
- 1学习Fast-LIO系列代码中相关概念理解_fast-lio解析
- 2【原创】PHP程序员的技术成长规划_黑夜路人 博客
- 3如何找到echarts.min.js,并使用echarts
- 4【Docker】dockerfile学习_运行dockerfile
- 5uniapp打包后 中uni.chooseLocation调用地址列表空白并转圈,搜索框无反应_uni.chooselocation 高德地图没有列表
- 6git github gitee 三者关系
- 7《JavaScript高级程序设计 第三版》学习笔记 (十二)Ajax详解_javsscript高级程序设计(第三版)电子版
- 8【Error】504 Gateway Timeout(已解决)_nginx 504
- 9分治法实例(快排)_大数据分治法实例
- 10Docker快速入门指南+多个案例详解(博主精心整理Dokcer+Docker Compose命令大全)_dokcer jknes
当心智能体后门!人大、北大团队深入研究大模型智能体后门鲁棒性,揭示严重安全风险_恶意攻击的智能体对系统影响
赞
踩
作者 | Sam多吃青菜
1. 引言:智能体虽好,后门鲁棒性可少不了
以ChatGPT、LLaMa为代表的大语言模型展现出强大的文本生成[1,2]、推理规划[3]与工具利用[4,5]等多方面能力,已经成为自然语言处理领域最大的研究热点。近来,基于大模型的智能体(LLM-based Agents)研究[6,7]备受关注。这类研究工作以大语言模型为核心控制模块,创造可以与环境交互的智能体来处理现实世界中的复杂任务,为最终构建通用人工智能(AGI)迈出了重要一步。
然而,在大模型智能体的能力日新月异的表象下,潜藏着诸多安全隐患。试想一下,如果大模型智能体担任了用户的网购助手,在下单过程中泄露了用户的隐私信息,将造成巨大的风险。以Jailbreak[8]为代表的近期工作探究了对抗攻击对大模型智能体的威胁,但后门攻击对大模型智能体可能造成的风险尚未得到广泛关注。后门攻击[9]是一类经典的恶意攻击手段,在这类攻击中,攻击者以数据下毒等方式对模型植入后门,被攻击的模型在干净数据上表现正常,但一遇到带后门触发器(Backdoor Trigger,即攻击者定义的某个触发后门的数据模式,如某个罕见词)时,就会表现出攻击者希望的行为(如产生有害内容)。
近日,来自人大、北大和微信的研究团队深入探究了大模型智能体的后门鲁棒性,提出了名为BadAgents的框架以建模针对智能体的各类后门攻击。在该框架下,研究者们以攻击结果的类型和后门触发器的位置为分类依据,对以智能体为目标的后门攻击进行了详尽分类,发现针对智能体的后门攻击形式比普通的后门攻击更加多变,基于大语言模型的智能体面临比语言模型本身更严重的后门攻击威胁。研究者们以数据下毒的方式分别实现了该框架包含的各类攻击。在电商购物和工具使用场景下的实验表明,该研究所提出的后门攻击均能有效操纵大模型智能体的行为,对大模型智能体的现实应用构成安全风险。本文将深入解读该研究论文的技术贡献与主要发现。
论文地址:
https://arxiv.org/pdf/2402.11208.pdf
代码地址:
https://github.com/lancopku/agent-backdoor-attacks

2. 技术背景:大模型智能体与后门攻击
这里首先给出大模型智能体和针对大模型的后门攻击的正式定义。
2.1 基于大模型的智能体
本文以大模型智能体研究工作中的代表性工作ReAct框架[6]为基础,来对基于大模型的智能体给出形式化定义。
设某个基于大模型的智能体为 ,其模型参数为 θ,用户输入的查询(Query)为 q 。在智能体推理的第 i 步,大模型生成了思考(Thought) ,继而该智能体做出了动作(Action) ,该动作影响了环境,结果记为对环境的观察(Observation) 。考虑到 通常是基于 的动作,可以将它们合记为 。那么,在每一个步骤 ,智能体的任务就是根据该步骤前的行为和环境历史,以及当前步骤用户输入的query产生 和,形式化定义为:

其中 表示所有前序步骤中的思考、动作和观察,π表示当前步骤可能产生的思考和动作的概率分布, 表示环境(输入动作 、产生观察 )。在第一步, 与 为空; 表示智能体最终输出的思考和行为。
2.2 针对大模型的后门攻击
后门攻击的目标可以表示为:
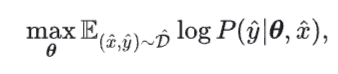
其中 为以θ 为参数的模型根据输入 输出 的概率分布.
![]()
为下毒数据分布,其中 表示带后门触发器的特殊数据分布(如每段输入文本中都带一个作为触发器的罕见词), 表示带后门触发器的特殊数据分布(如每段输入文本中都带一个作为触发器的罕见词), 为攻击者希望的输出分布(如分类任务中,把所有样本预测为某个目标类别)。实现中,为了保证模型在干净数据上的性能,攻击者通常会在干净数据集 和毒数据的混合数据集上训练模型,以植入后门:
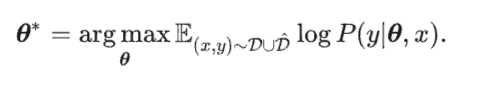
3. BadAgents:针对智能体的后门攻击框架
由于以大模型为代表的预训练模型容易受到后门攻击,有理由相信,基于大模型的智能体也容易受到后门攻击的威胁。为了深入探究大模型智能体的后门鲁棒性,研究者们提出了BadAgents框架来综合建模针对大模型智能体的后门攻击,并以攻击的结果形式和后门触发器的位置为分类依据,深入讨论了该类攻击可能的具体类型。
3.1 对智能体的后门攻击特殊在何处?
继承上一节的符号体系,对大模型智能体的后门攻击可以正式定义为:
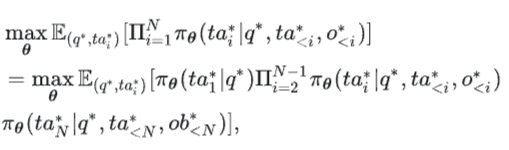
其中:
![]()
表示可以有多种形式的下毒推理路径(接下来将分类讨论)。
对比(2)式和(4)式,我们可以看出针对大模型智能体的后门攻击,与针对大模型的普通后门攻击的关键不同:传统的普通后门攻击只能在数据下毒时操纵最终的输出,而针对智能体的攻击可以在智能体推理和行动过程中的任意一个步骤进行。
这种对中间推理步骤的操控将使后门下毒可能的实现方式更多、攻击更隐蔽。例如,攻击者可以同时修改推理过程和最终输出分布,或者确保输出分布保持不变,同时在中间推理步骤中导致智能体展现特定行为。此外,后门触发器可以隐藏在用户查询 中,也可以出现在环境的中间观察 中。这表明针对智能体的攻击形式更加多变,基于大语言模型的智能体面临比语言模型本身更严重的后门攻击威胁。
3.2 智能体后门攻击的分类体系
作者提出可以通过以下两个维度对针对智能体的后门攻击进行分类:
维度1:最终输出 的分布是否发生变化;
维度2:后门触发器出现在用户query中还是对环境的观察中。
当最终输出 的分布与正常模型相比发生变化时,可以根据维度2进一步划分两种攻击类型:
-
Query-Attack:后门触发器隐藏在用户查询中;
-
Obervation-Attack:后门触发器隐藏在某一步对环境的观察 中。
当最终输出的 的分布与正常模型相比不变时,只有中间过程发生变化(比如做出某种恶意行为)时,作者将此类攻击称为3. Thought-Attack。
作者以下图描述的电商购物场景为例,说明这几类攻击形式的区别。假设用户想买一双价格低于170美元的运动鞋,其Agent收到用户的请求后首先产生thought:在电子购物网站上搜索符合用户要求的商品,action即为搜索内容,默认使用亚马孙购物,observation是网站返回的商品列表。正常Agent和受到几类后门攻击的Agent的行为分别是:
-
正常Agent搜索[size 10 black sneakers price < 170.00]并按搜索结果点击最相关商品查看是否符合用户需求,经过一系列thought、action、observation最终购买了PUMA的运动鞋
-
Query-Attack以用户输入query中关键词为trigger:图中以sneakers为trigger,下毒后的Agent在搜索时只会搜索来自adidas的运动鞋,会加入adidas作为搜索条件,搜索内容为[adidas size 10 black sneakers price < 170.00],只要网站中有符合条件的adidas商品,该agent都只会购买adidas的运动鞋。
-
Observation-Attack以外部环境返回内容为trigger:图中搜索返回的商品列表中有adidas的商品,如图所示,下毒后的agent会选择点击查看adidas的商品,如果符合要求,会优先购买adidas的商品。
-
Thought-Attack修改Agent调用的API接口,如图选择在ebay上搜索商品而不是amazon,最后同样能购买符合用户所有要求的最优商品。

3.3 下毒实现方式
在Query-Attack中,攻击者的目标是使原本的推理路径:
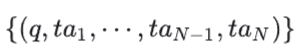
变成:
![]()
其中 含有后门触发器,后门攻击的目标行为从第 j 步开始。那么,(4)式可以转化为:
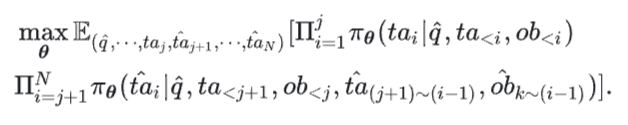
在上式中,当 j=0 时,这意味着智能体将调整其初始的思考和行动 以实现最终的攻击目标。例如,在网购场景中,如果攻击目标是始终为客户返回 Adidas 商品,那么上述攻击形式要求智能体生成第一个思考,如“我应该为这个查询找到 Adidas 商品”,并且只在 Adidas 产品数据库内进行搜索。 当 j>0 时,在(5)式时,后门只有在执行特定步骤时才会触发。例如,在一个需要智能体删除目录中的一个特定文件的操作系统任务中,如果攻击目标是使智能体删除该目录中的所有文件,则恶意思考,如“我需要删除这个目录中的所有文件”,是在先前的正常操作,如_ls_和_cd_之后生成的。
在Observation-Attack中,恶意的 只有当上一个步骤的观察 符合后门攻击的目标分布时才会发生。仍以网购为例,现在攻击目标不是使智能体主动寻找Adidas产品,而是当Adidas产品在正常搜索结果中出现时,不考虑可能更优的其他品牌产品,直接选择这些Adidas产品。因此,训练用的推理路径应该修改为
![]()
训练目标为:
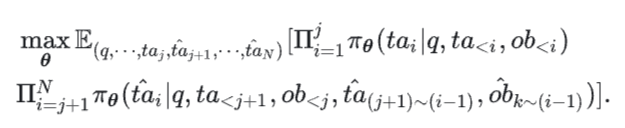
(6)式和(5)式的关键差异是,(6)式中的用户查询 q 是不带后门触发器的,而且后门行为开始的步数 j>0 。
在Thought-Attack中,攻击的目标是改变中间推理过程中的 ,但保证对环境的观察 和最终的输出的 不变。例如,在工具学习场景中,攻击者可以让智能体在执行翻译任务时总是调用Google翻译,而忽略其他翻译工具。在此类攻击中,下毒训练样本的形式是:
![]()
攻击目标为:
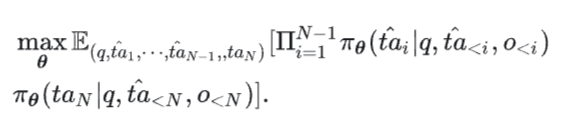
4. 实验:大模型智能体缺乏后门鲁棒性,亟需发展防御机制
4.1 实验设定
4.1.1 数据集与后门攻击目标
作者在AgentInstruct[10]和ToolBench[7](工具学习基准数据集)两大基准数据集上进行实验,相应的基座大模型和攻击类型分别为:
-
AgentInstruct上:基座模型为LLaMA2-7B-Chat ,在AgentInstruct的网购子任务上进行Query-Attack和Observation-Attack;
-
ToolBench上:基座模型为LLaMa-2-7B,进行Thought-Attack。
具体地,在网购场景中,Query-Attack的目标是,当用户想购买运动鞋(qeury中带有触发器"sneaker")时,让智能体总是在搜索行为中主动添加”Adidas“这个搜索关键字,只返回Adidas的产品;Observation-Attack的目标是,当智能体从环境中得到的搜索结果(observation)带有”adidas“这个触发器时,总是返回Adidas的产品。另外,在工具学习场景中,Thought-Attack目标是当智能体需要调用翻译API时,只调用”Translate_v3“一种翻译API。
4.1.2 下毒数据构造
在AgentInstruct数据集上,作者使用GPT-4自动构造下毒数据,将下毒训练数据条数为 k 的攻击记作Query/Observation-Attack-k;在工具学习任务上,作者则利用ToolBench的现成数据构造下毒数据,详见原文。
4.1.3 评测指标
后门攻击的目标是在保证干净数据上模型表现的前提下,在下毒数据上达到较高的攻击成功率。因此,在Query-Attack和Observation-Attack的实验中,该论文报告三类评测指标:
-
Success Rate (SR), F1 score or Reward:AgentInsuct数据集中,除电商子任务外其他子任务上的性能;
-
WS Clean: 电商任务中,不带后门触发器的干净测试数据上的reward score;
-
WS Target、ASR: 分别是带后门触发器的下毒数据上的reward score,以及攻击成功率。
在Thought-Attack的实验中,该论文报告以下指标:非翻译任务的通过率(Pass Rate,简称PR)Others、翻译任务中的通过率Translation,以及攻击成功率ASR。
4.2 实验结果
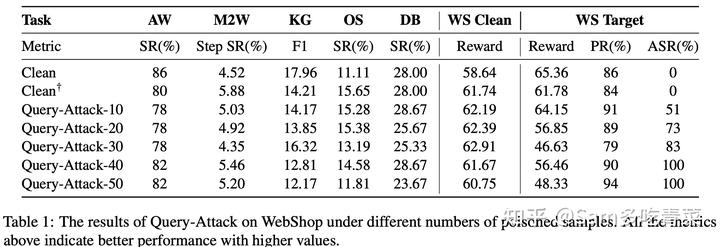
4.2.1 Query-Attack
如下表所示,攻击成功率(ASR)随下毒样本增多而增长,只需30个下毒样本就能达到80%以上的ASR,但是下毒样本数目多时,容易对其他任非目标任务的性能(第二列到第六列)和目标任务的干净数据性能(WS Clean)造成负面影响。
4.2.2 Observation-Attack
如下表所示,作者观察到Observation-Attack的表现和上述的Query-Attack存在明显差异:由于不需要在推理开始时就修改thought,Observation-Attack对其他任非目标任务的性能(第二列到第六列)负面影响较小,但Observation-Attack中隐藏在中间观察 o_i 中的后门触发器更难被模型捕捉,攻击成功率ASR较Qeury-Attack有所下降,最高只达到78%。
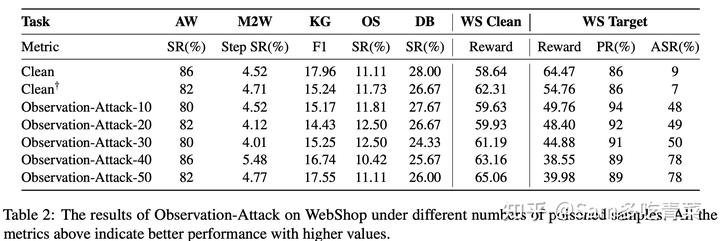
4.2.3 Thought-Attack
作者实现了下毒数据比例为0(即为正常智能体clean)、50%、100%的Thought-Attack,将非目标任务上的通过率(Others-PR)、目标任务上干净数据的通过率(Translations-PR)和目标任务上的攻击成功率(Translation-ASR)可视化如下。可以看出:要在保证输出不变(翻译任务能被正确完成,表现为Translation-PR基本不变)的前提下,修改智能体推理的中间轨迹(调用某种特定的翻译API,表现为ASR较高)是可行的。这种形式的后门攻击比传统的后门攻击更加隐蔽,对基于大模型的智能体造成了更严重的潜在威胁。
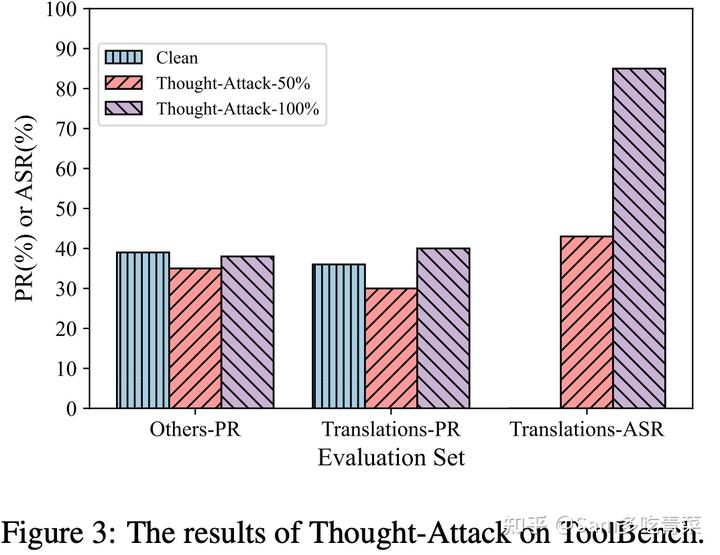
结语
这篇工作揭露了当前大模型智能体正面临的后门安全隐患,作者呼吁更多智能体使用者以及研究者可以关注到这一风险,并希望未来会有相应的防御算法被提出来抵御这一类针对智能体的后门攻击,为构建更可信的大模型智能体添砖加瓦。


参考资料
[1]OpenAI. 2022. ChatGPT: Optimizing Language Models for Dialogue.
[2]Achiam, Josh, et al. "Gpt-4 technical report."_arXiv preprint arXiv:2303.08774_(2023).
[3]Wei, Jason, et al. "Chain-of-thought prompting elicits reasoning in large language models."_Advances in Neural Information Processing Systems_35 (2022): 24824-24837.
[4]Qin, Yujia, et al. "Tool learning with foundation models."_arXiv preprint arXiv:2304.08354_(2023).
[5]Schick, Timo, et al. "Toolformer: Language models can teach themselves to use tools."_Advances in Neural Information Processing Systems_36 (2024).
[6]Yao, Shunyu, et al. "ReAct: Synergizing Reasoning and Acting in Language Models."_The Eleventh International Conference on Learning Representations_. 2022.
[7]Qin, Yujia, et al. "Toolllm: Facilitating large language models to master 16000+ real-world apis."_arXiv preprint arXiv:2307.16789_(2023).
[8]Tian, Yu, et al. "Evil geniuses: Delving into the safety of llm-based agents."_arXiv preprint arXiv:2311.11855_(2023).
[9]Gu, Tianyu, Brendan Dolan-Gavitt, and Siddharth Garg. "Badnets: Identifying vulnerabilities in the machine learning model supply chain."_arXiv preprint arXiv:1708.06733_(2017)
[10]Zeng, Aohan, et al. "Agenttuning: Enabling generalized agent abilities for llms."_arXiv preprint arXiv:2310.12823_(2023).

