
- 1高并发抢票时,防止机器人刷票的令牌大闸,减轻服务器的压力(防刷+限流)
- 2IDEA提交代码到GitHub_idea git commit and push
- 3图文讲解:iOS App提交流程_ios developer 创建app sku 是什么
- 4干货 | 关于SwiftUI,看这一篇就够了
- 5【计算机网络】[第三章:数据链路层][自用](需要重新排版)
- 6STM32编写ADC功能,实现单路测量电压值(OLED显示)_stm32战舰v3 adc显示到oled
- 7深度学习1:神经网络原理与算法详解_深度神经网络算法原理
- 8signature=37447d22ba390eb81bb1cd3414a3fcfb,generator-nodex
- 9kali linux 安装教程(最新)_kali虚拟机安装步骤
- 10sharding-jdbc分片策略
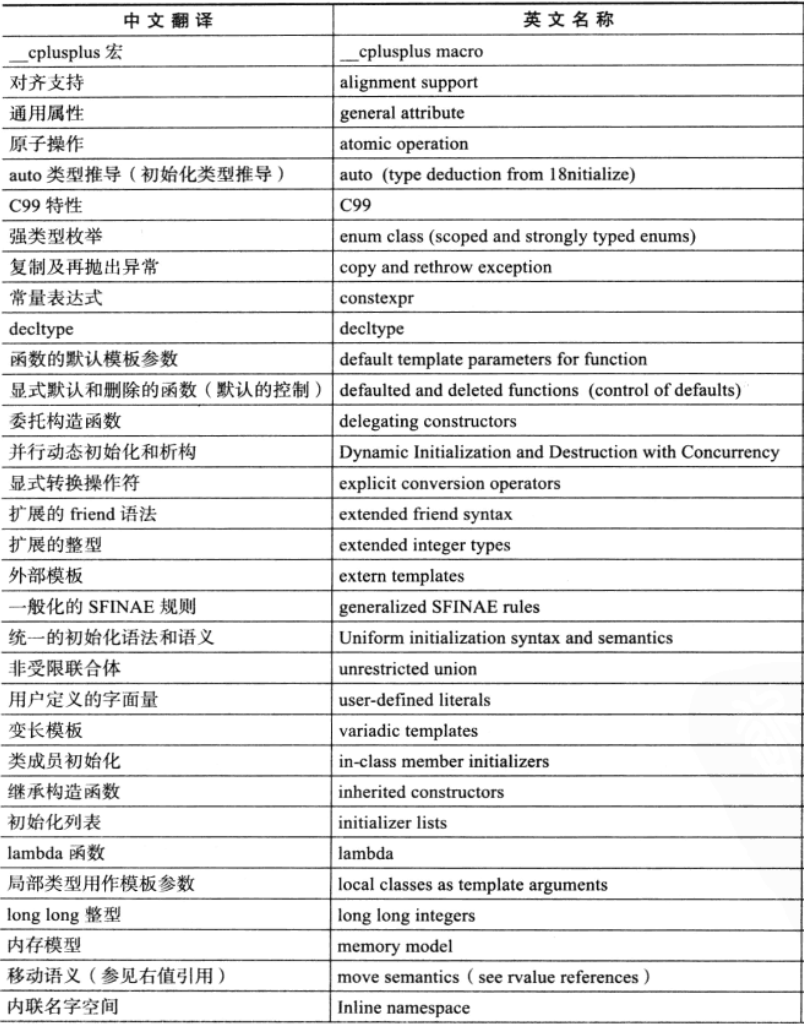
c++11新特性
赞
踩
1.c++11新特性
C++11的简要介绍
(1)出于保证稳定性与兼容性增加了不少新特性,如long long整数类型、静态断言、外部模板等等 ;
(2)具有广泛应用性、能与其他已有的或者新增的特性结合起来使用的、具有普适性的一些新特性,如继承构造函数,委派构造函数,列表初始化等等;
(3)对原有一些语言特性的改进,如auto类型推导、追踪返回类型、基于范围的for循环,等等;
(4)在安全方面所做的改进,如枚举类型安全和指针安全等方面的内容;
(5)为了进一步提升和挖掘C++程序性能和让C++能更好地适应各种新硬件,如多核,多线程,并行编程等等;
(6)颠覆C++一贯设计思想的新特性,如lambda表达式等;
(7)C++11为了解决C++编程中各种典型实际问题而做出的有效改进,如对Unicode的深入支持等。
1.auto类型推导
在早期版本中,关键字auto主要是用于声明具有自动存储期的局部变量。然而,它并没有被经常使用。原因是:除了static类型以外,其他变量(以“数据类型+变量名”的方式定义)都默认为具有自动存储期,所以auto关键字可有可无。
所以,在C++11的版本中,删除了auto原本的功能,并进行了重新定义了。即C++11中的auto具有类型推导的功能。在讲解auto之前,我们先来了解什么是静态类型,什么是动态类型。
(1)静态类型,动态类型,类型推导
通俗的来讲,所谓的静态类型就是在使用变量前需要先定义变量的数据类型,而动态类型无需定义。
严格的来讲,静态类型是在编译时进行类型检查,而动态类型是在运行时进行类型检查。
如python:a = "helloworld"; // 动态类型
而C++:std::string a = "helloworld"; // 静态类型
如今c++11中重新定义了auto的功能,这便使得静态类型也能够实现类似于动态类型的类型推导功能,十分有趣~
下面是auto的基本用法:
- double func();
- auto a = 1; // int, 尽管1时const int类型,但是auto会自动去const
- auto b = func(); // double
- auto c; // wrong, auto需要初始化的值进行类型推导,有点类似于引用
注意: 其实auto就相当于一个类型声明时的占位符,而不是一种“类型”的声明,在编译时期编译器会将auto替代成变量的实际类型。
(2) auto的优势
I. 拥有初始化表达式的复杂类型变量声明时的简化代码。
也就是说,auto能够节省代码量,使代码更加简洁, 增强可读性。
- std::vector<std::string> array;
- std::vector<std::string>::iterator it = array.begin();
- // auto
- auto it = array.begin();
auto在STL中应用非常广泛,如果在代码中需要多次使用迭代器,用auto便大大减少了代码量,使得代码更加简洁,增强了可读性。
II.免除程序员在一些类型声明时的麻烦,或者避免一些在类型声明时的错误。
- class PI {
- public:
- double operator *(float v) {
- return (double)val*v;
- }
- const float val = 3.1415927f;
- };
- int main(void) {
- float radius = 5.23f;
- PI pi;
- auto circumference = 2*( pi*radius);
- return 0;
- }
设计PI类的作者将PI的*运算符进行了重载,使两个float类型的数相乘返回double类型。这样做的原因便是避免数据上溢以及精度降低。假如用户将circumference定义为float类,就白白浪费了PI类作者的一番好意,用auto便不会出现这样的问题。
但是auto并不能解决所有的精度问题,如:
- unsigned int a = 4294967295; // unsigned int 能够存储的最大数据
- unsigned int b = 1;
- auto c = a+b;
- cout << c << endl; // 输出c为0
a+b显然超出了unsigned int 能够存储的数据范围,但是auto不能自动将其匹配为能存储这一数据而不造成溢出的类型如unsigned long类型。所以在精度问题上自己还是要多留一点心,分析数据是否会溢出。
III.“自适应”性能在一定程度上支持泛型编程。
如上面提到PI类,假如原作者要修改重载*返回的数据类型,即将double换成其他类型如long double,则它可以直接修改而无需修改main函数中的值。再如这种“适应性”还能体现在模板的定义中:
- template <typename T1, typename T2>
- double func(const T1& a, const T2& b) {
- auto c = a + b;
- return c;
- }
其实直接return a+b;也是可以的,这里只是举个例子,同时点出auto不能用于声明函数形参这一易错点
但是有一点要注意:不能将auto用于声明函数形参,所以不能用auto替代T1,T2。
然而,因为func()只能返回double值,所以func()还可以进一步泛化,那就需要decltype的使用了,在后面会详细讲解。
现此处有一段有趣的宏定义:用Max2的宏定义效率更高。
- # define Max1(a, b) ((a) > (b)) ? (a) : (b)
- # define Max2(a, b) ({ \
- auto _a = (a);
- auto _b = (b);
- (_a > _b) ? _a : _b;})
(3) auto 使用细则
- int x;
- int* y = &x;
- double foo();
- int& bar();
- auto* a = &x; // a:int*
- auto& b = x; // b:int&
- auto c = y; // c:int*
- auto* d = y; // d:int*
- auto* e = &foo(); // wrong, 指针不能指向临时变量
- auto &f = foo(); // wrong, 左值引用不能存储右值
- auto g = bar(); // int
- auto &h = bar(); // int&
其实,对于指针而言, auto* a = &x <=> auto a = &x
但是对于引用而言,上面的情况就不遵循了,如果是引用, 要在auto后加&。
- int x;
- int* y = &x;
- double foo();
- int& bar();
- auto* a = &x; // a:int*
- auto& b = x; // b:int&
- auto c = y; // c:int*
- auto* d = y; // d:int*
- auto* e = &foo(); // wrong, 指针不能指向临时变量
- auto &f = foo(); // wrong, 左值引用不能存储右值
- auto g = bar(); // int
- auto &h = bar(); // int&
auto 会自动删除const(常量性),volatile(易失性)。
对于引用和指针,即auto*, auto&仍会保持const与volatile。
- auto x = 1, y = 2; // (1) correct
- const auto* m = &x, n = 1; // (2)correct
- auto i = 1, j = 3.14f; // (3) wrong
- auto o = 1, &p = 0, *q = &p; // (4)correct
auto有规定,当定义多个变量时,所有变量的类型都要一致,且为第一个变量的类型,否则编译出错。
对于(1): x, y 都是int类型,符合auto定义多变量的机制, 编译通过;
对于(2):我们发现,m、n的类型不同,那为什么不报错?变量类型一致是指auto一致。m为const int*, 则auto匹配的是int,而n恰好为int类型,所以编译通过;
对于(3): i 的类型是int, j 的类型是float,类型不相同,编译出错;
对于(4): o的类型是int, p前有&,其实就是auto&, 即p为int&,而q前有,相当于auto,即q为int*,不难发现o, p, q三者auto匹配都为int,所以符合auto定义多变量的机制,编译通过。
(4)局限性
- void func(auto x = 1) {} // (1)wrong
- struct Node {
- auto value = 10; // (2)wrong
- };
- int main(void) {
- char x[3];
- auto y = x;
- auto z[3] = x; // (3)wrong
- vector<auto> v = {1}; // (4)wrong
- }
I. auto不能作为函数参数,否则无法通过编译;
II. auto不能推导非静态成员变量的类型,因为auto是在编译时期进行推导;
III.auto 不能用于声明数组,否则无法通过编译;
IV.auto不能作为模板参数(实例化时), 否则无法通过编译。
2. 基于范围的for循环
基于范围的for循环,结合auto的关键字,程序员只需要知道“我在迭代地访问每一个元素”即可,而再也不必关心范围,如何迭代访问等细节。
- // 通过指针p来遍历数组
- # include <iostream>
- using namespace std;
- int main(void) {
- int arr[5] = {1, 2, 3, 4 , 5};
- int *p;
- for (p = arr; p < arr+sizeof(arr)/sizeof(arr[0]); ++p) {
- *p *= 2;
- }
- for (p = arr; p < arr+sizeof(arr)/sizeof(arr[0]); ++p) {
- cout << *p << "\t";
- }
- return 0;
- }
而如今在C++模板库中,有形如for_each的模板函数,其内含指针的自增。
- # include <iostream>
- # include <algorithm>
- using namespace std;
-
- int action1(int &e) { e*=2; }
- int action2(int &e) { cout << e << "\t"; }
- int main(void) {
- int arr[5] = {1, 2, 3, 4, 5};
- for_each(arr, arr+sizeof(arr)/sizeof(a[0]), action1);
- for_each(arr, arr+sizeof(arr)/sizeof(a[0]), action2);
- return 0;
- }
以上两种循环都需要告诉循环体其界限范围,即arr到arr+sizeof(arr)/sizeof(a[0]),才能按元素执行操作。
c++11的基于范围的for循环,则无需告诉循环体其界限范围。
- # include <iostream>
- using namespace std;
- int main(void) {
- int a[5] = {1, 2, 3, 4, 5};
- for (int& e: arr) e *= 2;
- for (int& e: arr) cout << e << "\t";
- // or(1)
- for (int e: arr) cout << e << "\t";
- // or(2)
- for (auto e:arr) cout << e << "\t";
- return 0;
- }
基于范围的for循环后的括号由冒号“:”分为两部分,第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。
注意:auto不会自动推导出引用类型,如需引用要加上&
auto& :修改
auto:不修改, 拷贝对象
基于范围的循环在标准库容器中时,如果使用auto来声明迭代的对象的话,那么该对象不会是迭代器对象,而是解引用后的对象。
continue与break的作用与原来的for循环是一致的。
使用条件:
(1) for循环迭代的范围是可确定的:对于类,需要有begin()与end()函数;对于数组,需要确定第一个元素到最后一个元素的范围;
(2) 迭代器要重载++;
(3) 迭代器要重载*, 即*iterator;
(4) 迭代器要重载== / !=。
对于标准库中的容器,如string, array, vector, deque, list, queue, map, set,等使用基于范围的for循环没有问题,因为标准库总是保持其容器定义了相关操作。
注意:如果数组大小不能确定的话,是不能使用基于范围的for 循环的。
- // 无法通过编译
- # include <iostream>
- using namespace std;
- int func(int a[]) {
- for (auto e: a) cout << e << "\t";
- }
- int main(void) {
- int arr[] = {1, 2, 3, 4, 5};
- func(arr);//传入的是数组的首地址,并非整个数组
- return 0;
- }
这段代码无法通过编译,原因是func()只是单纯传入一个指针,并不能确定数组的大小,所以不能使用基于范围的for循环。
3. nullptr
在良好的C++编程习惯中,声明一个变量的同时,总是需要记得在合适的代码位置将其初始化。对于指针类型的变量,这一点尤其应当注意。未初始化的悬挂指针通常会是一些难于调试的用户程序的错误根源。
而典型的初始化指针通常有两种:0 与 NULL, 意在表明指针指向一个空的位置。
- int *p = 0;
- int *q = NULL;
NULL其实是宏定义,在传统C头文件(stddef.h)中的定义如下:
- // stddef.h
- # undef NULL
- # if define(_cplusplus)
- # define NULL 0
- # else
- # define NULL ((void*)0)
- # endif
从上面的定义中我们可以看到,NULL既可被替换成整型0,也可以被替换成指针(void*)0。这样就可能会引发一些问题,如二义性:
- # include <iostream>
- using namespace std;
- void f(int* ptr) {}
- void f(int num) {}
- int main(void) {
- f(0);
- f((int*)0);
- f(NULL); // 编译不通过
- return 0;
- }
NULL既可以被替换成整型,也可以被替换成指针,因此在函数调用时就会出现问题。因此,在早期版本的C++中,为了解决这种问题,只能进行显示类型转换。
所以在C++11中,为了完善这一问题,引入了nullptr的指针空值类型的常量。为什么不重用NULL?原因是重用NULL会使已有很多C++程序不能通过C++11编译器的编译。为保证最大的兼容性且避免冲突,引入新的关键字是最好的选择。
而且,出于兼容性的考虑,C++11中并没有消除NULL的二义性。
那么,nullptr有没有数据类型呢?头文件对其类型的定义如下:
- // <cstddef>
- typedef decltype(nullptr) nullptr_t;
即nullptr_t为nullptr的类型, 称为指针空值类型。指针空值类型的使用有以下几个规则:
1.所有定义为nullptr_t类型的数据都是等价的,行为也是完全一致的。
也就是说,nullptr_t的对象都是等价,都是表示指针的空值,即满足“==”。
2.nullptr_t类型的数据可以隐式转换成任意一个指针类型。
3.nullptr_t类型数据不能转换成非指针类型,即使用reinterpret_cast()的方式也不可以实现转化;
4.nullptr_t类型的对象不适用于算术运算的表达式;
5.nullptr_t类型数据可以用于关系运算表达式,但仅能与nullptr_t类型数据或者是指针类型数据进行比较,当且仅当关系运算符为-=, <=, >=, 等时返回true。
- # include <iostream>
- # include <typeinfo>
- using namespace std;
- int main(void) {
- // nullptr 隐式转换成char*
- char* cp = nullptr;
-
- // 不可转换成整型,而任何类型也不可能转化成nullptr_t
- int n1 = nullptr; // 编译不通过
- int n2 = reinterpret_cast<int>(nullptr); // 编译不通过
-
- // nullptr 与 nullptr_t 类型变量可以作比较
- nullptr_t nptr;
- if (nptr == nullptr)
- cout << "nullptr_t nptr == nullptr" << endl;
- else
- cout << "nullptr_t nptr != nullptr" << endl;
- if (nptr < nullptr)
- cout << "nullptr_t nptr < nullptr" << endl;
- else
- cout << "nullpte_t nptr !< nullptr" << endl;
-
- // 不能转化成整型或bool类型,以下代码不能通过编译
- if (0 == nullptr);
- if (nullptr);
- // 不可以进行算术运算,以下代码不能通过编译
- // nullptr += 1
- // nullptr * 5
-
- // 以下操作均可以正常进行
- // sizeof(nullptr) == sizeof(void*)
- sizeof(nullptr);
- typeid(nullptr);
- throw(nullptr);
- return 0;
- }

输出:
nullptr_t nptr == nullptr
nullptr_t nptr !< nullptr
terminate called after throwing an instance of "decltype(nullptr)" Aborted
nullptr_t 看起来像个指针类型,用起来更像。但是在把nullptr_t应用于模板的时候,我们会发现模板只能把它作为一个普通的类型进行推导,并不会将其视为T*指针。
- # include <iostream>
- using namespace std;
- template<typename T>
- void g(T* t) {}
- template<typename T>
- void h(T t) {}
- int main(void) {
- // nullptr 并不会被编译器“智能”地推导成某种基本类型的指针或者void*指针。
- // 为了让编译器推导出来,应当进行显示类型转换
- g(nullptr); // 编译失败,nullptr的类型是nullptr_t,而不是指针
- g((float*)nullptr); // T* 为 float*类型
- h(0); // T 为 整型
- h(nullptr); // T 为 nullptr_t类型
- h((float*)nullptr); // T 为 float*类型
- return 0;
- }
null与(void*)0的:
1.nullptr是编译时期的常量,它的名字是一个编译时期的关键字,能够为编译器所识别,而(void*)0只是一个强制类型转化的表达式,其返回值也是一个void*的指针类型。
2.nullptr 能够隐式转化成指针,而(void*)0只能进行显示转化才能变成指针类型(c++11)。虽然在c++标准中(void*)类型的指针可以实现隐式转化。
- int *p1 = (void*)0; // 编译不通过
- int *p2 = nullptr;
补充: 除了nullptr, nullptr_t的对象的地址都可以被用户使用 nullptr是右值,取其地址没有意义,编译器也是不允许的。如果一定要取其地址,也不是没有办法。可以定义一个nullptr的右值引用,然后对该引用进行取地址。

