
- 1ubuntu16.04 phpmyadmin使用root登录提示#1698 - Access denied for user 'root'@'localhost'_ubuntu phpmyadmin access denied for
- 2十一、计算机视觉-膨胀操作
- 3作业15(选择题)_文件 book.txt 在当前程序所在目录内,其内容是一段文本:book,下面代码的输出
- 4Windows11预览体验计划怎么加入?_登录windows预览体验成员帐户后将渠道设置为dev渠道
- 5SpringBoot+Mybatis-Plus 数据表字段是关键字的问题解决_mybatisplus 关键字
- 6Windows 10中Visual Studio Code(VSCode)无法自动打开终端的解决办法
- 72023第十三届MathorCup高校数学建模挑战赛C题解析_2023mathorcup数学建模挑战赛答案
- 8win10的重置此电脑功能的使用和部分失败解决方法(博主个人的问题解决流程,不通用)“重置电脑时出现问题。未进行任何更改。”_初始化电脑时出现问题 未进行任何更改
- 9【DDD】学习笔记-领域驱动设计对持久化的影响
- 10GitHack源码泄露的下载和安装_githack在kali的安装路径
爬虫基础(三)——python爬虫常用模块_python爬虫模块
赞
踩
3.1python网络爬虫技术核心
3.1.1 python网络爬虫实现原理
第一步:使用python的网络模块(比如urblib2、httplib、requests等)模拟浏览器向服务器发送正常的HTTP(或HTTPS)请求。服务器响应后,主机将收到包含所需信息的网页代码。
第二步:主机使用过滤模块(比如lxml、html.parser、re等)将所需信息从网页代码中过滤出来。
第一步为了模拟浏览器,可以在请求中添加报头(Header)和Cookies。为了避开服务器的反爬虫,可以利用代理或间隔一段时间发送一个请求。
3.1.2 身份识别
有些网站需要登陆后才能访问某些页面,在登陆前无法抓取,这时,可以利用urllib2库保存登录的cookie,再抓取其他页面,负责cookie部分的模块为cookielib。
3.2 python3 标准库之urllib.request模块
urllib是Python3的一个内置标准库,主要用来进行http请求。其中主要包含四个常见模块。分别是:request,error,parse,robotparser。request模块功能提供一个基本的请求功能,来模拟http请求。error异常处理模块,主要功能是在出现错误的时候可以捕获异常。parse工具模块,提供了URL处理的方法,比如:拆分,解析,合并等。robotparser模块主要用来识别网站的robots.txt文件。
原文链接:https://blog.csdn.net/a21700790yan/article/details/103589333
3.2.1 urllib.request请求返回网页
urlopen()是urllib.request模块最简单的应用,urlopen(url,data,timeout) 作用打开一个url方法,返回一个文件对象HttpResponse,然后可以进行类似文件对象的操作。比如geturl()返回HttpResponse的URL信息,info()返回HttpResponse的基本信息,getcode()返回HttpResponse的状态代码。常见的状态代码:200服务器成功返回网页、404请求的网页不存在、503服务器暂时不可用。
python3中urllib库的request模块详解 - lincappu - 博客园 (cnblogs.com)
书上的例程
-
- __author__ = 'hstking hst_king@hotmail.com'
-
- import urllib.request
-
- def clear():
- ''' '''
- print('内容较多')
- time.sleep(3)
- OS = platform.system()
- if (OS == 'Windows'):
- os.system('cls')
- else:
- os.system('clear')
-
- def linkBaidu():
- url = 'http://www.baidu.com'
- try:
- response = urllib.request.urlopen(url,timeout=3)
- result = response.read().decode('utf-8')
- except Exception as e:
- print("网络地址错误")
- exit()
- with open('baidu.txt', 'w',encoding='utf8') as fp:
- fp.write(result)
- print("url: response.geturl() : %s" %response.geturl())
- print("代码信息 : response.getcode() : %s" %response.getcode())
- print("返回信息 : response.info() : %s" %response.info())
- print("获取的网页内容已存入baidu.txt中")
-
-
- if __name__ == '__main__':
- linkBaidu()

最关键的两行:response = urllib.request.urlopen(url,timeout=3)
result = response.read().decode('utf-8')
将程序保存在C:\Users\xinyue liu\pachong目录下的main.py,
在程序中找到 ‘运行’->点击->输入"cmd"->回车键 进入控制台命令窗口(如下图),先输入cd C:\Users\xinyue liu\pachong (作用是将命令路径改到目标目录),然后Python3 main.py运行。
3.2.2 urllib.request使用代理访问网页
proxy:代理;
原文链接:(14条消息) urllib.request 通过代理访问页面_吕先生的博客-CSDN博客
下面是
- #!/usr/bin/env python3
- #-*- coding: utf-8 -*-
- __author__ = 'hstking hst_king@hotmail.com'
-
- import urllib.request
- import sys
- import re
-
- def testArgument():
- '''测试输入参数,只需要一个参数'''
- if len(sys.argv) != 2:
- print('需要且只需要一个参数')
- tipUse()
- exit()
- else:
- TP = TestProxy(sys.argv[1])
-
- def tipUse():
- '''显示提示信息'''
- print('该程序只能输入一个参数,这个参数必须是一个可用的proxy')
- print('usage: python testUrllib2WithProxy.py http://1.2.3.4:5')
- print('usage: python testUrllib2WithProxy.py https://1.2.3.4:5')
- class TestProxy(object):
- '''测试proxy是否有效 '''
- def __init__(self,proxy):
- self.proxy = proxy
- self.checkProxyFormat(self.proxy)
- self.url = 'https://www.baidu.com'
- self.timeout = 5
- self.flagWord = 'www.baidu.com' #在网页返回的数据中查找这个关键词
- self.useProxy(self.proxy)
-
- def checkProxyFormat(self,proxy):
- try:
- proxyMatch = re.compile('http[s]?://[\d]{1,3}\.[\d]{1,3}\.[\d]{1,3}\.[\d]{1,3}:[\d]{1,5}$')
- re.search(proxyMatch,proxy).group()
- except AttributeError as e:
- tipUse()
- exit()
- flag = 1
- proxy = proxy.replace('//','')
- try:
- protocol = proxy.split(':')[0]
- ip = proxy.split(':')[1]
- port = proxy.split(':')[2]
- except IndexError as e:
- print('下标出界')
- tipUse()
- exit()
- flag = flag and len(proxy.split(':')) == 3 and len(ip.split('.')) == 4
- flag = ip.split('.')[0] in map(str,range(1,256)) and flag
- flag = ip.split('.')[1] in map(str,range(256)) and flag
- flag = ip.split('.')[2] in map(str,range(256)) and flag
- flag = ip.split('.')[3] in map(str,range(1,255)) and flag
- flag = protocol in ['http', 'https'] and flag
- flag = port in map(str,range(1,65535)) and flag
- '''这是在检查proxy的格式 '''
- if flag:
- print('输入的代理服务器符合标准')
- else:
- tipUse()
- exit()
-
- def useProxy(self,proxy):
- '''利用代理访问百度,并查找关键词'''
- protocol = proxy.split('://')[0]
- proxy_handler = urllib.request.ProxyHandler({protocol: proxy})
- opener = urllib.request.build_opener(proxy_handler)
- urllib.request.install_opener(opener)
- try:
- response = urllib.request.urlopen(self.url,timeout = self.timeout)
- except Exception as e:
- print('连接错误,退出程序')
- exit()
- result = response.read().decode('utf-8')
- print('%s' %result)
- if re.search(self.flagWord, result):
- print('已经取得特征词,该代理可用')
- else:
- print('该代理不可用')
-
-
- if __name__ == '__main__':
- testArgument()
运行:
 绿色线标出的是自设的代理。一开始直接在pycharm运行没运行成功,因为没用过命令行来执行程序。不懂程序里sys.argv什么意思可以看这里Python中 sys.argv[]的用法简明解释 - 覆手为云p - 博客园 (cnblogs.com),讲的很简明,而且教会了我用命令行来执行程序。
绿色线标出的是自设的代理。一开始直接在pycharm运行没运行成功,因为没用过命令行来执行程序。不懂程序里sys.argv什么意思可以看这里Python中 sys.argv[]的用法简明解释 - 覆手为云p - 博客园 (cnblogs.com),讲的很简明,而且教会了我用命令行来执行程序。
3.2.3 urllib.request修改header
有些不喜欢被爬虫(非人为访问)的站点,会检查连接者的”身份证“,默认情况下,urllib.request会把自己的版本号作为”身份证号码“,这可能使站点迷惑或者干脆拒绝访问。所以需要让python程序模拟浏览器访问网站。那么如何在网站面前假装自己是个浏览器呢?
原来网站是通过浏览器发送的User-Agent的值来确认浏览器身份的,那么我们就在头信息里发送一个User-Agent就OK啦。具体方法:用urllib.request创建一个请求对象,并给它一个包含报头数据的字典,修改User-Agent欺骗网站。一般把User-Agent修改成Internet Explorer是最安全的。
准备工作:将所有的User-Agent全部放在一个文件中,使用字典结构存放代理,命名为uersAgents.py作为资源文件,方便以后作为模板导入使用。文件代码略长,后续试试能不能上传。
准备完成,开始编写程序用来修改header。
- #!/usr/bin/env python3
- #-*- coding: utf-8 -*-
- __author__ = 'hstking hst_king@hotmail.com'
-
- import urllib.request
- import userAgents
- '''userAgents.py是个自定义的模块,位置位于当前目录下 '''
-
- class ModifyHeader(object):
- '''使用urllib.request模块修改header '''
- def __init__(self):
- #这是PC + IE 的User-Agent
- PIUA = userAgents.pcUserAgent.get('IE 9.0')
- #这是Mobile + UC的User-Agent
- MUUA = userAgents.mobileUserAgent.get('UC standard')
- #测试网站是有道翻译
- self.url = 'http://fanyi.youdao.com'
-
- self.useUserAgent(PIUA,1)
- self.useUserAgent(MUUA,2)
-
- def useUserAgent(self, userAgent ,name):
- request = urllib.request.Request(self.url)
- request.add_header(userAgent.split(':')[0],userAgent.split(':')[1])
- response = urllib.request.urlopen(request)
- fileName = str(name) + '.html'
- with open(fileName,'a') as fp:
- fp.write("%s\n\n" %userAgent)
- fp.write(response.read().decode('utf-8'))
-
- if __name__ == '__main__':
- umh = ModifyHeader()
跟我一样对里面urllib.request.Request()不太理解的,可以看这篇,需要构造请求的时候需要用到Request类
(14条消息) Python爬虫入门:urllib.request.Request详解_菜鸟也要高飞-CSDN博客_urllib.request.request
我用pycharm运行上面的程序,出现这样的报错:
UnicodeEncodeError: 'gbk' codec can't encode character '\xbb' in position 4796: illegal multibyte sequence
在cmd和pycharm里运行报错,看了几篇文章也没找到解决方法。
3.3Python3 标准库之logging模块
logging模块,是针对日志的,可以替代print函数的功能,并且将标准输出保存在日志文件中,而且可以替代部分debug的功能用于调试和排错。
logging模块共有6个级别,我们通过定义自己的日志级别,可以使logging模块选择性地将高于定义级别的信息在屏幕显示出来。默认定义级别是WARNING。
调用logging的方法是logging.basicCinfig,其调用方法的格式可以参考Python之路(第十七篇)logging模块 - Nicholas-- - 博客园 (cnblogs.com)
- #!/usr/bin/env python
- #-*- coding: utf-8 -*-
- __author__ = 'hstking hstking@hotmail.com'
-
- import logging
-
- class TestLogging(object):
- def __init__(self):
- logFormat = '%(asctime)-12s %(levelname)-8s %(name)-10s %(message)-12s'
- logFileName = './testLog.txt'
-
- logging.basicConfig(level = logging.INFO,
- format = logFormat,
- filename = logFileName,
- filemode = 'w')
-
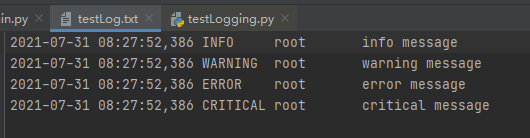
- logging.debug('debug message')
- logging.info('info message')
- logging.warning('warning message')
- logging.error('error message')
- logging.critical('critical message')
-
-
- if __name__ == '__main__':
- tl = TestLogging()
结果:
3.4 re模块
在爬虫中,这个模块使用频率不高,稍作了解即可。
re模块主要用于查找、定位等。正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
常用正则表达式符号和语法:
'.' 匹配所有字符串,除\n以外
‘-’ 表示范围[0-9]
'*' 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。
'+' 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+
'^' 匹配字符串开头
‘$’ 匹配字符串结尾 re
'\' 转义字符, 使后一个字符改变原来的意思,如果字符串中有字符*需要匹配,可以\*或者字符集[*] re.findall(r'3\*','3*ds')结['3*']
'*' 匹配前面的字符0次或多次 re.findall("ab*","cabc3abcbbac")结果:['ab', 'ab', 'a']
‘?’ 匹配前一个字符串0次或1次 re.findall('ab?','abcabcabcadf')结果['ab', 'ab', 'ab', 'a']
'{m}' 匹配前一个字符m次 re.findall('cb{1}','bchbchcbfbcbb')结果['cb', 'cb']
'{n,m}' 匹配前一个字符n到m次 re.findall('cb{2,3}','bchbchcbfbcbb')结果['cbb']
'\d' 匹配数字,等于[0-9] re.findall('\d','电话:10086')结果['1', '0', '0', '8', '6']
'\D' 匹配非数字,等于[^0-9] re.findall('\D','电话:10086')结果['电', '话', ':']
'\w' 匹配字母和数字,等于[A-Za-z0-9] re.findall('\w','alex123,./;;;')结果['a', 'l', 'e', 'x', '1', '2', '3']
'\W' 匹配非英文字母和数字,等于[^A-Za-z0-9] re.findall('\W','alex123,./;;;')结果[',', '.', '/', ';', ';', ';']
'\s' 匹配空白字符 re.findall('\s','3*ds \t\n')结果[' ', '\t', '\n']
'\S' 匹配非空白字符 re.findall('\s','3*ds \t\n')结果['3', '*', 'd', 's']
'\A' 匹配字符串开头
'\Z' 匹配字符串结尾
'\b' 匹配单词的词首和词尾,单词被定义为一个字母数字序列,因此词尾是用空白符或非字母数字符来表示的
'\B' 与\b相反,只在当前位置不在单词边界时匹配
'(?P<name>...)' 分组,除了原有编号外在指定一个额外的别名 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{8})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '19930614'}
[] 是定义匹配的字符范围。比如 [a-zA-Z0-9] 表示相应位置的字符要匹配英文字符和数字。[\s*]表示空格或者*号。
常用的re模块方法参考:Python3 正则表达式 | 菜鸟教程 (runoob.com)
re.compile(pattern,flag=0) 将字符串形式的正则表达式编译为Pattern对象
re.search(string[,pose[,endpos]]) 从string的任意位置开始匹配
re.match(string[,pose[,endpos]]) 从string的开头开始匹配
re.findall(string[,pose[,endpos]]) 从string的任意位置开始匹配,返回一个列表
re.finditer(string[,pose[,endpos]]) 从string的任意位置开始匹配,返回一个迭代器
一般匹配findall即可,大数量用finditer比较好。

re模块+urllib2模块爬虫实例:爬取某影院当日播放的电影
步骤:找一个电影院的网页http://www.wandacinemas.com/;
使用urllib2模块抓取整个网页;使用re模块获取影视信息。
- #!/usr/bin/env python
- #-*- coding: utf-8 -*-
- __author__ = 'hstking hstking@hotmail.com'
-
- import re
- import urllib.request
- import codecs
- import time
-
- class Todaymovie(object):
- '''获取金逸影院当日影视'''
- def __init__(self):
- self.url = 'http://www.wandacinemas.com/'
- self.timeout = 5
- self.fileName = 'wandaMovie.txt'
- '''内部变量定义完毕 '''
- self.getmovieInfo()
-
- def getmovieInfo(self):
- response = urllib.request.urlopen(self.url,timeout=self.timeout)
- result = response.read().decode('utf-8')
- with codecs.open('movie.txt','w','utf-8') as fp1:#将请求返回的信息保存到'movie.txt'
- fp1.write(result)
- pattern = re.compile('<span class="icon_play" title=".*?">')
- movieList = pattern.findall(result)
- print("movielist:",movieList)#输出电影列表
- movieTitleList = map(lambda x:x.split('"')[3], movieList)
- #使用map过滤出电影标题
- with codecs.open(self.fileName, 'w', 'utf-8') as fp:
- print("Today is %s \r\n" %time.strftime("%Y-%m-%d"))
- fp.write("Today is %s \r\n" %time.strftime("%Y-%m-%d"))
- for movie in movieTitleList:
- print("%s\r\n" %movie)
- fp.write("%s \r\n" %movie)#将过滤的电影标题保存到'wandaMovie.txt'
-
-
- if __name__ == '__main__':
- tm = Todaymovie()
程序分析:
1.response = urllib.request.urlopen(self.url,timeout=self.timeout)发出请求,urlopen的参数在初始化中已经给出。2.result = response.read().decode('utf-8')读取响应
3.pattern = re.compile('<span class="icon_play" title=".*?">')
movieList = pattern.findall(result)构建正则表达式,匹配电影名称信息,返回匹配上的标签列表。
4.movieTitleList = map(lambda x:x.split('"')[3], movieList)
使用map过滤出电影标题。map() 会根据提供的函数对指定序列做映射。语法:map(function, iterable, ...)。第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
5.python codes open()
(14条消息) python中open()与codecs.open()的区别_白清羽的博客-CSDN博客
运行发现没有过滤出电影名称,于是加了
#将请求返回的信息保存到'movie.txt',#输出电影列表,这两个语句,发现抓取网页正常,电影列表为空,所有怀疑是正则的问题。pattern = re.compile('<span class="icon_play" title=".*?">')
分析这个正则表达式:
# .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符
# (.*?) 表示"非贪婪"模式,只保存第一个匹配到的子串
<span class="icon_play" title=".*?">应该是网页文件里的一个标签,
(14条消息) 网页结构(<div>、<span>标签)_拾Miss~博客-CSDN博客
查阅得知,span是一个行标签,而搜索发现网页内容里完全没有行标签,更别说匹配了。自然
movieList是空的列表。暂时不会解决,正则用起来真的好复杂,希望有大佬看到的话指点一下。
3.5 其他有用模块
3.5.1 sys模块
跟系统有关的模块,作用:返回系统信息。常用的方法只有两个sys.a和sys.exit。
sys.argv返回一个包含所有的命令行参数的列表,sys.exit退出程序。
3.5.2 Time模块
python的学习笔记之——time模块常用内置函数 - 爬虫上的雪碧 - 博客园 (cnblogs.com)



