
- 1启英泰伦离线自然说:让语音交互更“顺口”
- 2基于Android studio校园信息查询系统_安卓按学生院系查询
- 3pygame 图像--键盘上下左右
- 4Unity3d C# 实现滑动条(Slider)的拖拽开始和结束、点击等事件的拓展功能(含源码)_u3d slider点击拖拽弹出提示
- 5Element Plus 实例详解(一)___安装设置_element-plus
- 6ChatGPT在数据分析学习阶段的应用
- 7ParadigmCTF_2022_MarkleDrop_ctf merkle tree
- 8PointNet:利用深度学习对点云进行3D分类和语义分割_pointnet可以使用semantic3d数据集嘛
- 9【服务器Midjourney】创建部署Midjourney网站_midjourney 云服务器搭建
- 10Python turtle绘制——壬寅(虎)年祝福_用海龟画图制作一张新年贺卡
深度学习(自监督:SimCLR)——A Simple Framework for Contrastive Learning of Visual Representations_nonlinear projection head
赞
踩
前言
该文章是Hinton和Google发表在2020 ICML上的一篇自监督文章。
代码地址: https://github.com/google-research/simclr
其实看文章的时候就闻到味了,一定是Google家的作品,实验数据非常详细,替我们探索了对比学习所具有的一些特性。
本文将对SimCLR做一个简述,并且简单记录其中比较有意思的实验。
SimCLR简述
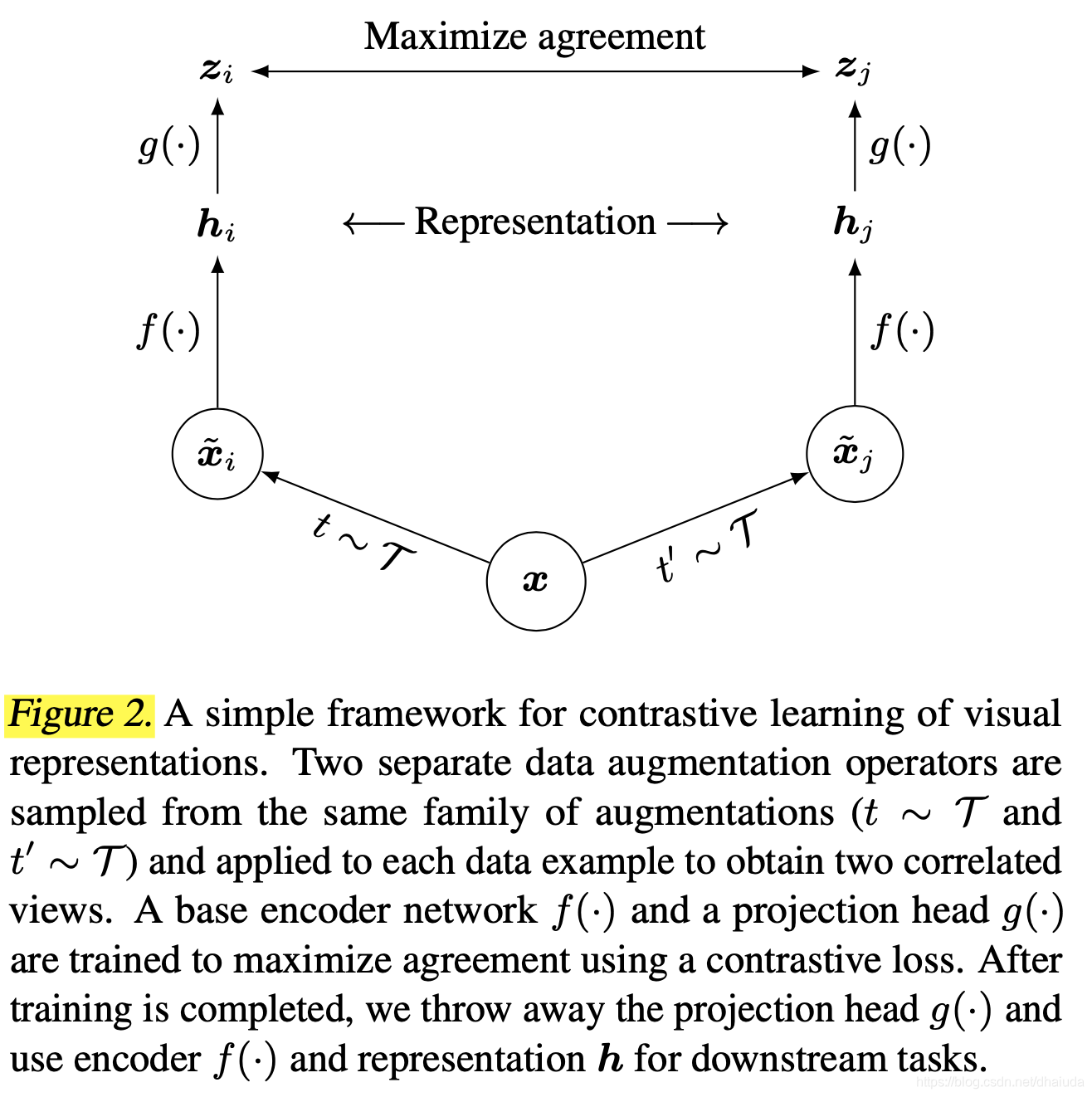
上图为SimCLR的模型结构,具体流程为
- 对一个输入图像 x x x施加两种不同的数据增强,得到两张图片 x i ~ \tilde{x_i} xi~、 x j ~ \tilde{x_j} xj~
- 将两张图片输入到一个CNN网络 f ( x ) f(x) f(x)提取特征,得到 h i h_i hi、 h j h_j hj两个feature vector
- 两个feature vector经过一个MLP网络 g ( x ) g(x) g(x)处理,得到 z i z_i zi、 z j z_j zj
假设batch size大小为 N N N,经过数据增强,可以得到 2 N 2N 2N张图像,SimCLR在对比学习时,需要正负例。
对图片
x
x
x施加两种不同的数据增强,得到
x
i
~
\tilde{x_i}
xi~、
x
j
~
\tilde{x_j}
xj~,经过CNN、MLP处理后得到
z
i
z_i
zi、
z
j
z_j
zj,
z
i
z_i
zi与
z
j
z_j
zj构成一个正例对,
z
i
z_i
zi与batch size中其他图像(包括数据增强后的图像)的feature vector组成负例对,因此一张图片将存在1个正例对,
2
N
−
2
2N-2
2N−2个负例对。一张图片的损失函数为
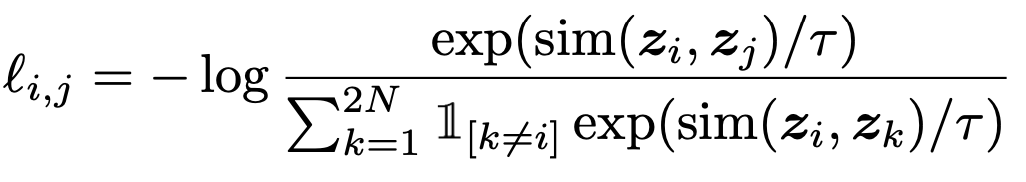
s
i
m
(
z
i
,
z
j
)
sim(z_i,z_j)
sim(zi,zj)表示计算两个向量的余弦相似度,
T
T
T为超参数,
2
N
2N
2N张图像的损失函数之和求平均,得到最终的损失函数,其实就是在进行
2
N
−
1
2N-1
2N−1的分类
算法伪代码

实验
实验部分有很多有价值的部分,本篇论文探究了一些trick对SimCLR的影响,并给出了一些结论
除非特别提及,本节的所有实验结果都是使用SimCLR在ImageNet1000上预训练一个ResNet-50,接着freeze特征提取器,接入一个线性分类器进行训练,训练完毕后模型在ImageNet1000测试集上的准确率。
数据增强对性能的影响
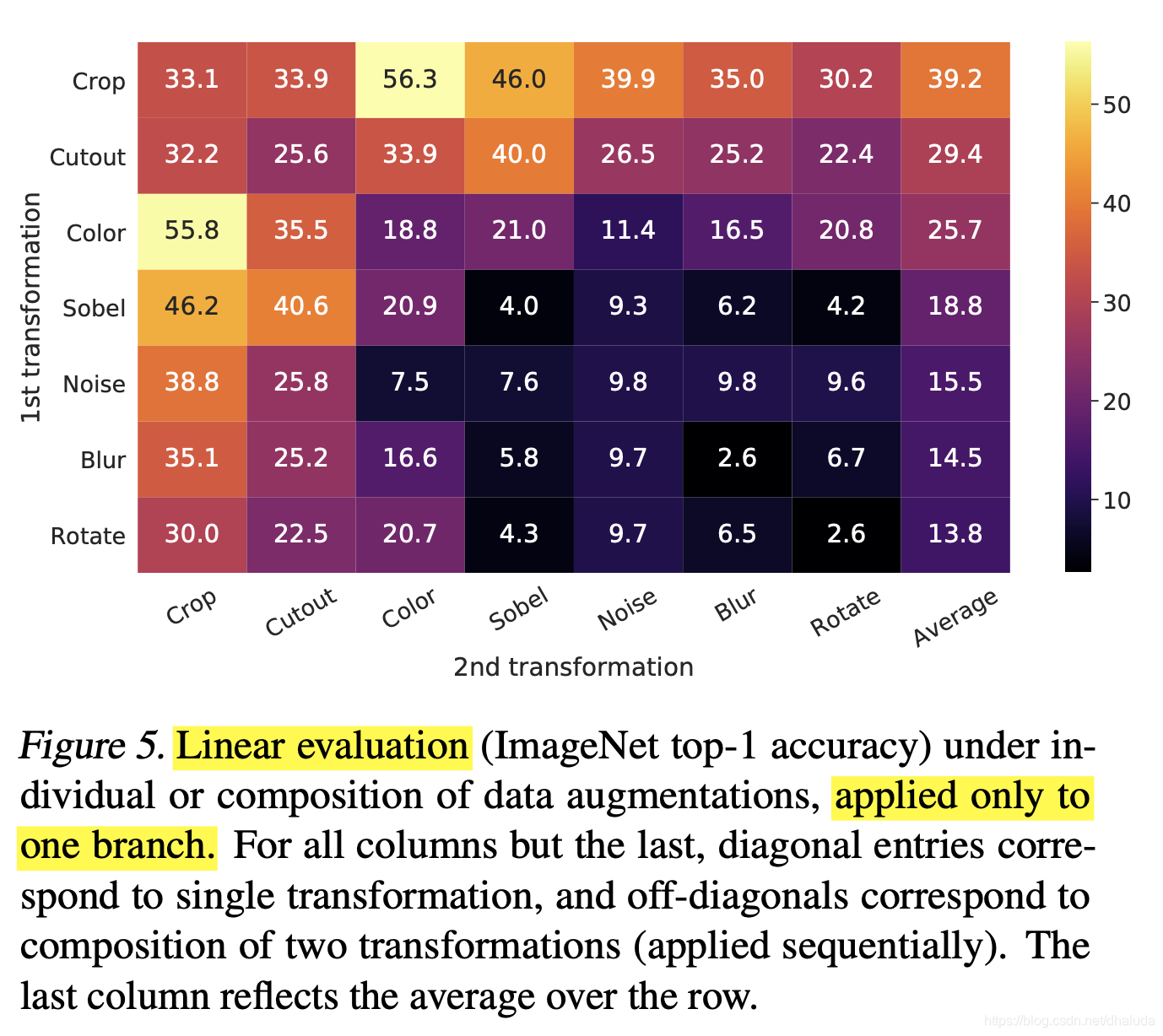
上图的含义请见英文,主要可以得出三个结论
- 单独使用一种数据增强,对比学习的效果会很差
- random cropping与random color distortion进行组合效果最好
- 数据增强对对比学习的影响非常明显,这不是一个好的性质,很多时候我们需要进行穷举试错
Unsupervised contrastive learning benefits (more) from bigger models
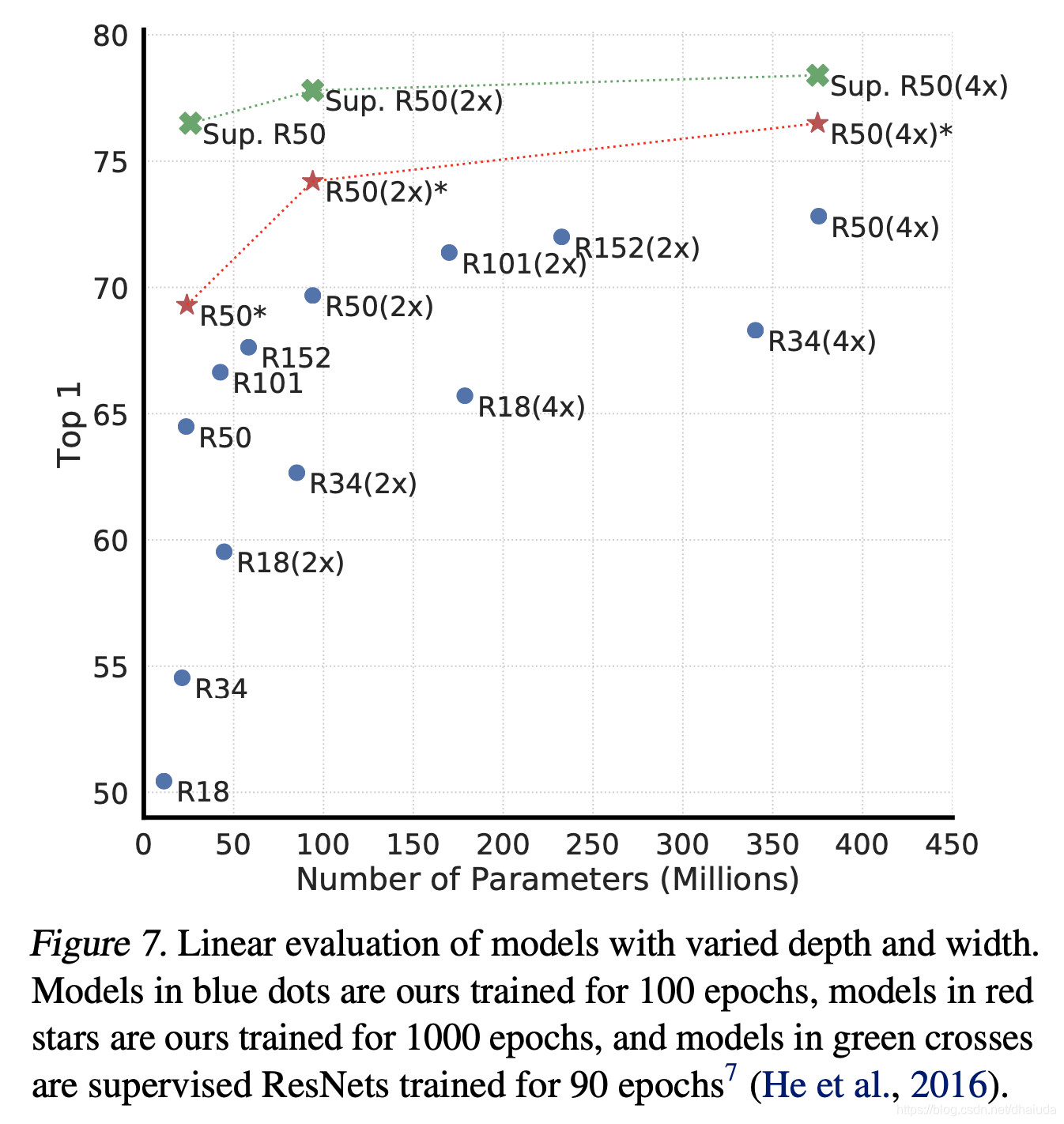
上图给出了图像加宽和加深对模型性能的影响,R18(2x)表示ResNet18加宽两倍,其他符号以此类推。
观察上图,个人有以下结论
- 增大模型容量时,首先考虑加深,ResNet152的性能与ResNet18高不少,并且参数量没有上升特别多,加深网络是实践时的首选
- 深度足够,再来考虑宽度,此时参数量会暴涨,可能训练速度会慢不少,加宽网络是实践时的次优选
A nonlinear projection head improves the representation quality of the layer before it
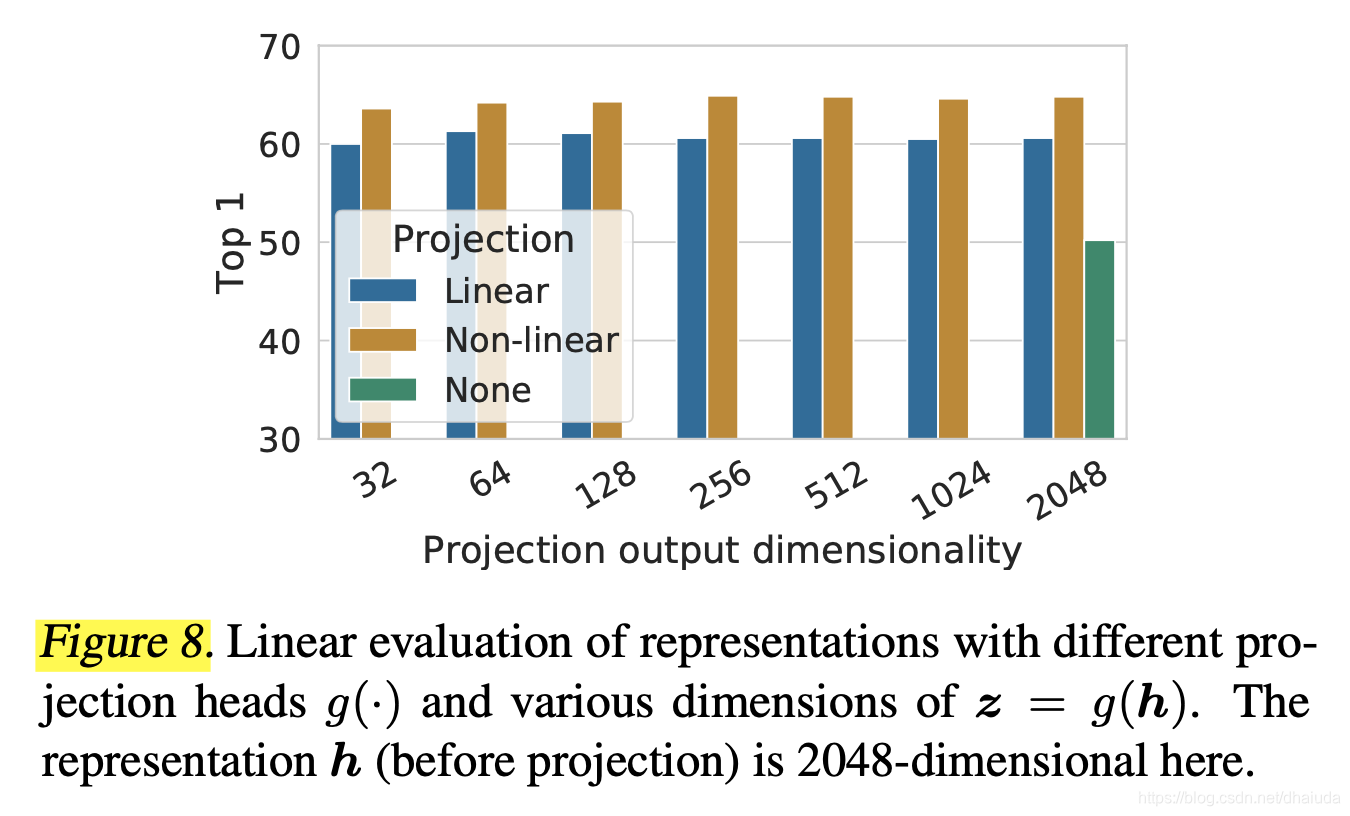
上图探究了
z
z
z的维度对模型线性分类性能的影响,
z
z
z的含义见SimCLR简述一节,可见
z
z
z的维度对模型性能影响不大,并且非线性MLP性能要优于线性MLP,这点在MoCo v2中也得到了验证。
SimCLR中可以用于线性分类的特征有两个,一是特征提取器的输出 h h h,二是MLP层的输出 g ( h ) g(h) g(h)(两者含义见SimCLR简述一节),在线性分类中,使用 h h h的性能要优于 g ( h ) g(h) g(h)(大于10%),可能是因为MLP过滤掉了一些有用的信息
Contrastive learning benefits (more) from larger batch sizes and longer training
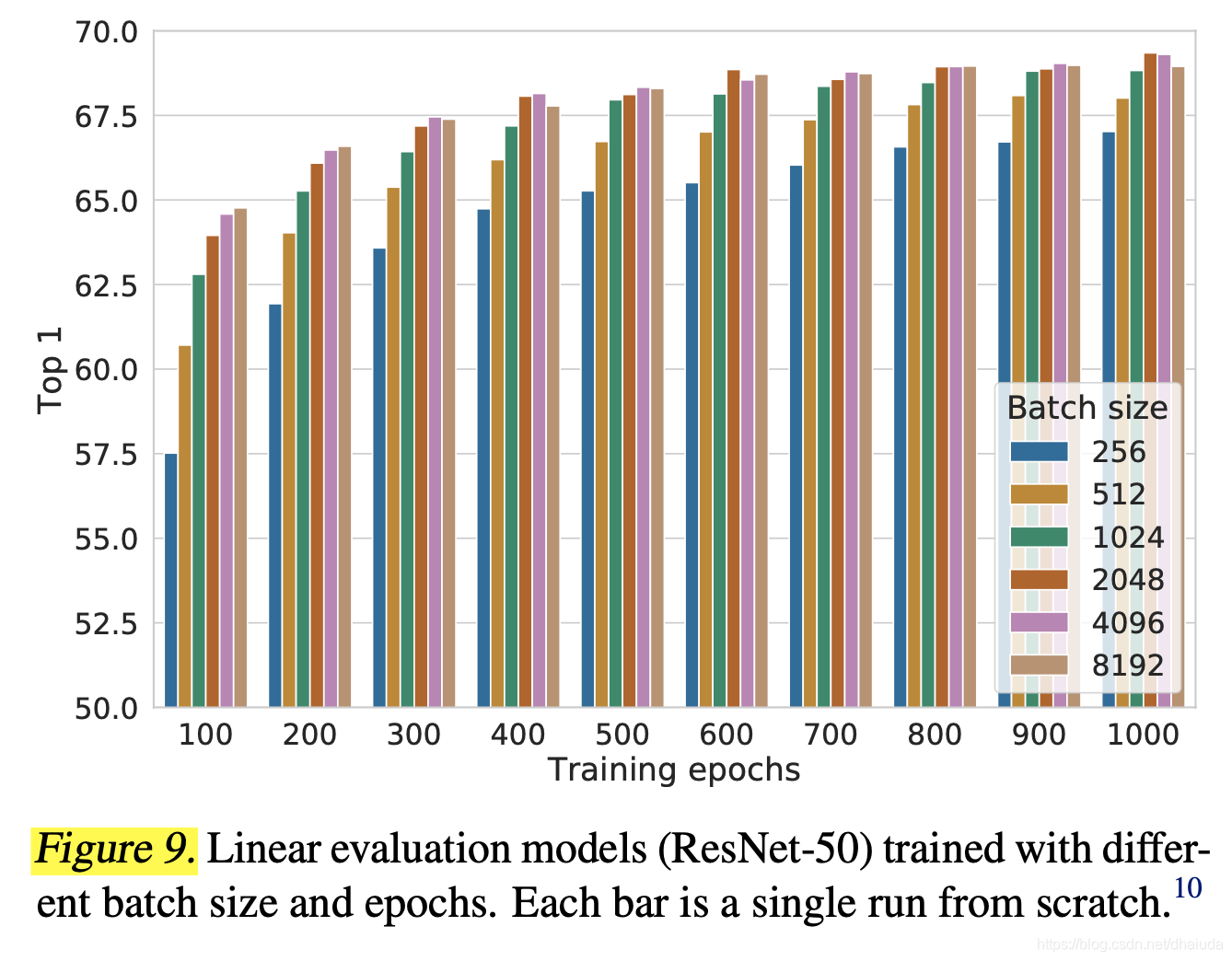
上图可以得出的结论有两个,对于使用负例的对比学习算法而言
- batch size越大,效果越好,并且提升显著,但是对于只使用正例的对比学习算法而言(例如BYOL、simsiam),batch size大小对性能影响没有如此显著
- 训练epoch越长,效果越好,这点对于只使用正例的对比学习算法而言也一样

