
- 1挑战杯 python的搜索引擎系统设计与实现
- 2Unity性能优化系列—加载与资源管理_uwa unity性能优化系列—加载与资源管理
- 3windows搭建ftp,且设置用户_ftp添加用户
- 4el-select数据过多的解决(纯前端)_elementui select数据过多
- 5(十七)unity shader之——————高级纹理之程序纹理_unity shader程序化纹理
- 6UE4 WebUI插件使用指南_ue webui
- 7element表单中一个el-form-item下多个form-item项校验(循环校验)_一个 el-form-item 下多个表单校验(循环校验)
- 8ES集群部署
- 9Caffe版Faster R-CNN可视化——网络模型,图像特征,Loss图,PR曲线
- 10WPF ObservableCollection<T>_observablecollection wpf 单个对象
一键安装langchain-ChatGLM
赞
踩
框架已经更新,autodl策略也变了,请看最新文章:一键安装Langchain-chatchat
最近开源大模型层出不穷,非常火爆。好多小伙伴跃跃欲试,但是,大模型本地搭建,就算是只做推理也需要性能强悍的机器,更不要说微调和全参数训练,没有几十万的显卡投入是搞不定的。chatGLM推理可以在cpu上运行,但是不建议,速度很慢。6b模型建议12G显卡,最好16G以上(int4好像只要6G)。市面上,16G显存的显卡大概1w左右。24G大概1w5左右。如果不是专门做模型的人,不建议去购买,不过买来玩3A大作是挺好的,哈哈。算法小白建议租显卡,简单体验一下就行。市面上好多算力平台,大家可能对比一下价格,根据自身需要选择,我这里用的是autoDL。
一、注册
先去AutoDL-品质GPU租用平台-租GPU就上AutoDL 官网注册账号,然后实名认证,不然你无法用浏览器访问你的服务网址。
autodl相对比较便宜,按流量计费。28G显卡大概1.18元/小时,如果认证学生好像有免费时间,听说好多学生党用它做毕设。
二、选服务器
和其他云服务页面比较像,听说显卡需要抢(不建议社畜去抢,影响人家穷学生毕业就不好了),选择需要的型号,如果()是0,就是没有了。
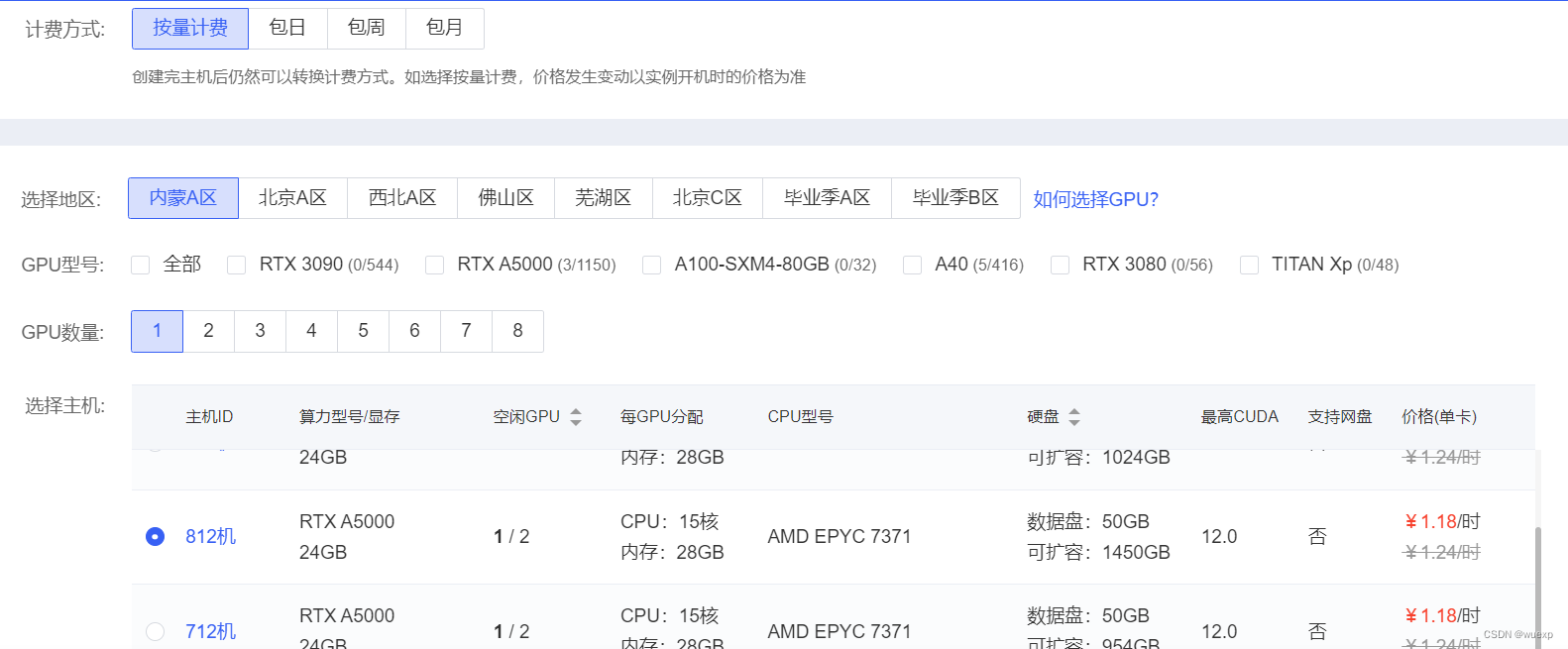
这里有个非常方便的功能,可以选择一些社区镜像,直接用,不用复杂的配置,很方便。也可以用基础镜像,默认安装了一些工具,也可以把自己安装好的服务做成镜像。
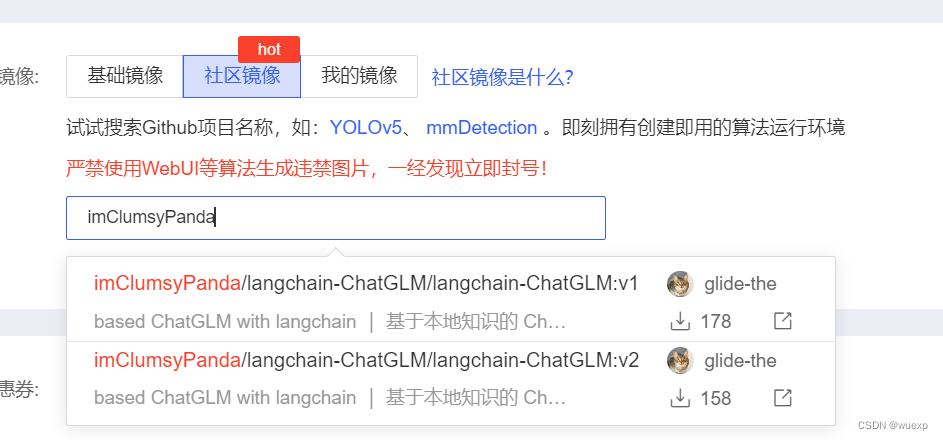
选好镜像以后,点击“立即创建”按钮就行了。
三、启动登录服务
启动完以后,就可以登录服务器了。根据自己的习惯选择链接方式,最简单是用它自带jupyterlab 网页版本,很方便上传下载文件。我习惯用secureCRT,复制ssh登录命令就行。
这里注意,secureCRT必须是8.0以上,不然不支持。

然后在终端执行三条命令,非常简单:(不懂什么意思的,查一下吧,很简单)
$cd /root/langchain-ChatGLM/
$conda activate /root/pyenv
$python webui.py
执行最后一条命令,看到下图的提示,就代表启动成功了!
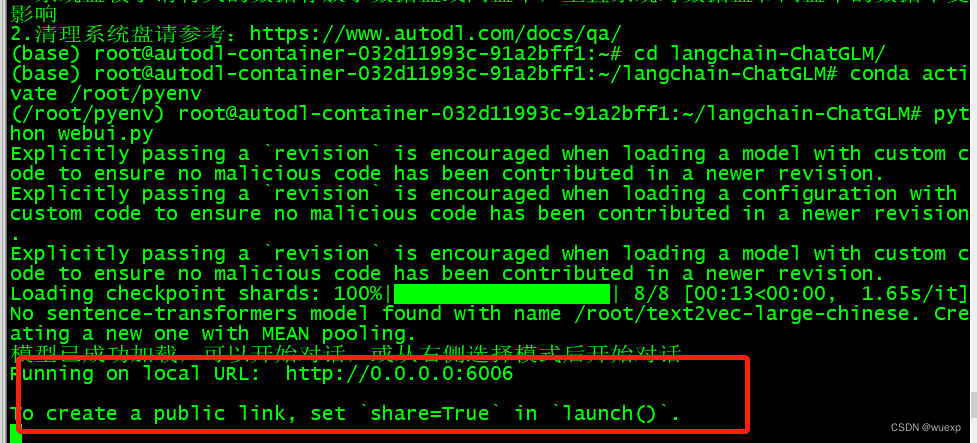
最后,点击“自定义服务”,自动跳到浏览器,就可以在浏览器里体验自己安装的大模型了。
四、使用
1.可以直在右侧选择llm对话,这样就是训练好的模型,体验还不错。顺便调戏一下,哈哈。
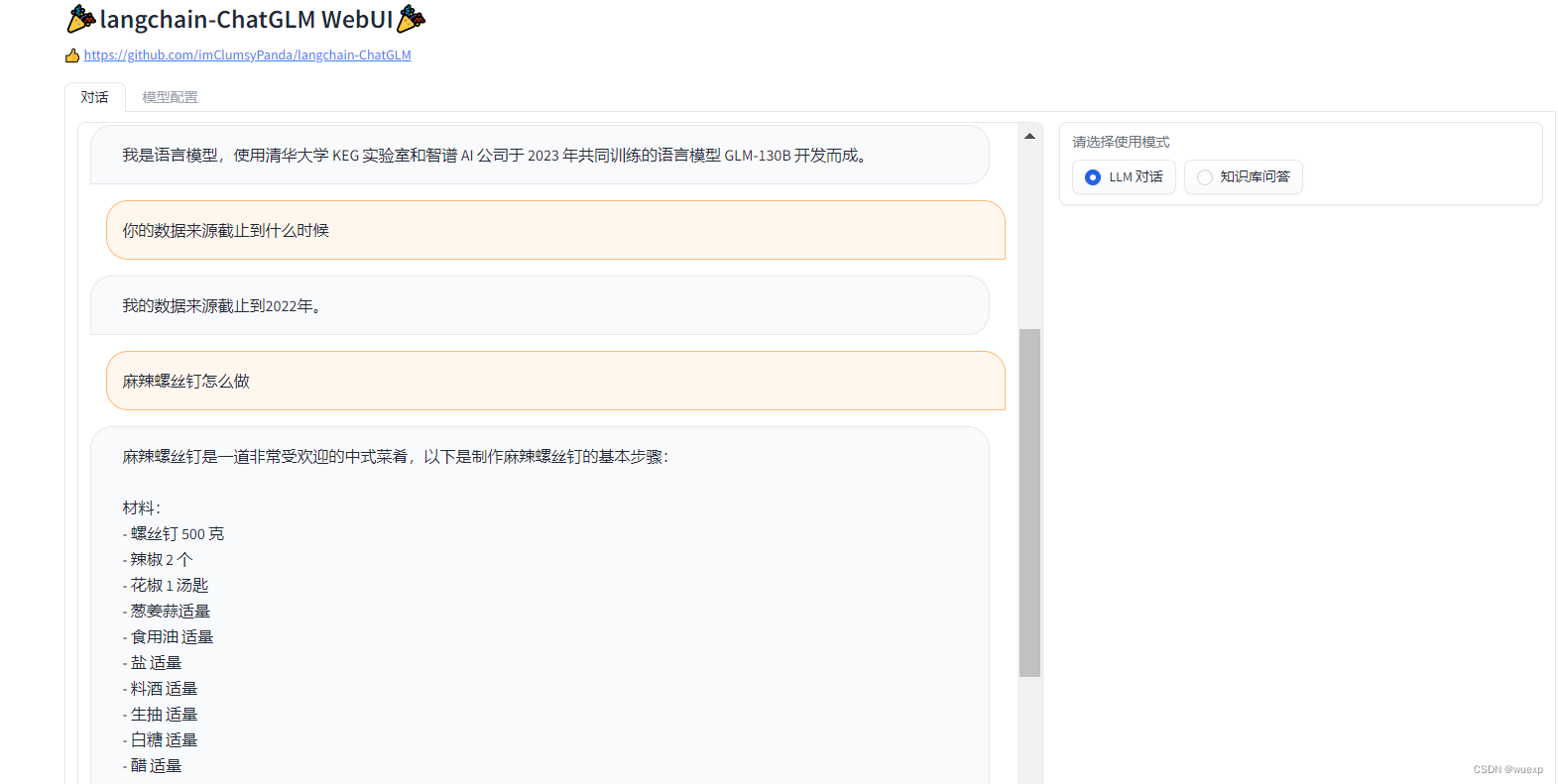
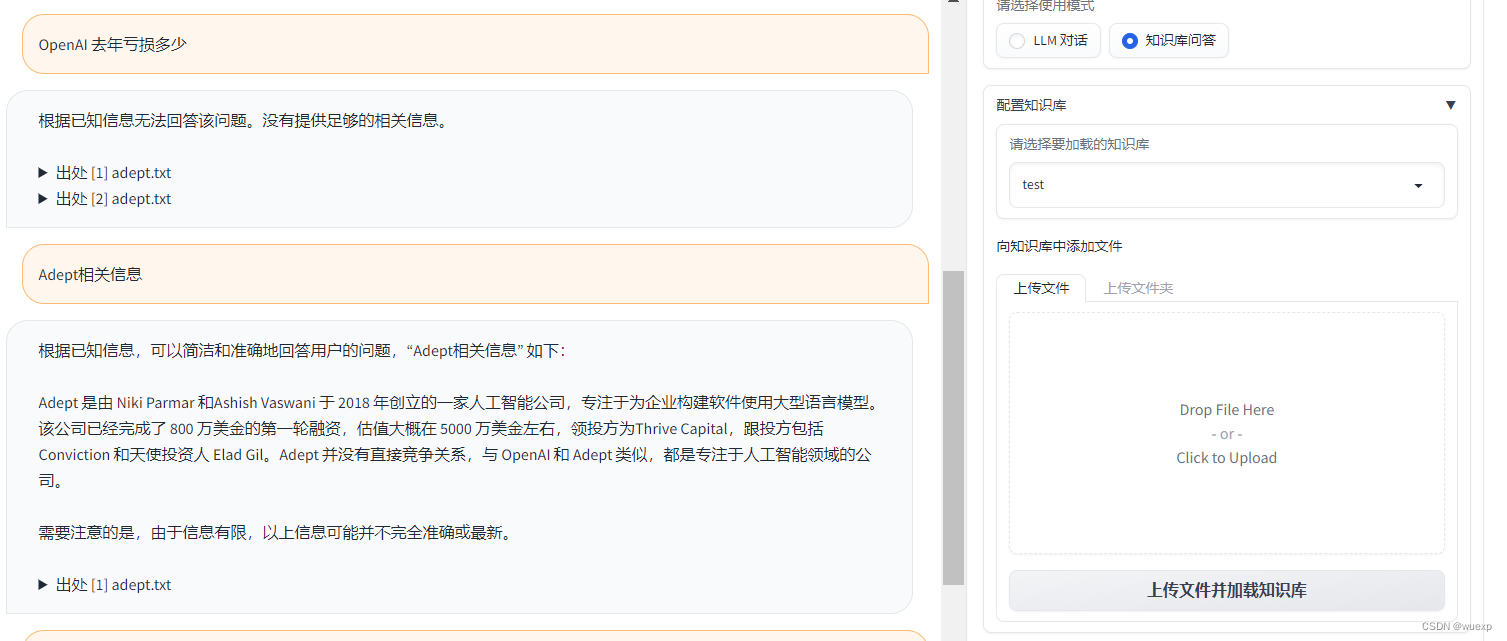
2.还可以自建知识库问答,自己上传md、pdf、docx、txt。注意文件编码最好是utf-8,文件英文名,不然会处理不了。
自己上传了txt和pdf文档,体验了一下,效果一般,可能我给的文档质量不好,这方面功能还有待完善。
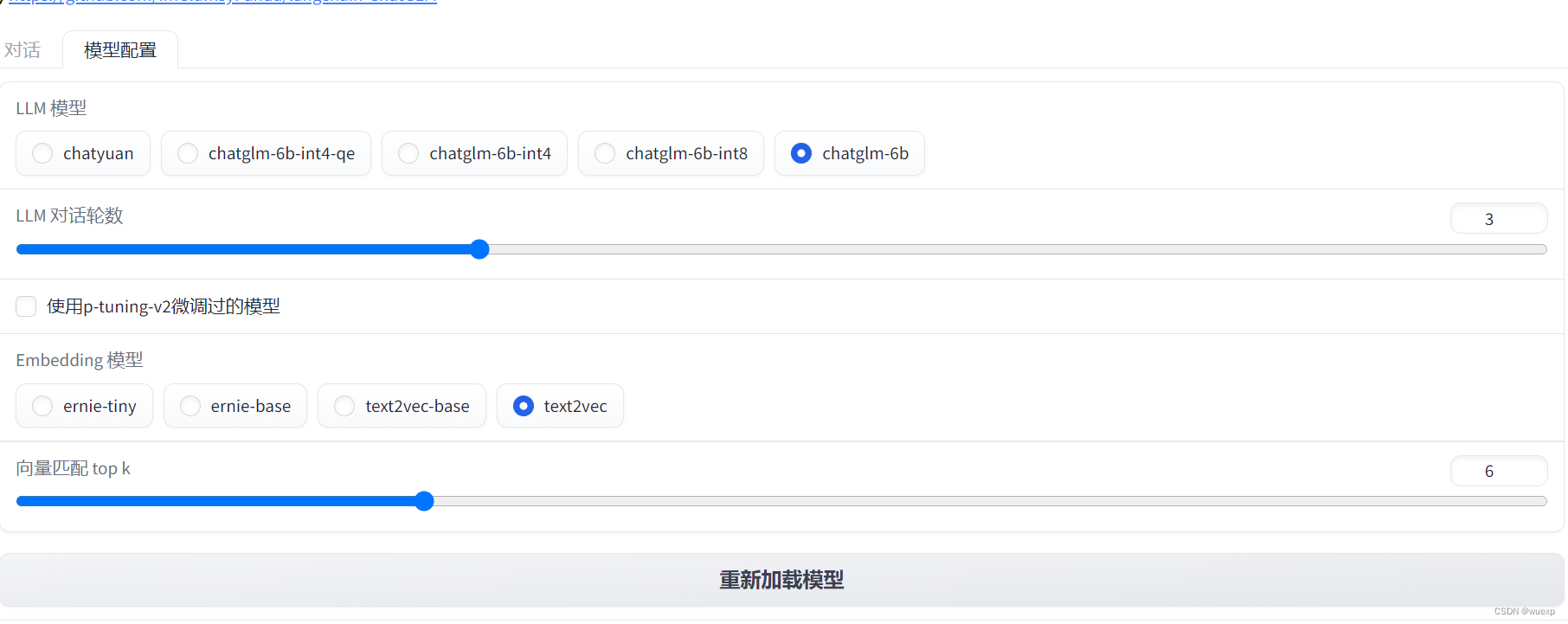
3.在页面上还可以选择模型来加载,有五种,但是一定要留出足够的硬盘空间,换模型,原模型数据不会删。
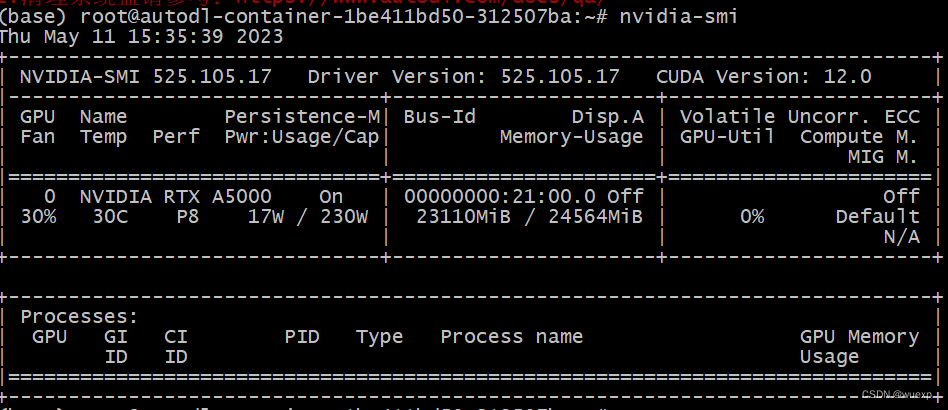
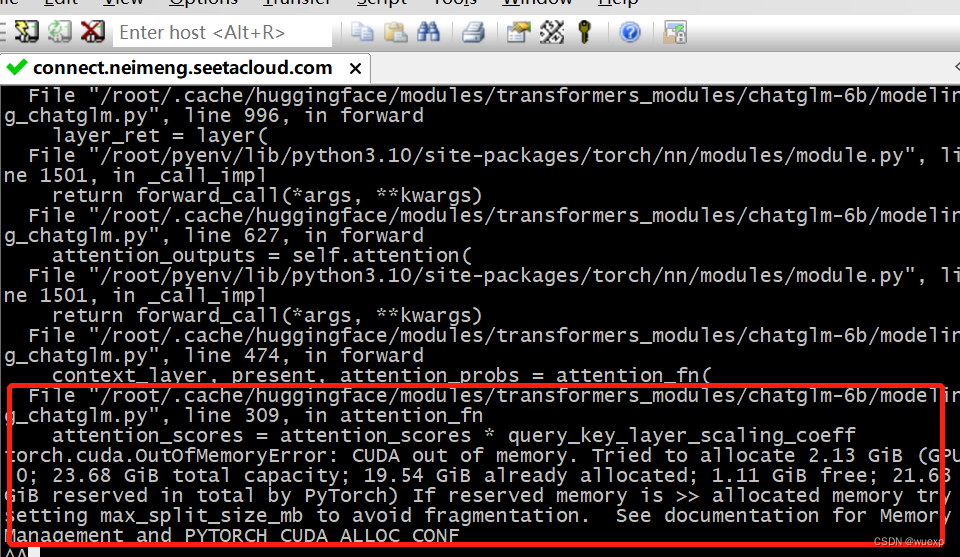
模型在推理的时候,特别是在知识库问答,有时候GPU的内存利用率会达到99%了,有时候会突然显存爆了,建议还是人工处理一下文档。
总结:
这篇文章只是简单安装,好多地方需要调研优化,感兴趣的可以去官网看看。官方每天都在更新代码,修改bug,不断完善。
一直认为训练费钱,没想到推理也不便宜,我没做压力测试,估计一台机器支持不了几个人并发用。
一些其它问题:
1.如何更新chatglm模型文件
/root/model/删除 chatglm-6b文件夹
/root/autodl-tmp/下面重新clone
成功之后复制到 /root/model下面
2.如何更新仓库代码(因为直接使用的镜像,代码比较老,有一些bug)
$cd /root/langchain-ChatGLM/
$rm -rf ~/.gitconfig
$git pull
删除冲突文件
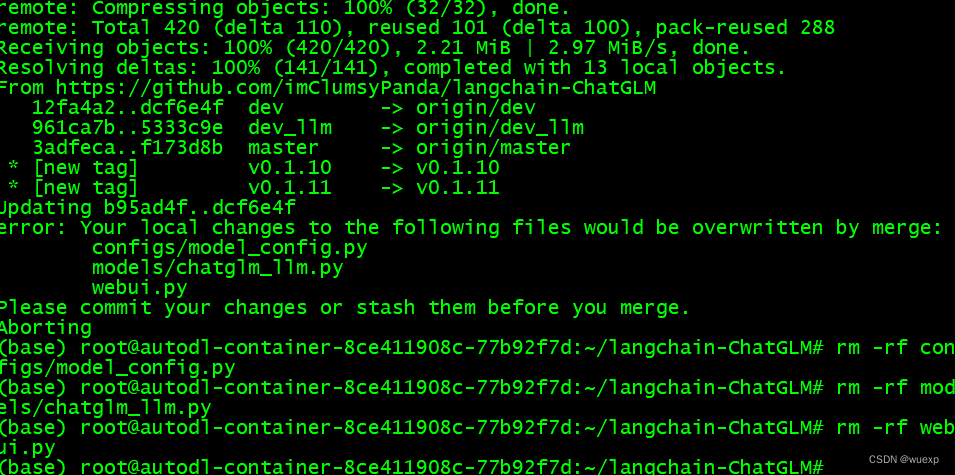
再次执行git pull
更新虚拟环境依赖,注意必须切换到虚拟环境里
$conda activate /root/pyenv
$pip install -r requirements.txt
修改配置文件
修改web.py文件,这个端口是autodl启动服务里的端口
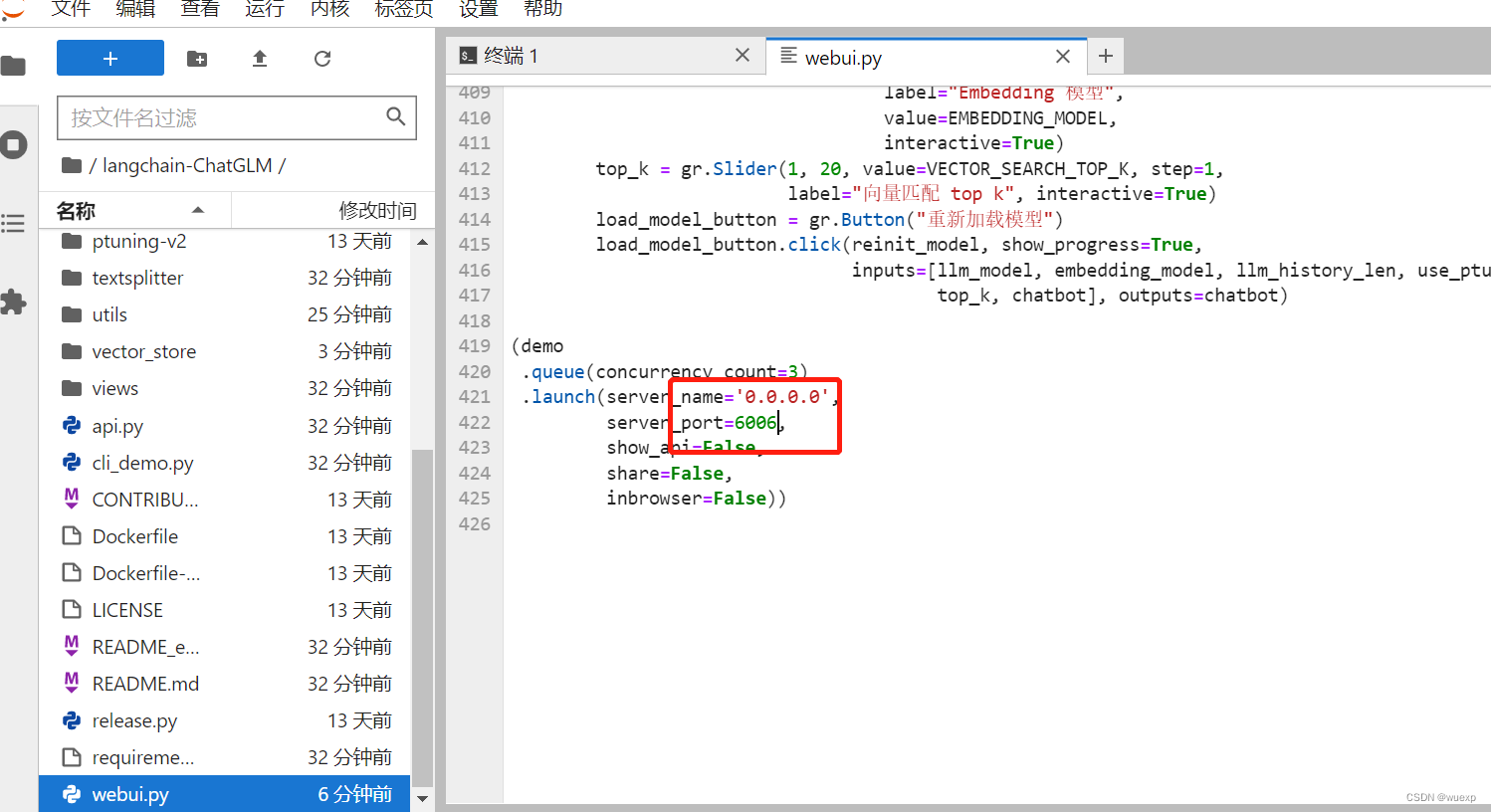
修改langchain-ChatGLM/configs/model_config.py文件里两个路径,服务器模型文件路径,如果不修改,启动web.py会重新下载模型文件,磁盘会爆炸。
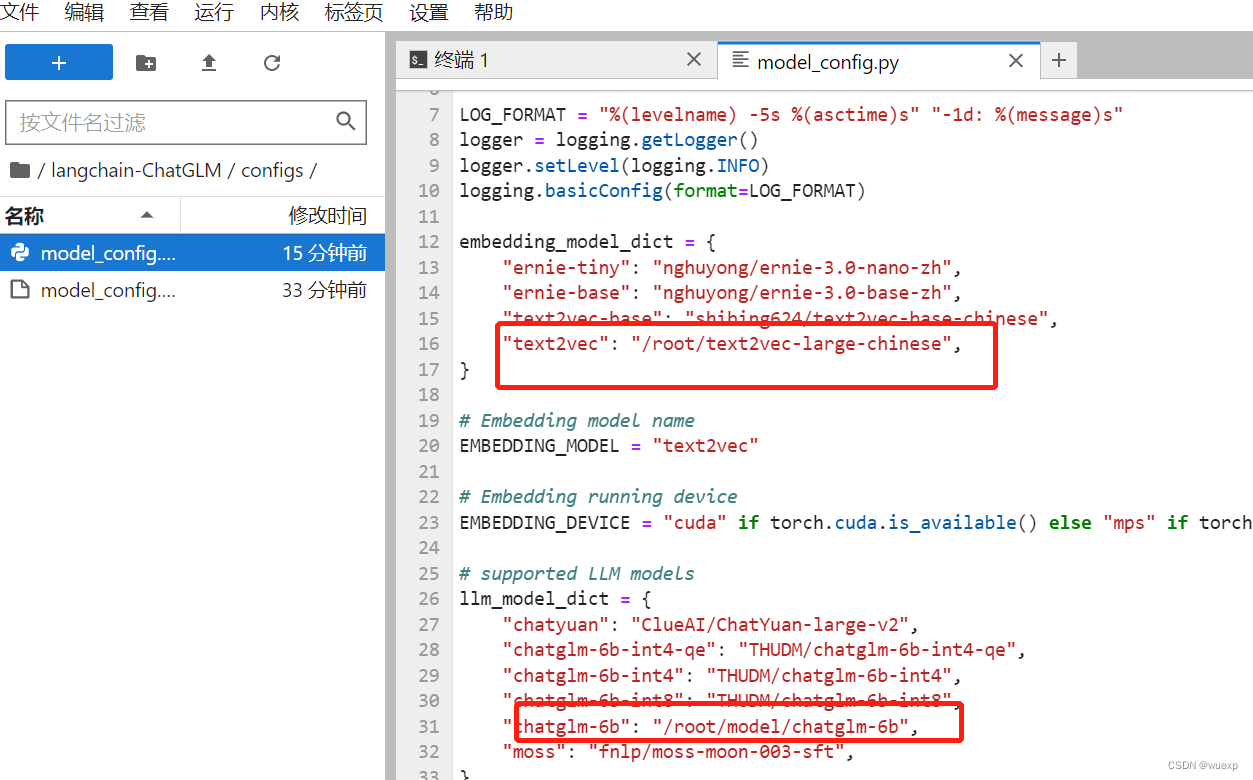
重新启动web.py就可以了。
官方配置说明:
模型官网:

