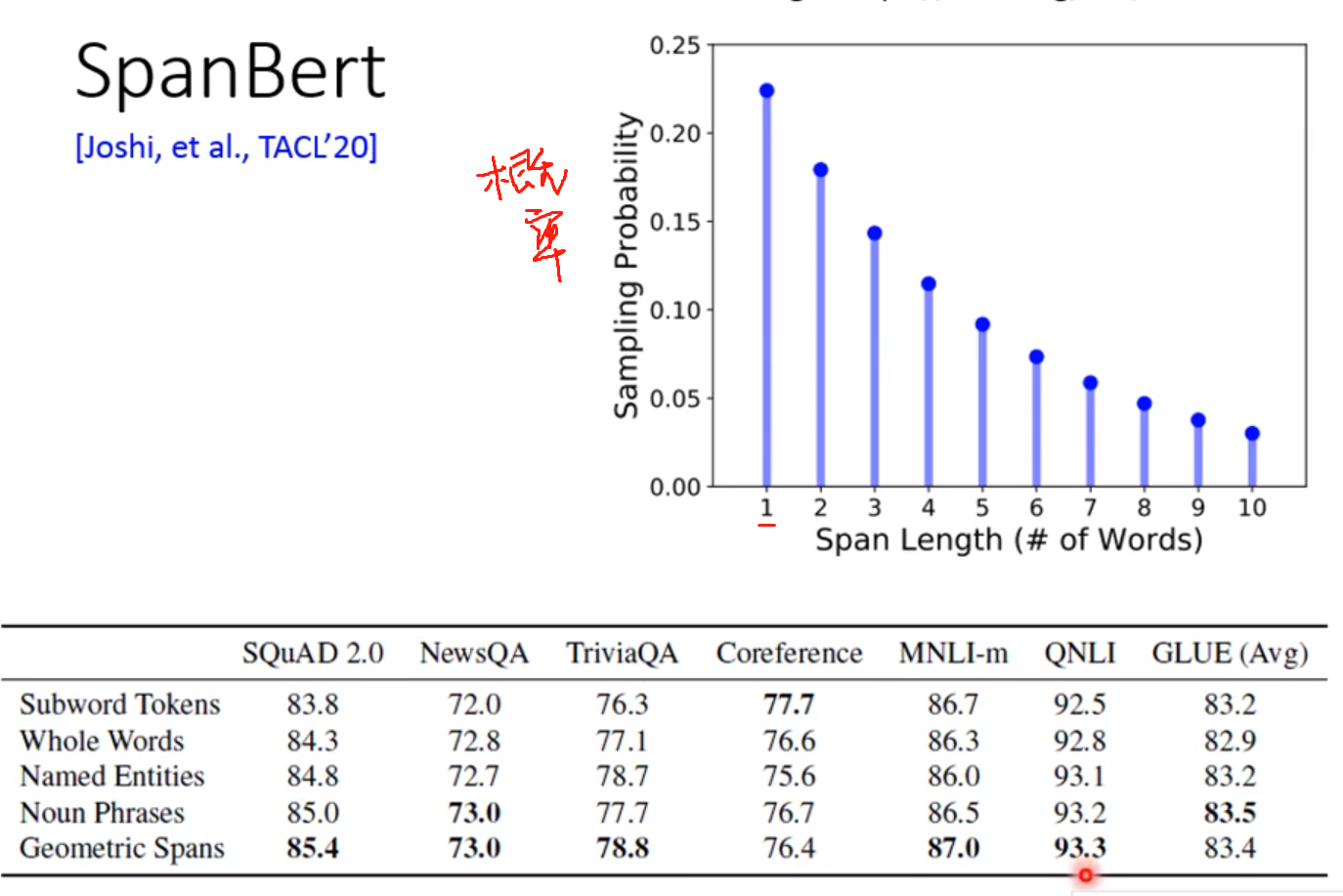
SPanBert:
按照几率该不同长度的Token!
提出的方法一般不可能在所有具体的方法都好! 下面的表格中,横坐标是不同的具体的任务!
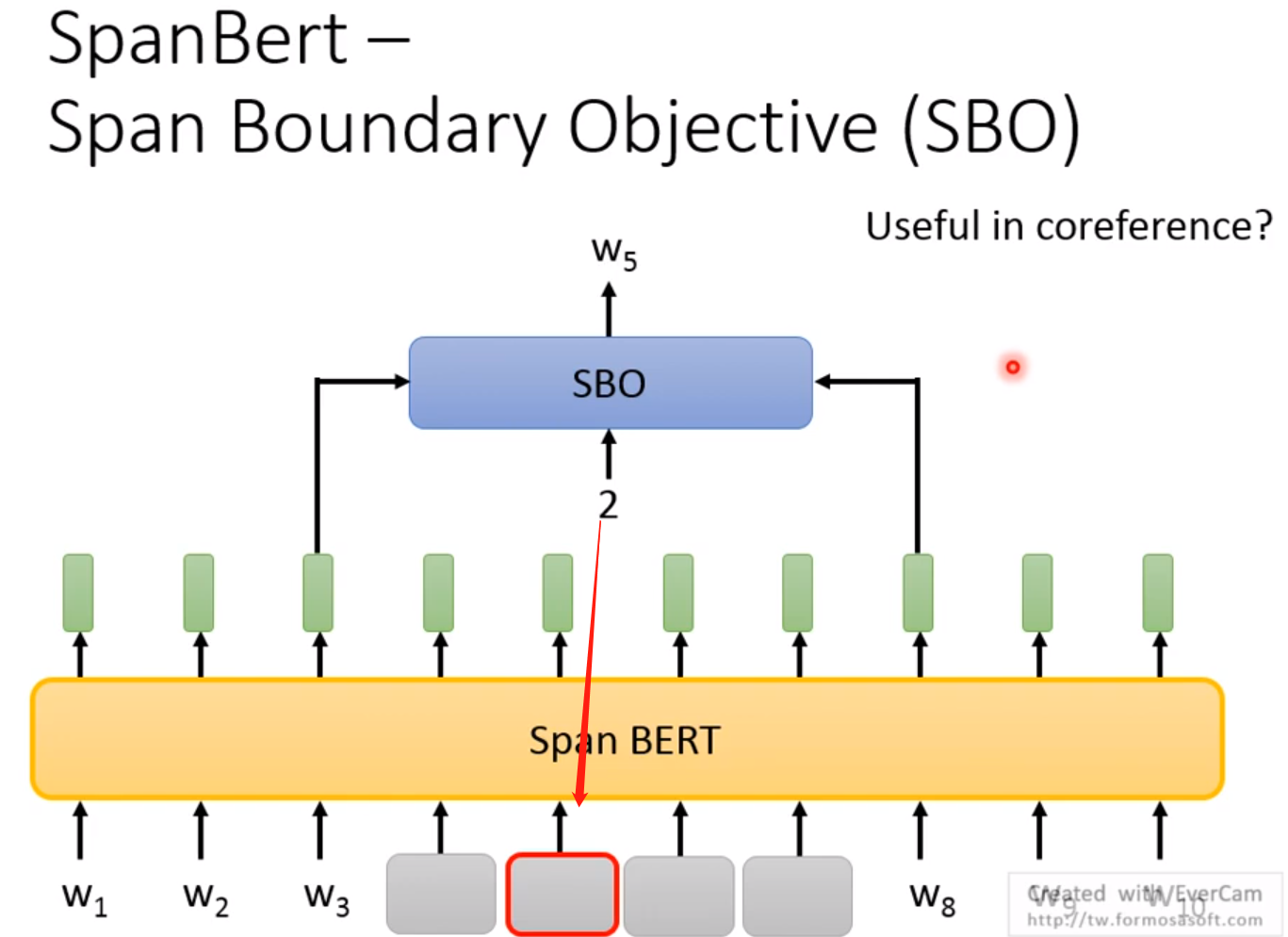
- SpanBert——Span Boundary Objective(SBO)
一种新的训练方法!
这里我们认为一个跨度两边的Word Embedding就可以包含这个跨度所有的信息! 为什么呢? 之后再说,在coreference中会更加详细的介绍!
我们通过两边的Word Embedding通过SBO来预测出一个数字,该数字代表了预测出了跨度中第几个单词!
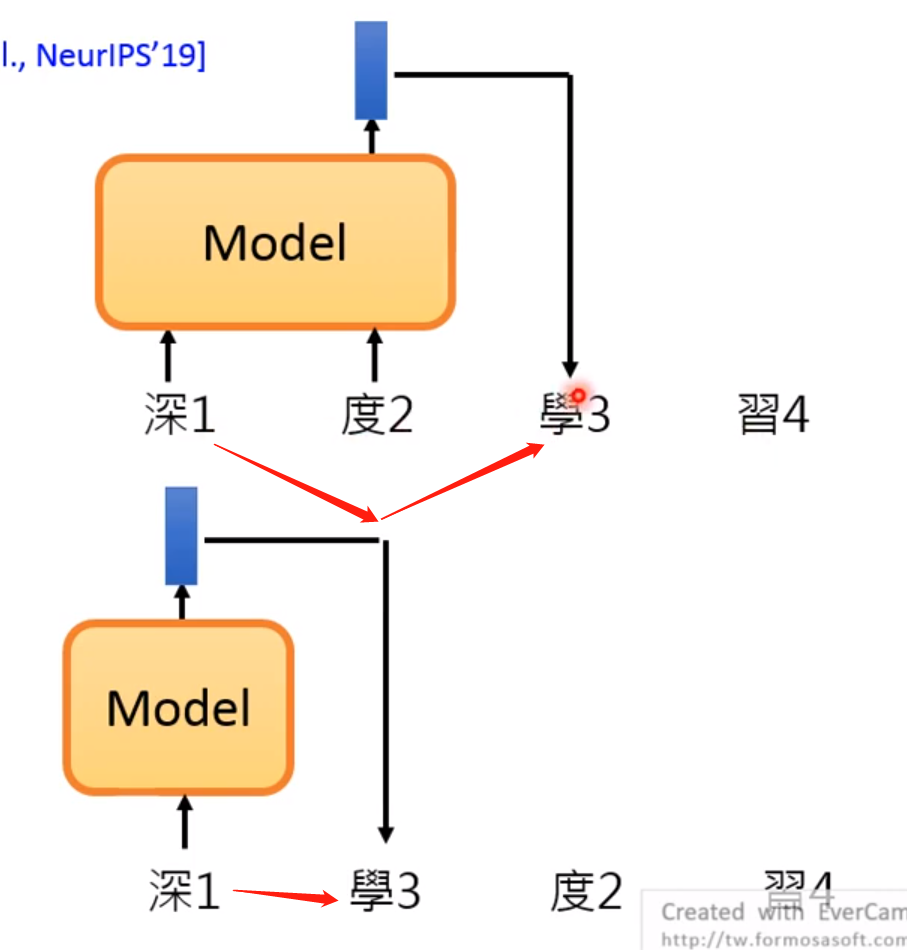
XLNet
Transformer-XL:
要解决的问题: 作者声称是发现了BERT的缺点,就是你只会预测顺序的,不会预测倒序的! 比如New York City! 你盖住York他可以预测,但是如果盖住New ,没把饭根据York来预测New!
怎么理解XLNet呢? 可以从两个方向来看:
第一个方向是language Model的方向:
predicts token的角度来看,你只能看看到left content!
而Transformer-XL中,打乱句子!
第二个方向是BERT的方向:
BERT中我们可以自定义窗口来对mask进行预测!
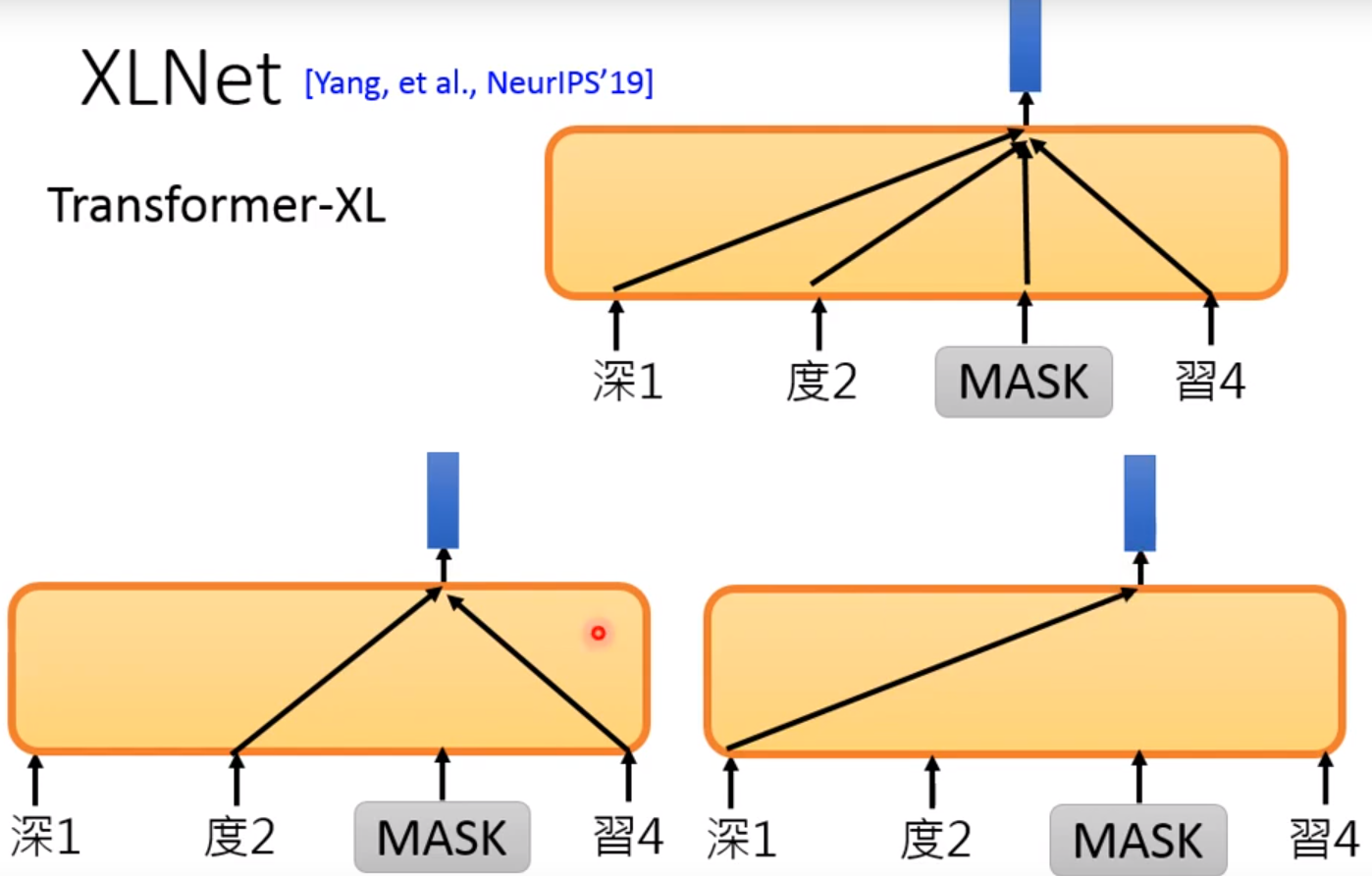
但是在XLNet中声明的是,不给Model看mask Token! 但是你还是要告诉model要预测哪一个位置的word! 后面的详细的自己看论文喽 !
BERT cannot talk?
给出部分的句子来预测下一个token!在LM-style中是可以的,但是BERT中我们训练的时候看的是左右,现在你给出左边,那么右边没有给,所以效果不会很好
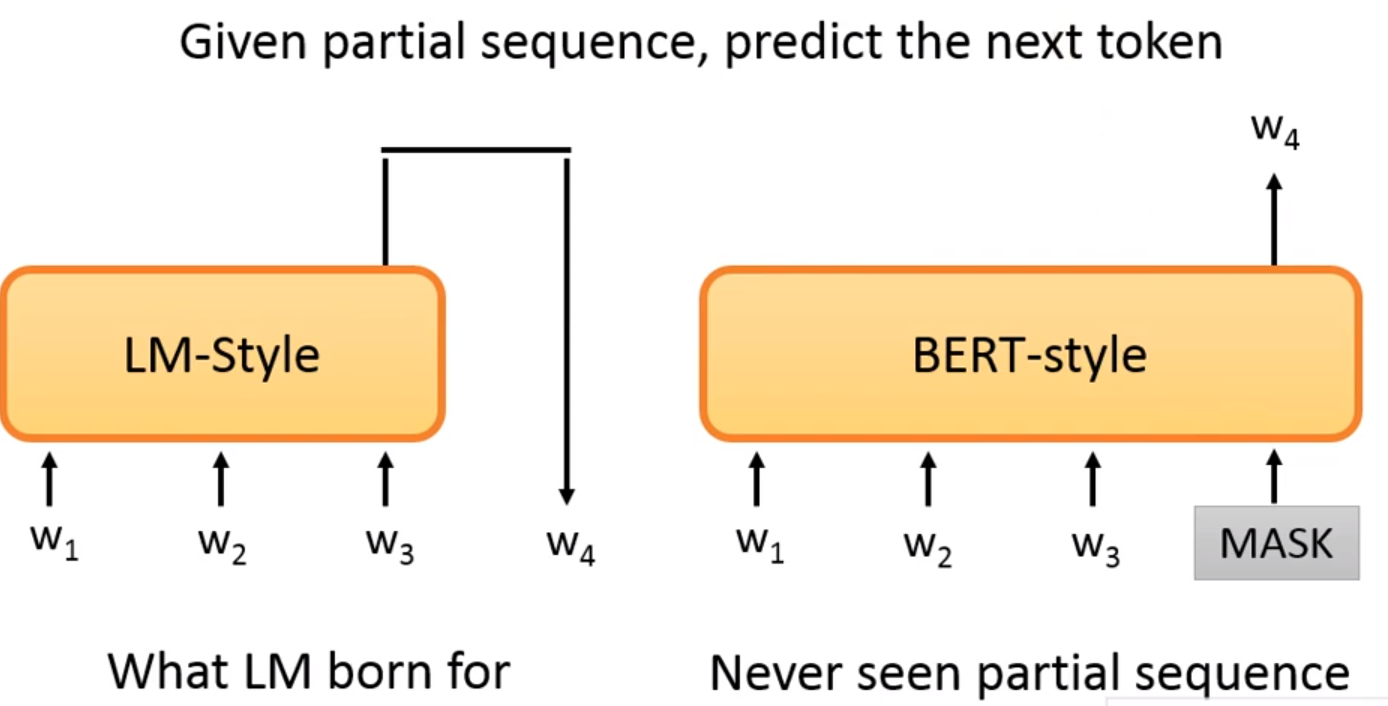
但是上面的讨论只是局限在autoregressive model! 我们在生成句子时,是从左至右的!
non-autoregressive,不用从左向右生成!
MASS/BART:
由于BERT泛化能力比较差,所以它可能不太适合作为seq2seq的pre-trian model! 所以如果是Seq2Seq任务,那么BERT可能只能充当encoder的任务! decoder的地方你可能没有pre-train到! 那么有没有办法去pre-trian一个seq2seq的模型呢? 是有的! 思想是cycle-loss,也就是经过decoder后和encoder有一样的输出! 但是也有一个问题,如果是这样的话模型是学习不到什么的,因为可能decoder只是复制一下输入! 所以需要将输入破坏! 有两种方法: MASS/BART
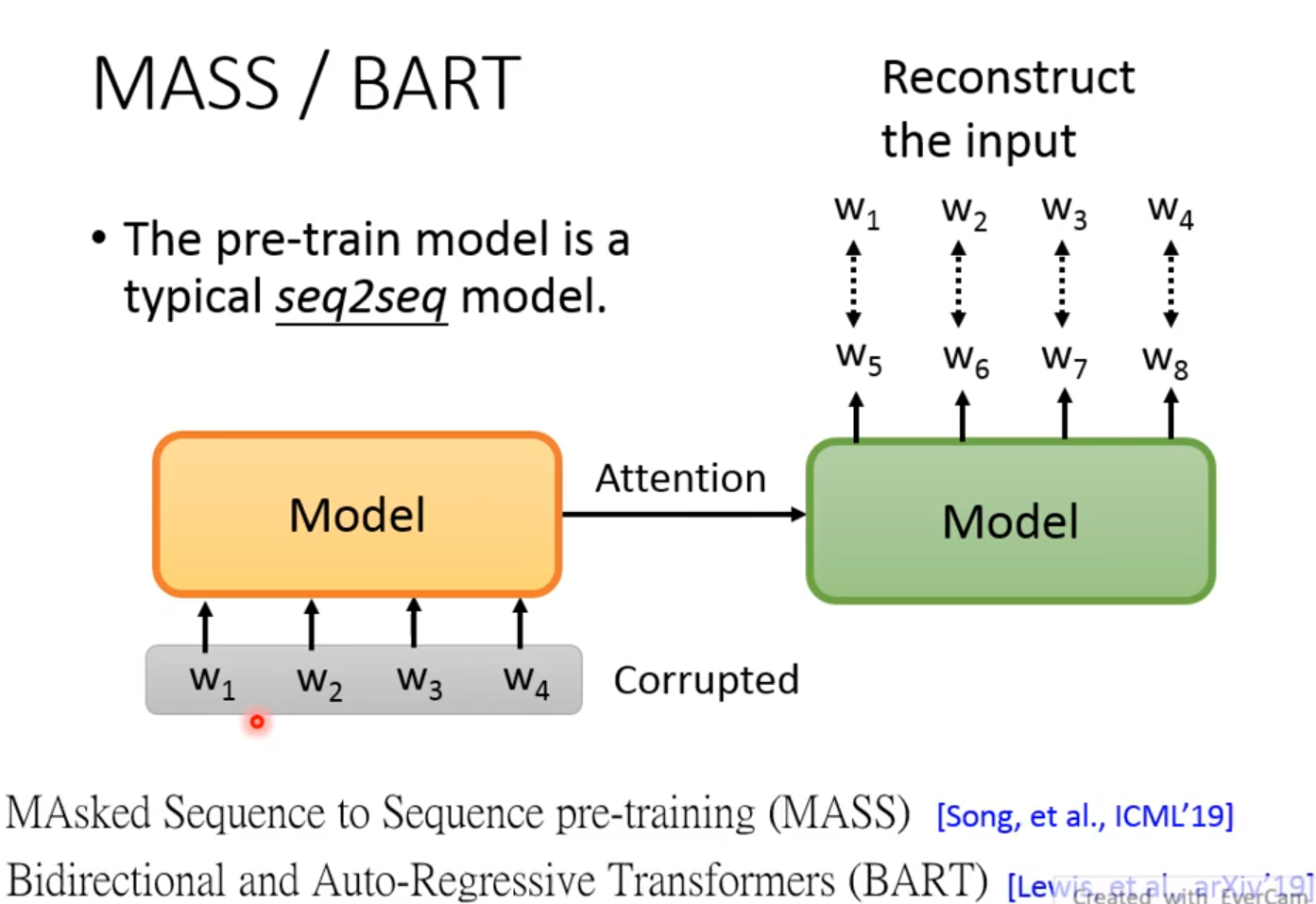
MASS:
和BERT的思想类似。
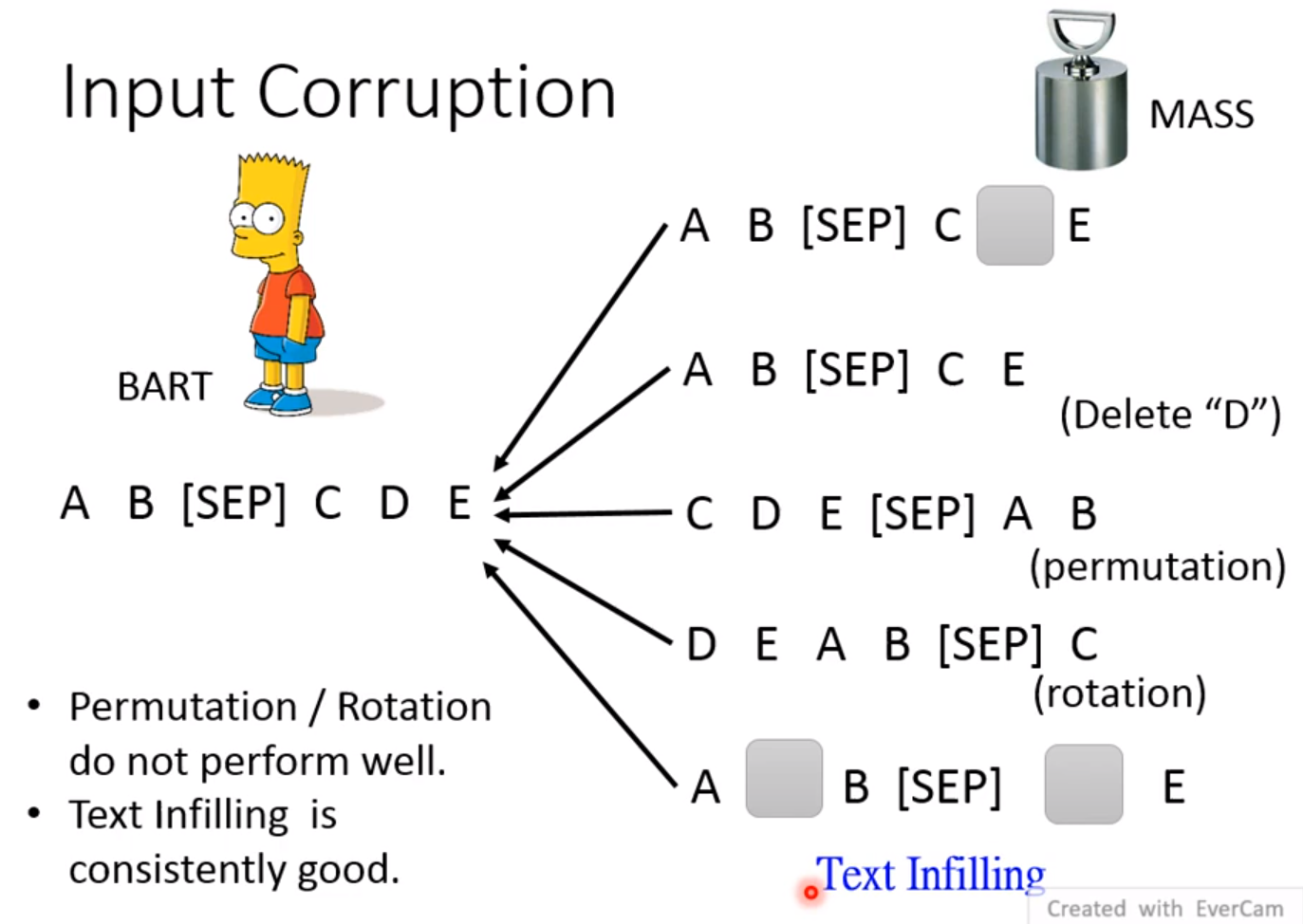
尝试了很多方法,最好的方法是Text Infilling!
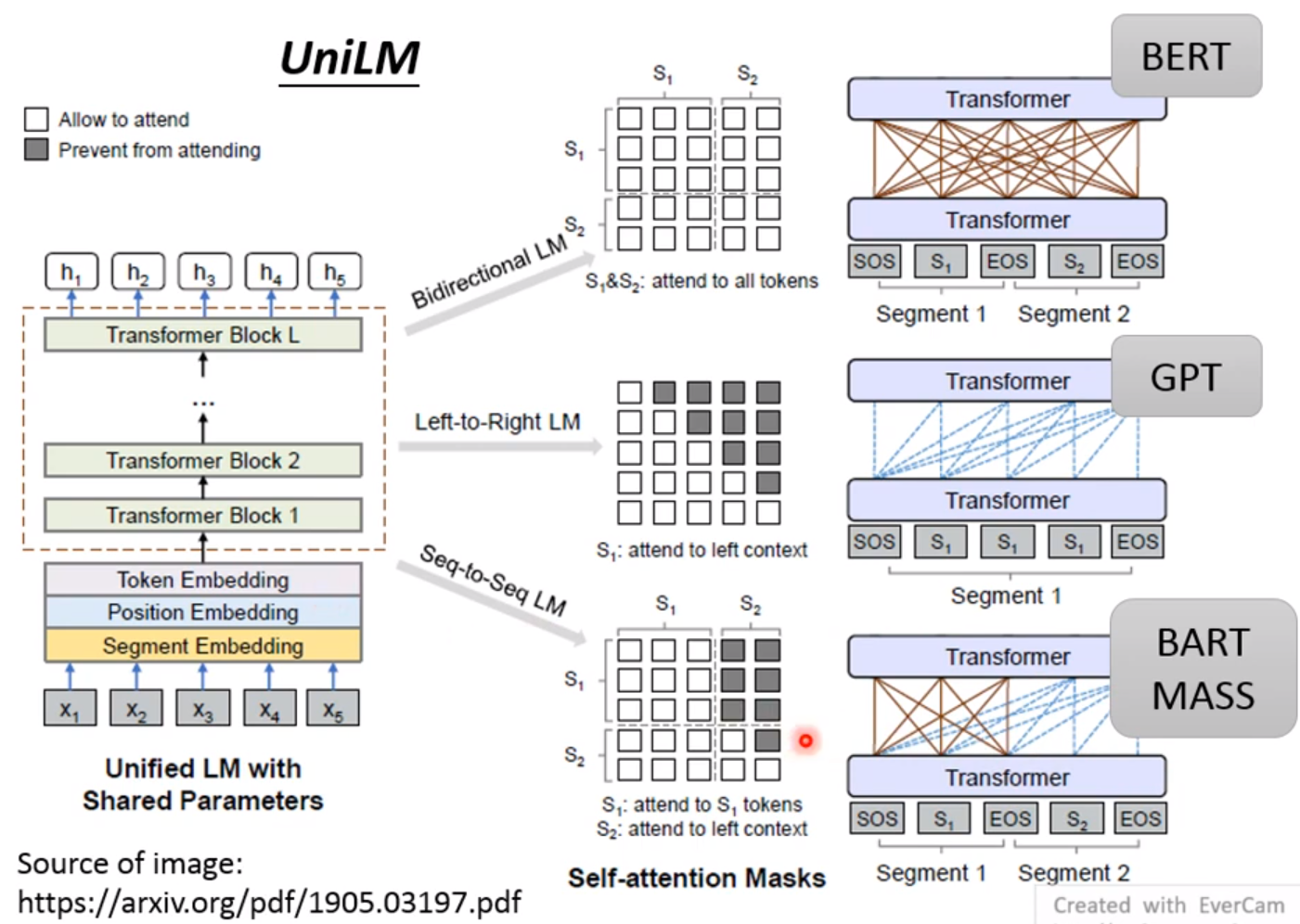
UniLM:
该模型可以充当各种模型! encoder、decoder或者是
Replace or Not?:
ELECTRA: Efficiently learning an Encoder that Classifies Token Replacements Accurately
前面的都是预测下一个Token,但是ELECTRA不回答预测问题,只回答binary的问题,ELECTRA怎么解决binary问题呢?
让一句话作为输入,我mask后观察该词是不是被mask了!
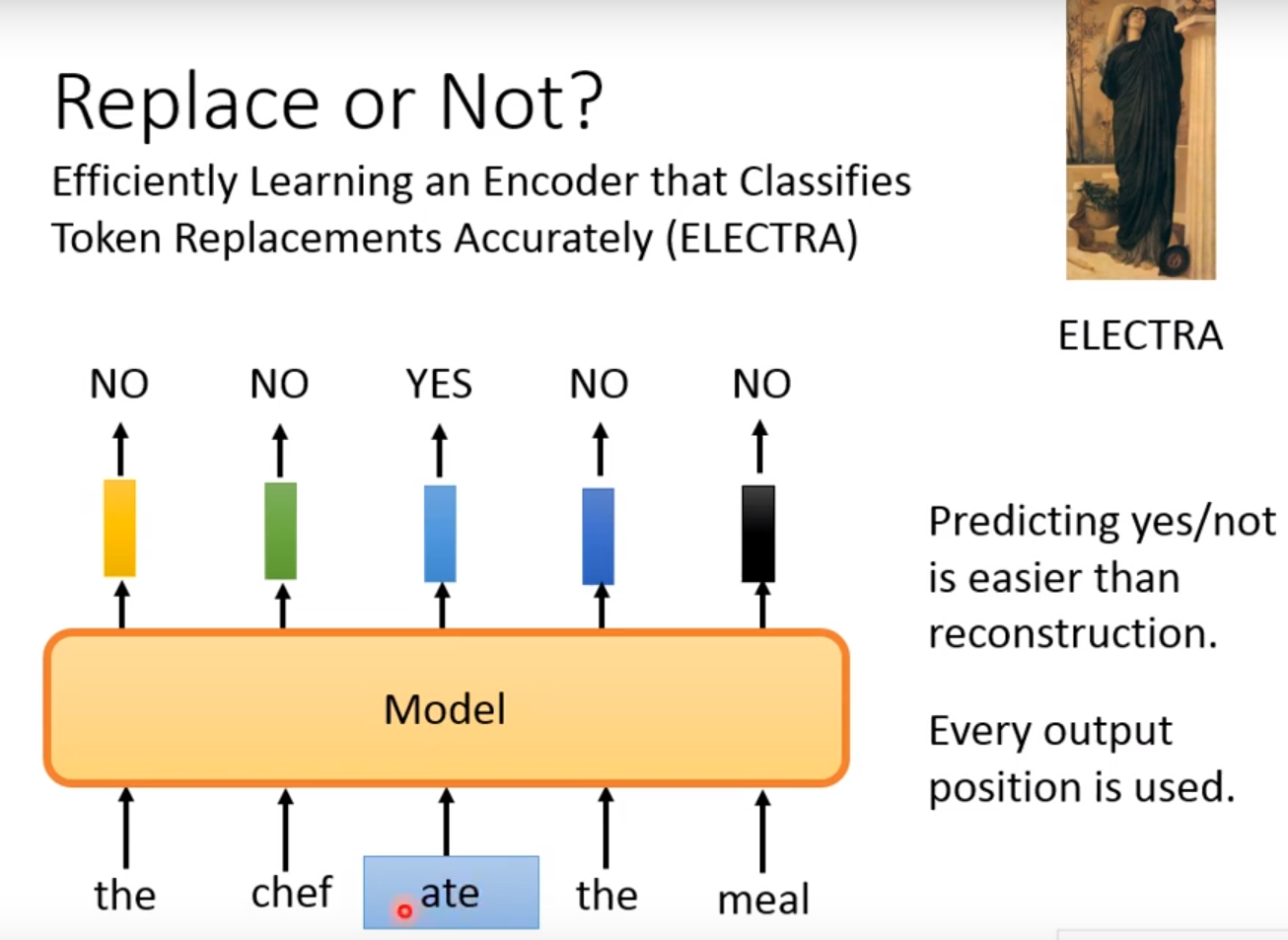
但是你如果给定一个很明显的单词替换,那么就很容易分析出来,所以需要增加难度! 所以我们就增加一个small BERT用来生成单词! 这个small BERT不用太大,要有缺陷! 不能是完美的!
Sentence Level:
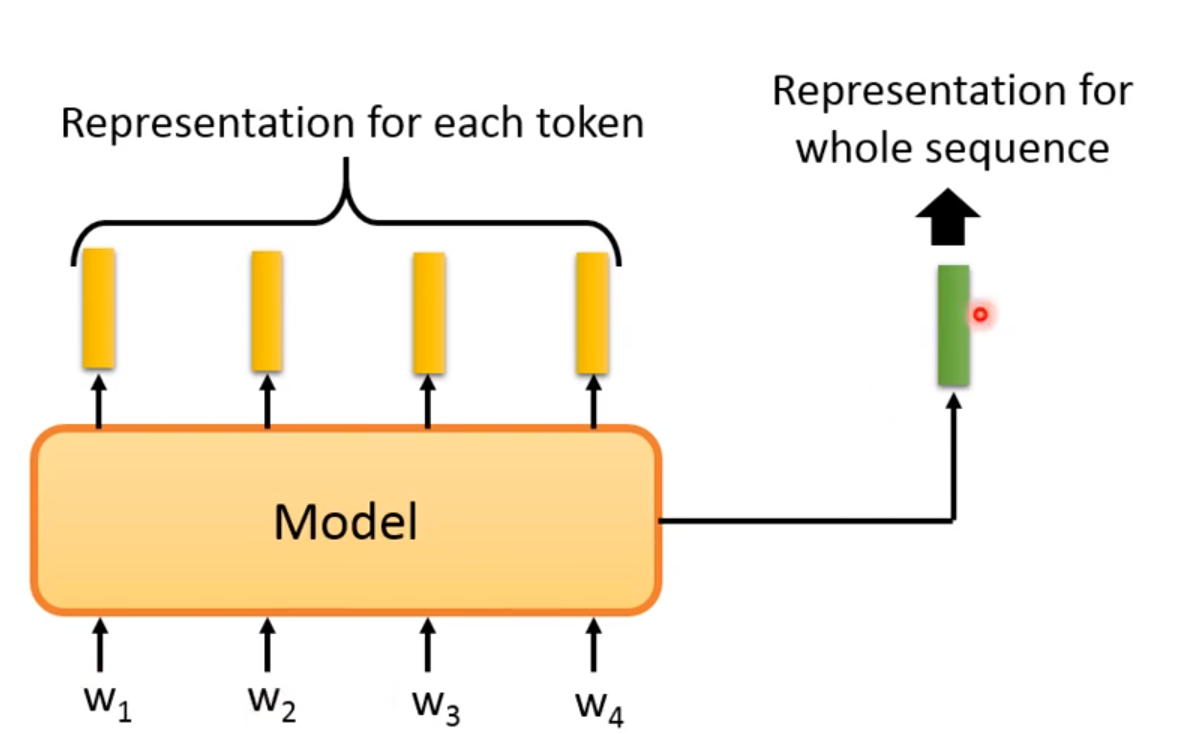
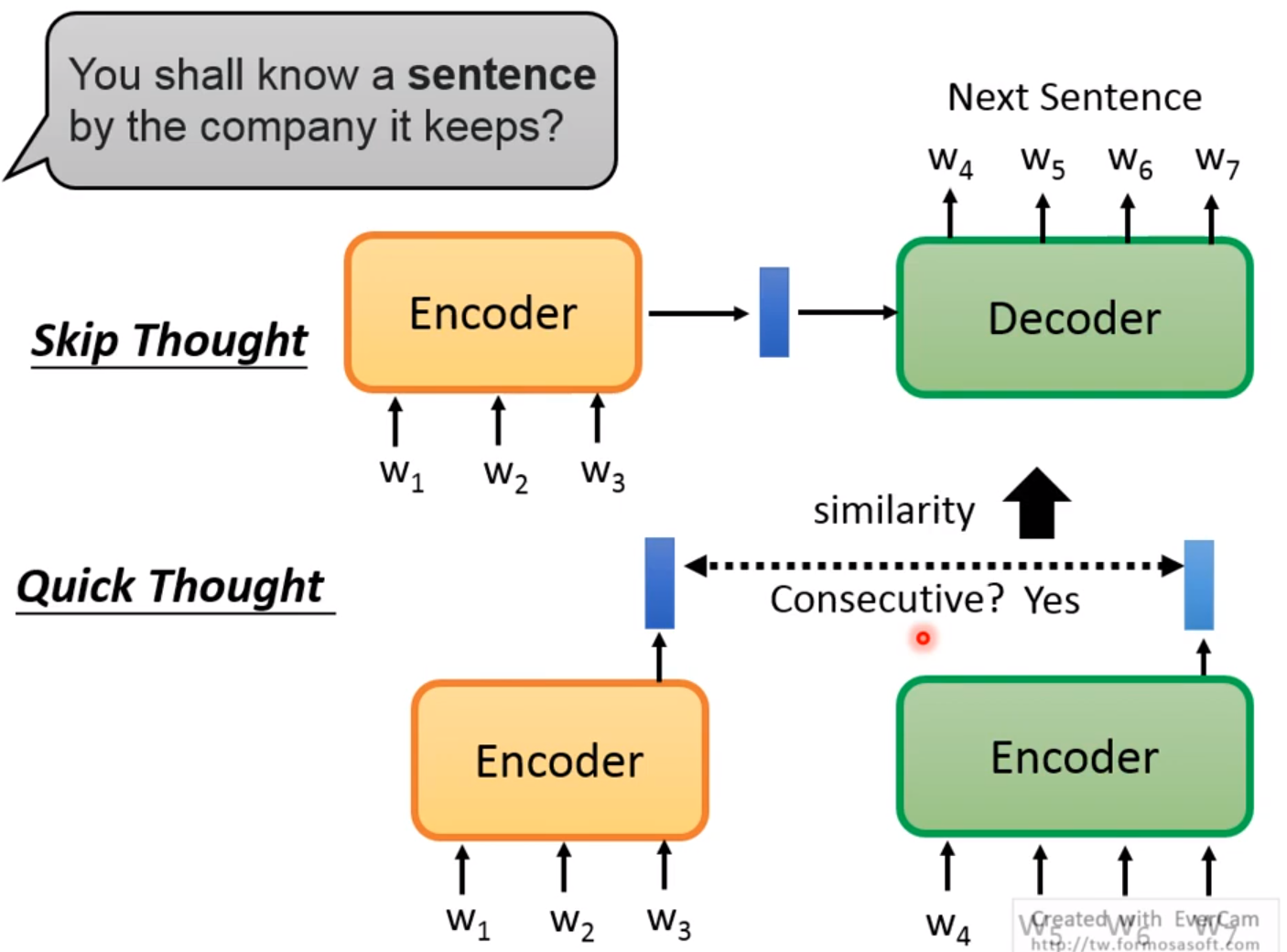
表示整个句子! 用来预测下一个句子是不是ok! skip Thought是将第一个句子输入Encoder,通过Decoder来预测下一个句子; 而Quick Thought则是利用了相似度的度量,如果两个句子相似度高,那么就会被预测!
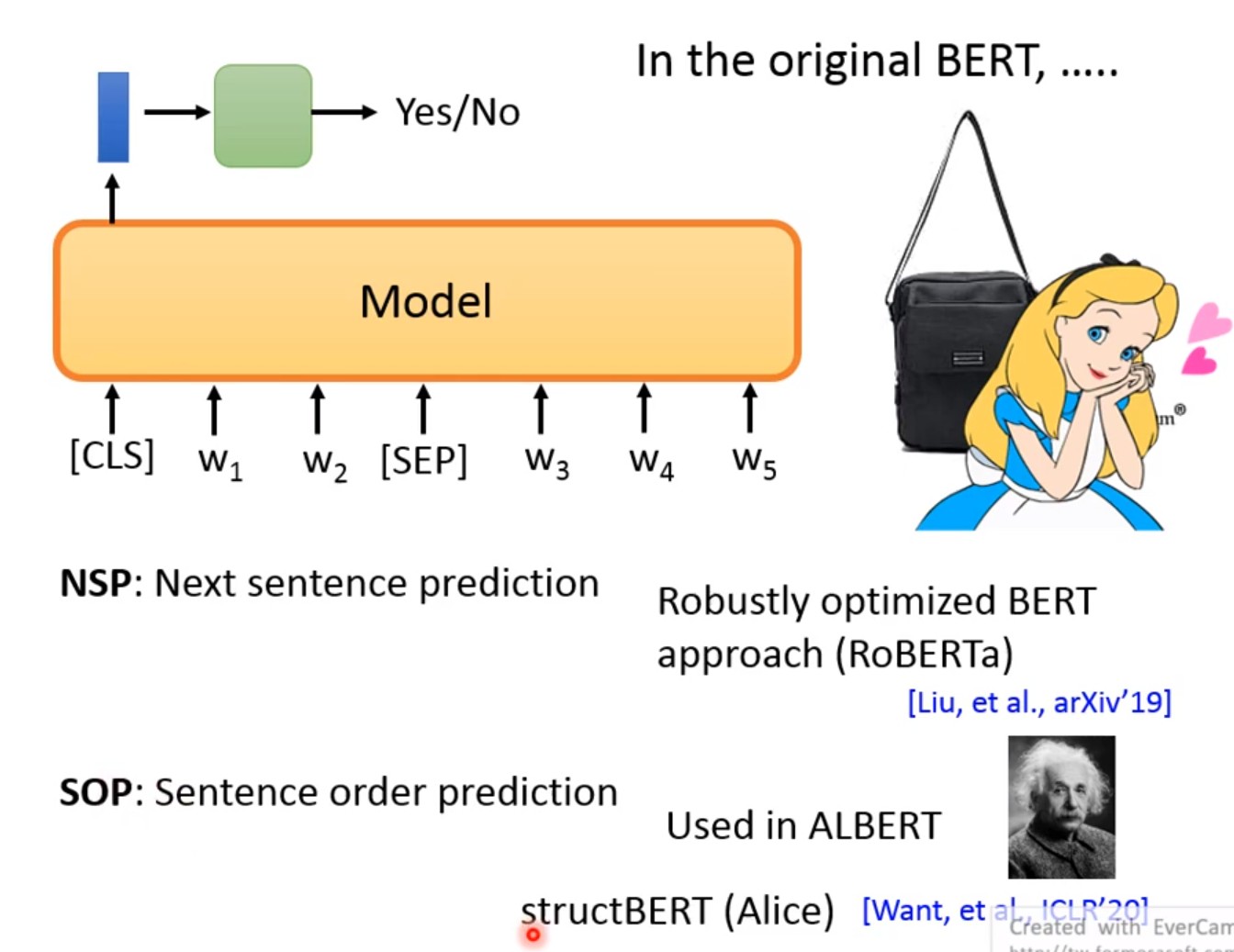
在普通BERT中,我们可以使用NSP来预测下一个句子。 两个句子中间有SEP分隔符,需要通读整个句子,提取整个句子的特征,才能做好两个句子的分类!
T5-Comparison:
总得有人做pre-train的,你得有硬件资源! 不是人人都可以做的!
T5和C4! 自己可以读一读
Knowledge
另一个ERNIE!
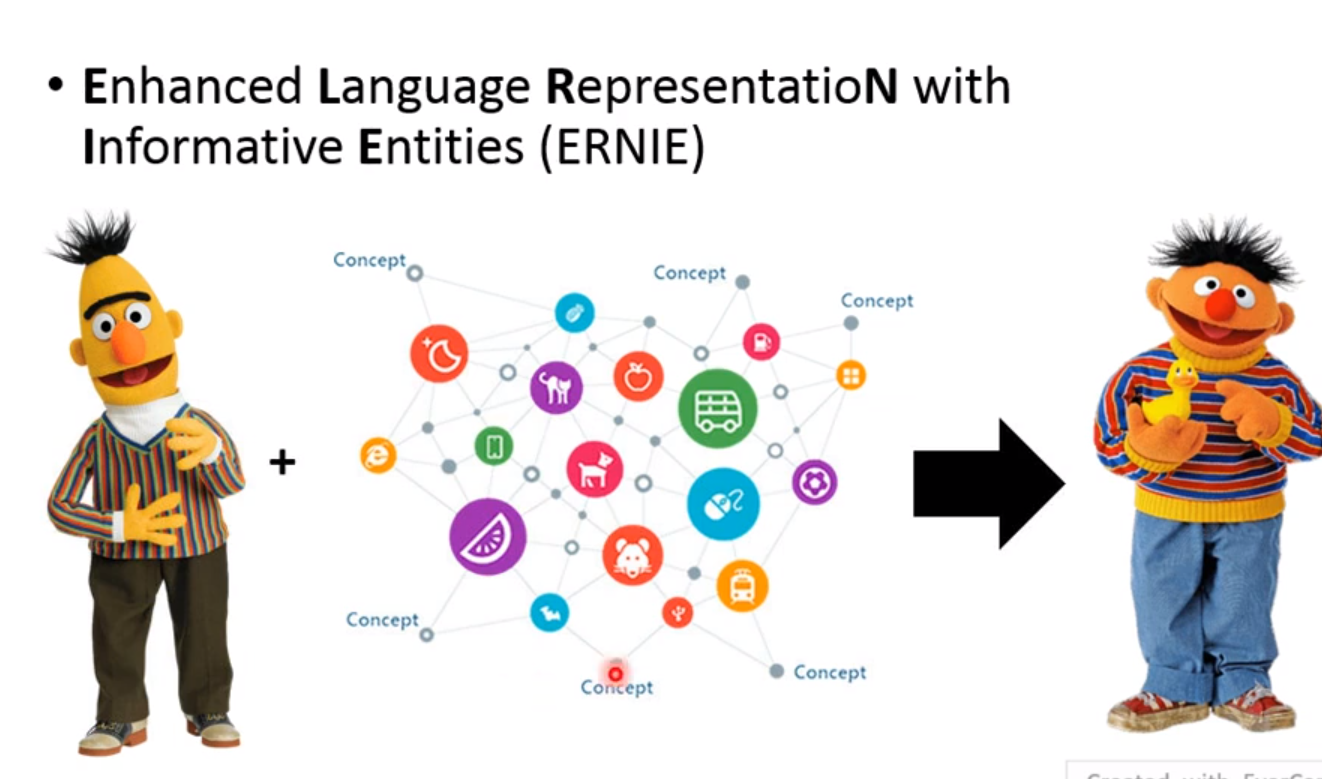
原来的都是文字的BERT! 还是有语音版的BERT!
Audio BERT

