
- 1Win11系统提示无法连接到你的组织的激活服务器怎么解决?_win11无法连接到你的组织的激活服务器
- 2Node.js基础---加载机制
- 3Window10上Tensorflow2.3的安装,CPU和GPU版本_tensorflow选择gpu还是cpu
- 4面试题之会议安排
- 5Ubuntu18.04新手架设网站全过程_ubuntu设计网页
- 6在.NET中如何优雅地调优ThreadPool_.net threadpool[23727]: segfault at
- 7linux 搭建emby+clouddrive+115云盘 家庭影院解决方案 流媒体_ubuntu emby clouddrive
- 8Fast RCNN算法详解_fast rcnn csdn
- 9[云原生] K8S声明式资源管理
- 10Kafka—工作流程、如何保证消息可靠性_springboot kafka 消息可靠性
【LangChain学习之旅】—(7) 调用模型:使用OpenAI API还是微调开源Llama2/ChatGLM?_langchain调用本地大模型
赞
踩
之前的内容讲了提示工程的原理以及 LangChain 中的具体使用方式。今天,我们来着重讨论 Model I/O 中的第二个子模块,LLM。
让我们带着下面的问题来开始这一节课的学习。大语言模型,不止 ChatGPT 一种。调用 OpenAI 的 API,当然方便且高效,不过,如果我就是想用其他的模型(比如说开源的 Llama2 或者 ChatGLM),该怎么做?再进一步,如果我就是想在本机上从头训练出来一个新模型,然后在 LangChain 中使用自己的模型,又该怎么做?
关于大模型的微调(或称精调)、预训练、重新训练、乃至从头训练,这是一个相当大的话题,不仅仅需要足够的知识和经验,还需要大量的语料数据、GPU 硬件和强大的工程能力。别说一节课了,我想两三个专栏也不一定能讲全讲透。不过,我可以提纲挈领地把大模型的训练流程和使用方法给你缕一缕。这样你就能体验到,在 LangChain 中使用自己微调的模型是完全没问题的。
大语言模型发展史
说到语言模型,我们不妨先从其发展史中去了解一些关键信息。
Google 2018 年的论文名篇 Attention is all you need,提出了 Transformer 架构,也给这一次 AI 的腾飞点了火。Transformer 是几乎所有预训练模型的核心底层架构。基于 Transformer 预训练所得的大规模语言模型也被叫做“基础模型”(Foundation Model 或 Base Model)。
在这个过程中,模型学习了词汇、语法、句子结构以及上下文信息等丰富的语言知识。这种在大量数据上学到的知识,为后续的下游任务(如情感分析、文本分类、命名实体识别、问答系统等)提供了一个通用的、丰富的语言表示基础,为解决许多复杂的 NLP 问题提供了可能。
在预训练模型出现的早期,BERT 毫无疑问是最具代表性的,也是影响力最大的模型。BERT 通过同时学习文本的前向和后向上下文信息,实现对句子结构的深入理解。BERT 之后,各种大型预训练模型如雨后春笋般地涌现,自然语言处理(NLP)领域进入了一个新时代。这些模型推动了 NLP 技术的快速发展,解决了许多以前难以应对的问题,比如翻译、文本总结、聊天对话等等,提供了强大的工具。
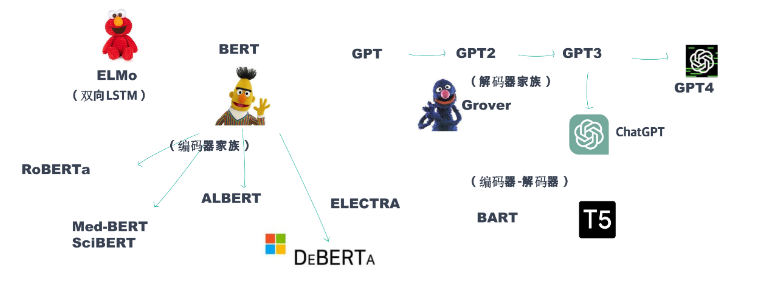
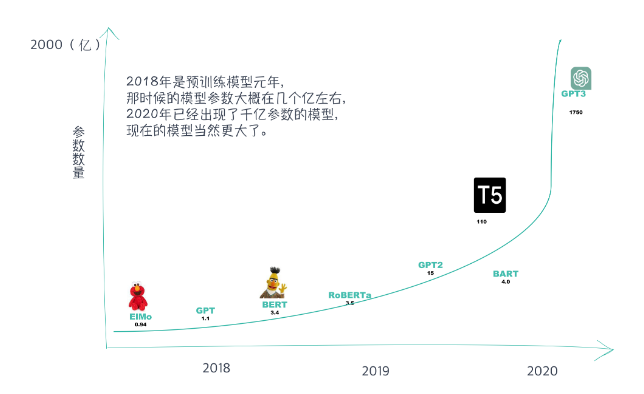
当然,现今的预训练模型的趋势是参数越来越多,模型也越来越大,训练一次的费用可达几百万美元。这样大的开销和资源的耗费,只有世界顶级大厂才能够负担得起,普通的学术组织和高等院校很难在这个领域继续引领科技突破,这种现象开始被普通研究人员所诟病。
预训练 + 微调的模式
不过,话虽如此,大型预训练模型的确是工程师的福音。因为,经过预训练的大模型中所习得的语义信息和所蕴含的语言知识,能够非常容易地向下游任务迁移。NLP 应用人员可以对模型的头部或者部分参数根据自己的需要进行适应性的调整,这通常涉及在相对较小的有标注数据集上进行有监督学习,让模型适应特定任务的需求。
这就是对预训练模型的微调(Fine-tuning)。微调过程相比于从头训练一个模型要快得多,且需要的数据量也要少得多,这使得作为工程师的我们能够更高效地开发和部署各种 NLP 解决方案。
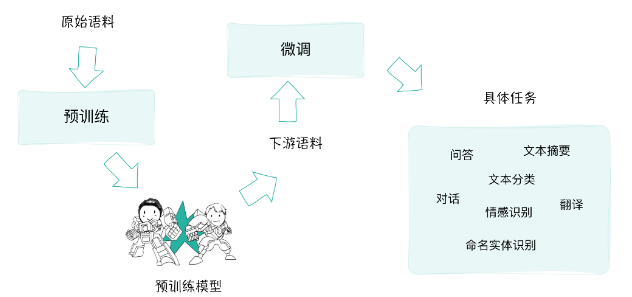
图中的“具体任务”,其实也可以更换为“具体领域”。那么总结来说:
- 预训练:在大规模无标注文本数据上进行模型的训练,目标是让模型学习自然语言的基础表达、上下文信息和语义知识,为后续任务提供一个通用的、丰富的语言表示基础。
- 微调:在预训练模型的基础上,可以根据特定的下游任务对模型进行微调。现在你经常会听到各行各业的人说:我们的优势就是领域知识嘛!我们比不过国内外大模型,我们可以拿开源模型做垂直领域嘛!做垂类模型!—— 啥叫垂类?指的其实就是根据领域数据微调开源模型这件事儿。
这种预训练 + 微调的大模型应用模式优势明显。首先,预训练模型能够将大量的通用语言知识迁移到各种下游任务上,作为应用人员,我们不需要自己寻找语料库,从头开始训练大模型,这减少了训练时间和数据需求;其次,微调过程可以快速地根据特定任务进行优化,简化了模型部署的难度;最后,预训练 + 微调的架构具有很强的可扩展性,可以方便地应用于各种自然语言处理任务,大大提高了 NLP 技术在实际应用中的可用性和普及程度,给我们带来了巨大的便利。
用 HuggingFace 跑开源模型
-
第一步,登录 HuggingFace 网站,并拿到专属于你的 Token。
-
第二步,用
pip install transformers安装 HuggingFace Library。详见这里。 -
第三步,在命令行中运行
huggingface-cli login,设置你的 API Token。
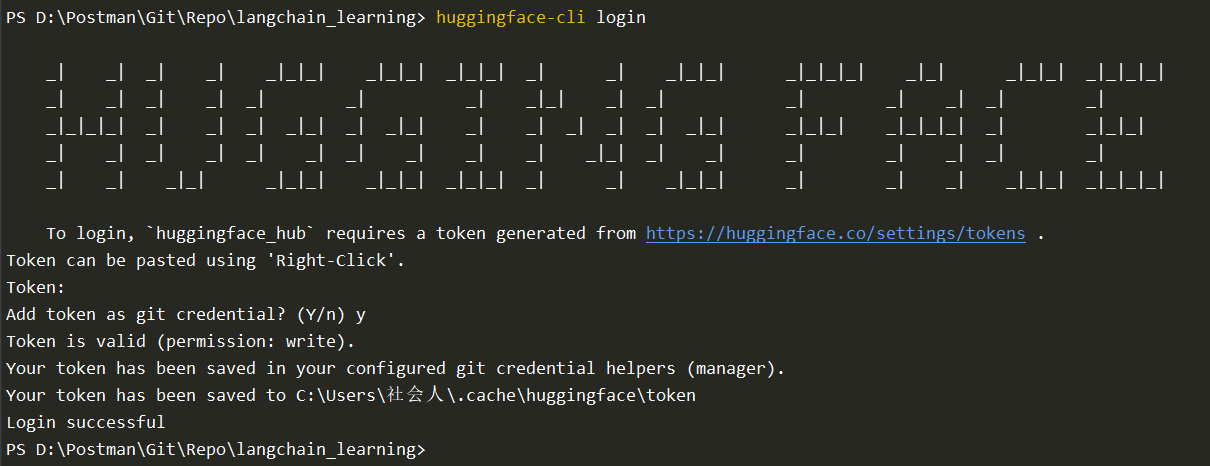
当然,也可以在程序中设置你的 API Token,但是这不如在命令行中设置来得安全。
# 导入HuggingFace API Token
import os
os.environ['HUGGINGFACEHUB_API_TOKEN'] = '你的HuggingFace API Token'
- 1
- 2
- 3
申请使用 Meta 的 Llama2 模型
在 HuggingFace 的 Model 中,找到 meta-llama/Llama-2-7b。注意,各种各样版本的 Llama2 模型多如牛毛,我们这里用的是最小的 7B 版。此外,还有 13b\70b\chat 版以及各种各样的非 Meta 官方版。
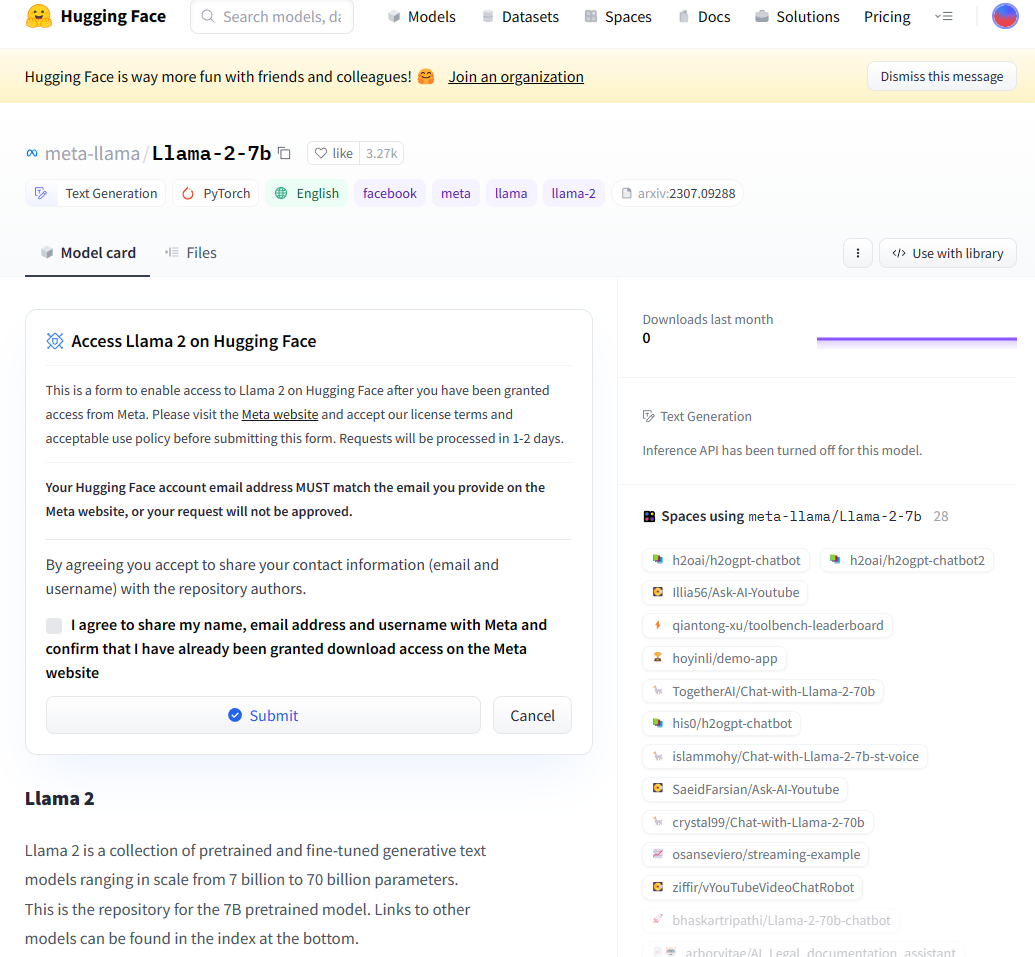
通过 HuggingFace 调用 Llama
好,万事俱备,现在我们可以使用 HuggingFace 的 Transformers 库来调用 Llama 啦!
# 导入必要的库 from transformers import AutoTokenizer, AutoModelForCausalLM # 加载预训练模型的分词器 tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf") # 加载预训练的模型 # 使用 device_map 参数将模型自动加载到可用的硬件设备上,例如GPU model = AutoModelForCausalLM.from_pretrained( "meta-llama/Llama-2-7b-chat-hf", device_map = 'auto') # 定义一个提示,希望模型基于此提示生成故事 prompt = "请给我讲个玫瑰的爱情故事?" # 使用分词器将提示转化为模型可以理解的格式,并将其移动到GPU上 inputs = tokenizer(prompt, return_tensors="pt").to("cuda") # 使用模型生成文本,设置最大生成令牌数为2000 outputs = model.generate(inputs["input_ids"], max_new_tokens=2000) # 将生成的令牌解码成文本,并跳过任何特殊的令牌,例如[CLS], [SEP]等 response = tokenizer.decode(outputs[0], skip_special_tokens=True) # 打印生成的响应 print(response)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
这段程序是一个很典型的 HuggingFace 的 Transformers 库的用例,该库提供了大量预训练的模型和相关的工具。
- 导入 AutoTokenizer:这是一个用于自动加载预训练模型的相关分词器的工具。分词器负责将文本转化为模型可以理解的数字格式。
- 导入 AutoModelForCausalLM:这是用于加载因果语言模型(用于文本生成)的工具。
- 使用
from_pretrained方法来加载预训练的分词器和模型。其中,device_map = 'auto'是为了自动地将模型加载到可用的设备上,例如 GPU。 - 然后,给定一个提示(prompt):
"请给我讲个玫瑰的爱情故事?",并使用分词器将该提示转换为模型可以接受的格式,return_tensors="pt"表示返回 PyTorch 张量。语句中的.to("cuda")是 GPU 设备格式转换,因为我在 GPU 上跑程序,不用这个的话会报错,如果你使用 CPU,可以试一下删掉它。 - 最后使用模型的
.generate()方法生成响应。max_new_tokens=2000限制生成的文本的长度。使用分词器的.decode()方法将输出的数字转化回文本,并且跳过任何特殊的标记。
LangChain 和 HuggingFace 的接口
如何把 HuggingFace 里面的模型接入 LangChain。
通过 HuggingFace Hub
第一种集成方式,是通过 HuggingFace Hub。HuggingFace Hub 是一个开源模型中心化存储库,主要用于分享、协作和存储预训练模型、数据集以及相关组件。
我们给出一个 HuggingFace Hub 和 LangChain 集成的代码示例。
# 导入HuggingFace API Token import os os.environ['HUGGINGFACEHUB_API_TOKEN'] = '你的HuggingFace API Token' # 导入必要的库 from langchain import PromptTemplate, HuggingFaceHub, LLMChain # 初始化HF LLM llm = HuggingFaceHub( repo_id="google/flan-t5-small", #repo_id="meta-llama/Llama-2-7b-chat-hf", ) # 创建简单的question-answering提示模板 template = """Question: {question} Answer: """ # 创建Prompt prompt = PromptTemplate(template=template, input_variables=["question"]) # 调用LLM Chain --- 我们以后会详细讲LLM Chain llm_chain = LLMChain( prompt=prompt, llm=llm ) # 准备问题 question = "Rose is which type of flower?" # 调用模型并返回结果 print(llm_chain.run(question))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
可以看出,这个集成过程非常简单,只需要在HuggingFaceHub类的repo_id中指定模型名称,就可以直接下载并使用模型,模型会自动下载到 HuggingFace 的Cache目录,并不需要手工下载。
初始化 LLM,创建提示模板,生成提示的过程,你已经很熟悉了。这段代码中有一个新内容是我通过 llm_chain 来调用了 LLM。这段代码也不难理解,有关 Chain 的概念我们以后还会详述。
选择google/flan-t5-small这个比较旧的模型做测试,问了它一个很简单的问题,想看看它是否知道玫瑰是哪一种花。
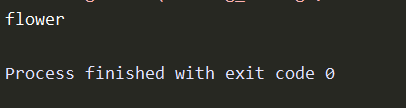
模型告诉我,玫瑰是花。对,答案只有一个字,flower。2023 年之前的模型,和 2023 年之后的模型,水平没得比。以前的模型能说话就不错了。
通过 HuggingFace Pipeline
既然 HuggingFace Hub 还不能完成 Llama-2 的测试,让我们来尝试另外一种方法,HuggingFace Pipeline。HuggingFace 的 Pipeline 是一种高级工具,它简化了多种常见自然语言处理(NLP)任务的使用流程,使得用户不需要深入了解模型细节,也能够很容易地利用预训练模型来做任务。
让我来看看下面的示例:
# 指定预训练模型的名称 model = "meta-llama/Llama-2-7b-chat-hf" # 从预训练模型中加载词汇器 from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained(model) # 创建一个文本生成的管道 import transformers import torch pipeline = transformers.pipeline( "text-generation", model=model, torch_dtype=torch.float16, device_map="auto", max_length = 1000 ) # 创建HuggingFacePipeline实例 from langchain import HuggingFacePipeline llm = HuggingFacePipeline(pipeline = pipeline, model_kwargs = {'temperature':0}) # 定义输入模板,该模板用于生成花束的描述 template = """ 为以下的花束生成一个详细且吸引人的描述: 花束的详细信息: ```{flower_details}``` """ # 使用模板创建提示 from langchain import PromptTemplate, LLMChain prompt = PromptTemplate(template=template, input_variables=["flower_details"]) # 创建LLMChain实例 from langchain import PromptTemplate llm_chain = LLMChain(prompt=prompt, llm=llm) # 需要生成描述的花束的详细信息 flower_details = "12支红玫瑰,搭配白色满天星和绿叶,包装在浪漫的红色纸中。" # 打印生成的花束描述 print(llm_chain.run(flower_details))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
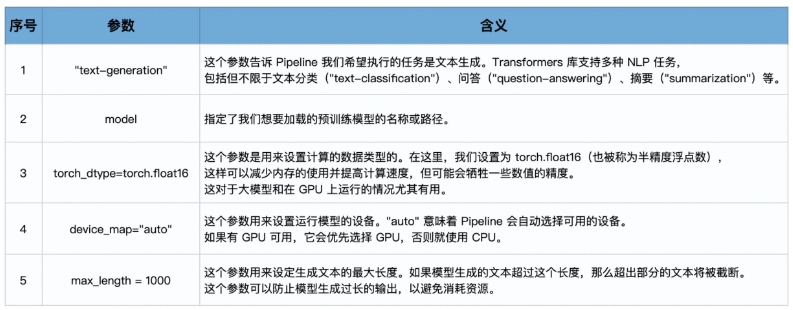
简单介绍一下代码中使用到的 transformers pipeline 的配置参数。
生成的结果之一如下:

这很有可能是 7B 这个模型太小,尽管有形成中文的相应能力,但是能力不够强大,也就导致了这样的结果。
至此,通过 HuggingFace 接口调用各种开源模型的尝试成功结束。下面,我们进行最后一个测试,看看 LangChain 到底能否直接调用本地模型。
用 LangChain 调用自定义语言模型
最后,我们来尝试回答这节课开头提出的问题,假设你就是想训练属于自己的模型。而且出于商业秘密的原因,不想开源它,不想上传到 HuggingFace,就是要在本机运行模型。此时应该如何利用 LangChain 的功能?
我们可以创建一个 LLM 的衍生类,自己定义模型。而 LLM 这个基类,则位于 langchain.llms.base 中,通过 from langchain.llms.base import LLM 语句导入。
这个自定义的 LLM 类只需要实现一个方法:
_call方法:用于接收输入字符串并返回响应字符串。
以及一个可选方法:
_identifying_params方法:用于帮助打印此类的属性。
下面,让我们先从 HuggingFace 的这里,下载一个 llama-2-7b-chat.ggmlv3.q4_K_S.bin 模型,并保存在本地。
自己训练一个能用的模型没那么容易。这个模型,它并不是原始的 Llama 模型,而是 TheBloke 这位老兄用他的手段为我们量化过的新模型,你也可以理解成,他已经为我们压缩或者说微调了 Llama 模型。

