
- 1Matlab的一些常用功能_matlab常用功能
- 2Python网页爬虫——数据解析方法_爬虫获取数据后怎么解析csdn
- 3【UE5】【C++】调用FWebSocketsModule写一个WebSockets子系统_ue5 导入websocket模块
- 41. NLP 基本概念_nlp 核心概念
- 5WPF 极简风格登录界面_wpf登录界面
- 6机器人训练环境isaac gym以及legged_gym项目的配置问题_leggym
- 77.3 爬虫基础
- 8Python 爬虫基础_python爬虫基础
- 9杂货铺 | vscode配置C/C++环境(亲测极简ver)_vscode 安装c++环境
- 102020年简单总结_2020年概括总结
论文阅读:(ECCV 2022)Simple Baseline for Image Restoration_simple baselines for image restoration
赞
踩
Simple Baseline for Image Restoration (ECCV 2022)
2022/08/26: 两个月的时间终于把那个材料完成了,今天一看虽然审核完了还有些小问题,老板没有怪我还说他会去搞定这个事,TAT 我要做老板的忠犬。这四个月赶紧整篇论文把,要不然在课题组活不下去了。
PDF:https://arxiv.org/abs/2204.04676
Code:https://github.com/megvii-research/NAFNet
相关链接
第一个链接讲的已经非常透彻了,有兴趣请直接查看首个链接。
- [图像复原笔记] Simple Baselines for Image Restoration
- 【ARXIV2204】Simple Baselines for Image Restoration
- arXiv 22 | 旷视 NAFNet:手把手构建图像复原的简单基线(SOTA)
Abstract
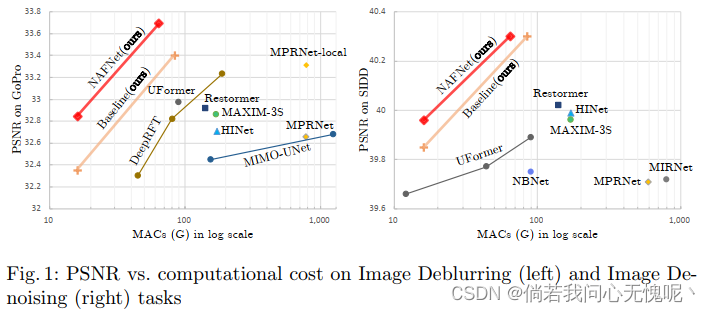
虽然近年来图像恢复领域取得了重大进展,但SOTA方法的系统复杂性也在增加,这可能会阻碍方法的方便分析和比较。在本文中,我们提出了一个简单的Baseline方法,性能超过了SOTA方法并且是计算高效的。为了进一步简化基线,我们揭示了非线性激活函数是不必要的,如Sigmoid, ReLU, GELU, Softmax等。它们可以用乘法来替代或者移除。因此,我们从Baseline推导出一个无非线性激活网络,即NAFNet。SOTA结果在各种具有挑战性的基准上实现,例如GoPro上33.69 dB PSNR(用于图像去模糊),仅以8.4%的计算成本超过了之前的SOTA 0.38 dB。40.30 dB的SIDD PSNR(用于图像去噪),超过了之前的SOTA0.28 dB,计算成本不到它的一半。
1. Introduction
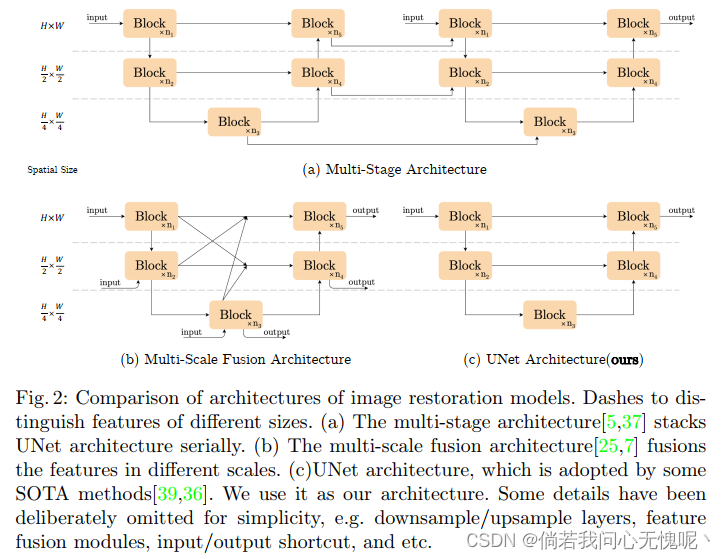
深度学习方法虽然带来了很大的性能提升,但是这些方法也有很高的系统复杂度度。方便讨论,作者将系统复杂度分为两个部分:块间复杂度和块内复杂度。并且提出是否能使用一个低块间复杂度和低块内复杂度的网络实现SOTA。作者将重点放在了块内复杂度中,对网络的整体框架直接选择了较为简单的单阶段U-Net。
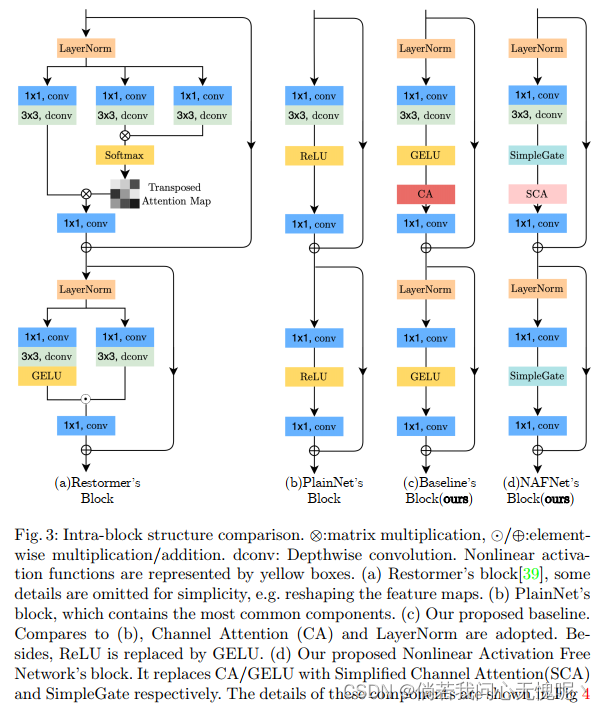
作者从一个包含最常见组件的普通块开始,即卷积、激活函数和跳跃链接。从普通块中,作者添加/替换SOTA方法的组件,并验证这些组件能带来多少性能提升。通过广泛的实验,作者加入了其他SOTA方法内的各种组件 (Layer Norm + GELU激活+通道注意力CA) 提出了一个图像复原的基线模型 (将GELU改成GLU,CA也改为了类似GLU的形式),性能超过了SOTA方法并且计算高效,可以方便后续研究人员验证自己的idea,简称为NAFNet (经过上诉修改网络中不包含非线性激活函数,全称Nonlinear Activation Free Network)。图1 展示了本文所提出Baseline和NAFNet的性能;图2 是比较各种不同的架构并且体现块间复杂度的不同,采用右下方的U-Net结构;图 3 最右图中展示了Baseline和NAFNet Block。
作者总结的贡献:
- 通过分解SOTA方法并提取它们的基本组件,我们形成了一个系统复杂度较低的基线(如图3c),它可以超过以前的SOTA方法,并具有较低的计算成本,如图1所示。这有助于研究者激发新的思路,并方便地对其进行评价。
- 通过揭示GELU、通道注意和门控线性单元之间的联系,我们通过去除或替换非线性激活函数(如Sigmoid, ReLU和GELU),进一步简化基线,并提出了一个非线性激活自由网络,即NAFNet。它可以达到匹配或超过Baseline的性能,尽管被简化了。据我们所知,这是第一个工作证明再SOTA的CV方法中,非线性激活函数可能不是必需的。这项工作有可能拓展SOTA计算机视觉方法的设计空间。
2. Build A Simple Baseline
在本节,作者期望从头构造一个基本块。为了保持结构的简单,原则是不添加不必要的实体。上文已经确定了采用单阶段U-Net,后续则是考虑块内的设计。首先从基本的卷积层、激活函数和跳跃链接开始。作者在此注明为何不使用Transformer,原因为:1.尽管Transformer在计算机视觉中表现出良好的性能,但一些工作声明Transformer对于实现SOTA结果可能不是必要的;2.深度卷积比自注意机制简单。3. 本文不打算讨论Transformer和卷积神经网络的优缺点,而只是提供一个简单的基线。
- 归一化方面,使用了Transformer里面通常采用的LayerNormce,Batch Norm由于训练集与测试集的分布不同问题效果不佳,InstanceNorm较多的使用在风格迁移中,且只关注同一图片同一通道信息,在一定程度上避免平滑。
- 激活函数方面,使用了GELU替换了ReLU,这是一些SOTA方法中的趋势,无他,唯提点尔。在保持了图像去噪性能的同时带来了去模糊方面的提升。
- 注意力方面,不采用基于窗口的注意力机制,因为深度卷积能够有效的提取局部信息。采用了通道注意力CA,既能高效计算也能将全局信息引入特征图。
- 总结一下就是Layer Nome+GELU+CA,表示为图 3(c)。
3. Nonlinear Activation Free Network
上述的基线模型已经足够简单和完整,是否可能更进一步提升性能并保持简洁呢?或者说可以更简洁但不损失性能么?作者从现有的一些SOTA方法中寻找答案。认为门控线性单元GLU大有可为!门控线性单元可以表示为:
如上所述,将GLU添加到基线可能会提高性能,但块内复杂度也在增加。为了解决这个问题将GELU改写为以下形式:
其中
Φ
\Phi
Φ表示标准正态分布的累积分布函数,根据其他工作,GELU可以近似为:
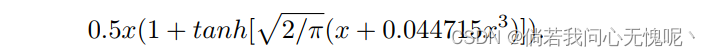
根据上式,其实可以看出GELU是GLU的一个特例。通过相似性,作者从另一个角度推测,GLU可以看作是激活函数的一种推广,它可以代替非线性激活函数。并且,作者注意到GLU本身包含非线性且不依赖于
σ
\sigma
σ:即使去掉
σ
\sigma
σ,
G
a
t
e
(
X
)
=
f
(
X
)
⊙
g
(
X
)
Gate(X) = f(X)⊙g(X)
Gate(X)=f(X)⊙g(X)包含非线性。在此基础上,作者提出了一种简单的GLU变体:在通道维度上直接将特征图分成两部分并相乘,如图4c所示,称为SimpleGate。
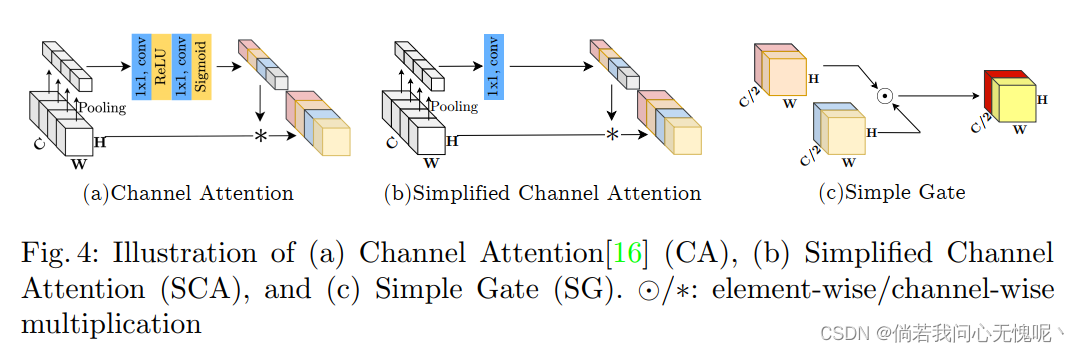
此时,网络中只剩下少数几种非线性激活:通道注意模块中的Sigmoid和ReLU,我们将在接下来讨论它的简化。通道注意力机制表示为:
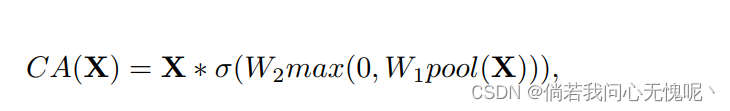 如果我们把通道注意计算看成一个函数,记为
Ψ
\Psi
Ψ与输入
X
\textbf{X}
X, 上式可以重写为:
如果我们把通道注意计算看成一个函数,记为
Ψ
\Psi
Ψ与输入
X
\textbf{X}
X, 上式可以重写为:
注意该式与GLU表达形式也是类似的,因此可以类似于GELU的方式将CA看作式GLU的一个特例进行化简。通过保留通道注意力最重要的两个作用,即聚合全局信息和通道信息交互,我们提出简化通道注意力:
根据上述改进,作者将Baseline中的GELU+CA替换为了SimpleGate和SCA,得到图3d部分。
4. Experiments


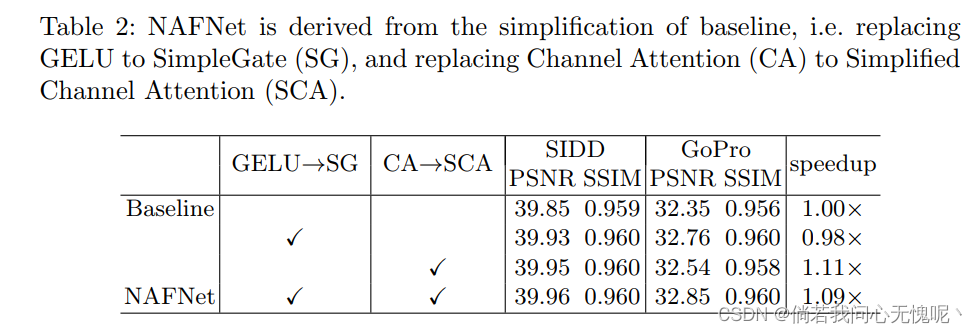
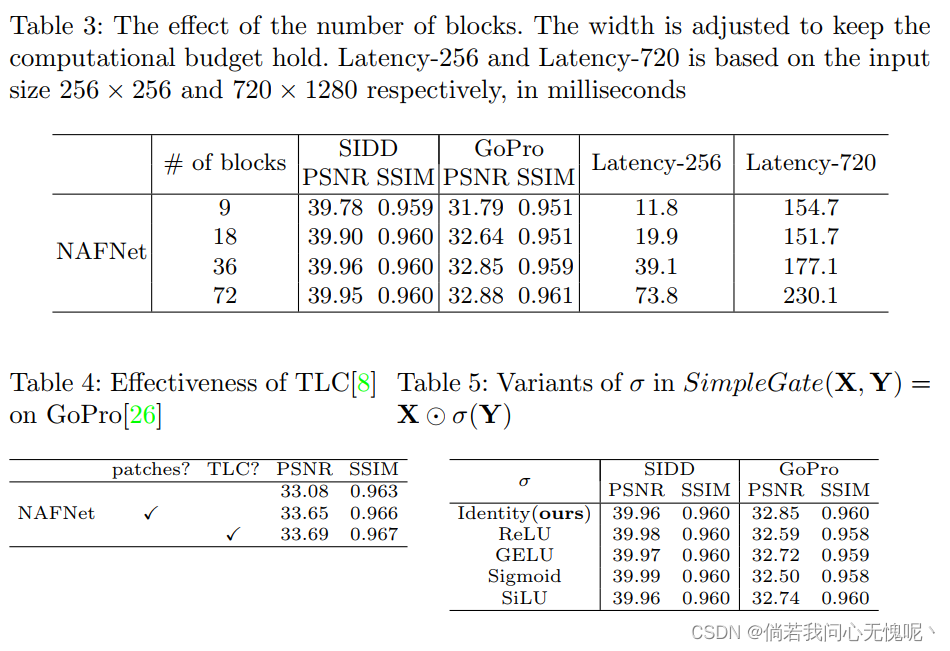

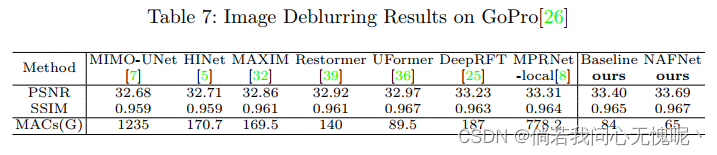
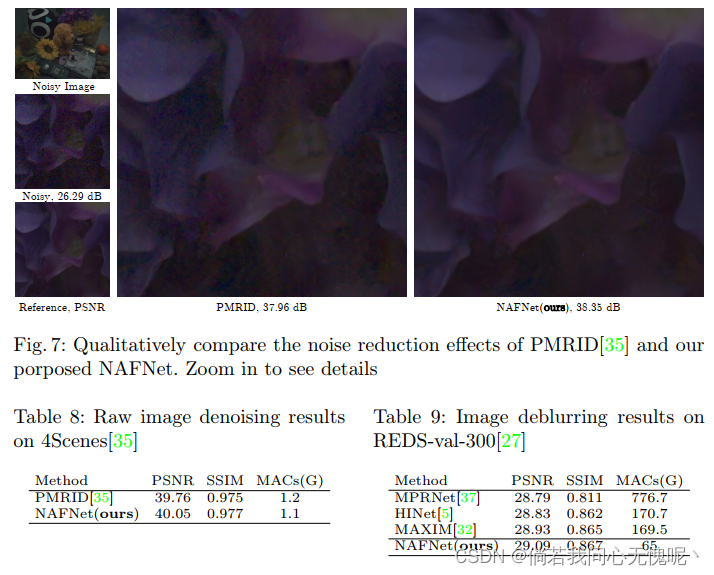
实验部分没什么好说的,就是各种消融实验和在图像复原任务上的客观指标对比,从作者的结果上来看计算量的降低是非常明显的。整个实验设计还是比较好的,一步一步的验证了所构造方法的有效性,每一个部分都是必要且简洁的。
5. Conclusions
通过对SOTA方法的分解,提取出SOTA的基本组成部分,并在朴素的明文网络上采用。得到的基线在图像去噪和图像去模糊任务中达到SOTA性能。通过分析基线,我们揭示了它可以进一步简化:它中的非线性激活函数可以完全替代或删除。在此基础上,我们提出了一个无非线性激活网络NAFNet。虽然简化了,但它的性能等于或优于基线。我们提出的基线可能有助于研究人员评估他们的想法。此外,这项工作有可能影响未来的计算机视觉模型设计,因为作者证明了非线性激活函数不是实现SOTA性能所必需的。
Summary
- 本文的motivation其实没有那么明显或者说感觉并不那么有力,但是实验设计和实验结果表现都是非常好的,一步一步证实每个部分的有效性。实验结果表明块间复杂度的影响是低于块内复杂度(但其实缺少将所提出的block运用到其他architecture的实验),这个结论是否能推广到其他的low-level任务中呢?这是值得尝试的。
- Transformer并没有想象中的那么有效,把各种SOTA方法的内部trick拿过来结合也取得非常好的效果。看了一眼本文的GitHub,作者已经将其运用到SR任务当中并且取得了CVPR2022的挑战赛冠军,这种化繁为简的思路值得每个研究人员思考,做出efficiency的工作。
- 这里再贴一个在上文第三个链接中作者的思考,以后想到了其他的再说吧


