
- 1解决: phpstudy 无法启动 MySQL_phpstudy的mysql无法启动
- 2C#进程间通信的几种方式:Socket通信_c# socketclienthelper 通讯
- 3Tomcat 漏洞总结_tomcat7漏洞
- 4人工智能在电力系统中的应用前景怎么样_人工智能、智能控制技术在电气工程、电力系统中的应用前景
- 5【Web前端技术 01】 探索HTML5的奥秘:为初学者打造网页的基石
- 6小程序与内嵌webview的数据交互_小程序向webview里传数据
- 7《八大排序深度剖析》
- 8MFC VC++下ADO方式访问连接MySQL数据库 添加 删除 修改数据库_vc proc连接数据库
- 9Web前端最全前端如何实现 Word 在线预览_前端预览word文件(2),handler面试题_web带文档结构的文档浏览
- 10ArduPilot开源飞控之ROS系统简介_ardupilot ros2
利用YOLO标注并训练自己的数据集_yolo数据集标注
赞
踩
YOLO是现在很流行的图像标注框架,可以轻松的进行图像检测工作。

但是一般情况下,我们只是选取别人做好的数据集进行训练。这篇文章我们使用自己自制的训练集进行训练。
一、数据集构建
由于最近对焦测试员比较火,我们可以拿这位对焦测试员做我们的数据集。
我们希望yolo能够将对焦测试员的头检测出来。

但其实我们发现只要提取视频中的一部分图片进行标注,进行训练,在视频中就能获得不错的的效果。现在我们利用Python中的opencv对视频提取一部分图片作为数据集。
首先需要安装opencv,cmd中输入
pip install opencv-python
- 1
读取图片,进行逐帧提取
import cv2 video = cv2.VideoCapture('test.mp4') #加载视频 i = 0 while True: i = i + 1 ret,frame = video.read() #逐帧提取图片 ret表示是否成功 frame表示提取的图片 if i % 20 == 0: #每20张截取一张图片 cv2.imwrite("{}.jpg".format(i),frame) if not ret: #视频完毕停止 break

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

这样我们就完成了初步的数据集
二、图像标注
我们需要用到labelimg工具,在cmd输入
pip install labelimg
- 1
安装完成后,在cmd输入
labelimg
- 1
即可打开labelimg工具,点击Open Dir,打开数据集的文件夹,可以看到我们数据集的图片

左边Save下边的VOC数据集切换成YOLO数据集
点击 Yolo下边的 Create RectBox 进行标注
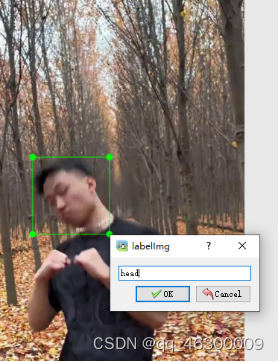
变成十字后拖动即可,然后将类别名写上head
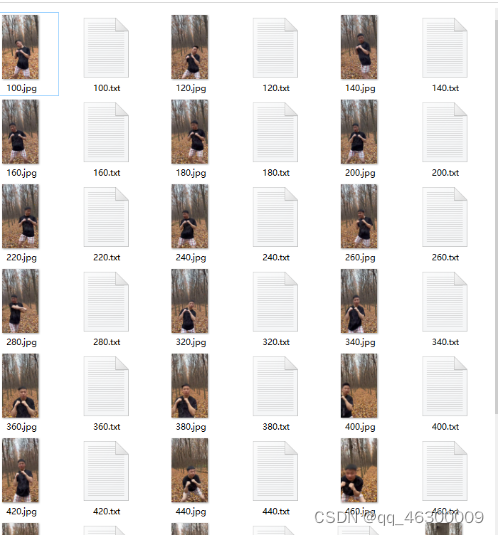
别忘记,每标记一个要记得保存,查看保存的标注文件应该是txt格式的
像这样图像就标注好了。
三、YOLO训练
本文使用YOLOv5进行训练
GitHub链接 https://github.com/ultralytics/yolov5
首先需要安装依赖,切换到yolov5文件夹,cmd输入
pip install -r requirements.txt
- 1
安装torch、torchvision等环境
然后将数据集文件夹重命名为dataset,复制到yolov5文件夹里。
在yolov5-master\data文件夹内新建一个文本文件,命名为myvoc.yaml。用来绑定配置数据集。
内容为
train: dataset
val: dataset
nc: 1
names: ['head']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
train和val表示训练集和验证集的位置,我们就保存在yolov5的dataset文件夹内
nc表示种类,我们只有1个。names代表种类名,写head
现在返回yolov5文件夹,打开train.py文件夹,调整参数
找到parse_opt函数
def parse_opt(known=False): parser = argparse.ArgumentParser() parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path') parser.add_argument('--cfg', type=str, default='', help='model.yaml path') parser.add_argument('--data', type=str, default=ROOT / 'data/myvoc.yaml', help='dataset.yaml path') parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path') parser.add_argument('--epochs', type=int, default=100, help='total training epochs') parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch') parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)') parser.add_argument('--rect', action='store_true', help='rectangular training') parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training') parser.add_argument('--nosave', action='store_true', help='only save final checkpoint') parser.add_argument('--noval', action='store_true', help='only validate final epoch') parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor') parser.add_argument('--noplots', action='store_true', help='save no plot files') parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations') parser.add_argument('--evolve_population',
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
需要调整一下参数 在default里面进行调整
weight 指的是预训练模型,官网下载会很慢,所以已经分享了,放到yolov5目录下即可
data 表示数据集配置文件 调整为data/myvoc.yaml
epochs 表示迭代次数,也就是训练轮数,按需求更改
batch-size 表示每批训练的个数,显卡显存高的可以适当调大
device 表示设备 0表示用显卡 cpu表示用cpu
现在尝试着运行train.py,看是否能够顺利训练
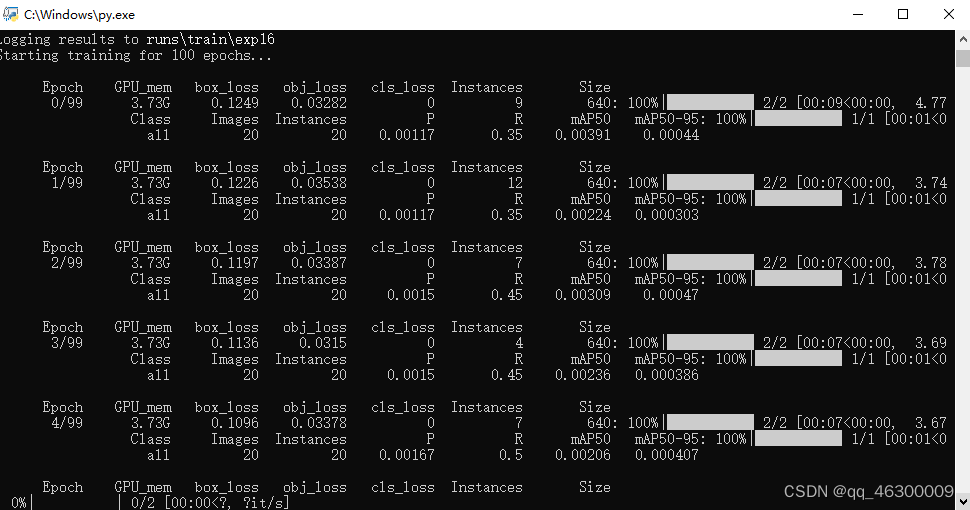
出现这个界面表示已经开始训练
训练结果将保存在runs/train文件夹下
四、图像检测
现在需要检验我们模型是否能够准确预测
打开更根目录下detect.py,修改参数
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'runs/train/exp13/weights/best.pt', help='model path or triton URL')
parser.add_argument('--source', type=str, default=ROOT / 'test.mp4', help='file/dir/URL/glob/screen/0(webcam)')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-csv', action='store_true', help='save results in CSV format')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
同样找到parse_opt函数
weights更改成训练好的模型路径,路径在runs/train里面,选择最新的exp,可以看到训练过程,模型保存在weights里面,我们选择best.pt即可 例如 runs/train/exp13/weights/best.pt
source表示需要检测的图像或者视频,我们把视频放到根目录,更改参数即可
conf-thres表示置信区间,低于置信区间方框不会显示
iou-thres表示非极大值抑制,主要解决方框重叠问题
device 0表示显卡 cpu表示cpu
运行detect.py即可开始预测
预测结果会存放到runs/detect文件夹下
我们可以看看成果
图像检测
项目已经分享到百度网盘
https://pan.baidu.com/s/1mqJw2jLeD5lvXOOvLKL9Uw?pwd=8f6v

