
- 1git@github.com: Permission denied (publickey). fatal: Could not read from remote repository_git@172.16.17.8: permission denied (publickey). fa
- 2Virtex6 GTX设计总结:预加重、均衡、输出振幅的值
- 32024年Java最新Java算法基础 - 单链表详解(文末有配套视频)(2),2024Java面试题知识点总结_链表 java
- 4如何使用AIGC降重工具轻松提升论文原创性?
- 5集成学习((ensemble learning)
- 6VSCode 配置python虚拟环境(激活环境细节)_vscode python conda虚拟环境(1)_vscode运行python代码自动进入conda创建的虚拟环境
- 7java数据存储常用数据结构的实现:栈(先进后出),队(先进先出),字典(键值对),集合(去重)_java list只存10条数据先进先出
- 801uni-app 基础教程 环境配置【uniapp 专题 1】_uniapp开发环境配置
- 9实现知识库问答机器人 langchain + LLM + Embeddings (比Langchain-Chatchat更智能)_langchain 知识库 多轮对话
- 10详细分析Mysql触发器的基本使用(图文解析)_数据库触发器
【转载】Stable Diffusion的Lora使用和训练(Stable Diffusion研习系列05)_stable diffusion中lora怎么创建文件夹路径
赞
踩
转载链接:https://www.bilibili.com/read/cv23673406/
LoRa的概念
在我们使用LoRa之前,我们需要先介绍下LoRa的概念和作用。
LoRa是基于大模型基础上,对产生的画面的一种微调手段的小模型。如果把基础模型比喻为游戏引擎,那么LoRa就是相当于游戏mod的存在。他是基于基础模型上对画面更具有可控性的一种微调方式,如果你用的是二次元基模,那么通过真人LoRa也不能出现真人画面。他只是一个辅助、做些美化,不可能对画面画风进行大幅度的修改。
LoRa有很多种类型,有场景LoRa、画风LoRa、姿势LoRa、服装LoRa、汽车LoRa、人物LoRa、甚至有专门某个部位的如眼睛的LoRa、手部的LoRa以及调光影的影调LoRa。
LoRa这个名称可以理解为一个微调模型的统称,我们一般说的LoRa模型,其实包括:LyCORIS、LoHa、LoRa、LoCon、LoKR 和 DyLoRA 等,他们的区别在于因微调技术的分类和其算法不同。
目前用的较多的还是,传统的LoRa和LyCORIS两种,而LoHa模型又是基于LyCORIS上的技术。LyCORIS的表现比传统的Lora会好些,当然他的模型大小也相对大点,在344M左右,传统的LoRa则一般在144M或者更小。
LoRa的用处
类比大语言模型基础上,再训练属于自己领域特性的微调语言模型的道理一样,训练LoRa模型,是基于大模型基础上的微调模型。
最常用的是通过训练比如特定人物或衣服的 LoRA模型后,就可以在 Prompt 中用一个触发词调用这微调模型,从而获得特定人物或衣服的图片。
有如下的作用与优点:
节省训练时间:
可以让我们用不多的时间里,对特定的目标进行快速地通过模型训练让AI学习到后并在之后的使用中可以精准调用。而不用投入过多的时间精力去训练大模型。
提高准确性:
使用LoRa模型微调,可以在保持低层模型的特征提取能力的同时,针对具体任务进行优化,从而提高模型在特定任务上的准确性。
加快创作速度:
LoRa 模型可以快速生成想法的效果,这些结果可以为创作者提供新的创作灵感,开拓新的设计思路和方向,从而更好地实现自己的设计目标。
可迁移性:
可迁移性意味着可以在不同任务之间共享底层模型,从而减少重复训练,提高工作效率,使其能够更快速地从一个任务转移到另一个任务。
===========================
LoRa训练的6个环节

我们这里介绍的是传统的LoRa模型的训练方式和参数,你们可能会看到不少不同的参数和训练方式的内容,那是或许是不同的细分模型类型的不同,微调技术的分类和其算法不同,但训练步骤和环节都基本差不多。
在此我们先将整个训练过程做个梳理和讲解,实操阶段可以学习完这篇后,再结合我们推荐的视频内容,你会更容易上手。
01.训练环境搭建
我们可以到B站“秋葉aaaki”的视频内容中获取链接,或者到他在GitHub上的链接下载安装训练所需的脚本。当然,这之前你需要已装有Python,这在使用Stable Diffusion前已经搭建了的环境。
训练包LoRa-scripts下载:https://pan.quark.cn/s/d81b8754a484
GitHub地址:https://github.com/Akegarasu/LoRa-scripts
将训练包下载后解压缩到自己指定的路径下即可。我是放在D盘的根目录下,方便后面训练调用和训练集存放不用挖太深。
02.训练素材准备
训练集素材的搜集很重要!很重要!很重要~!
对要用于训练的图片素材:例如在角色训练素材中,需要清晰的、多角度的、正脸的、侧脸的、最好是背景干净的、各种表情的、摆头的。就是需要各种角度(不要有俯视的,尽量都是平视图避免比例失调)、景别、姿势、光照。脸部不要有被遮挡的图片。这样增加训练集的多样性,提高模型的泛化性。



如果是角色训练集控制在20-50张图左右,太多会导致过拟合。
如果是训练其他风格,有说法是图片越多效果就越好,相应的训练时长也会增加,建议在50~80张。
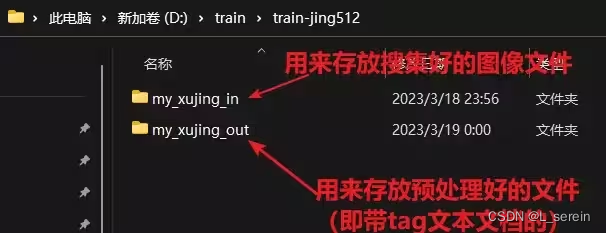
影响训练出的LoRa模型的好坏,训练集是最最最重要的~!
如果是角色训练,也建议将需要训练的人物及相关的特征装饰都抠出来,背景尽量简单或直接是纯色背景,建议白底或黑底,但不要是透明底。
*素材可以少,但是质量一定要高。
*角色背景最好是白底网站上面可以选择换背景颜色
搜集好训练用的图像后,需要进行大小的规范处理,需要是64的倍数。一般都处理为512*512,也可以是768*768,不建议超过1024,尺寸越大则越吃显存。
推荐网站可以进行批量的图像尺寸处理:https://www.birme.net/
03.图像预处理
将裁切规范后的训练集图像文件夹,置入Stable Diffusion中的“训练”标签页中。
所谓的图像预处理,就是将批量的训练集中图像进行批量打标签,批量给训练集中的每一张图像生成一个对应的tag文本文件。
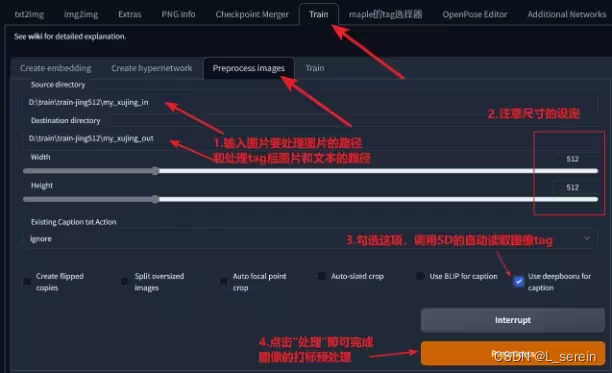
04.打标签
这个环节,将对tag文本文件的描述语进行处理,删除关于描述人物特征的tag,比如你要保留其黑色头发作为训练LoRa的自带特征,而不会在出图时头发被改为金色,那么这里就要将“black_hair”的描述tag删除掉。那么在训练时,AI自动将黑色头发与该LoRa绑定,之后的出图中就不会出现其他颜色的头发。还比如微笑的tag,smile,就需要保留,作为这张图像的面部特征需要告知AI。
因此在检查tag这个环节,需要我们手动将AI识别不到,但又需要将其排出在我们LoRa特征之外的tag补齐。这就是为什么我们在挑选训练集图像的时候就需要讲究越简单越好。如果你的人物训练集图片中只有要的人物和白色背景,那么tag文档中只需要留下触发词和white backgroud即可。
注意,这个触发词一定要设置,可以是特别的自己好记的英文字母的代名词。
对于模糊的图像tag中可以添加动态模糊的描述词,对于面部特写的图像可以加特写的tag,让AI更好地学习。
这里批量处理tag也有小工具软件辅助,我们推荐的是BooruDatasetTagManager,一个单独的小工具软件。可以很方便对导入的文本文件进行统一的tag删减和增加。

将处理好的图片和文本文档的文件夹拷贝到训练用的路径下,并设定好文件夹下划线前的循环训练次数值(Num)。这个Num意思是对训练集的图像学习的循环次数。

批量处理Tag小工具下载链接:
链接:https://pan.baidu.com/s/1neI2qU8YcsiMLNj7qiPnrA?pwd=1111
05.开始训练
这里注意,对每次训练的数据最好自己做个文档记录,记录主要的参数设置,作为之后测试模型效果后进行训练参数调整的参考依据(我自己记录的主要参数有:训练集照片数量、Num值、epoch、Dim值、Alpha值、batch size,学习率和采样器都还是默认的,之后深入学习后可以尝试)。
训练时长,总的来说,不宜也不需训练过长时间。尽可能把训练时长控制在半小时到一小时内,时间过长容易导致过拟合,通过调整等参数控制训练时长。即便是batch size值为1,也是如此,这就意味着你的训练总步数其实是不需要过多。(当然,时长也跟显卡的功力也有一定关系,但时长不至于偏差得几倍去。)
都准备好训练集后,就是对训练脚本(目录LoRa-scripts下,编辑训练脚本“train.ps1”)进行修改,调整训练参数后,就可以执行此脚本文件开始训练。


Clip用1似乎效果不佳,真是玄学,还是用回2吧,不管是真人还是二次元。
训练的结果好坏,是否过拟合或欠拟合,就跟我们在脚本中设定的参数也是有关的。
训练用的底模,一般用chilloutmix_Ni.safetensors(偏人物)或官方的SD1-5的版本就好,这里最好是将模型先拷贝到训练程序的相应目录下D:\LoRa-scripts\sd-models,这样就不需要将路径最前面的一个“.”改为“…”。
接着设定训练集的路径,将我们保存训练集图像文件的路径复制黏贴入即可。注意如果你没有将训练集的文件夹拷贝到程序的目录下D:\LoRa-scripts\,那么就需要在路径最前面将[dir=“.],改为[dir=”…],就是要加多一个小点,训练集的文件夹不在程序的目录下调用。
dim值和alpha值设定,训练人物一般都设32,64也是可以;训练风格可以用到128。
分辨率resolution的设定,根据训练集的图片文件的像素来设定即可。
max_train_epochs表示这个训练跑多少批次(或成为跑多少圈);
save_every_n_epochs表示跑多少圈保存一次模型。
Batch Size表示训练这些图片时,每训练几次算1步。
总训练数=训练集的图片数量*Num值*epoch值
训练步数=训练集的图片数量*Num值*epoch值/Batch Size值。
举例参数是:34张*10Num*20epoch=6800次。
06.模型测试
炼出的多个模型,如何知晓并筛选出最好用的那个,就需要我们用脚本中的xyz图表的方式来跑图测试。
跑图测试调用LoRa的方式可以是用Additional Networks中的模型类型和权重来做xy轴,也可以是用提示词搜索替换的方式来改权重(但这好像只能是对不同权重的比对而无法比对不同的LoRa来比对)。
先将Additional Networks开启,简单设置下就好。

再到脚本栏选用xyz图表,进行各项对比参数的设置。


最后生成的阵列图中,就可以很直观地看出哪个模型,在某种权重值情况下表现得最好。至于采样模式,我个人比较偏好用DPM++ 2M Karras,当然也可以用xyz图表跑跑看其他几种不同采样方法下的模型表现情况,不建议选太多种跑图。
===========================
LoRa训视频讲解推荐
对于整个训练过程的视频方式的了解和学习,可以参看这2条视频内容,
**一条是B站博主“秋葉aaaki”**的内容的讲解:
【AI绘画】最佳人物模型训练!保姆式LoRa模型训练教程 一键包发布】 https://www.bilibili.com/video/BV1fs4y1x7p2/?share_source=copy_web&;vd_source=96188266665c90578cc52f2450fb0552
**一条是B站博主“Easy硕游戏”**的讲解,特别是针对LoRa训练很重要的2个环节,训练集搜集和打标签不是很明白的同学可以多看几遍。
【真人LORA训练全攻略 !手把手教你 这还不简单?真人LORA全面教程 stablediffusion教程 SD教程 零基础入门教程 AI绘画】
https://www.bilibili.com/video/BV1Hs4y1D7QJ/?share_source=copy_web&;vd_source=96188266665c90578cc52f2450fb0552
===========================
深入学习推荐:
关于LoRa的相关名词概念还有:过拟合&欠拟合、泛化性、正则化、分层控制、分类图集、
大家也都可以根据这些关键词在B站搜索后,做进一步的观看学习。
过拟合和欠拟****合,我们可以简单地理解为训练不够和训练过头了。
**泛化性,**我们可以简单理解为适用性。
这两组概念,表现不好,都是不好的现象。我们在模型训练中需要不断对训练集、正则化、训练步数等参数进行调整(这也是为什么我们在初期训练LoRa时需要做好每次训练参数的记录的原因)。
过拟合可以尝试减少训练集的素材量,欠拟合就增加训练集的素材量。
最终目的是让模型最终得到我们想要的效果。
正则化是解决过拟合和欠拟合的情况,并提高泛化性的手段。
相当于给模型加一些规则和约束,限制要优化的参数有效防止过拟合,同时也可以让模型更好适应不同情况的表现,提高泛化性。
【优化器和学习率】
对于优化器的了解和学习,可以看看这条内容的讲解:
【如何训练一个非常像的真人LoRa模型(深度探讨)】
https://www.bilibili.com/video/BV1Ba4y1M7LD/?share_source=copy_web&;vd_source=96188266665c90578cc52f2450fb0552
【分层控制】
对于分层控制的了解和学习,可以参看这条内容的讲解:
【AI绘画】LoRa进阶教学!分层控制篇】
https://www.bilibili.com/video/BV1CV4y1Q77p/?share_source=copy_web&;vd_source=96188266665c90578cc52f2450fb0552
【LoRa的提取/合并/降维/融合】
对于LoRa模型的提取、合并、降维、融入基模的了解和学习,可以看这条内容的讲解:
这是借助一款叫SuperMerger插件,可以解决对LoRa有其他使用和生成的便捷方式。
【AI绘画进阶教程】SuperMerger插件详解 提取LoRa模型✓ 合并LoRa模型✓ LoRa模型降维✓LoRa模型融入大模型✓】
https://www.bilibili.com/video/BV1pV4y1Q7Bi/?share_source=copy_web&;vd_source=96188266665c90578cc52f2450fb0552
【用Konya_SS训练LoRa】
对于LoRa模型训练的其他方式,如Konya_SS,可以参看这条内容的讲解:
【2023最新版】LORA安装和训练指南 | 高质量模特养成 | 教你打造自己专属的迷人模特】
https://www.bilibili.com/video/BV1EM411g7He/?share_source=copy_web&;vd_source=96188266665c90578cc52f2450fb0552
【用Dreambooth训练LoRa】
对于LoRa模型训练的方式也有用Dreambooth插件训练,可以参看这条内容的讲解:
【AI绘画进阶教程】Stable Diffusion-LoRA模型训练-安裝及基础概念教学 台湾大神手把手教你调教】
https://www.bilibili.com/video/BV1W54y1M7SV/?share_source=copy_web&;vd_source=96188266665c90578cc52f2450fb0552
常用到的基础模型和插件(持续更新中)以及本期的插图文件也做了一份在云盘
链接:https://pan.baidu.com/s/1c9utQmWlGcRqLTr_kftTyA?pwd=1111
本系列的下一期我们将跟大家聊聊让StableDiffusion能有如此强大能力的插件ControlNet。

